Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il 📦 pacchetto Microsoft.Extensions.DataIngestion fornisce blocchi predefiniti .NET fondamentali per l'inserimento di dati. Consente agli sviluppatori di leggere, elaborare e preparare documenti per i flussi di lavoro di Intelligenza artificiale e apprendimento automatico, in particolare scenari di generazione aumentata dal recupero (RAG).
Con questi blocchi predefiniti, è possibile creare pipeline di inserimento dati affidabili, flessibili e intelligenti personalizzate per le esigenze dell'applicazione:
- Rappresentazione unificata dei documenti: Rappresenta qualsiasi tipo di file (ad esempio, PDF, Immagine o Microsoft Word) in un formato coerente che funziona bene con i modelli linguistici di grandi dimensioni.
- Inserimento dati flessibile: Leggere i documenti sia dai servizi cloud che dalle origini locali usando più lettori predefiniti, semplificando l'inserimento di dati da qualsiasi posizione.
- Miglioramenti predefiniti dell'intelligenza artificiale: Arricchire automaticamente il contenuto con riepiloghi, analisi del sentiment, estrazione di parole chiave e classificazione, preparazione dei dati per flussi di lavoro intelligenti.
- Strategie di suddivisione in blocchi personalizzabili: Suddividere i documenti in blocchi usando approcci basati su token, basati su sezioni o con riconoscimento semantico, in modo da poter ottimizzare le esigenze di recupero e analisi.
- Archiviazione pronta per la produzione: Memorizza blocchi elaborati nei database vettoriali e nei document store più diffusi, con supporto per la generazione di embedding, rendendo le pipeline pronte per l'utilizzo in scenari reali.
- Composizione della pipeline end-to-end: Concatenare lettori, processori, chunker e scrittori con l'API IngestionPipeline<T>, riducendo codice standard e semplificando la creazione, la personalizzazione e l'estensione dei flussi di lavoro completi.
- Prestazioni e scalabilità: Progettato per l'elaborazione dei dati scalabile, questi componenti possono gestire in modo efficiente grandi volumi di dati, rendendoli adatti per applicazioni di livello aziendale.
Tutti questi componenti sono aperti ed estendibili per progettazione. È possibile aggiungere logica personalizzata e nuovi connettori ed estendere il sistema per supportare gli scenari di intelligenza artificiale emergenti. Standardizzando il modo in cui i documenti vengono rappresentati, elaborati e archiviati, gli sviluppatori .NET possono creare pipeline di dati affidabili, scalabili e gestibili senza "reinventare la ruota" per ogni progetto.
Basata su basi stabili
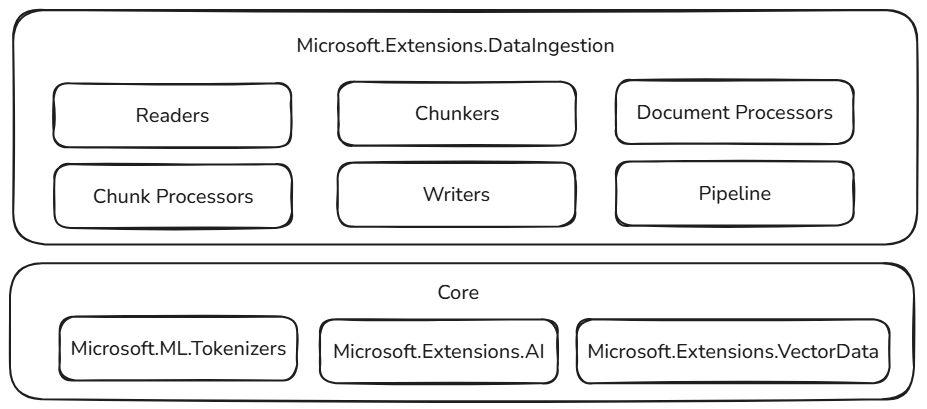
Questi blocchi predefiniti di inserimento dati si basano su componenti collaudati ed estendibili nell'ecosistema .NET, garantendo affidabilità, interoperabilità e integrazione senza problemi con i flussi di lavoro di intelligenza artificiale esistenti:
- Microsoft.ML.Tokenizers: I tokenizer forniscono le basi per la suddivisione in blocchi dei documenti in base ai token. Ciò consente una suddivisione precisa del contenuto, essenziale per preparare i dati per modelli linguistici di grandi dimensioni e ottimizzare le strategie di recupero.
- Microsoft.Extensions.AI: Questo set di librerie supporta le trasformazioni di arricchimento usando modelli linguistici di grandi dimensioni. Consente funzionalità come riepilogo, analisi del sentiment, estrazione di parole chiave e generazione di embedding, semplificando il miglioramento dei dati con approfondimenti intelligenti.
- Microsoft.Extensions.VectorData: Questo set di librerie offre un'interfaccia coerente per l'archiviazione di blocchi elaborati in un'ampia gamma di archivi vettoriali, tra cui Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch e molti altri ancora. In questo modo, le pipeline di dati sono pronte per la produzione e possono essere ridimensionate in back-end di archiviazione diversi.
Oltre a modelli e strumenti familiari, queste astrazioni si basano su componenti già estendibili. Le funzionalità e l'interoperabilità dei plug-in sono fondamentali, quindi, man mano che il resto dell'ecosistema di intelligenza artificiale .NET aumenta, aumentano anche le funzionalità dei componenti di inserimento dati. Questo approccio consente agli sviluppatori di integrare facilmente nuovi provider, arricchimenti e opzioni di archiviazione, mantenendo le pipeline pronte per il futuro e adattabili agli scenari di intelligenza artificiale in continua evoluzione.
Vedere anche
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.