Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'estensione Fabric Data Engineering Visual Studio (VS) Code supporta completamente le operazioni di creazione, lettura, aggiornamento ed eliminazione (CRUD) della definizione del processo Spark in Fabric. Dopo aver creato una definizione del processo Spark, è possibile caricare più librerie di riferimento, inviare una richiesta per eseguire la definizione del processo Spark e controllare la cronologia di esecuzione.
Definire una definizione del compito Spark
Per creare una nuova definizione del job Spark:
In Visual Studio Code Explorer, selezionare l'opzione Crea definizione del processo Spark.

Immettere i campi obbligatori iniziali: nome, lakehouse di riferimento e lakehouse predefinito.
I processi di richiesta e il nome della definizione del processo Spark appena creata vengono visualizzati nel nodo principale Definizione del processo Spark in VS Code Explorer. Nel nodo di definizione dell'attività Spark, sono visibili tre sottonodi.
- File: elenco del file di definizione principale e di altre librerie a cui si fa riferimento. È possibile caricare nuovi file da questo elenco.
-
Lakehouse: elenco di tutti i lakehouse menzionati da questa definizione del job Spark. Il lakehouse predefinito è contrassegnato nell'elenco ed è possibile accedervi tramite il relativo percorso
Files/…, Tables/…. - Esegui: elenco della cronologia di esecuzione di questa definizione del processo Spark e dello stato di ogni esecuzione.

Caricare un file di definizione principale in una libreria di riferimento
Per caricare o sovrascrivere il file di definizione principale, selezionare l'opzione Aggiungi file principale.

Per caricare il file di libreria a cui fa riferimento il file di definizione principale, selezionare l'opzione Aggiungi file libreria.

Dopo aver caricato un file, è possibile sostituirlo facendo clic sull'opzione Aggiorna file e caricando un nuovo file oppure è possibile eliminare il file tramite l'opzione Elimina.

Inviare una richiesta di esecuzione
Per inviare una richiesta di esecuzione della definizione del processo Spark da VS Code:
Dalle opzioni a destra del nome della definizione del processo Spark che si vuole eseguire, selezionare l'opzione Esegui processo Spark.

Dopo aver inviato la richiesta, appare una nuova applicazione Apache Spark nel nodo Esecuzioni nell'elenco di Esplora risorse. È possibile annullare il processo in esecuzione selezionando l'opzione Annulla processo Spark.
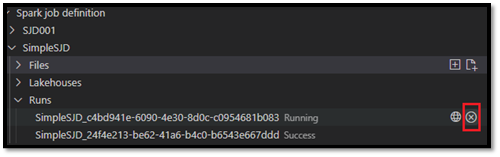


Aprire una definizione del job Spark nel portale Fabric
È possibile aprire la pagina di creazione della definizione del processo Spark nel portale di Fabric selezionando l'opzione Apri nel browser.
È anche possibile selezionare Apri nel browser accanto a un'esecuzione completata per vedere la pagina di monitoraggio dei dettagli di tale esecuzione.

Eseguire il debug del codice sorgente della definizione del processo Spark (Python)
Se la definizione del processo Spark viene creata con PySpark (Python), è possibile scaricare lo script .py del file di definizione principale e del file di riferimento, ed eseguire il debug dello script di origine in VS Code.
Per scaricare il codice sorgente, selezionare l'opzione Debug della definizione del processo Spark a destra della definizione del processo Spark.

Al termine del download, la cartella del codice sorgente si apre automaticamente.
Selezionare l'opzione Considerare attendibili gli autori quando richiesto. (Questa opzione appare solo la prima volta che si apre la cartella. Se non si seleziona questa opzione, non sarà possibile eseguire il debug o lo script di origine. Per altre informazioni, vedere Sicurezza dell'attendibilità dell'area di lavoro di Visual Studio Code.)
Se il codice sorgente è stato scaricato in precedenza, verrà richiesto di confermare che si vuole sovrascrivere la versione locale con il nuovo download.
Nota
Nella cartella radice dello script di origine, il sistema crea una sottocartella denominata conf. All'interno di questa cartella, un file denominato lighter-config.json contiene alcuni metadati di sistema necessari per l'esecuzione remota. NON apportare modifiche a tale file.
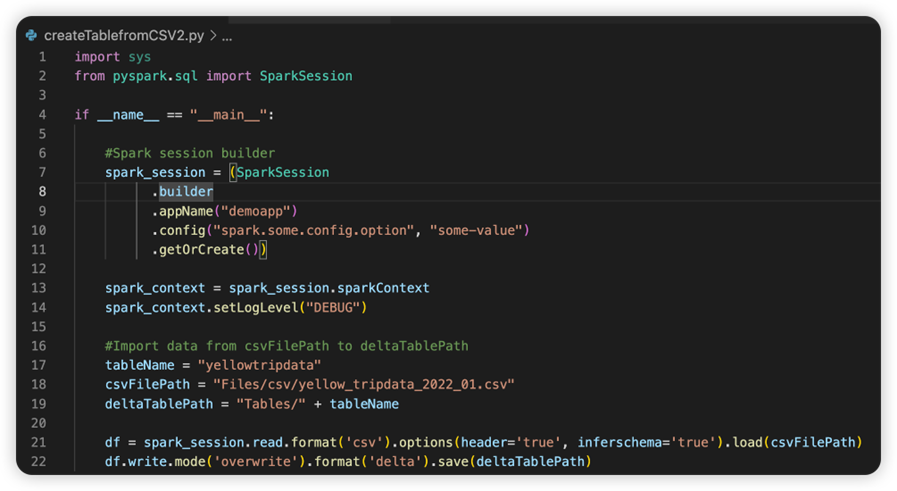
Il file denominato sparkconf.py contiene un frammento di codice da aggiungere per configurare l'oggetto SparkConf. Per abilitare il debug remoto, assicurarsi che l'oggetto SparkConf sia configurato correttamente. L'immagine seguente mostra la versione originale del codice sorgente.
L'immagine successiva è il codice sorgente aggiornato dopo aver copiato e incollato il frammento.
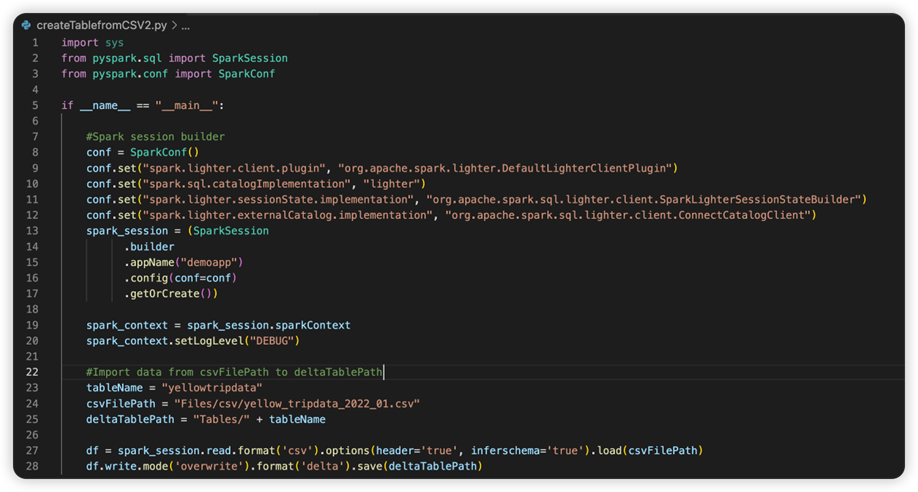
Dopo aver aggiornato il codice sorgente con la configurazione necessaria, occorre selezionare l'interprete Python corretto. Assicurarsi di selezionare quello installato nell'ambiente conda synapse-spark-kernel.



Modificare le proprietà della definizione del processo Spark
È possibile modificare le proprietà di dettaglio delle definizioni del processo Spark, come argomenti della riga di comando.
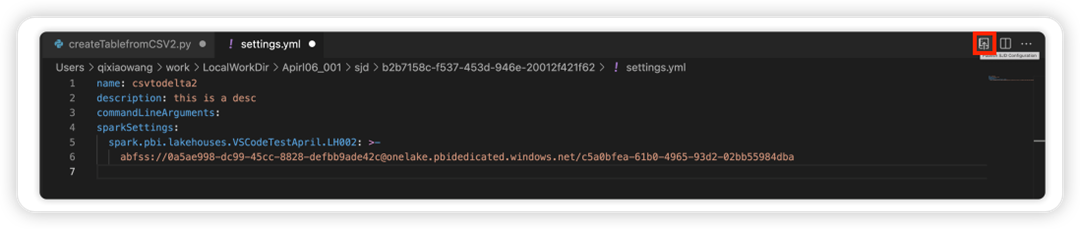
Selezionare l'opzione Aggiorna configurazione SJD per aprire un file settings.yml. Le proprietà esistenti popolano il contenuto del file.
Aggiorna e salva il file .yml.
Selezionare l'opzione Pubblica proprietà SJD in alto a destra per sincronizzare la modifica all'area di lavoro remota.