Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook, Progettazione di applicazioni .NET native del cloud per Azure, disponibile in .NET Docs o come PDF scaricabile gratuitamente che può essere letto offline.

Quello relazionale (SQL) e non relazionale (NoSQL) rappresentano due tipi di sistemi di database comunemente implementati nelle app native del cloud. Sono diversi nella costurzione, nel modo di archiviare i dati e nell’accesso. Entrambi saranno esaminati in questa sezione. Più avanti in questo capitolo, si parlerà della tecnologia di database emergente NewSQL.
I database relazionali sono una tecnologia imperante da decenni. Sono evoluti, collaudati e ampiamente implementati. Prodotti di database concorrenti, strumenti e competenze in ingresso. I database relazionali forniscono un archivio di tabelle dati correlate. Queste tabelle hanno uno schema fisso, usano SQL (Structured Query Language) per gestire i dati e supportano garanzie ACID: atomicità, coerenza, isolamento e durabilità.
I database No-SQL fanno riferimento ad archivi dati non relazionali ad alte prestazioni. Sono eccellenti nelle caratteristiche di facilità d'uso, scalabilità, resilienza e disponibilità. Anziché unire tabelle di dati normalizzati, NoSQL archivia dati non strutturati o semistrutturati, spesso come coppie chiave-valore o documenti JSON. In genere, i database No-SQL non forniscono garanzie ACID oltre l'ambito di una singola partizione di database. Servizi con volumi elevati che richiedono tempi di risposta secondari favoriscono gli archivi dati NoSQL.
L'impatto delle tecnologie NoSQL per sistemi nativi del cloud distribuiti non può essere sopravvalutato. La proliferazione di nuove tecnologie dati in questo spazio ha compromesso soluzioni basate esclusivamente su database relazionali.
I database NoSQL includono diversi modelli per l'accesso e la gestione dei dati, adatti a casi d'uso specifici. La figura 5-9 presenta quattro modelli comuni.
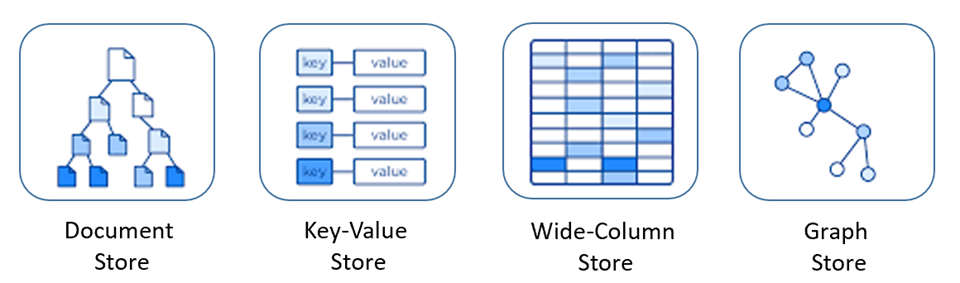
Figura 5-9: Modelli di dati per database NoSQL
| Modello | Caratteristiche |
|---|---|
| Archivio documenti | I dati e i metadati vengono archiviati gerarchicamente in documenti basati su JSON all'interno del database. |
| Archivio chiave-valore | Il più semplice dei database NoSQL, i dati sono rappresentati come una raccolta di coppie chiave-valore. |
| Wide-Column Negozio | I dati correlati vengono archiviati come set di coppie chiave-valore nidificate all'interno di una singola colonna. |
| Archivio a grafo | I dati vengono archiviati in una struttura del grafo come proprietà di nodo, bordo e dati. |
Teorema CAP e PACELC
Per comprendere le differenze tra questi tipi di database, considerare il teorema CAP, un set di principi applicati ai sistemi distribuiti che archiviano lo stato. La figura 5-10 illustra le tre proprietà del teorema CAP.
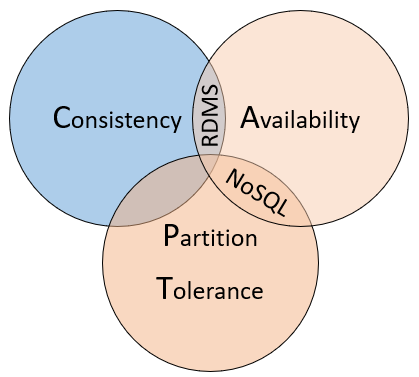
Figura 5-10. il teorema CAP
Il teorema indica che i sistemi di dati distribuiti offriranno un compromesso tra coerenza, disponibilità e tolleranza di partizione. E che qualsiasi database può garantire solo due delle tre proprietà:
Coerenza. Ogni nodo del cluster risponde con i dati più recenti, anche se il sistema deve bloccare la richiesta fino all'aggiornamento di tutte le repliche. Se si esegue una query su un "sistema coerente" per un elemento che sta attualmente completando un aggiornamento, si dovrà attendere la risposta fino a quando tutte le repliche non saranno aggiornate correttamente. Tuttavia, si riceveranno i dati più recenti. È bene comprendere che il termine "coerenza" come viene usato nel contesto del teorema CAP ha un significato tecnico che è diverso dal modo in cui la "coerenza" è definita nel contesto delle garanzie ACID.
Disponibilità. Ogni richiesta ricevuta da un nodo non con errori nel sistema deve generare una risposta. Se si esegue una query su un "sistema disponibile" per un elemento che sta attualmente completando un aggiornamento, si otterrà la miglior risposta che il servizio può fornire in quel momento. Si noti tuttavia che la "disponibilità" definita dal teorema CAP è tecnicamente diversa dalla "disponibilità elevata" perché è convenzionalmente nota per i sistemi distribuiti.
Tolleranza di partizione. Garantisce che il sistema continui a funzionare anche se un nodo dati replicato non riesce o perde la connettività con altri nodi dati replicati.
Il teorema CAP illustra i compromessi associati alla gestione della coerenza e della disponibilità durante una partizione di rete; tuttavia, tali compromessi sussistono anche in assenza di una partizione di rete.
Nota
Anche se si sceglie la disponibilità rispetto alla coerenza, in tempi di partizione di rete, la disponibilità verrà influenzata negativamente. Il sistema disponibile CAP è più disponibile per alcuni dei suoi client, ma non è necessariamente "a disponibilità elevata" per tutti i suoi clienti.
Il teorema CAP è spesso esteso a PACELC per illustrare i compromessi in modo più completo. Il teorema CAP è particolarmente rilevante negli ambienti connessi intermittentmente, ad esempio quelli correlati a Internet delle cose (IoT), il monitoraggio ambientale e le applicazioni per dispositivi mobili. In questi contesti, i dispositivi possono essere partizionati a causa di condizioni fisiche complesse, ad esempio interruzioni dell'alimentazione o quando entrano in spazi limitati come gli ascensori. Per i sistemi distribuiti, ad esempio le applicazioni cloud, è più appropriato usare il teorema PACELC, che è più completo e considera compromessi come latenza e coerenza anche in assenza di partizioni di rete.
In genere, i database relazionali offrono coerenza e disponibilità, ma non tolleranza di partizione. Il loro provisioning è solitamente effettuato a un singolo server e scalabilità verticale aggiungendo altre risorse al computer.
Molti sistemi di database relazionali supportano funzionalità di replica predefinite in cui è possibile creare copie del database primario in altre istanze del server secondario. Le operazioni di scrittura vengono eseguite nell'istanza primaria e replicate in ognuna delle istanze secondarie. In caso di errore, l'istanza primaria può eseguire il failover in un database secondario per garantire disponibilità elevata. Le repliche secondarie possono essere usate anche per distribuire operazioni di lettura. Mentre le operazioni di scrittura passano sempre attraverso la replica primaria, le operazioni di lettura possono essere instradate a qualsiasi database secondario per ridurre il carico di sistema.
I dati possono anche essere partizionati orizzontalmente tra più nodi, ad esempio con il partizionamento orizzontale. Tuttavia, il partizionamento orizzontale aumenta notevolmente il sovraccarico operativo distribuendo i dati tra molte parti che non riescono a comunicare facilmente. Può essere costoso e dispendioso in termini di tempo da gestire. Le funzionalità relazionali che includono join di tabelle, transazioni e integrità referenziale richiedono penali per le prestazioni elevate nelle distribuzioni partizionate.
Gli obiettivi di coerenza della replica e del punto di recupero possono essere ottimizzati configurando se la replica si verifica in modo sincrono o asincrono. Se le repliche di dati dovessero perdere la connettività di rete in un cluster di database relazionale "altamente coerente" o sincrono, non sarà possibile scrivere nel database. Il sistema respinge l'operazione di scrittura perché non può ripetere la modifica nell'altra replica dati. Ogni replica dati deve essere aggiornata perché la transazione possa essere completata.
In genere, i database NoSQL supportano disponibilità elevata e tolleranza di partizione. Aumentano orizzontalmente, spesso tra server di base. Questo approccio offre un'enorme disponibilità, sia all'interno che tra aree geografiche, a un costo ridotto. È possibile partizionare e replicare dati tra questi computer o nodi, garantendo ridondanza e tolleranza di errore. La coerenza viene generalmente ottimizzata tramite protocolli di consenso o meccanismi quorum. Forniscono un maggiore controllo quando si spostano i compromessi tra ottimizzazione sincrona e replica asincrona nei sistemi relazionali.
Se le repliche dati perdono la connettività in un cluster di database NoSQL a disponibilità elevata, è comunque possibile completare un'operazione di scrittura nel database. Il cluster di database consente l'operazione di scrittura e aggiorna ogni replica dati non appena disponibile. I database NoSQL che supportano più repliche scrivibili possono rafforzare ulteriormente la disponibilità elevata evitando la necessità di failover durante l'ottimizzazione dell'obiettivo del tempo di ripristino.
Generalmente, i database NoSQL moderni implementano abilità di partizionamento come funzionalità del design di sistema. La gestione delle partizioni è spesso incorporata nel database e il routing viene ottenuto tramite hint di posizionamento, spesso denominati chiavi di partizione. I modelli di dati flessibili consentono ai database NoSQL di ridurre il carico di lavoro della gestione dello schema e migliorare la disponibilità durante la distribuzione degli aggiornamenti delle applicazioni che richiedono modifiche al modello di dati.
Disponibilità e scalabilità elevate sono spesso più importanti per l'azienda rispetto ai join di tabelle relazionali e all'integrità referenziale. Gli sviluppatori possono implementare tecniche e modelli come Sagas, CQRS e messaggistica asincrona per infine adottare la coerenza.
Al giorno d'oggi, è necessario fare attenzione quando si considerano i vincoli del teorema CAP. È emerso un nuovo tipo di database, NewSQL, che estende il motore di database relazionale per supportare sia la scalabilità orizzontale che la prestazione scalabile dei sistemi NoSQL.
Considerazioni per relazionali vs. Sistemi NoSQL
In base ai requisiti specifici dei dati, un microservizio basato sul cloud può implementare un archivio dati relazionale, NoSQL o entrambi.
| Valutare l’uso di un archivio dati NoSQL quando: | Valutare l’uso di un database relazionale quando: |
|---|---|
| Sono presenti carichi di lavoro a volume elevato che richiedono una latenza prevedibile su larga scala (ad esempio, una latenza misurata in millisecondi durante l'esecuzione di milioni di transazioni al secondo) | In genere, il volume del carico di lavoro è di migliaia di transazioni al secondo |
| I dati sono dinamici e cambiano di frequente | I dati sono altamente strutturati e richiedono integrità referenziale |
| Le relazioni possono essere modelli di dati denormalizzati | Le relazioni sono espresse tramite join di tabelle su modelli di dati normalizzati |
| Il recupero dei dati è semplice ed espresso senza join di tabelle | È possibile usare query e report complessi |
| I dati vengono generalmente replicati tra aree geografiche e richiedono un maggiore controllo sulla coerenza, la disponibilità e le prestazioni | In genere, i dati sono centralizzati o possono essere replicati in modo asincrono |
| L'applicazione verrà distribuita nell'hardware di base, ad esempio con cloud pubblici | L'applicazione verrà distribuita in hardware di grandi dimensioni e di alta gamma |
Nelle sezioni successive verranno esaminate le opzioni disponibili nel cloud di Azure per l'archiviazione e la gestione dei dati nativi del cloud.
Database distribuito come servizio
Per iniziare, è possibile effettuare il provisioning di una macchina virtuale di Azure e installare il database preferito per ogni servizio. Anche se si ha il controllo completo sull'ambiente, si rinuncerebbe a molte funzionalità predefinite della piattaforma cloud. Si sarebbe anche responsabili della gestione della macchina virtuale e del database per ogni servizio. Questo approccio potrebbe presto diventare dispendioso in termini di tempo e costoso.
Al contrario, le applicazioni native del cloud preferiscono servizi dati esposti come database distribuito come servizio (DBaaS). Completamente gestiti da un fornitore di servizi cloud, questi servizi offrono sicurezza, scalabilità e monitoraggio predefiniti. Anziché possedere il servizio, è sufficiente utilizzarlo come servizio di backup. Il provider gestisce la risorsa su larga scala ed è responsabile di prestazioni e manutenzione.
Possono essere configurati tra zone di disponibilità cloud e aree per ottenere una disponibilità elevata. Tutti supportano la capacità just-in-time e un modello con pagamento in base al consumo. Azure offre diversi tipi di opzioni di servizio dati gestito, ognuna con vantaggi specifici.
Prima di tutte, si esamineranno i servizi DBaaS relazionali disponibili in Azure. Si noterà che il database SQL Server principale di Microsoft è disponibile insieme a diverse opzioni open source. Quindi, si descriveranno i servizi dati NoSQL in Azure.
Database relazionali di Azure
Per i microservizi nativi del cloud che richiedono dati relazionali, Azure offre quattro offerte di database relazionali gestiti come servizio (DBaaS), come illustrato nella figura 5-11.

Figura 5-11. Database relazionali gestiti disponibili in Azure
Nella figura precedente, notare come ciascuno è basato su un'infrastruttura DBaaS comune che offre funzionalità chiave senza costi aggiuntivi.
Queste funzionalità sono particolarmente importanti per le organizzazioni che eseguono il provisioning di un numero elevato di database, ma hanno risorse limitate per amministrarli. È possibile effettuare il provisioning di un database di Azure in pochi minuti selezionando la quantità di core di elaborazione, memoria, e archiviazione sottostante. È possibile ridimensionare il database in tempo reale e regolare dinamicamente le risorse senza tempi di inattività.
Database SQL di Microsoft Azure
Per team di sviluppo con esperienza in Microsoft SQL Server, l’uso del database SQL di Azure è consigliabile. Si tratta di un database relazionale come servizio (DBaaS) completamente gestito basato sul motore di database di Microsoft SQL Server. Il servizio ha molte funzionalità disponibili anche nella versione locale di SQL Server ed esegue la versione stabile più recente del motore di database di SQL Server.
Per l'uso con un microservizio nativo del cloud, il database SQL di Azure è disponibile con tre opzioni di distribuzione:
Un Database singolo rappresenta un database SQL completamente gestito eseguito in un server di database SQL di Azure nel cloud di Azure. Il database è considerato indipendente perché non ha dipendenze di configurazione nel server di database sottostante.
Un’istanza gestita è un'istanza completamente gestita del motore di database di Microsoft SQL Server che offre una compatibilità quasi del 100% con un'istanza locale di SQL Server. Questa opzione supporta database di grandi dimensioni (fino a 35 TB) e viene inserita in una Rete virtuale di Azure per un migliore isolamento.
Il serverless del database SQL di Azure è un livello di calcolo per database singolo che viene ridimensionato automaticamente in base alle esigenze del carico di lavoro. Fattura solo per la quantità di calcolo usata al secondo. Il servizio è particolarmente adatto per carichi di lavoro con modelli di utilizzo intermittenti e imprevedibili, con periodi di inattività. Il livello di calcolo serverless sospende automaticamente anche i database durante periodi di inattività in modo che vengano fatturati solo gli addebiti per l'archiviazione. Riprende automaticamente quando viene l’attività è ripristinata.
Oltre allo stack tradizionale di Microsoft SQL Server, Azure include anche le versioni gestite di tre database open source più diffusi.
Database open source in Azure
I database relazionali open source sono una scelta diffusa per le applicazioni native del cloud. Molte aziende li prediligono rispetto ai prodotti di database commerciali, soprattutto per risparmiare sui costi. Molti team di sviluppo ne apprezzano la flessibilità, lo sviluppo supportato dalla community e l'ecosistema di strumenti ed estensioni. I database open source possono essere distribuiti in più provider di servizi cloud, riducendo al minimo il problema del "blocco fornitore”.
Gli sviluppatori possono facilmente ospitare qualsiasi database open source in una macchina virtuale di Azure. Fornendo controllo completo, questo approccio comporta la responsibilità di gestione, monitoraggio e manutenzione del database e della macchina virtuale.
Tuttavia, Microsoft continua a impegnarsi per mantenere Azure una "piattaforma aperta", offrendo diversi database open source molto diffusi come servizi DBaaS completamente gestiti.
Database di Azure per MySQL
MySQL è un database relazionale open source e un pilastro per le applicazioni basate sullo stack di software LAMP. Ampiamente scelto per carichi elevati di lavoro di lettura, è usato da molte grandi organizzazioni, tra cui Facebook, Twitter e YouTube. L'edizione Community è disponibile gratuitamente, mentre l'edizione Enterprise richiede l’acquisto di una licenza. Originariamente creato nel 1995, il prodotto è stato acquistato da Sun Microsystems nel 2008. Oracle ha acquisito Sun e MySQL nel 2010.
Database di Azure per MySQL è un servizio di database relazionale gestito basato sul motore del server MySQL open source. Usa l'edizione MySQL Community. Il server MySQL di Azure è il centro amministrativo del servizio. Si tratta dello stesso motore del server MySQL usato per distribuzioni locali. Il motore può creare un database singolo per server o più database per server che condividono risorse. È possibile continuare a gestire dati usando gli stessi strumenti open source senza dover acquisire nuove competenze o gestire macchine virtuali.
Database di Azure per MariaDB
Il server MariaDB è un altro server di database open source molto diffuso. È stato creato come fork di MySQL quando Oracle ha acquistato Sun Microsystems, allora proprietario di MySQL. La finalità era quella di garantire che MariaDB rimanesse open source. Poiché MariaDB è un fork di MySQL, le definizioni di dati e tabelle sono compatibili, e i protocolli client, le strutture e le API sono a maglia stretta.
MariaDB ha una solida community ed è usata da molte grandi aziende. Mentre Oracle continua a sostenere, perfezionare e supportare MySQL, la fondazione MariaDB gestisce MariaDB, consentendo contributi pubblici al prodotto e alla documentazione.
Database di Azure per MariaDB è un database relazionale completamente gestito come servizio nel cloud di Azure. Il servizio si basa sul motore del server MariaDB, edizione Community. È in grado di gestire carichi di lavoro critici con prestazioni prevedibili e scalabilità dinamica.
Database di Azure per PostgreSQL
PostgreSQL è un database relazionale open source con oltre 30 anni di sviluppo attivo. PostgreSQL ha una reputazione solida per affidabilità e integrità dei dati. È Ricco di funzionalità, conforme a SQL e considerato più efficiente di MySQL, in particolare per carichi di lavoro con query complesse e scritture pesanti. Molte grandi aziende, tra cui Apple, Red Hat e Fujitsu, hanno costruito prodotti usando PostgreSQL.
Database di Azure per PostgreSQL è un servizio di database relazionale completamente gestito, basato sul motore di database open source Postgres. Il servizio supporta molte piattaforme di sviluppo, tra cui C++, Java, Python, Node, C# e PHP. È possibile eseguire la migrazione di database PostgreSQL usando lo strumento dell'interfaccia della riga di comando o il Servizio migrazione dei dati di Azure.
Il database di Azure per PostgreSQL è disponibile con due opzioni di distribuzione:
L'opzione di distribuzione con Server singolo è un centro amministrativo per più database al quale è possibile distribuire molti database. I prezzi sono strutturati per server in base ai core e all'archiviazione.
L'opzione Hyperscale (Citus) è basata sulla tecnologia Citus Data. Consente prestazioni elevate ridimensionando orizzontalmente un singolo database tra centinaia di nodi per offrire prestazioni e scalabilità rapide. Questa opzione consente al motore di inserire più dati in memoria, parallelizzare le query tra centinaia di nodi e indicizzare i dati più velocemente.
Dati NoSQL in Azure
Cosmos DB è un servizio di database NoSQL completamente gestito e distribuito a livello globale nel cloud di Azure. È stato adottato da molte grandi aziende in tutto il mondo, tra cui Coca-Cola, Skype, ExxonMobil e Liberty Mutual.
Se i servizi richiedono risposte rapide da qualsiasi parte del mondo, disponibilità elevata o scalabilità elastica, Cosmos DB è un'ottima opzione. La figura 5-12 mostra Cosmos DB.
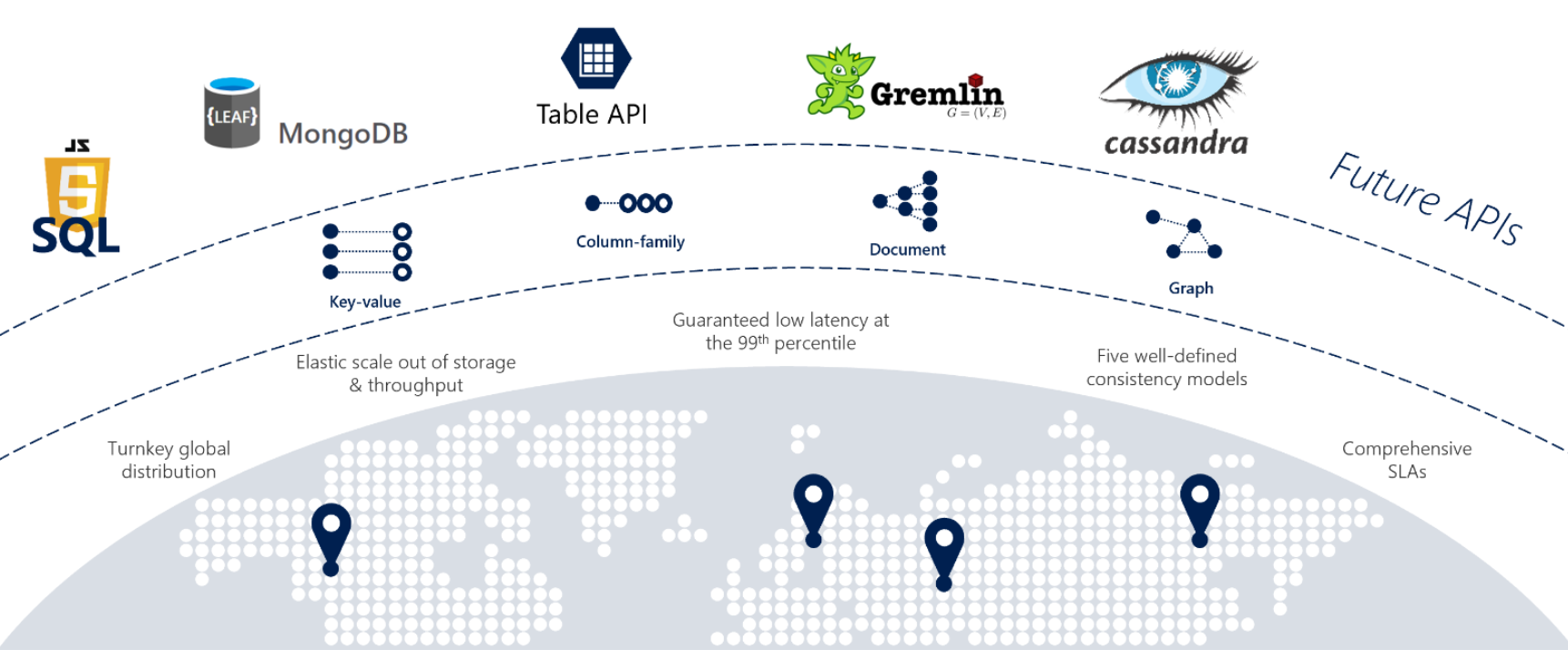
Figura 5-12: Panoramica di Azure Cosmos DB
La figura precedente presenta molte delle funzionalità integrate native del cloud disponibili in Cosmos DB. Saranno esaminate in dettaglio in questa sezione.
Supporto globale
Spesso, le applicazioni native del cloud hanno un pubblico globale e richiedono scalabilità globale.
È possibile distribuire i database Cosmos tra aree o in tutto il mondo, inserendo dati vicino agli utenti, migliorando il tempo di risposta e riducendo la latenza. È possibile aggiungere o rimuovere un database da un'area senza sospendere o ridistribuire i servizi. In background, Cosmos DB replica i dati in modo trasparente in ognuna delle aree configurate.
Cosmos DB supporta il clustering attivo/attivo a livello globale, consentendo di configurare una delle aree di database per supportare sia le operazioni di scrittura che di lettura.
Il protocollo di scrittura multi-area è un’importante caratteristica di Cosmos DB che abilita la seguente funzionalità:
Scalabilità elastica illimitata per la scrittura e la lettura.
Disponibilità in lettura e scrittura pari al 99,999% in tutto il mondo.
Letture e scritture gestite in meno di 10 millisecondi nel 99% dei casi.
Con le API multi-homing di Cosmos DB, il microservizio riconosce automaticamente l’area di Azure più vicina e vi invia le richieste. L'area più vicina è identificata da Cosmos DB senza alcuna modifica di configurazione. Se un'area non è più disponibile, la funzionalità Multi-Homing instrada automaticamente le richieste alla successiva area disponibile più vicina.
Supporto di più modelli
Quando si effettua il replatforming di applicazioni monolitiche in un'architettura nativa del cloud, i team di sviluppo devono talvolta eseguire la migrazione di archivi dati NoSQL open source. Cosmos DB consente di preservare l'investimento in questi archivi dati NoSQL con la relativa piattaforma dati multi-modello. La seguente tabella illustra le API di compatibilità di NoSQL supportate.
| Fornitore | Descrizione |
|---|---|
| API NoSQL | LE API per NoSQL archiviano dati in formato di documento |
| API MongoDB | Supporta le API Mongo DB e i documenti JSON |
| API Gremlin | Supporta l'API Gremlin con nodi basati su grafi e rappresentazioni dei dati perimetrali |
| API Cassandra | Supporta l'API Casandra per le rappresentazioni di dati a colonne larghe |
| API di tabella | Supporta Archiviazione tabelle di Azure con potenziamenti premium |
| PostgreSQL API | Servizio gestito per l'esecuzione di PostgreSQL su qualsiasi scala |
I team di sviluppo possono eseguire la migrazione di database esistenti Mongo, Gremlin o Cassandra in Cosmos DB con modifiche minime a dati o codici. Per nuove app, i team di sviluppo possono scegliere tra opzioni open source o il modello API SQL integrato.
Al suo interno, Cosmos archivia dati in un semplice formato struct costituito da tipi di dati primitivi. Per ogni richiesta, il motore di database converte i dati primitivi nella rappresentazione del modello selezionata.
Nella tabella precedente, notare l'opzione Tabella API. Questa API è un'evoluzione di Archiviazione tabelle di Azure. Entrambe condividono lo stesso modello di tabella di base, ma l'API Tabella di Cosmos DB aggiunge migliorie premium non disponibili nell'API di archiviazione di Azure. La seguente tabella contrasta le funzionalità.
| Funzionalità | Archiviazione delle tabelle di Azure | Azure Cosmos DB, un servizio di database distribuito globale di Microsoft |
|---|---|---|
| Latenza | Veloce | Latenza in millisecondi a cifra singola per letture e scritture in tutto il mondo |
| Velocità effettiva | Limite di 20.000 operazioni per tabella | Operazioni illimitate per tabella |
| Distribuzione globale | Area singola con area di lettura secondaria singola facoltativa | Distribuzioni chiavi in mano in tutte le aree con failover automatico |
| Indicizzazione | Disponibile solo per le proprietà delle chiavi di partizione e di riga | Indicizzazione automatica di tutte le proprietà |
| Prezzi | Ottimizzato per carichi di lavoro ad accesso saltuario (velocità effettiva bassa: rapporto di archiviazione) | Ottimizzato per carichi di lavoro ad accesso frequente (velocità effettiva elevata: rapporto di archiviazione) |
I microservizi che usano l'archiviazione tabelle di Azure possono eseguire facilmente la migrazione all'API tabella di Cosmos DB. Non sono necessarie modifiche al codice.
Coerenza ottimizzabile
La sezione Relazionale vs. NoSQL ha illustrato in precedenza l’argomento della coerenza dei dati. La coerenza dei dati si riferisce all’integrità dei dati. I servizi nativi del cloud con dati distribuiti si basano sulla replica e devono fare un compromesso fondamentale tra coerenza di lettura, disponibilità e latenza.
La maggior parte dei database distribuiti consente agli sviluppatori di scegliere tra due modelli di coerenza: coerenza assoluta e coerenza finale. La coerenza assoluta è lo standard di rifermiento per la programmabilità di dati. Garantisce che una query restituisca sempre i dati più recenti, anche se il sistema dovesse incorrere in una latenza in attesa della replica di un aggiornamento in tutte le copie del database. Al contrario, un database configurato per coerenza finale restituirà immediatamente i dati, anche se non sono la copia più recente. La seconda opzione consente maggiori disponibilità e scalabilità e migliori prestazioni.
Azure Cosmos DB offre cinque modelli di coerenza ben definiti, illustrati nella figura 5-13.

Figura 5-13: Livelli di coerenza di Cosmos DB
Queste opzioni consentono di effettuare scelte precise e compromessi granulari per coerenza, disponibilità e prestazioni per i dati. I livelli sono illustrati nella seguente tabella.
| Livello di coerenza | Descrizione |
|---|---|
| Finale | Nessuna garanzia di ordine per le letture. Alla fine, le repliche convergeranno. |
| Prefisso costante | Le letture sono ancora eventuali, ma i dati vengono restituiti nell'ordine in cui sono scritti. |
| Sessione | Garantisce la lettura di tutti i dati scritti durante la sessione corrente. È il livello di coerenza predefinito. |
| Decadimento ristretto | Legge le scritture finali in base all'intervallo specificato. |
| Assoluta | Le letture garantiscono di restituire la versione con commit più recente di un elemento. Un client non vede mai un'operazione di lettura parziale o di cui non è stato eseguito il commit. |
Nell'articolo Familiarizzare con il 9-Ball: livelli di coerenza di Cosmos DB, il Program manager di Microsoft Jeremy Likness fornisce un’eccellente descrizione dei cinque modelli.
Partizionamento
Azure Cosmos DB adotta il partizionamento automatico per ridimensionare un database al fine di soddisfare le esigenze di prestazione dei servizi nativi del cloud.
È possibile gestire dati in Cosmos DB creando database, contenitori ed elementi.
I contenitori si trovano in un database Cosmos DB e rappresentano un raggruppamento di elementi indipendente da schemi. Gli elementi sono dati aggiunti al contenitore. Sono rappresentati come documenti, righe, nodi o contorni. Tutti gli elementi aggiunti a un contenitore vengono indicizzati automaticamente.
Per partizionare il contenitore, gli elementi sono suddivisi in subset denominati partizioni logiche. Le partizioni logiche vengono popolate in base al valore di una chiave di partizione associata a ogni elemento in un contenitore. La figura 5-14 mostra due contenitori, ciascuno con una partizione logica basata su un valore di chiave di partizione.
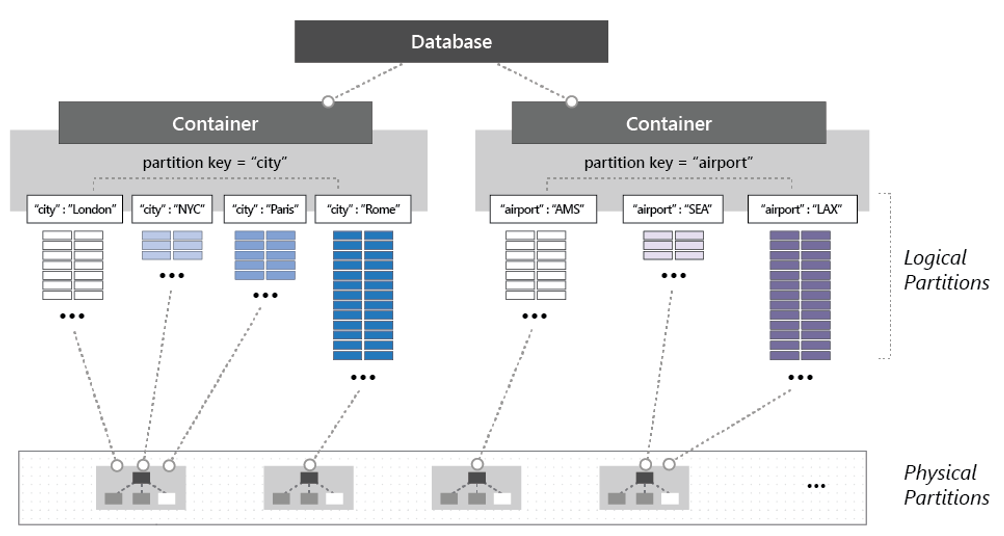
Figura 5-14: Meccanismi di partizionamento di Cosmos DB
Nella figura precedente, notare come ogni elemento include una chiave di partizione o di "città" o di "aeroporto". La chiave determina la partizione logica dell'elemento. Gli elementi con un codice città vengono assegnati al contenitore a sinistra e quelli con un codice aeroporto vengono assegnati al contenitore a destra. La combinazione del valore della chiave di partizione e del valore ID crea l'indice di un elemento, che identifica l’elemento in modo univoco.
Internamente, Cosmos DB gestisce automaticamente il posizionamento di partizioni logiche in partizioni fisiche per soddisfare le esigenze di scalabilità e di prestazione del contenitore. Man mano che i requisiti di velocità effettiva e archiviazione dell'applicazione aumentano, Azure Cosmos DB ridistribuisce le partizioni logiche in un numero maggiore di server. Le operazioni di ridistribuzione vengono gestite da Cosmos DB e sono eseguite senza interruzioni o tempi di inattività.
Database NewSQL
NewSQL è una tecnologia di database emergente che combina la scalabilità distribuita di NoSQL con le garanzie ACID di un database relazionale. I database NewSQL sono importanti per sistemi aziendali che devono elaborare volumi elevati di dati, tra ambienti distribuiti, con supporto transazionale completo e conformità ACID. Anche se un database NoSQL può offrire scalabilità elevata, non garantisce la coerenza di dati. Problemi intermittenti causati da dati incoerenti possono comportare un onere per il team di sviluppo. Gli sviluppatori devono costruire misure di sicurezza nel codice del microservizio per gestire i problemi causati da dati incoerenti.
Cloud Native Computing Foundation (CNF) include diversi progetti di database NewSQL.
| Progetto | Caratteristiche |
|---|---|
| CockroachDB | Un database relazionale conforme ad ACID, ridimensionato a livello globale. Quando si aggiunge un nuovo nodo a un cluster, CockroachDB si occupa di gestire il bilanciamento dei dati tra istanze e aree geografiche. Crea, gestisce e distribuisce repliche per garantire affidabilità. È open source e disponibile gratuitamente. |
| TiDB | Un database open source che supporta carichi di lavoro Hybrid Transactional and Analytical Processing (HTAP). È compatibile con MySQL e offre scalabilità orizzontale, coerenza assoluta e disponibilità elevata. TiDB funge da server MySQL. È possibile continuare a usare librerie client MySQL esistenti, senza richiedere ampie modifiche al codice per l'applicazione. |
| YugabyteDB | Un database SQL distribuito open source e ad alte prestazoni. Supporta bassa latenza di query, resilienza in caso di errori e distribuzione globale dei dati. YugabyteDB è compatibile con PostgreSQL e gestisce carichi di lavoro RDBMS e OLTP su larga scala. Il prodotto supporta anche NoSQL ed è compatibile con Cassandra. |
| Vitess | Vitess è una soluzione di database per la distribuzione, il ridimensionamento e la gestione di cluster di grandi dimensioni di istanze MySQL. Può essere usato in un'architettura di cloud pubblica o privata. Vitess combina ed estende molte importanti funzionalità di MySQL e supporta sia il partizionamento orizzontale che verticale. Originato da YouTube, Vitess ha servito tutto il traffico di database di YouTube a partire dal 2011. |
I progetti open source nella figura precedente sono resi disponibili dalla Cloud Native Computing Foundation. Tre delle offerte sono prodotti di database completi che includono il supporto di .NET. L'altra, Vitess, è un sistema di clustering di database che ridimensiona orizzontalmente cluster di grandi dimensioni di istanze MySQL.
Un obiettivo chiave di progettazione per i database NewSQL consiste nel lavorare a livello nativo in Kubernetes, sfruttando la resilienza e la scalabilità della piattaforma.
I database NewSQL sono progettati per prosperare in ambienti cloud temporanei in cui è possibile riavviare o riprogrammare le macchine virtuali sottostanti in qualsiasi momento. I database sono progettati per sopravvivere agli errori di nodi senza perdita di dati né tempi di inattività. CockroachDB, ad esempio, è in grado di sopravvivere alla perdita di un computer mantenendo tre repliche coerenti di tutti i dati tra i nodi di un cluster.
Kubernetes usa un costrutto di servizi per consentire a un client di gestire un gruppo di processi di database NewSQL identici tramite una singola voce DNS. Separando le istanze del database dall'indirizzo del servizio a cui è associato, è possibile effettuare il ridimensionamento senza interrompere le istanze dell'applicazione esistenti. L'invio di una richiesta a qualsiasi servizio in un determinato momento restituirà sempre lo stesso risultato.
In questo scenario, tutte le istanze del database sono uguali. Non esistono relazioni primarie o secondarie. Tecniche come la replica di consenso in CockroachDB consentono a qualsiasi nodo del database di gestire qualsiasi richiesta. Se il nodo che riceve una richiesta con carico bilanciato possiede i dati necessari localmente, risponderà immediatamente. In caso contrario, il nodo diventerà un gateway e inoltrerà la richiesta ai nodi idonei per ottenere la risposta corretta. Dal punto di vista del client, ogni nodo del database è uguale: tutti appaiono come un singolo database logico con le garanzie di coerenza di un sistema a computer singolo, nonostante abbiano decine o persino centinaia di nodi al lavoro dietro le quinte.
Per un'analisi dettagliata dei meccanismi alla base dei database NewSQL, consultare l'articolo DASH: quattro proprietà dei database nativi di Kubernetes.
Migrazione dei dati al cloud
Una delle attività che richiedono più tempo è la migrazione di dati da una piattaforma dati a un'altra. Il Servizio migrazione dei dati di Azure consente di accelerare tali sforzi. Può eseguire la migrazione di dati da diverse fonti esterne di database alle piattaforme dati di Azure con tempi di inattività minimi. Le piattaforme di destinazione includono i seguenti servizi:
- Database SQL di Microsoft Azure
- Database di Azure per MySQL
- Database di Azure per MariaDB
- Database di Azure per PostgreSQL
- Azure Cosmos DB, un servizio di database distribuito globale di Microsoft
Il servizio fornisce indicazioni su come effettuare le modifiche necessarie per eseguire una migrazione, sia di piccole che di grandi dimensioni.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.