Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook Architecting Cloud Native .NET Applications for Azure, disponibile in .NET Docs o come PDF scaricabile gratuito che può essere letto offline.

La prima linea di difesa è la resilienza delle applicazioni.
Anche se è possibile investire molto tempo nella scrittura del proprio framework di resilienza, tali prodotti esistono già.
Polly è una libreria completa di resilienza .NET e di gestione degli errori temporanei che consente agli sviluppatori di esprimere criteri di resilienza in modo fluente e thread-safe. Polly è destinato alle applicazioni compilate con .NET Framework o .NET 7. Nella tabella seguente vengono descritte le funzionalità di resilienza, denominate policies, disponibili nella libreria Polly. Possono essere applicate singolarmente o raggruppate.
| Politica | Esperienza |
|---|---|
| Riprova | Configura le operazioni di ripetizione dei tentativi nelle operazioni designate. |
| Interruttore | Blocca le operazioni richieste per un periodo predefinito quando gli errori superano una soglia configurata |
| Interruzione temporanea | Limita la durata per cui un chiamante può attendere una risposta. |
| Paratia | Limita le azioni al pool di risorse a dimensione fissa per evitare che le chiamate fallite sovraccarichino una risorsa. |
| cache | Archivia automaticamente le risposte. |
| Risoluzione alternativa | Definisce il comportamento strutturato in caso di errore. |
Si noti come nella figura precedente i criteri di resilienza si applicano ai messaggi di richiesta, indipendentemente dal fatto che provenissi da un client esterno o da un servizio back-end. L'obiettivo è compensare la richiesta di un servizio che potrebbe essere momentaneamente non disponibile. Queste interruzioni di breve durata si manifestano in genere con i codici di stato HTTP illustrati nella tabella seguente.
| Codice di stato HTTP | Motivo |
|---|---|
| 404 | Non trovato |
| 408 | Timeout richiesta |
| 429 | Troppe richieste (probabilmente sei stato limitato) |
| 502 | Gateway non valido |
| 503 | Servizio non disponibile |
| 504 | Timeout del gateway |
Domanda: Ritenteresti un codice di stato HTTP 403 - Forbidden? No In questo caso, il sistema funziona correttamente, ma informa il chiamante che non sono autorizzati a eseguire l'operazione richiesta. È necessario prestare attenzione a ripetere solo le operazioni causate da errori.
Come consigliato nel capitolo 1, gli sviluppatori Microsoft che creano applicazioni native del cloud devono avere come destinazione la piattaforma .NET. La versione 2.1 ha introdotto la libreria HTTPClientFactory per la creazione di istanze client HTTP per l'interazione con le risorse basate su URL. Sostituire la classe HTTPClient originale, la classe factory supporta molte funzionalità avanzate, una delle quali è una stretta integrazione con la libreria di resilienza Polly. Con esso, è possibile definire facilmente i criteri di resilienza nella classe startup dell'applicazione per gestire errori parziali e problemi di connettività.
Passiamo ad ampliare i modelli di retry e circuit breaker.
Modello di ripetizione dei tentativi
In un ambiente nativo del cloud distribuito, le chiamate ai servizi e alle risorse cloud possono non riuscire a causa di errori temporanei (di breve durata), che in genere si correggeranno dopo un breve periodo di tempo. L'implementazione di una strategia di ripetizione dei tentativi consente a un servizio nativo del cloud di attenuare questi scenari.
Il modello di ripetizione consente a un servizio di ripetere un'operazione di richiesta non riuscita per un numero configurabile di volte, con un tempo di attesa in aumento esponenziale. La figura 6-2 mostra un nuovo tentativo in azione.
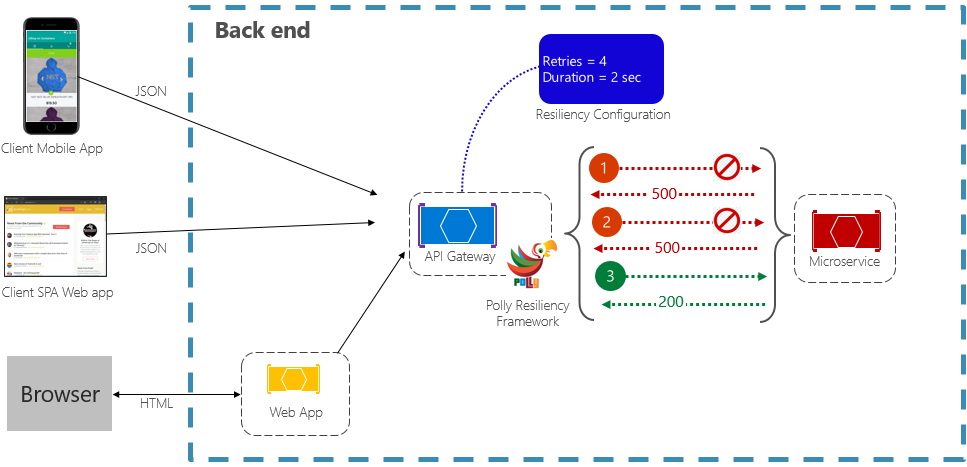
Figura 6-2. Modello di ripetizione dei tentativi in azione
Nella figura precedente è stato implementato un modello di ripetizione dei tentativi per un'operazione di richiesta. È configurato per consentire fino a quattro tentativi prima di fallire, con un intervallo di attesa con aumento graduale (tempo di attesa) a partire da due secondi, che raddoppia esponenzialmente per ogni tentativo successivo.
- La prima chiamata ha esito negativo e restituisce un codice di stato HTTP pari a 500. L'applicazione attende due secondi e ritenta la chiamata.
- La seconda chiamata ha esito negativo e restituisce anche un codice di stato HTTP pari a 500. L'applicazione raddoppia ora l'intervallo di backoff a quattro secondi e ritenta la chiamata.
- Infine, la terza chiamata ha esito positivo.
- In questo scenario, l'operazione di ripetizione avrebbe tentato fino a quattro volte, raddoppiando la durata del backoff prima di fallire la chiamata.
- Se il quarto tentativo non è riuscito, viene richiamato un criterio di fallback per gestire correttamente il problema.
È importante aumentare il periodo di backoff prima di ripetere la chiamata per consentire al servizio di auto-correggersi. È consigliabile implementare un backoff in aumento esponenziale (raddoppiando il periodo in ogni tentativo) per consentire un tempo di correzione adeguato.
Modello di interruttore
Anche se il modello di ripetizione dei tentativi può aiutare a salvare una richiesta in un errore parziale, esistono situazioni in cui gli errori possono essere causati da eventi imprevisti che richiedono periodi di tempo più lunghi per la risoluzione. Questi errori possono variare, in base alla gravità, dalla perdita parziale della connettività alla totale interruzione di un servizio. In queste situazioni, non è opportuno che un'applicazione riprova continuamente a un'operazione che non sia probabile che abbia esito positivo.
Per peggiorare le cose, l'esecuzione di continue operazioni di ripetizione dei tentativi in un servizio non reattivo può comportare lo spostamento in uno scenario denial of service autoimposto in cui si inonda il servizio con chiamate continue che esauriscono risorse come memoria, thread e connessioni di database, causando un errore in parti non correlate del sistema che usano le stesse risorse.
In queste situazioni, è preferibile che l'operazione abbia esito negativo immediatamente e tenti di richiamare il servizio solo se è probabile che abbia esito positivo.
Il pattern Circuit Breaker può impedire a un'applicazione di tentare ripetutamente di eseguire un'operazione che probabilmente fallirà. Dopo un numero predefinito di chiamate non riuscite, blocca tutto il traffico verso il servizio. Periodicamente, consentirà a una chiamata di prova di determinare se il guasto è stato risolto. La figura 6-3 mostra il modello interruttore in azione.
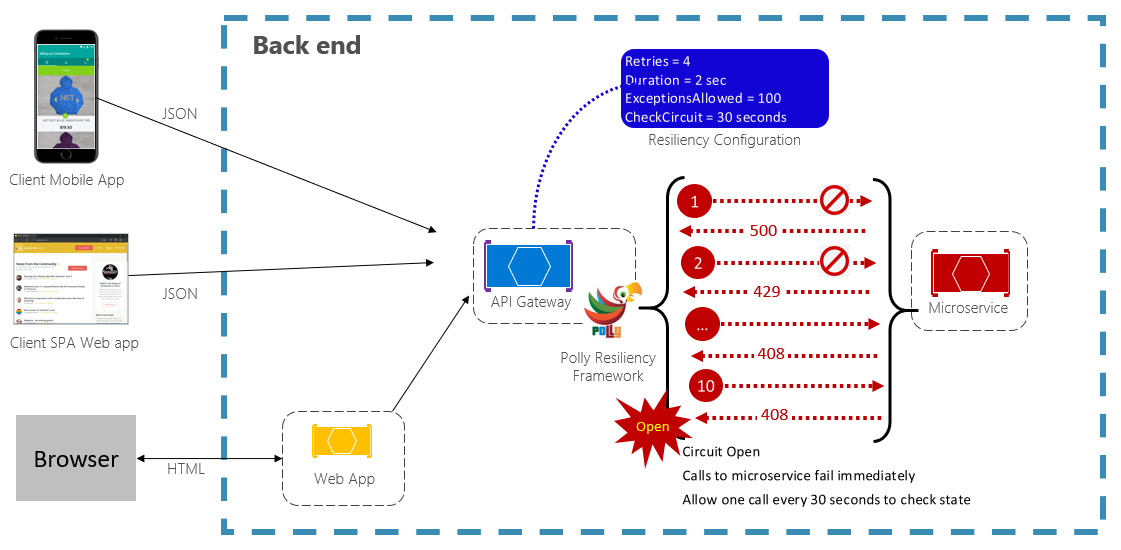
Figura 6-3. Modello di interruttore in azione
Nella figura precedente è stato aggiunto un modello di "Circuit Breaker" al modello originale di ripetizione dei tentativi. Si noti che dopo 100 richieste non riuscite, gli interruttori vengono aperti e non consentono più chiamate al servizio. Il valore CheckCircuit, impostato a 30 secondi, specifica la frequenza con cui la libreria consente a una richiesta di procedere al servizio. Se la chiamata ha esito positivo, il circuito si chiude e il servizio è nuovamente disponibile per il traffico.
Tenere presente che l'intento dello schema Circuit Breaker è diverso da quello dello schema Retry. Il modello Di ripetizione dei tentativi consente a un'applicazione di ripetere un'operazione nel presupposto che abbia esito positivo. Il modello interruttore impedisce a un'applicazione di eseguire un'operazione che potrebbe non riuscire. In genere, un'applicazione combina questi due modelli usando il modello Di ripetizione dei tentativi per richiamare un'operazione tramite un interruttore.
Test della resilienza
I test per la resilienza non possono essere sempre eseguiti allo stesso modo in cui si testano le funzionalità dell'applicazione (eseguendo unit test, test di integrazione e così via). È invece necessario testare le prestazioni del carico di lavoro end-to-end in condizioni di errore, che si verificano solo in modo intermittente. Ad esempio: inserire errori bloccando processi, certificati scaduti, rendere i servizi dipendenti non disponibili e così via. Framework come chaos-monkey possono essere usati per questi test di caos.
La resilienza delle applicazioni è un must per la gestione delle operazioni richieste problematiche. Ma è solo la metà della storia. Verranno ora illustrate le funzionalità di resilienza disponibili nel cloud di Azure.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.