Modifiche alla disponibilità elevata e alla resilienza del sito rispetto alle versioni precedenti di Exchange Server
Exchange Server 2013 e versioni successive usa dag e copie del database delle cassette postali (insieme ad altre funzionalità come il ripristino di un singolo elemento, i criteri di conservazione e le copie ritardate del database) per garantire disponibilità elevata, resilienza del sito e protezione dei dati nativa di Exchange. La piattaforma a disponibilità elevata, Exchange Information Store ed Extensible Storage Engine (ESE) sono stati tutti migliorati da Exchange 2010 per offrire disponibilità e una gestione meno complessa e per ridurre i costi. Questi miglioramenti includono:
Riduzione delle operazioni di I/O al secondo: ciò consente di usare dischi di dimensioni maggiori in termini di capacità e operazioni di I/O al secondo nel modo più efficiente possibile.
Disponibilità gestita: con la disponibilità gestita, il monitoraggio interno e le funzionalità orientate al ripristino sono strettamente integrate per evitare errori, ripristinare in modo proattivo i servizi e avviare automaticamente i failover del server o avvisare gli amministratori di intervenire. L'attenzione si concentra sul monitoraggio e sulla gestione dell'esperienza dell'utente finale piuttosto che sui tempi di attività del server e dei componenti per mantenere il servizio sempre disponibile.
Archivio gestito: l'archivio gestito è il nome dei processi di Archivio informazioni riscritti in Exchange 2013 o versioni successive. L'archivio gestito è scritto in C# e strettamente integrato con il servizio Replica di Microsoft Exchange (MSExchangeRepl.exe) per garantire una maggiore disponibilità grazie a una resilienza migliorata.
Supporto per più database per disco: i miglioramenti consentono di supportare più database (combinazioni di copie attive e passive) sullo stesso disco, usando quindi dischi più grandi in termini di capacità e operazioni di I/O al secondo nel modo più efficiente possibile.
AutoReseed: la funzionalità di reseeding automatico consente di ripristinare rapidamente la ridondanza del database dopo l'errore del disco. Se un disco è in errore, la copia del database archiviata su quel disco viene copiata dalla copia del database attiva a un disco di riserva sullo stesso server. Se nel disco danneggiato sono state archiviate più copie di database, queste possono essere sottoposte automaticamente a reseeding su un disco di riserva. In questo modo si accelera il reseeding poiché è probabile che i database attivi si trovino su più server e i dati vengano copiati in parallelo.
Ripristino automatico dagli errori di archiviazione: questa funzionalità prosegue le innovazioni introdotte in Exchange 2010 per consentire il ripristino del sistema in caso di errori che agiscono sulla resilienza o sulla ridondanza. Exchange include ora più comportamenti di ripristino per tempi di I/O lunghi, un consumo eccessivo di memoria per MSExchangeRepl.exe e casi gravi in cui il sistema si trova in uno stato non valido che i thread non possono essere pianificati.
Miglioramenti delle copie ritardate: le copie in ritardo possono ora prendersi cura di se stesse in una certa misura usando il play-down automatico del log. Le copie in ritardo riproduceranno automaticamente i file di log in varie situazioni, ad esempio l'applicazione di patch alle pagine e scenari di spazio su disco insufficiente. Se il sistema rileva che l'applicazione di patch alle pagine è necessaria per una copia ritardata, i log verranno riprodotti automaticamente nella copia ritardata per eseguire l'applicazione di patch alle pagine. Le copie isolate richiameranno inoltre la funzione di riproduzione automatica al raggiungimento della soglia di spazio insufficiente su disco e al rilevamento della copia isolata come unica disponibile per un periodo di tempo specifico. Inoltre, le copie in ritardo possono usare Safety Net, rendendo molto più semplice il ripristino o l'attivazione.
Miglioramenti degli avvisi per la copia singola: l'avviso di copia singola introdotto in Exchange 2010 non è più uno script pianificato separato. Ora è integrato nei componenti di disponibilità gestita nel sistema ed è una funzione nativa di Exchange.
Configurazione automatica della rete dag: le reti dag possono essere configurate automaticamente dal sistema in base alle impostazioni di configurazione. Oltre alle opzioni di configurazione manuale, i gruppi di disponibilità del database possono distinguere le reti della replica da quelle MAPI e configurare automaticamente le reti dei gruppi di disponibilità del database.
Riduzione delle operazioni di I/O al secondo
In Exchange 2010 le copie passive del database hanno una profondità di checkpoint bassa, necessaria per il failover rapido. Inoltre, la copia passiva esegue una prelettura aggressiva dei dati per tenere il passo con una profondità di checkpoint di 5 MB. In seguito all'uso di una profondità di checkpoint bassa e all'esecuzione di queste operazioni aggressive di pre-lettura, le operazioni di I/O al secondo per una copia passiva del database sono uguali alle operazioni di I/O al secondo per una copia attiva in Exchange 2010.
In Exchange 2013 o versioni successive, il sistema può fornire un failover rapido usando una profondità del checkpoint elevata nella copia passiva (100 MB). Poiché hanno una profondità del punto di arresto di 100 MB, le copie passive sono state modificate in modo da non essere più così aggressive. Come risultato dell'aumento della profondità del checkpoint e della deregolazione delle pre-letture aggressive, le operazioni di I/O al secondo per una copia passiva rappresentano circa il 50% delle operazioni di I/O al secondo della copia attiva.
La profondità di arresto più elevata sulla copia passiva ha dato luogo anche ad altre modifiche. Al failover in Exchange 2010, la cache del database viene svuotata mentre il database viene convertito da una copia passiva a una copia attiva. A partire da Exchange 2013, la registrazione ESE è stata riscritta in modo che la cache venga mantenuta durante la transizione da passiva a attiva. Poiché ESE non ha bisogno di svuotare la cache, si ottiene un failover veloce.
Un'altra modifica è stata apportata al processo di manutenzione in background del database (BDM). Adesso il processo di manutenzione in background del database elabora 1-2 MB al secondo per copia.
In seguito a queste modifiche, Exchange offre ora una riduzione significativa delle operazioni di I/O al secondo rispetto a Exchange 2010.
Disponibilità gestita
La disponibilità gestita è l'integrazione di monitoraggio attivo e predefinito e della piattaforma a disponibilità elevata di Exchange. Con la disponibilità gestita, il sistema può determinare quando eseguire un failover su un database in base all'integrità dei servizi. La disponibilità gestita è un'infrastruttura interna distribuita nei servizi accesso client (front-end) e nei servizi back-end nei server Cassette postali. La disponibilità gestita include tre componenti asincroni principali che eseguono costantemente operazioni:
Il primo componente è il motore probe, responsabile dell'esecuzione delle misurazioni nel server e della raccolta dei dati. I risultati di tali misurazioni fluiscono nel secondo componente: lo strumento di monitoraggio.
Lo strumento di monitoraggio contiene tutta la logica aziendale utilizzata dal sistema sulla base di ciò che è considerato integro nei dati raccolti. Simile al motore di riconoscimento dello schema, lo strumento di monitoraggio cerca vari schemi diversi in tutte le misurazioni raccolte, quindi stabilisce se un elemento debba considerarsi o meno integro.
Infine, c'è il motore del risponditore, che è responsabile delle azioni di ripristino.
Se qualche elemento non è integro, la prima azione da eseguire è tentare di recuperarlo. Ciò potrebbe includere azioni di ripristino in più fasi; Per esempio:
Riavviare il pool di applicazioni.
Riavviare il servizio.
Riavviare il server.
Portare offline il server in modo che non accetti più il traffico.
Se le azioni di recupero hanno esito negativo, il sistema inoltra il problema a una persona tramite notifiche del registro eventi.
Disponibilità gestita viene implementata sotto forma di due servizi:
Servizio Exchange Health Manager (MSExchangeHMHost.exe): processo del controller usato per gestire i processi di lavoro. Viene utilizzato per realizzare, eseguire, avviare e arrestare il processo di lavoro, in base alle esigenze. Viene, inoltre, utilizzato per recuperare il processo di lavoro in caso di arresti anomali, per impedire che questo diventi un singolo punto di errore.
Processo di lavoro di Exchange Health Manager (MSExchangeHMWorker.exe): questo è il processo di lavoro responsabile dell'esecuzione delle attività di runtime.
La disponibilità gestita usa l'archiviazione persistente per eseguire le relative funzioni:
i file di configurazione XML vengono utilizzati per inizializzare le definizioni dell'elemento di lavoro durante l'avvio del processo di lavoro.
Il Registro di sistema viene utilizzato per memorizzare i dati di runtime, quali i segnalibri.
L'infrastruttura del registro eventi del canale Crimson viene utilizzata per memorizzare i risultati degli elementi di lavoro.
Per altre informazioni sulla disponibilità gestita, vedere Disponibilità gestita.
Archivio gestito
Exchange 2010 e versioni precedenti supportano l'esecuzione di una singola istanza del processo di Archivio informazioni (Store.exe) nel ruolo del server Cassette postali. Questa singola istanza di Store ospita tutti i database nel server: attivo, passivo, in ritardo e ripristino. In queste architetture di Exchange l'isolamento tra i diversi database ospitati in un server Cassette postali è minimo, se presente. Un problema con un singolo database delle cassette postali può influire negativamente su tutti gli altri database e gli arresti anomali causati da un danneggiamento delle cassette postali possono influire sul servizio per tutti gli utenti i cui database sono ospitati in tale server.
Un'altra sfida con una singola istanza dello Store è la mancanza di scalabilità del processore con il motore di archiviazione ESE (Extensible Storage Engine). ESE può essere ridimensionato bene fino a 8-12 core del processore, ma oltre a questo, i problemi di comunicazione tra processori e sincronizzazione della cache portano a prestazioni negative. Dati i server di oggi con più di 16 sistemi core disponibili, ciò comporterebbe la sfida amministrativa di gestire l'affinità di 8-12 core per ESE e di usare gli altri core per i processi non store (ad esempio, Assistenti, Search Foundation, Disponibilità gestita e così via). Inoltre, l'architettura precedente limitava l'aumento del numero di istanze per il processo dello Store.
Il processo Store.exe si è evoluto considerevolmente nel corso degli anni man mano che Exchange Server stessa si è evoluta, ma come un unico processo, alla fine la sua scalabilità è limitata e rappresenta un singolo punto di guasto. A causa di questi limiti, Store.exe è stato rimosso in Exchange 2013 e sostituito da Managed Store.
Per altre informazioni, vedere Managed Store.
Più database per volume
Anche se i miglioramenti dell'archiviazione in Exchange sono progettati principalmente per una serie di configurazioni di dischi (JBOD), sono disponibili per l'uso da parte di tutte le configurazioni di archiviazione supportate. Una di queste funzionalità è la capacità di ospitare più database sullo stesso volume. Questa funzionalità riguarda l'ottimizzazione di Exchange per dischi di grandi dimensioni. Queste ottimizzazioni danno luogo ad un uso molto più efficace dei dischi di grandi dimensioni in termini di capacità, operazioni di input/output su disco al secondo previste e tempi di reseeding e sono state ideate per affrontare le difficoltà dell'esecuzione in una configurazione di archiviazione JBOD:
Le dimensioni dei database devono essere gestibili.
Le operazioni di reseeding devono essere veloci e affidabili.
Sebbene la capacità di archiviazione sia in aumento, le operazioni di input/output su disco al secondo previste non lo sono.
I dischi che ospitano copie di database passive sono sottoutilizzati in termini di operazioni di input/output su disco al secondo previste.
Le copie ritardate hanno requisiti di archiviazione asimmetrica.
Si dispone di una capacità limitata di recupero in condizioni di spazio su disco insufficiente.
La tendenza all'aumento della capacità di archiviazione continua. Ad esempio, le linee guida sulle procedure consigliate di Exchange per le dimensioni massime del database (2 terabyte) in un'unità da 8 terabyte implicano uno spreco di più di 5 terabyte di spazio su disco.
Una soluzione sarebbe aumentare le dimensioni dei database, ma ciò inibisce la gestibilità perché potrebbe introdurre tempi di reinsediamento lunghi (inclusi i tempi di reinsediamento non gestibili operativamente) e l'affidabilità compromessa della copia di tale quantità di dati in rete.
Inoltre, nel modello di Exchange 2010, il disco che memorizza una copia passiva è sottoutilizzato in termini di operazioni di input/output su disco al secondo previste. Nel caso di una copia passiva ritardata, non soltanto il disco è sottoutilizzato in termini di operazioni di input/output su disco al secondo previste, ma è anche asimmetrico in termini di dimensioni, rispetto ai dischi utilizzati per memorizzare le copie attive e passive non ritardate.
Exchange 2013 e versioni successive è stato ottimizzato per l'uso di dischi di grandi dimensioni (8 terabyte) in una configurazione JBOD in modo più efficiente. Con più database per disco, è ora possibile avere dischi delle stesse dimensioni che archiviano più copie di database, incluse le copie ritardate. Lo scopo è guidare la distribuzione degli utenti attraverso il numero di volumi esistenti, fornendo una struttura simmetrica in cui durante le normali operazioni ciascun membro di un gruppo di disponibilità del database ospita un insieme di copie attive, passive e facoltative ritardate sugli stessi volumi.
Un esempio di una configurazione che utilizza più database per volume è illustrato qui di seguito.
Configurazione che utilizza più database per ciascun volume
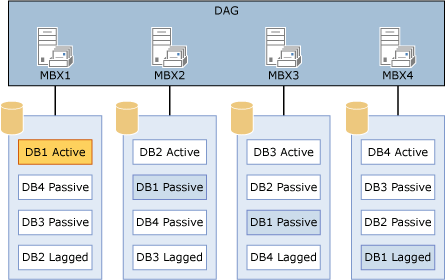
La configurazione nel diagramma fornisce una progettazione simmetrica. Tutti e quattro i server hanno gli stessi quattro database, tutti ospitati su un singolo disco per server. L'aspetto più importante è che il numero di copie di ciascun database di cui si dispone deve essere uguale al numero di copie di database per disco.
Nella configurazione del diagramma sono presenti quattro copie di ogni database: una copia attiva, due copie passive e una copia ritardata. Poiché esistono quattro copie di ciascun database, la configurazione appropriata è una con quattro copie per volume.
Inoltre, è stata configurata la preferenza di attivazione in modo che ci sia un equilibrio nel gruppo di disponibilità del database e su ciascun server. Ad esempio:
La copia attiva avrà un valore di preferenza di attivazione pari a 1.
La prima copia passiva avrà un valore di preferenza di attivazione pari a 2.
La seconda copia passiva avrà un valore di preferenza di attivazione pari a 3.
La copia ritardata avrà un valore di preferenza di attivazione pari a 4.
Oltre ad avere una migliore distribuzione degli utenti tra i volumi esistenti, un altro vantaggio dell'uso di più database per disco è una riduzione della quantità di tempo necessaria per ripristinare la protezione dei dati per gli errori che richiedono un reseed (ad esempio, un errore del disco).
Aumentando le dimensioni del database, aumenterà anche il tempo richiesto per il reseeding del database. Ad esempio, un database da 2 TB potrebbe richiedere 23 ore per l'operazione di reseeding, mentre per un database da 8 TB potrebbero volercene 93 (quasi 4 giorni). Entrambi i seeding si verificherebbero a circa 20 MB al secondo. Generalmente, ciò significa che non è possibile eseguire il seeding di un database di dimensioni notevoli entro una quantità di tempo ragionevole a livello operativo.
Nel caso di uno scenario di una singola copia di database per disco, l'origine del seeding viene individuata facilmente, in quanto il seeding del disco viene sempre effettuato da una singola origine.
Dividendo il volume in più copie di database e avendo la copia attiva dei database passivi su un determinato volume archiviata in membri del gruppo di disponibilità del database distinti, il sistema non è più in grado di individuare efficacemente l'origine nel contesto del reseeding del disco. Quando viene sostituito un disco danneggiato, il reseeding può essere effettuato da più origini. Ciò consente al sistema di effettuare il reseeding e ripristinare la protezione dei dati per questi database in tempi molto più brevi.
Quando si usano più database per volume, è consigliabile seguire le procedure consigliate e i requisiti seguenti:
È necessario utilizzare una singola partizione del disco logico per ogni disco fisico. Evitare di creare più partizioni sul disco. Tutte le copie di database e i relativi file complementari (quali, i registri delle transazioni e l'indice del contenuto) devono essere ospitati in una directory univoca sulla singola partizione.
Il numero di copie del database configurato per volume deve essere uguale al numero di copie di ciascun database. Ad esempio, se si dispone di 4 copie dei database utilizzati, è necessario utilizzare 4 copie di database per volume.
Le copie di database devono avere gli stessi vicini. (ad esempio, devono condividere tutte lo stesso disco su ciascun server).
È necessario equilibrare la preferenza di attivazione nel gruppo di disponibilità del database, in modo che ciascuna copia del database su un determinato disco abbia un valore di preferenza di attivazione univoco.
Reseeding automatico
Il reseed automatico (noto anche come AutoReseed) è la sostituzione di un'azione normalmente gestita dall'amministratore in risposta a un errore del disco, a un evento di danneggiamento del database o a un altro problema che richiede un nuovo invio di una copia del database. L'AutoReseed è stato ideato per ripristinare automaticamente la ridondanza del database a seguito di un errore del disco utilizzando dischi di riserva forniti con il sistema.
Per ulteriori informazioni, vedere AutoReseed. Per la procedura dettagliata per configurare l'AutoReseed, vedere Configurare il reseeding automatico per un gruppo di disponibilità del database.
Ripristino automatico degli errori di archiviazione
Il ripristino automatico dagli errori di archiviazione consente al sistema di eseguire il ripristino da errori che influiscono sulla resilienza o sulla ridondanza. Oltre ai comportamenti di controllo dei bug introdotti in Exchange 2010, Exchange include ora comportamenti di ripristino aggiuntivi per tempi di I/O lunghi, utilizzo eccessivo della memoria da parte del servizio replica di Microsoft Exchange (MSExchangeRepl.exe) e casi gravi in cui i thread non possono essere pianificati.
Anche negli ambienti JBOD, i controller degli array di archiviazione possono riscontrare dei problemi, quali arresti anomali o blocchi. Nella tabella seguente sono elencate le funzionalità che offrono funzionalità di rilevamento e ripristino di I/O bloccate che offrono resilienza migliorata.
| Nome | Assegno | Azione | Soglia |
|---|---|---|---|
| Rilevamento dell'interruzione di I/O del Database Extensible Storage Engine (ESE) | Controlli ESE per I/O eccezionali | Genera un errore nel canale Crimson per riavviare il server | 240 secondi |
| Heartbeat del canale con errore | Garantisce la possibilità di scrivere e leggere gli elementi errati sul canale Crimson | Il servizio di replica rileva gli heartbeat del canale Crimson e riavvia il server in errore | 30 secondi |
| Heartbeat del disco di sistema | Verifica lo stato del disco di sistema del server | Invia periodicamente I/O senza buffer al disco di sistema; riavvia il server in caso di timeout dell'heartbeat | 120 secondi |
Exchange 2013 e versioni successive migliora la resilienza del server e dell'archiviazione includendo comportamenti per altre condizioni gravi. Queste condizioni e i relativi comportamenti sono descritti nella tabella seguente.
| Nome | Assegno | Azione | Soglia |
|---|---|---|---|
| Stato non valido del sistema | Nessun thread, tra cui i thread non gestiti, può essere programmato | Riavvio del server | 302 secondi |
| Tempi di I/O elevati | Misurazioni della latenza del funzionamento I/O | Riavvio del server | 41 secondi |
| Utilizzo della memoria del servizio di replica | Misurazione del working set di MSExchangeRepl.exe | 1: Registrare l'evento 4395 nel canale crimson con una richiesta di terminazione del servizio 2: Avviare la terminazione del MSExchangeRepl.exe 3: Se la terminazione del servizio non riesce, riavviare il server |
4 GB |
| Evento di sistema 129 (reimpostazione del bus) | Verifica dell'evento 129 nel registro degli eventi di sistema | Riavvio del server | Quando si verifica un evento |
| Blocco del database di cluster | Vengono bloccati gli aggiornamenti di Update Manager globali | Riavvio del server | Quando si verifica un evento |
Miglioramenti della copia ritardata
I miglioramenti apportati alla copia ritardata includono l'integrazione con una rete sicura e la riproduzione automatica dei file di registro in determinati scenari. Safety Net è stato introdotto in Exchange 2013 per sostituire la funzionalità exchange 2010 nota come dumpster di trasporto. Safety Net è simile al dumpster del trasporto, in quanto si tratta di una coda di recapito associata al servizio Trasporto in un server Cassette postali. Questa coda archivia le copie dei messaggi che sono stati recapitati al database delle cassette postali attivo sul server Cassette postali. Ciascun database delle cassette postali attivo sul server Cassette postali dispone di una coda che archivia le copie dei messaggi recapitati. È possibile specificare per quanto tempo la Rete sicura conserva le copie dei messaggi recapitati prima che scadano e vengano eliminati automaticamente.
La rete sicura si assume alcune responsabilità della ridondanza shadow negli ambienti dei gruppi di disponibilità del database. Negli ambienti dei gruppi di disponibilità del database, non è necessario che la ridondanza shadow mantenga un'altra copia del messaggio recapitato in una coda shadow mentre attende che il messaggio recapitato venga replicato sulle copie passive del database delle cassette postali sugli altri server Cassette postali nel gruppo di disponibilità del database. La copia del messaggio recapitato è già archiviata nella rete sicura, quindi la ridondanza shadow può recapitare nuovamente il messaggio dalla rete sicura, se necessario.
Con Safety Net, l'attivazione di una copia ritardata del database diventa più semplice. Ad esempio, si supponga di disporre di una copia ritardata con un intervallo di riproduzione di 2 giorni. In questo caso, è necessario configurare la rete sicura per un periodo di 2 giorni. Se si verifica una situazione in cui è necessario usare la copia ritardata, è possibile:
Sospendere la replica.
Copiarlo due volte (per mantenere la natura ritardata del database e per creare una copia aggiuntiva nel caso in cui sia necessario).
Eseguire una copia e rimuovere tutti i file di log, ad eccezione di quelli inclusi nell'intervallo richiesto.
Installare la copia; in questo modo viene attivata una richiesta automatica alla rete sicura affinché recapiti nuovamente gli ultimi due giorni di posta.
Con la rete sicura, non è necessario rispondere dove è stato introdotto il punto di danneggiamento. Si ricevono gli ultimi due giorni di posta, meno i dati andati normalmente persi per un failover.
Le copie ritardate si possono ora autoripristinare richiamando l'esecuzione automatica del registro per riprodurre i file di registro in certi scenari:
Raggiungimento di una soglia di spazio insufficiente su disco
Quando la copia ritardata ha un danneggiamento fisico è necessaria un'applicazione di patch alla pagina
Quando sono presenti meno di tre copie integre disponibili (solo attivo o passivo; copie del database ritardate non sono conteggiate) per più di 24 ore
In Exchange 2010, l'applicazione di patch alla pagina non era disponibile per le copie ritardate. In Exchange 2013 o versioni successive, l'applicazione di patch alle pagine è disponibile per le copie ritardate tramite questa funzionalità di riproduzione automatica. Se il sistema rileva che l'applicazione di patch alla pagina è necessaria per una copia ritardata, i registri vengono automaticamente riprodotti nella copia ritardata per eseguire l'applicazione di patch alla pagina. Le copie ritardate richiamano inoltre la funzione di riproduzione automatica al raggiungimento della soglia di spazio insufficiente su disco e al rilevamento della copia ritardata come unica disponibile per un periodo di tempo specifico.
Il comportamento di riproduzione delle copie ritardate è disabilitato per impostazione predefinita e può essere abilitato utilizzando il comando seguente.
Set-DatabaseAvailabilityGroup <DAGName> -ReplayLagManagerEnabled $true
Una volta abilitata, la riproduzione avviene quando ci sono meno di tre copie. È possibile modificare il valore predefinito di 3, modificando il seguente valore di registro DWORD.
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagManagerNumAvailableCopies
Per abilitare la riproduzione per il raggiungimento della soglia di spazio insufficiente su disco, è necessario configurare la seguente voce di registro.
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagLowSpacePlaydownThresholdInMB
Dopo aver configurato tutte le impostazioni di registro, riavviare il servizio Microsoft Exchange DAG Management per rendere effettive le modifiche.
Si consideri, ad esempio, un ambiente in cui un determinato database ha quattro copie (tre copie a disponibilità elevata e una copia ritardata) e l'impostazione predefinita viene usata per ReplayLagManagerNumAvailableCopies. Se una copia non ritardata non è in grado di funzionare per qualsiasi motivo (ad esempio è sospeso) la copia ritardata riprodurrà automaticamente i rispettivi file di registro in 24 ore.
Miglioramenti dell'avviso della presenza di una singola copia
Garantire che i server funzionino in modo affidabile e che le copie del database delle cassette postali siano integre sono gli obiettivi principali delle operazioni quotidiane di messaggistica di Exchange. È necessario monitorare attivamente l'hardware, il sistema operativo Windows e i servizi di Exchange.
In un ambiente di resilienza delle cassette postali di Exchange, tuttavia, è importante monitorare l'integrità e lo stato del gruppo di disponibilità del database e le copie del database delle cassette postali. È particolarmente importante eseguire la gestione dei rischi della ridondanza dei dati ed eseguirne il monitoraggio per i periodi in cui un database replicato è sceso fino a una singola copia. Ciò è fondamentale negli ambienti che non usano l'array ridondante di dischi indipendenti (RAID) e distribuiscono invece configurazioni JBOD. In un ambiente RAID, l'errore di un singolo disco non influisce su una copia attiva del database delle cassette postali. Tuttavia, in un ambiente JBOD, l'errore di un singolo disco provoca un failover del database.
Lo script CheckDatabaseRedundancy.ps1 è stato introdotto in Exchange 2010. Come indica il nome, l'obiettivo dello script era di monitorare la ridondanza dei database delle cassette postali replicati con la convalida di almeno due copie configurate, integre e aggiornate e inviare un avviso all'amministratore, tramite la generazione di una registrazione dell'evento, in presenza di una sola copia integra di un database replicato. In questo caso, vengono conteggiate entrambe le copie attiva e passiva per la determinazione della ridondanza.
Di seguito sono elencate alcune fra le condizioni di singola copia:
Replica su qualsiasi copia passiva non riuscita da parte di una copia attiva.
Errore di tutte le copie passive, inclusi lo stato FailedAndSuspended e Failed oltre agli stati di integrità in cui la copia è in ritardo nel copiare la registrazione o nella riproduzione. Le copie ritardate non vengono considerate in ritardo se sono entro 10 minuti dalla riproduzione dei log fino al periodo di ritardo.
Errore del sistema sull'informazione precisa riguardante l'attuale generazione del registro della copia attiva.
Poiché è altamente prioritario per gli amministratori sapere quando si trovano in presenza di una singola copia integra di un database, lo script CheckDatabaseRedundancy.ps1 è stato sostituito con una funzionalità nativa integrata che fa parte del set di integrità DataProtection di disponibilità gestita.
La funzionalità nativa avvisa ancora gli amministratori tramite notifiche del log eventi e per distinguere gli avvisi di Exchange 2013 o versioni successive da Exchange 2010, Exchange usa ora gli ID evento seguenti:
Evento 4138 (Red Alert)
Evento 4139 (Green Alert)
La funzionalità nativa è stata migliorata per ridurre il rumore degli avvisi che si verifica quando più database nello stesso server entrano in una singola condizione di copia. In Exchange 2010, gli avvisi di singola copia sono stati generati a livello del singolo database. Di conseguenza, un problema a livello di server che interessa più database e più copie di database potrebbe causare tempeste di avvisi. Poiché diversi errori sono a livello di server( ad esempio, problemi di controller o memoria), vi erano buone probabilità che si verificasse una tempesta di avvisi per ogni evento imprevisto del server.
Gli avvisi vengono ora generati in base al server. Quando un'interruzione influisce su un intero server e la ridondanza dei dati diventa a rischio per più copie del database, viene generato un singolo avviso per server.
Configurazione automatica della rete dei DAG
Una rete del DAG è un insieme di una o più subnet utilizzato sia per il traffico di replica che per il traffico MAPI. Ciascun DAG contiene al massimo una rete MAPI e zero o più reti di replica.
In Exchange 2010 le reti dag iniziali ,ad esempio DAGNetwork01 e DAGNetwork02, sono state create dal sistema in base alle subnet enumerate dal servizio cluster. Se erano presenti più reti e le interfacce per una rete specificata (ad esempio, la rete MAPI) si trovava nella stessa subnet, era necessaria poca configurazione aggiuntiva. Tuttavia, se le interfacce per una rete specificata si trovava in più subnet, è necessario eseguire un'attività nota come compressione delle reti dag.
In Exchange 2013 o versioni successive non è più necessario comprimere le reti dag. Exchange usa ancora gli stessi meccanismi di rilevamento per distinguere le reti MAPI e di replica, ma ora comprime automaticamente le reti dag in base alle esigenze.
Inoltre, per impostazione predefinita, le reti dei gruppi di disponibilità del database vengono ora gestite automaticamente dal sistema. Per visualizzare le proprietà di rete del gruppo di disponibilità del database tramite l'interfaccia di amministrazione di Exchange, è necessario configurare il gruppo di disponibilità del database per il controllo di rete manuale modificando le proprietà del dag tramite EAC o usando il cmdlet Set-DatabaseAvailabilityGroup per impostare il parametro ManualDagNetworkConfiguration su $true.
Modifiche al processo di selezione della copia migliore
Il processo di selezione della copia migliore (BCS) è un processo di algoritmo interno per trovare la copia migliore di un singolo database da attivare in un elenco di potenziali copie per l'attivazione con relativi integrità e stato. Active Manager seleziona la migliore copia disponibile (e non bloccata) adatta a diventare la nuova copia attiva del database quando si verifica un errore della copia attiva del database esistente o quando l'amministratore esegue un passaggio generico. In Exchange 2010 il processo BCS valutava numerosi aspetti di ciascuna copia di database per determinare la copia migliore da attivare. Tra questi erano inclusi:
Lunghezza coda di copia
Lunghezza coda di riproduzione
Stato del database
Stato dell'indice del contenuto
In Exchange 2013 o versioni successive Active Manager esegue gli stessi controlli e le stesse fasi BCS per determinare l'integrità della replica, ma ora include anche l'uso di un vincolo dell'ordine decrescente degli stati di integrità. Come conseguenza di tali modifiche, il processo di selezione della copia migliore (BCS) viene ora denominato processo di selezione della copia e del server migliori (BCSS).
BCSS include diversi nuovi controlli di integrità che ora fanno parte dei componenti predefiniti di monitoraggio della disponibilità gestita in Exchange. Sono disponibili quattro controlli aggiuntivi eseguiti da Active Manager (elencati nell'ordine in cui vengono eseguiti):
Tutto integro: verifica la presenza di un server che ospita una copia del database interessato con tutti i componenti di monitoraggio in uno stato integro.
Fino alla normale integrità: verifica la presenza di un server che ospita una copia del database interessato con tutti i componenti di monitoraggio con priorità Normale in uno stato integro.
Tutto migliore dell'origine: verifica la presenza di un server che ospita una copia del database interessato con componenti di monitoraggio in uno stato migliore rispetto al server corrente che ospita la copia interessata.
Uguale a Source: verifica la presenza di un server che ospita una copia del database interessato con componenti di monitoraggio in uno stato analogo al server corrente che ospita la copia interessata.
Se BCSS viene richiamato come conseguenza di un failover attivato dal componente di monitoraggio di disponibilità gestita (ad esempio, attraverso un risponditore di failover), viene applicato un ulteriore vincolo obbligatorio per cui l'integrità del componente del server di destinazione deve essere migliore del server sul quale si è verificato il failover. Ad esempio, se un errore di Outlook sul web (precedentemente noto come Outlook Web App) attiva un failover di disponibilità gestita tramite un risponditore di failover, BCSS deve selezionare un server che ospita una copia del database interessato in cui Outlook sul web è integro.
Servizio di gestione del gruppo di disponibilità del database (DAG)
Exchange 2013 CU2 o versioni successive include microsoft Exchange DAG Management Service (MSExchangeDAGMgmt). Questo servizio contiene la funzionalità di monitoraggio del dag interno che in precedenza era all'interno del servizio Replica di Microsoft Exchange (MSExchangeRepl).
DAG senza un punto di accesso di amministrazione cluster
Tutti i dag nei server Exchange che eseguono Windows Server 2008 R2 o Windows Server 2012 richiedono almeno un indirizzo IP in ogni subnet inclusa nella rete MAPI. Gli indirizzi IP assegnati al DAG vengono utilizzati dal cluster del DAG con il punto di accesso amministrativo del cluster (denominato anche nome rete cluster) per abilitare la risoluzione del nome e la connettività sul cluster (o più esattamente, connettività sul membro del cluster che al momento include il gruppo risorsa principale del cluster) utilizzando il nome del cluster.
Windows Server 2012 R2 o versioni successive consente di creare un cluster di failover senza un punto di accesso amministrativo. I cluster di failover di Windows senza punti di accesso amministrativo hanno le seguenti caratteristiche:
Al cluster non viene assegnato alcun indirizzo IP, quindi non è presente alcuna risorsa indirizzo IP nel gruppo di risorse di base del cluster.
Al cluster non viene assegnato alcun nome di rete, quindi non è presente alcuna risorsa nome di rete nel gruppo di risorse di base del cluster.
Il nome del cluster non è registrato in DNS e il nome del cluster non è risolvibile in rete.
Un oggetto nome cluster (CNO) non viene creato in Active Directory.
Non è possibile gestire il cluster di failover di Windows usando lo strumento Gestione cluster di failover. È invece necessario usare Windows PowerShell ed è necessario eseguire i cmdlet di PowerShell sui singoli membri del cluster.
Exchange 2013 SP1 o versioni successive in esecuzione in Exchange in Windows Server 2012 R2 o versioni successive consente di creare un gruppo di disponibilità del database senza un punto di accesso amministrativo del cluster. Per altre informazioni, vedere Creazione di dag e Creazione di un gruppo di disponibilità del database.