Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come creare un modello di rilevamento oggetti usando ML.NET Model Builder e Azure Machine Learning per rilevare e individuare le immagini di arresto.
In questa esercitazione verranno illustrate le procedure per:
- Preparare e identificare i dati
- Creare un file di configurazione di Model Builder
- Scegliere lo scenario
- Scegliere l'ambiente di training
- Caricare i dati
- Eseguire il training del modello
- Valutare il modello
- Usare il modello per le stime
Prerequisiti
Per un elenco dei prerequisiti e delle istruzioni di installazione, vedere la guida all'installazione di Model Builder.
Panoramica del rilevamento oggetti di Model Builder
Il rilevamento degli oggetti è una questione correlata alla visione artificiale. Sebbene sia un concetto strettamente correlato alla classificazione delle immagini, il rilevamento degli oggetti esegue l'operazione di classificazione delle immagini su scala più granulare. Il rilevamento degli oggetti individua e classifica le entità all'interno delle immagini. I modelli di rilevamento oggetti vengono comunemente sottoposti a training usando deep learning e reti neurali. Per altre informazioni, vedere Deep Learning e Machine Learning .
Usare il rilevamento degli oggetti quando le immagini contengono più oggetti di tipi diversi.

Ecco alcuni casi d'uso per il rilevamento degli oggetti:
- Auto senza guidatore
- Robotica
- Rilevamento viso
- Sicurezza nell'ambiente di lavoro
- Conteggio di oggetti
- Riconoscimento di attività
Questo esempio crea un'applicazione console .NET Core C# che rileva l'arresto delle immagini usando un modello di Machine Learning creato con Model Builder. È possibile trovare il codice sorgente per questa esercitazione nel repository GitHub dotnet/machinelearning-samples .
Preparare e identificare i dati
Il set di dati Stop Sign è costituito da 50 immagini scaricate da Unsplash, ognuna delle quali contiene almeno un segno di arresto.
Creare un nuovo progetto VoTT
Scaricare il set di dati di 50 immagini di segno di arresto e decomprimere.
Scaricare VoTT (Visual Object Tagging Tool).
Aprire VoTT e selezionare Nuovo progetto.
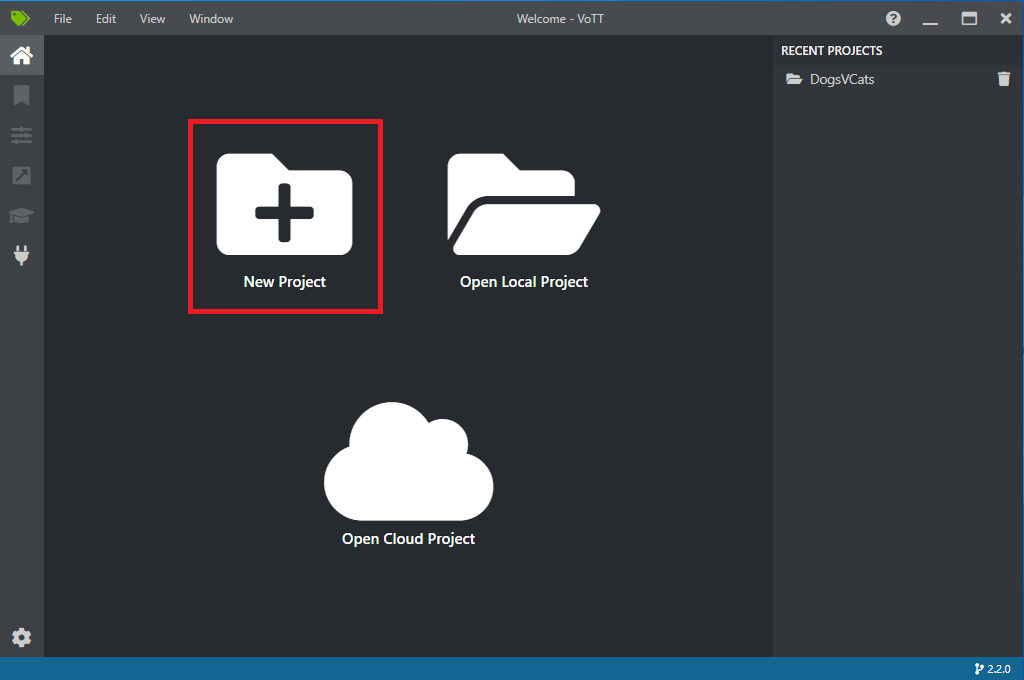
In Impostazioni progetto modificare il nome visualizzato in "StopSignObjDetection".
Modificare il token di sicurezza per generare un nuovo token di sicurezza.
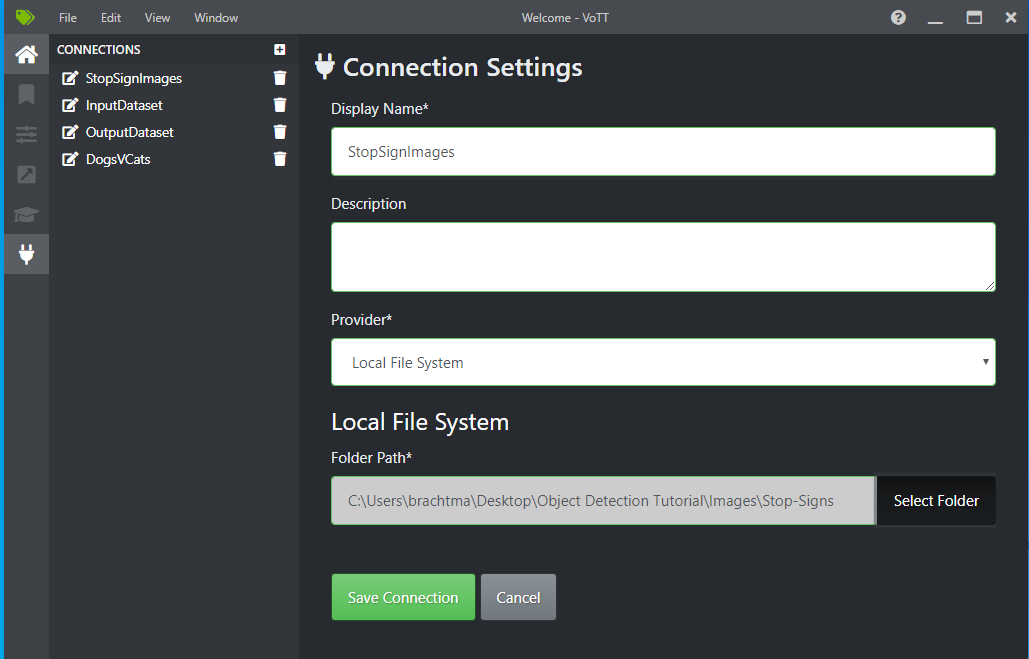
Accanto a Connessione di origine selezionare Aggiungi connessione.
In Impostazioni di connessione modificare il nome visualizzato per la connessione di origine a "StopSignImages" e selezionare File system locale come provider. Per Percorso cartella selezionare la cartella Stop-Sign contenente le 50 immagini di training e quindi selezionare Salva connessione.
In Impostazioni progetto modificare la connessione di origine a StopSignImages (la connessione appena creata).
Modificare anche la connessione di destinazione in StopSignImages . Le impostazioni del progetto dovrebbero ora essere simili a questa schermata:
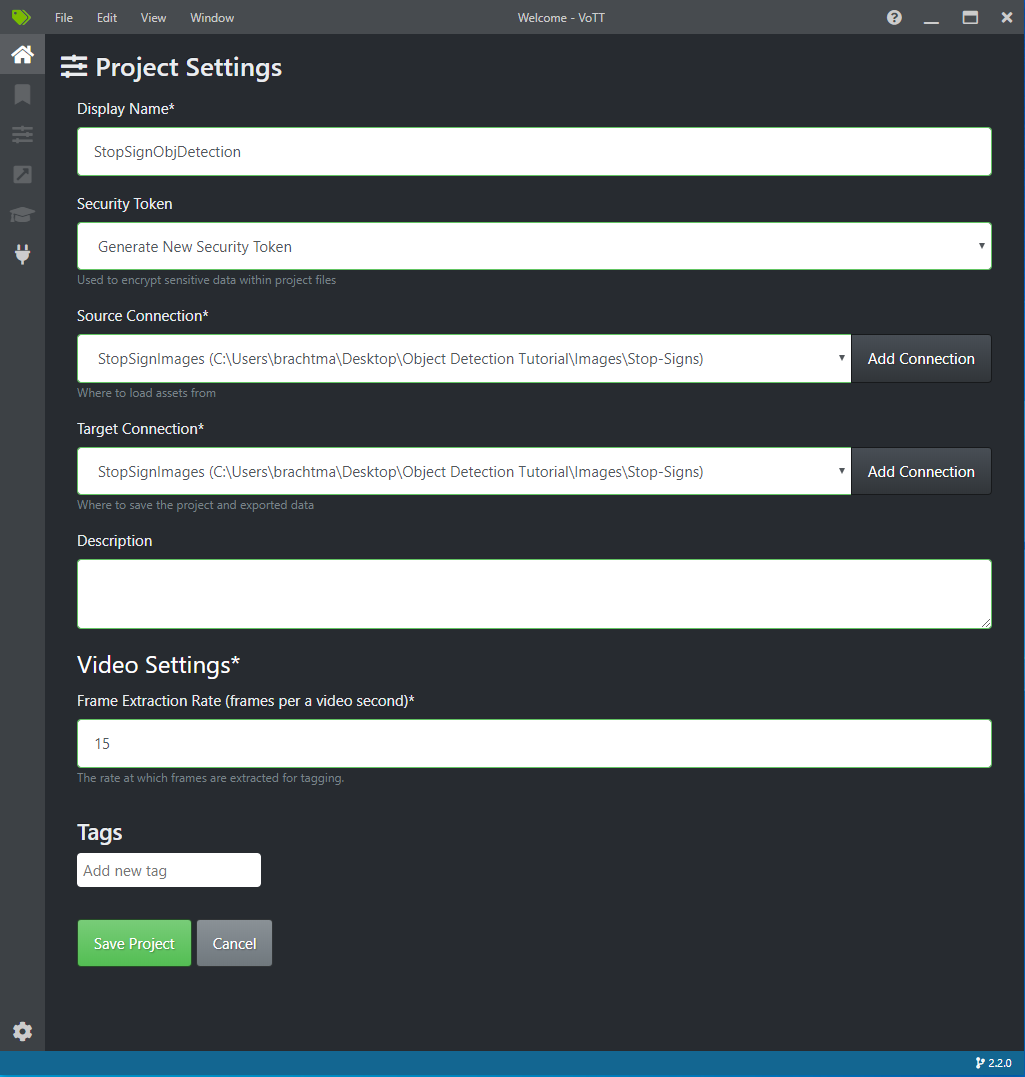
Selezionare Salva progetto.
Aggiungere immagini di tag e etichette
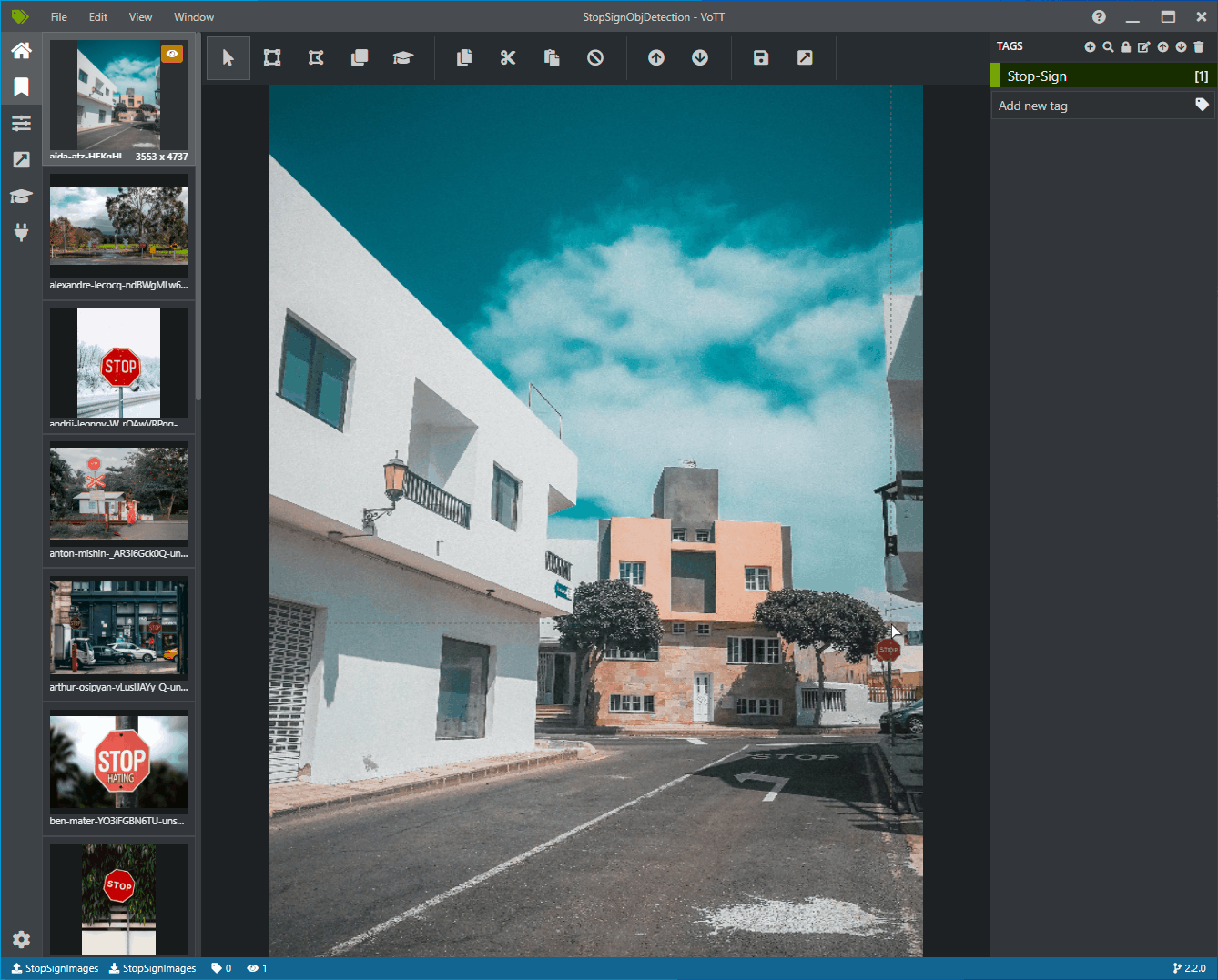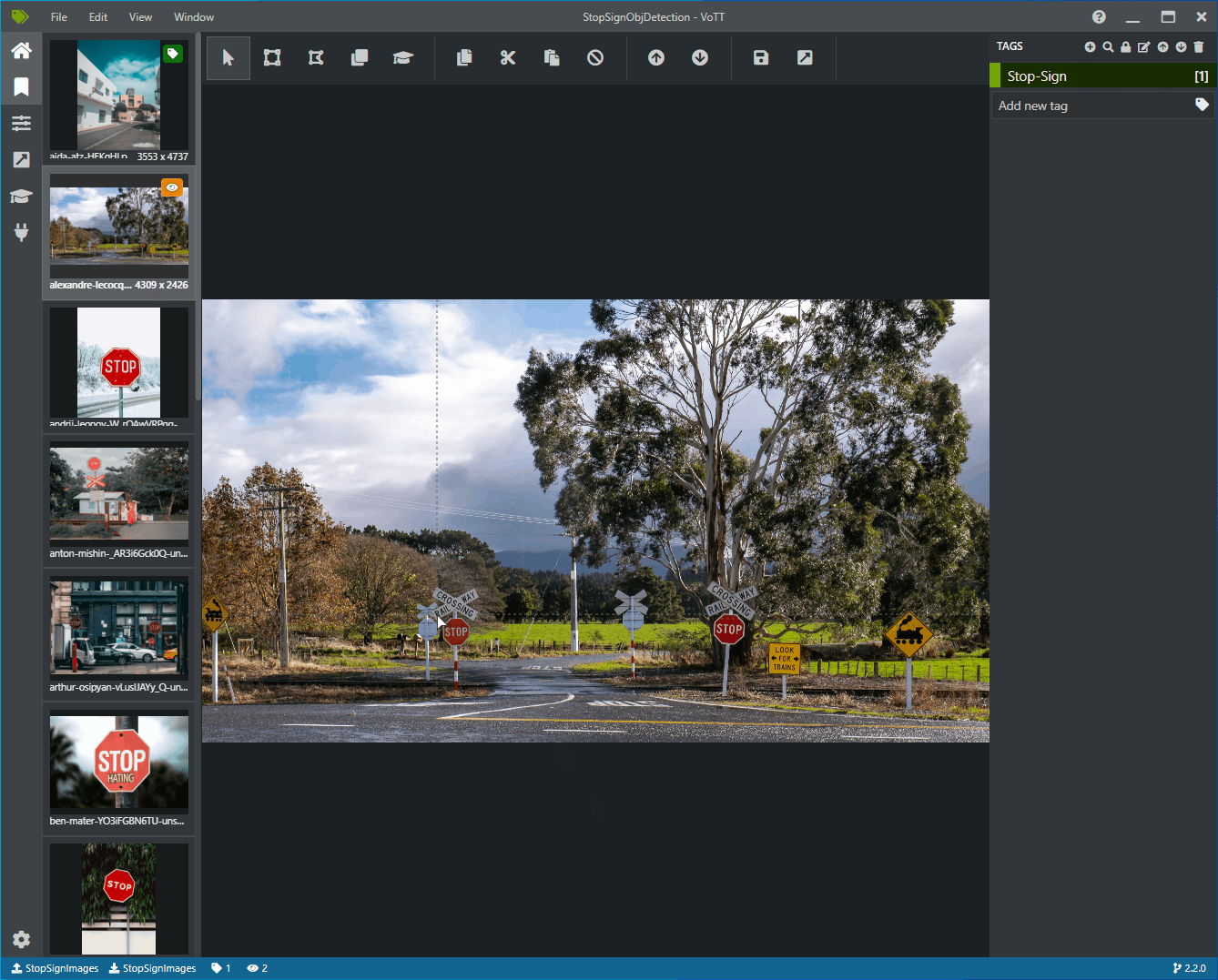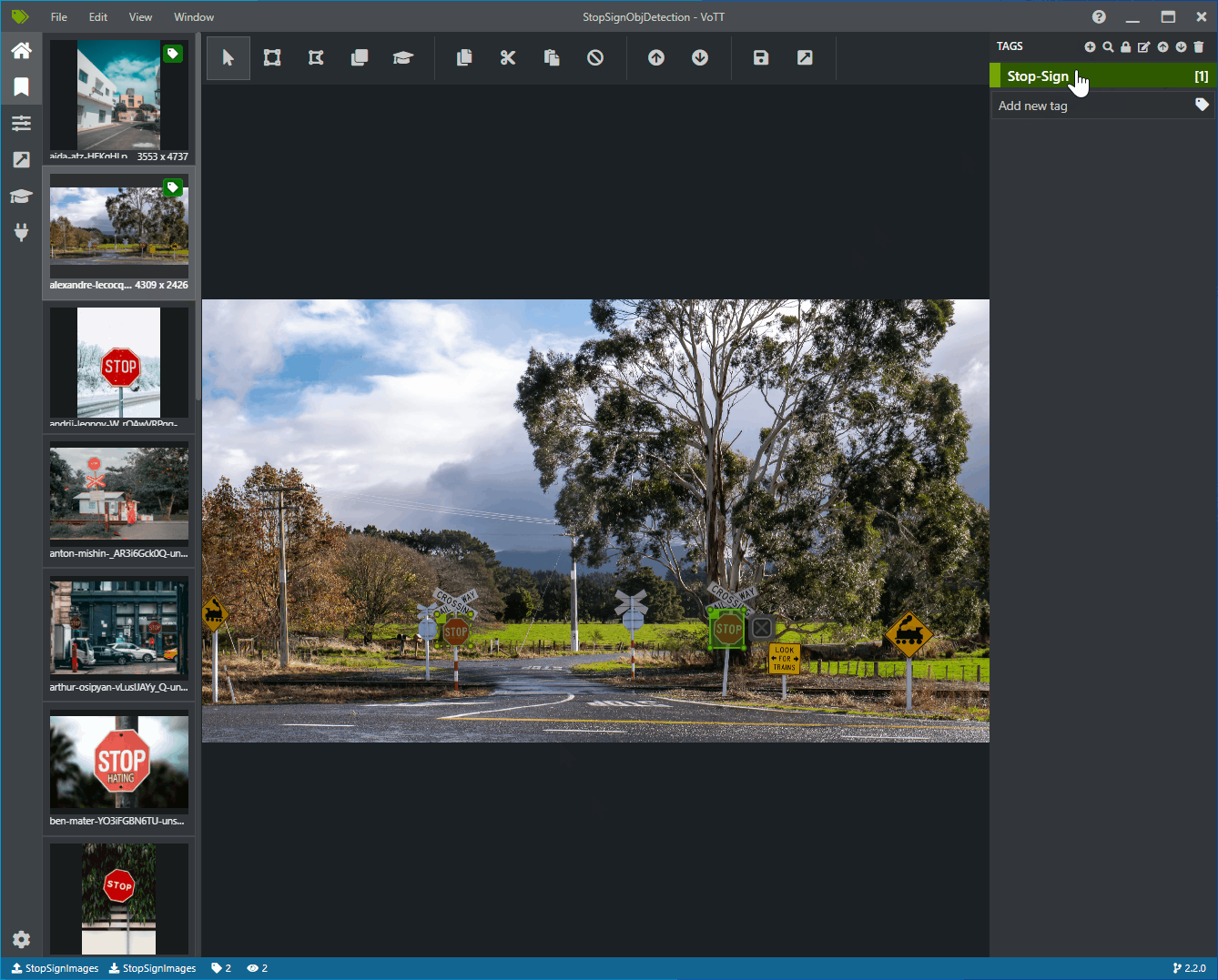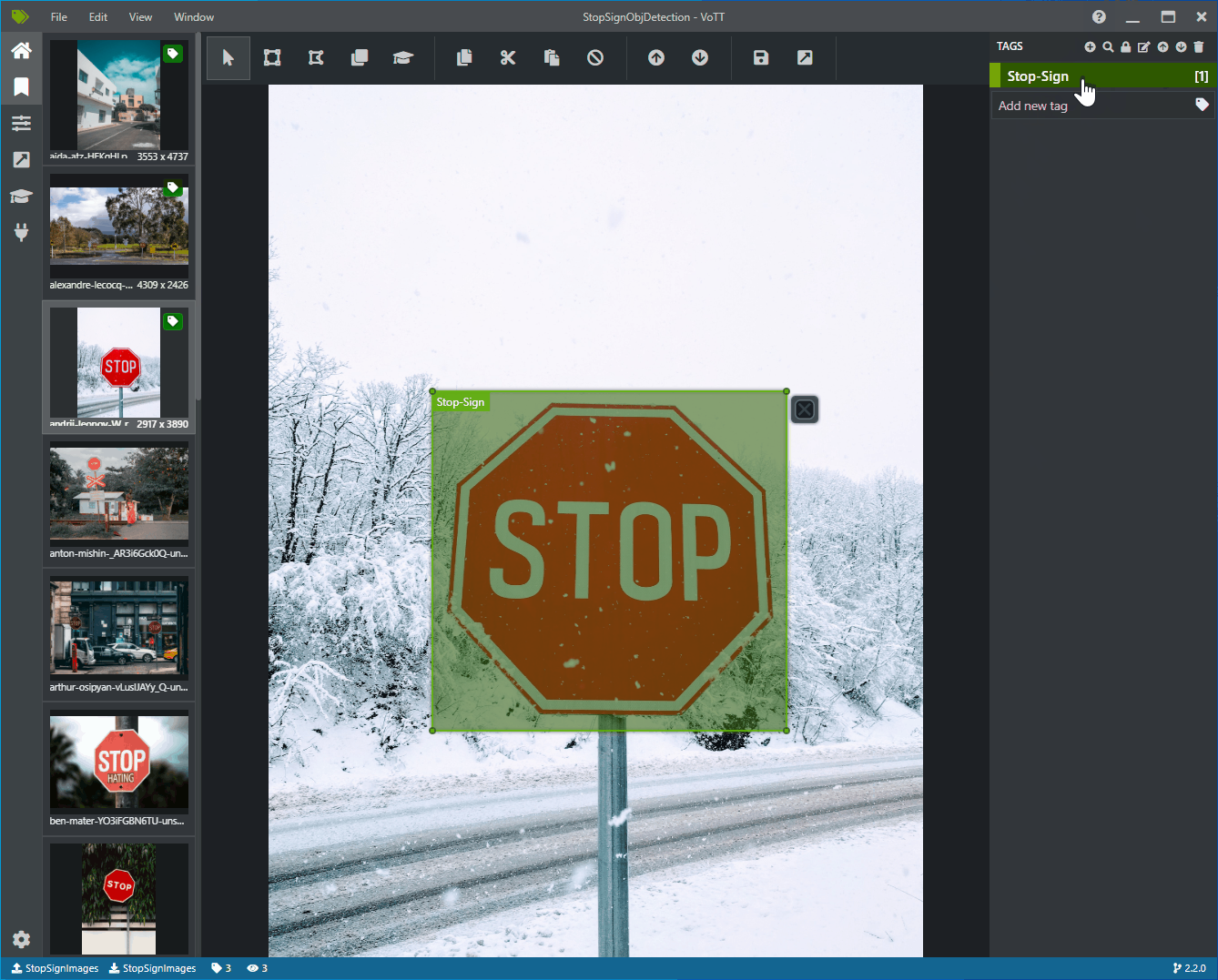
Verrà ora visualizzata una finestra con immagini di anteprima di tutte le immagini di training a sinistra, un'anteprima dell'immagine selezionata al centro e una colonna Tag a destra. Questa schermata è l'editor Tag.
Selezionare la prima icona (con forma più) nella barra degli strumenti Tag per aggiungere un nuovo tag.

Assegnare al tag il nome "Stop-Sign" e premere INVIO sulla tastiera.

Fare clic e trascinare per disegnare un rettangolo attorno a ogni segno di arresto nell'immagine. Se il cursore non consente di disegnare un rettangolo, provare a selezionare lo strumento Disegna rettangolo dalla barra degli strumenti in alto o usare il tasto di scelta rapida R.
Dopo aver disegnato il rettangolo, selezionare il tag Stop-Sign creato nei passaggi precedenti per aggiungere il tag al rettangolo di selezione.
Fare clic sull'immagine di anteprima per l'immagine successiva nel set di dati e ripetere questo processo.
Continuare i passaggi da 3 a 4 per ogni accesso di arresto in ogni immagine.
Esportare il file JSON VoTT
Dopo aver etichettato tutte le immagini di training, è possibile esportare il file che verrà usato da Model Builder per il training.
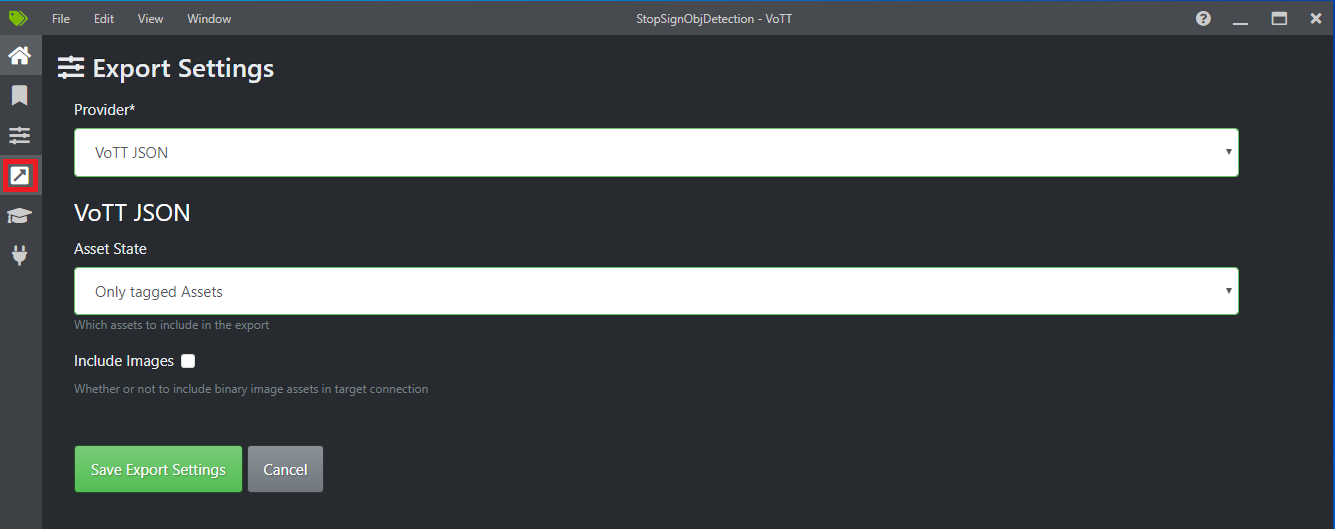
Selezionare la quarta icona sulla barra degli strumenti a sinistra (quella con la freccia diagonale in una casella) per passare alle impostazioni di esportazione.
Lasciare il provider come JSON VoTT.
Modificare lo stato dell'asset in Solo asset contrassegnati.
Deselezionare Includi immagini. Se si includono le immagini, le immagini di training verranno copiate nella cartella di esportazione generata, che non è necessaria.
Selezionare Salva impostazioni di esportazione.
Indietro all'editor Tag (la seconda icona nella barra degli strumenti sinistra a forma di barra multifunzione). Nella barra degli strumenti superiore selezionare l'icona Esporta progetto (l'ultima icona a forma di freccia in una casella) oppure usare i tasti di scelta rapida CTRL+E.

Questa esportazione creerà una nuova cartella denominata vott-json-export nella cartella Stop-Sign-Images e genererà un file JSON denominato StopSignObjDetection-export in tale nuova cartella. Questo file JSON verrà usato nei passaggi successivi per il training di un modello di rilevamento oggetti in Generatore modelli.
Creare un'applicazione console
In Visual Studio creare un'applicazione console .NET Core C# denominata StopSignDetection.
Creare un mbconfig file
- In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto StopSignDetection e scegliere Aggiungi>modello di Machine Learning per aprire l'interfaccia utente di Generatore modelli.
- Nella finestra di dialogo assegnare al progetto Model Builder il nome StopSignDetection e fare clic su Aggiungi.
Scegliere uno scenario
Per questo esempio, lo scenario è rilevamento oggetti. Nel passaggio Scenario di Generatore modelli selezionare lo scenario rilevamento oggetti .
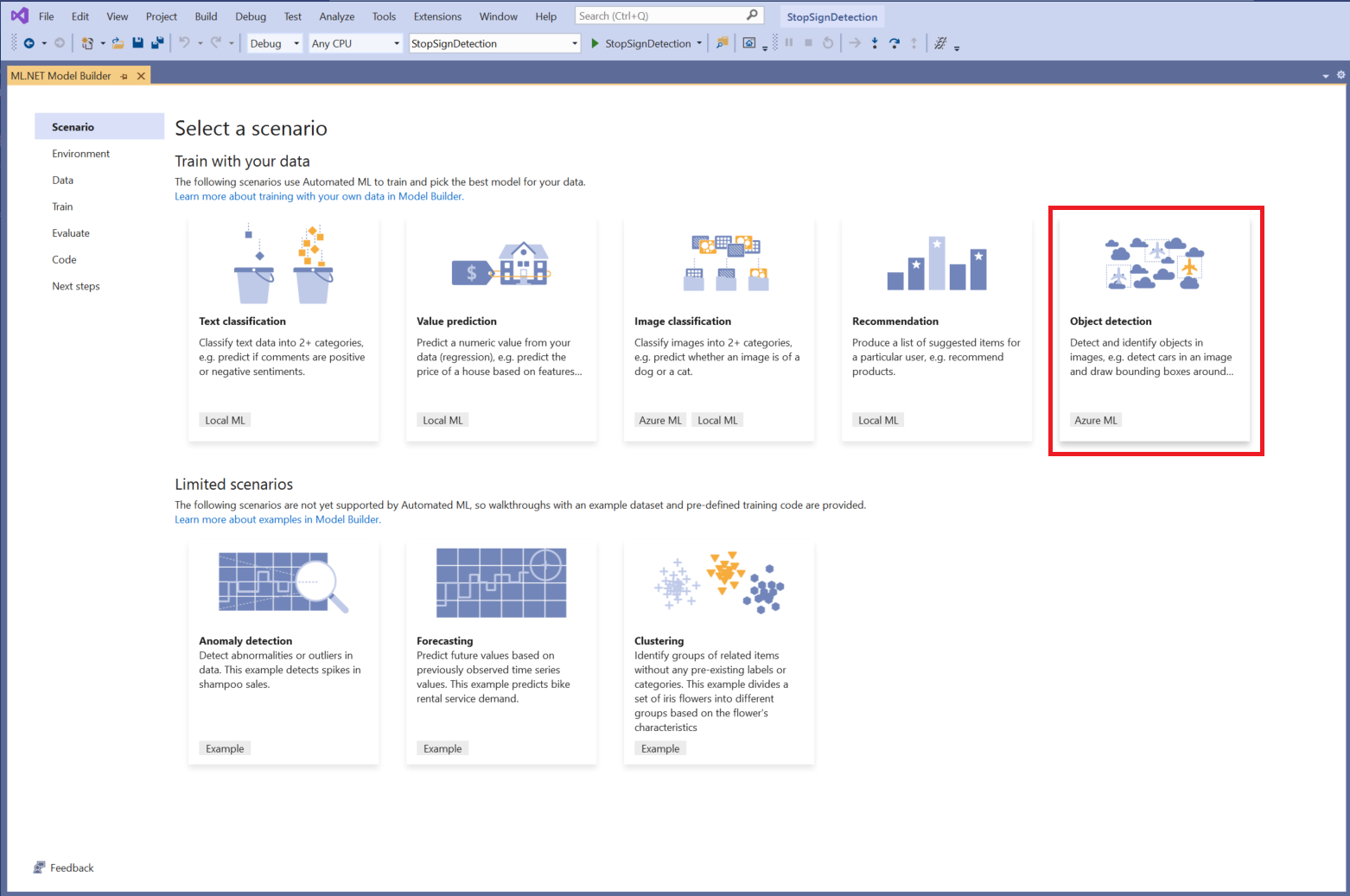
Se il rilevamento oggetti non viene visualizzato nell'elenco degli scenari, potrebbe essere necessario aggiornare la versione di Model Builder.
Scegliere l'ambiente di training
Attualmente Model Builder supporta i modelli di rilevamento oggetti di training solo con Azure Machine Learning, quindi l'ambiente di training di Azure è selezionato per impostazione predefinita.
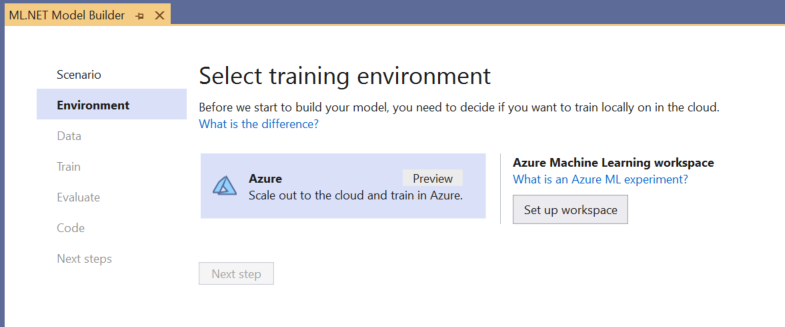
Per eseguire il training di un modello usando Azure ML, è necessario creare un esperimento di Azure ML da Model Builder.
Un esperimento di Azure ML è una risorsa che incapsula la configurazione e i risultati per una o più esecuzioni di training di Machine Learning.
Per creare un esperimento di Azure ML, è prima necessario configurare l'ambiente in Azure. Per eseguire un esperimento è necessario quanto segue:
- Una sottoscrizione di Azure
- Un'area di lavoro: una risorsa di Azure ML che fornisce una posizione centrale per tutte le risorse e gli artefatti di Azure ML creati come parte di un'esecuzione di training.
- Un ambiente di calcolo: un ambiente di calcolo di Azure Machine Learning è una macchina virtuale Linux basata sul cloud usata per il training. Altre informazioni sui tipi di calcolo supportati da Generatore modelli.
Configurare un'area di lavoro di Azure ML
Per configurare l'ambiente:
Selezionare il pulsante Configura area di lavoro .
Nella finestra di dialogo Crea nuovo esperimento selezionare la sottoscrizione di Azure.
Selezionare un'area di lavoro esistente o creare una nuova area di lavoro di Azure ML.
Quando si crea una nuova area di lavoro, viene effettuato il provisioning delle risorse seguenti:
- Area di lavoro di Azure Machine Learning
- Archiviazione di Azure
- Azure Application Insights
- Registro Azure Container
- Insieme di credenziali chiave di Azure
Di conseguenza, questo processo può richiedere alcuni minuti.
Selezionare un ambiente di calcolo esistente o creare un nuovo ambiente di calcolo di Azure ML. Il processo potrebbe richiedere alcuni minuti.
Lasciare il nome predefinito dell'esperimento e selezionare Crea.
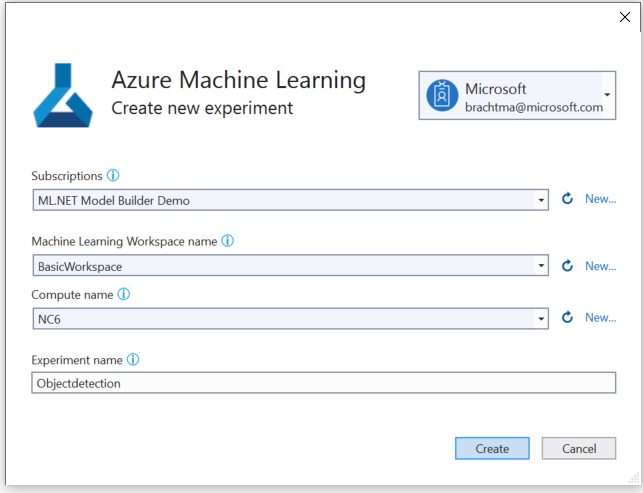
Viene creato il primo esperimento e il nome dell'esperimento viene registrato nell'area di lavoro. Tutte le esecuzioni successive (se viene usato lo stesso nome dell'esperimento ) vengono registrate come parte dello stesso esperimento. In caso contrario, viene creato un nuovo esperimento.
Se si è soddisfatti della configurazione, selezionare il pulsante Passaggio successivo in Generatore modelli per passare al passaggio Dati .
Caricare i dati
Nel passaggio Dati di Generatore modelli selezionare il set di dati di training.
Importante
Model Builder attualmente accetta solo il formato JSON generato da VoTT.
Selezionare il pulsante all'interno della sezione Input e usare il Esplora file per trovare l'elemento
StopSignObjDetection-export.jsonche deve trovarsi nella directory Stop-Sign/vott-json-export.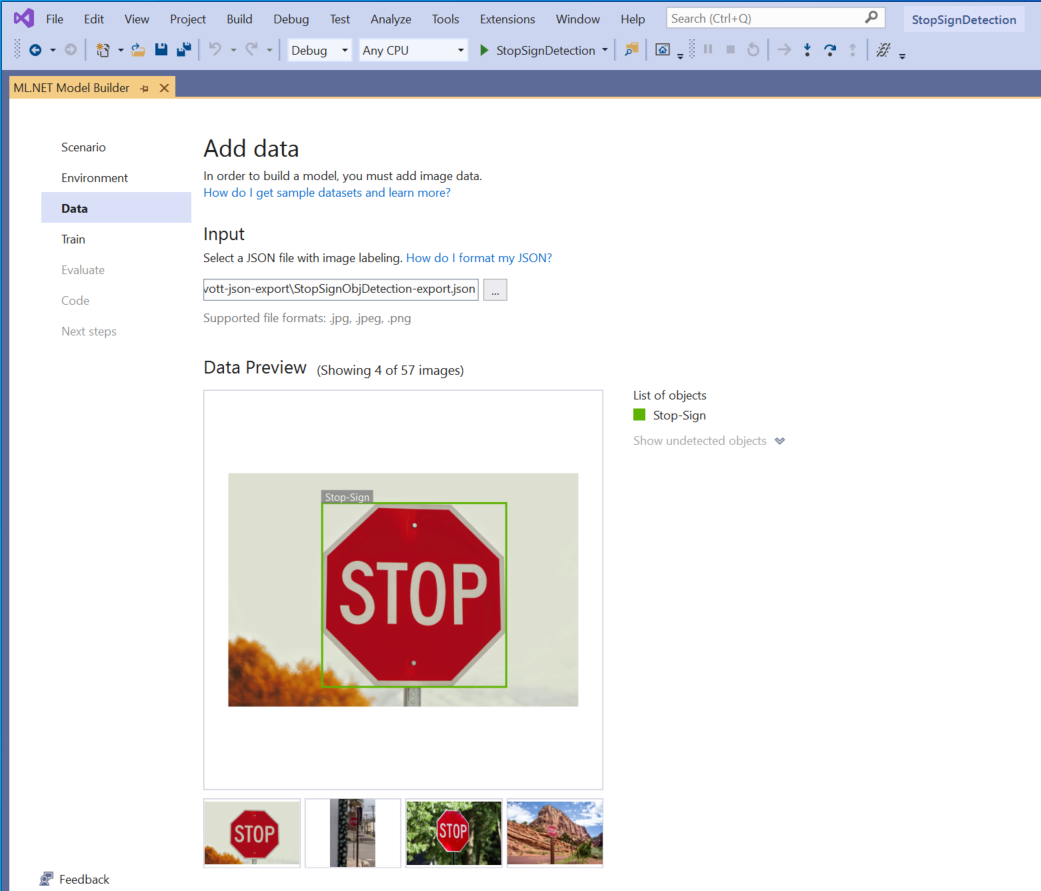
Se i dati sono corretti nell'anteprima dei dati, selezionare Passaggio successivo per passare al passaggio Esegui training.
Eseguire il training del modello
Il passaggio successivo consiste nel eseguire il training del modello.
Nella schermata Training di Generatore modelli selezionare il pulsante Avvia training .
A questo punto, i dati vengono caricati in Archiviazione di Azure e il processo di training inizia in Azure ML.
Il processo di training richiede tempo e la quantità di tempo può variare a seconda delle dimensioni di calcolo selezionate e della quantità di dati. La prima volta che viene eseguito il training di un modello in Azure, è possibile prevedere un tempo di training leggermente più lungo perché è necessario effettuare il provisioning delle risorse. Per questo esempio di 50 immagini, il training ha richiesto circa 16 minuti.
È possibile tenere traccia dello stato di avanzamento delle esecuzioni nel portale di Azure Machine Learning selezionando il collegamento Monitoraggio esecuzione corrente in portale di Azure in Visual Studio.
Al termine del training, selezionare il pulsante Passaggio successivo per passare al passaggio Valuta .
Valutare il modello
Nella schermata Valuta viene visualizzata una panoramica dei risultati del processo di training, inclusa l'accuratezza del modello.
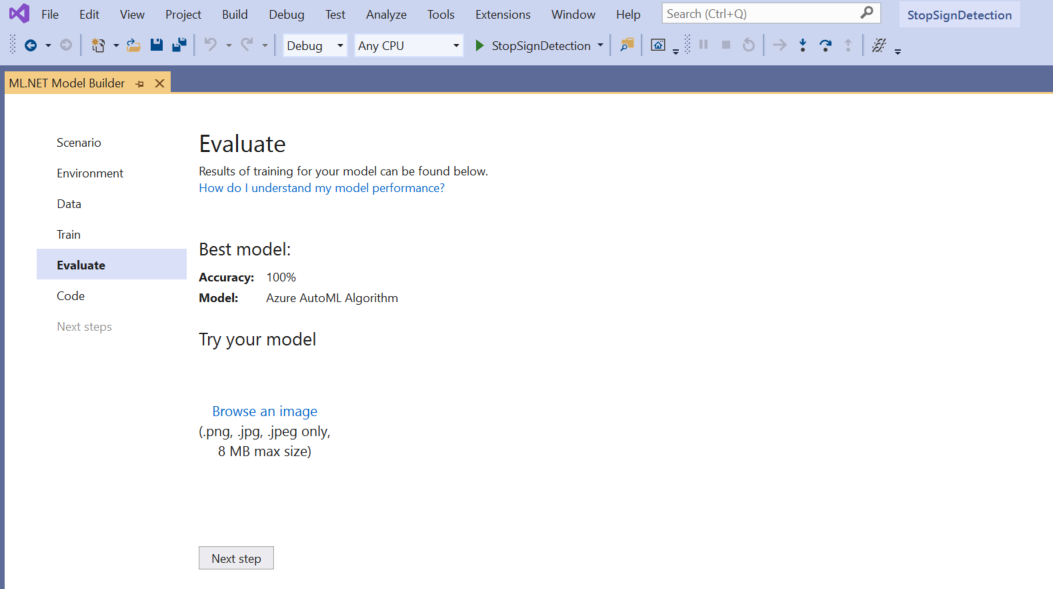
In questo caso, l'accuratezza indica il 100%, il che significa che il modello è più di probabile overfit a causa di un numero eccessivo di immagini nel set di dati.
È possibile usare l'esperienza Provare il modello per verificare rapidamente se il modello funziona come previsto.
Selezionare Sfoglia un'immagine e specificare un'immagine di test, preferibilmente quella che il modello non ha usato come parte del training.
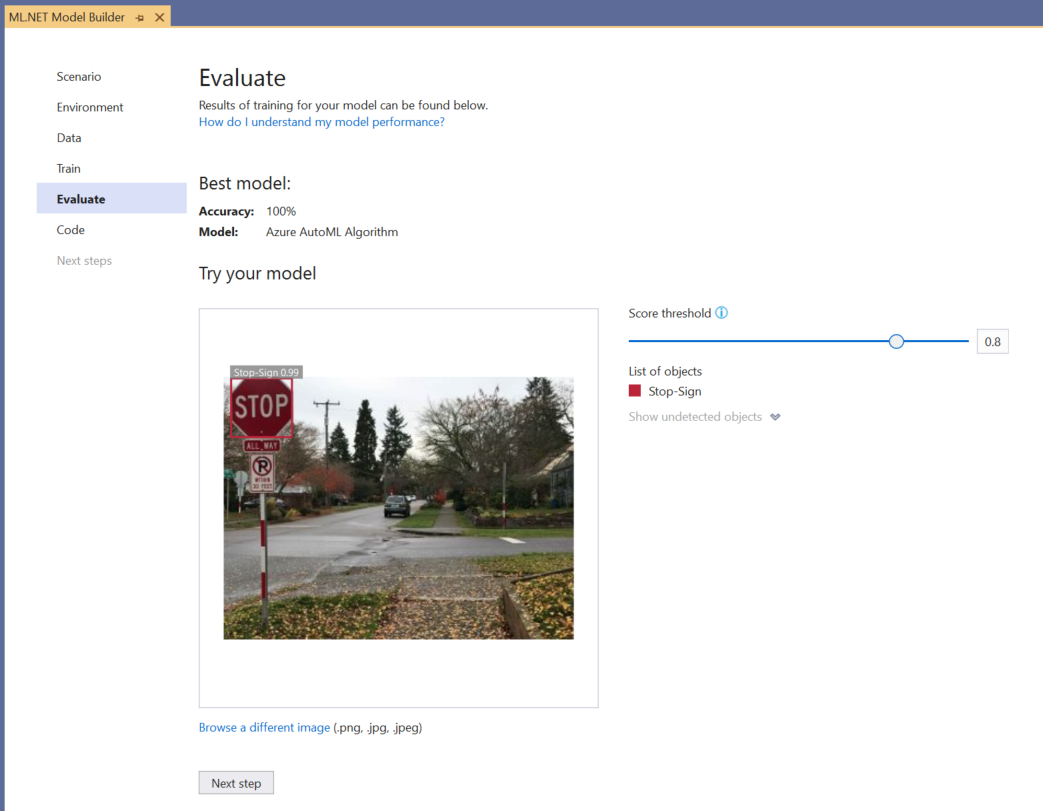
Il punteggio visualizzato in ogni rettangolo di selezione rilevato indica l'attendibilità dell'oggetto rilevato. Ad esempio, nello screenshot precedente, il punteggio del riquadro intorno al segno di arresto indica che il modello è sicuro del 99% che l'oggetto rilevato sia un segno di arresto.
La soglia score, che può essere aumentata o ridotta con il dispositivo di scorrimento soglia, aggiunge e rimuove gli oggetti rilevati in base ai punteggi. Ad esempio, se la soglia è 51, il modello mostrerà solo gli oggetti con un punteggio di attendibilità pari a 51 o superiore. Man mano che si aumenta la soglia, verranno visualizzati oggetti meno rilevati e man mano che si riduce la soglia, verranno visualizzati più oggetti rilevati.
Se non si è soddisfatti delle metriche di accuratezza, un modo semplice per provare a migliorare l'accuratezza del modello consiste nell'usare più dati. In caso contrario, selezionare il collegamento Passaggio successivo per passare al passaggio Utilizzo in Generatore modelli.
(Facoltativo) Utilizzare il modello
Questo passaggio includerà modelli di progetto che è possibile usare per utilizzare il modello. Questo passaggio è facoltativo ed è possibile scegliere il metodo più adatto alle proprie esigenze su come gestire il modello.
- App console
- API Web
App console
Quando si aggiunge un'app console alla soluzione, verrà richiesto di denominare il progetto.
Assegnare al progetto il nome StopSignDetection_Console.
Fare clic su Aggiungi alla soluzione per aggiungere il progetto alla soluzione corrente.
Eseguire l'applicazione.
L'output generato dal programma dovrebbe essere simile al frammento di codice seguente:
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
API Web
Quando si aggiunge un'API Web alla soluzione, verrà richiesto di denominare il progetto.
Assegnare al progetto API Web il nome StopSignDetection_API.
Fare clic su Aggiungi alla soluzione per aggiungere il progetto alla soluzione corrente.
Eseguire l'applicazione.
Aprire PowerShell e immettere il codice seguente in cui PORT è la porta su cui è in ascolto l'applicazione.
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"In caso di esito positivo, l'output dovrebbe essere simile al testo seguente.
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}- La
boxescolonna fornisce le coordinate del rettangolo di delimitazione dell'oggetto rilevato. I valori qui appartengono rispettivamente alle coordinate sinistra, superiore, destra e inferiore. - Sono
labelsl'indice delle etichette stimate. In questo caso, il valore 1 è un segno di arresto. - Definisce
scoresil modo in cui il modello è sicuro che il rettangolo di selezione appartiene a tale etichetta.
Nota
(Facoltativo) Le coordinate del rettangolo di selezione vengono normalizzate per una larghezza di 800 pixel e un'altezza di 600 pixel. Per ridimensionare le coordinate del rettangolo delimitatore per l'immagine in un'ulteriore post-elaborazione, è necessario:
- Moltiplicare le coordinate superiore e inferiore in base all'altezza dell'immagine originale e moltiplicare le coordinate sinistra e destra per la larghezza dell'immagine originale.
- Dividere le coordinate superiore e inferiore per 600 e dividere le coordinate di sinistra e destra per 800.
Ad esempio, date le dimensioni
actualImageHeightoriginali dell'immagine eactualImageWidth, e unModelOutputdenominatoprediction, il frammento di codice seguente mostra come ridimensionare leBoundingBoxcoordinate:var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;Un'immagine può avere più di un rettangolo di selezione, quindi lo stesso processo deve essere applicato a ognuno dei rettangoli di selezione nell'immagine.
- La
Congratulazioni! È stato creato un modello di Machine Learning per rilevare l'arresto delle immagini usando Model Builder. È possibile trovare il codice sorgente per questa esercitazione nel repository GitHub dotnet/machinelearning-samples .
Risorse aggiuntive
Per altre informazioni sugli argomenti presentati in questa esercitazione, vedere le risorse seguenti:
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.