Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Usare pool di Spark personalizzati per personalizzare il calcolo per i carichi di lavoro in Fabric. È possibile scegliere le dimensioni del nodo, configurare il comportamento di scalabilità automatica e abilitare l'allocazione dinamica dell'executor.
I pool personalizzati consentono di bilanciare le prestazioni e i costi consentendo di impostare limiti di scalabilità che corrispondono alla domanda del carico di lavoro.
Annotazioni
I pool di Spark personalizzati possono raggiungere circa 5 secondi per l'inizio delle sessioni quando vengono configurati come pool live personalizzato con un ambiente che utilizza la modalità completa per la pubblicazione delle librerie. Senza una configurazione del pool live, l'avvio dei pool di Spark personalizzati richiede circa tre minuti.
Se si usano già pool di avvio, i pool personalizzati sono un'opzione complementare quando è necessario un maggiore controllo sul ridimensionamento e sul comportamento di ridimensionamento per carichi di lavoro specifici. Usare i pool di avvio per l'avvio rapido e le impostazioni predefinite e passare a pool personalizzati quando è necessaria l'ottimizzazione di calcolo specifica del carico di lavoro. Per altre informazioni sui pool di avvio, vedere Configurare i pool di avvio in Fabric.
Prerequisiti
Per creare un pool di Spark personalizzato:
- È necessario il ruolo di amministratore nell'area di lavoro.
- Un amministratore delle risorse deve abilitare i pool personalizzati di aree di lavoro nelle impostazioni di Calcolo Spark per le risorse.
Per altre informazioni, vedere Configurare e gestire le impostazioni di data science e ingegneria dei dati per le capacità di Fabric.
Creare pool di Spark personalizzati
Per creare o gestire il pool di Spark associato all'area di lavoro:
Passare all'area di lavoro e selezionare Impostazioni area di lavoro.

Selezionare l'opzione Data Engineering/Science per espandere il menu, quindi selezionare Impostazioni Spark.

Selezionare Nuovo pool dall'elenco a discesa Pool predefinito per l'area di lavoro per creare un nuovo pool di Spark personalizzato. È possibile creare più pool personalizzati e selezionarli come pool predefinito per l'area di lavoro.
Nella pagina Crea nuovo pool immettere un nome del pool. Selezionare una famiglia di nodi (ad esempio ottimizzata per la memoria) e dimensioni del nodo in base ai requisiti del carico di lavoro. Per altre informazioni sulle dimensioni dei nodi, vedere la sezione Opzioni relative alle dimensioni del nodo di seguito.
Suggerimento
Le dimensioni del nodo sono determinate dalle unità di capacità (CU), che rappresentano la capacità di calcolo assegnata a ogni nodo.
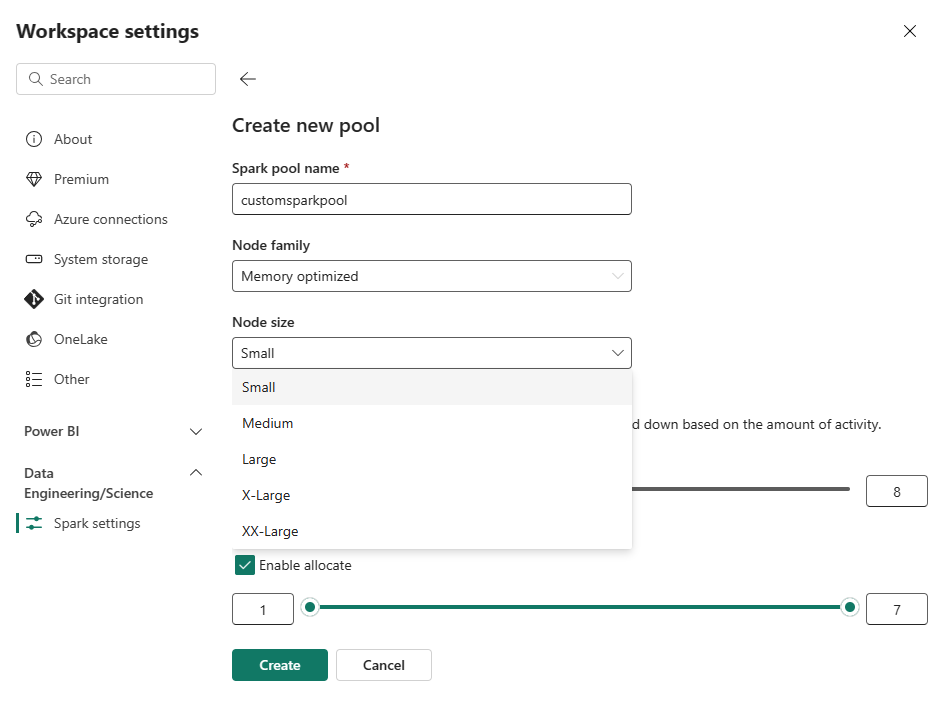
Nella visualizzazione di modifica configurare la scalabilità automatica e allocare dinamicamente gli esecutori.
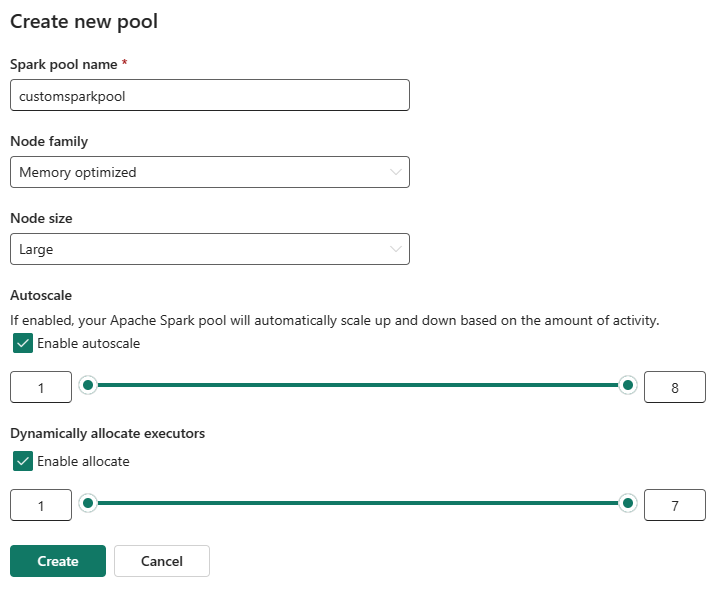
Usare i dispositivi di scorrimento per aumentare o ridurre ogni impostazione in base alle esigenze del carico di lavoro.
Se la scalabilità automatica è abilitata, il pool viene ridimensionato tra i valori minimo e massimo dei nodi configurati in base all'attività.
Se è abilitato l'allocazione dinamica degli executor , Fabric regola l'allocazione dell'executor in base alla domanda di carico di lavoro all'interno dei limiti configurati.
Fare clic su Crea.




Suggerimento
Dopo aver creato un pool di Spark personalizzato, i tempi di distribuzione della libreria dipendono dalla modalità di pubblicazione nell'ambiente collegato. La modalità rapida pubblica in circa 5 secondi e installa le librerie all'avvio della sessione. La modalità completa richiede da 3 a 6 minuti per pubblicare e distribuire le librerie come parte dell'avvio della sessione (da 1 a 3 minuti). Per un'esperienza più veloce, configurare il pool come pool live personalizzato con modalità completa per ottenere circa 5 secondi di avvio della sessione.
I pool personalizzati hanno una durata predefinita di sospensione automatica di 2 minuti dopo un periodo di inattività. Quando viene raggiunta la sospensione automatica, la sessione scade e il cluster viene deallocato. La fatturazione si applica solo quando il calcolo viene usato attivamente. I pool di Spark personalizzati in Microsoft Fabric supportano attualmente un limite massimo di nodi pari a 200, quindi assicurarsi che i valori di scalabilità automatica minima e massima rimangano entro questo limite.
Opzioni dimensioni nodo
Quando si configura un pool di Spark personalizzato, è possibile scegliere tra le dimensioni del nodo seguenti:
| Dimensioni nodo | vCores | Memoria (GB) | Descrizione |
|---|---|---|---|
| Piccola | 4 | 32 | Per processi di sviluppo e test leggeri. |
| Intermedio | 8 | 64 | Per carichi di lavoro generali e operazioni tipiche. |
| Grande | 16 | 128 | Per attività a elevato utilizzo di memoria o processi di elaborazione dati di grandi dimensioni. |
| X-Large | 32 | 256 | Per i carichi di lavoro Spark più impegnativi che necessitano di risorse significative. |
| XXL | 64 | 512 | Per i carichi di lavoro Spark più grandi che richiedono il calcolo e la memoria più elevati per nodo. |
Contenuto correlato
- Per ulteriori informazioni, consultare la documentazione pubblica di Apache Spark.
- Introduzione alle impostazioni di amministrazione dell'area di lavoro Spark in Microsoft Fabric.
- Gestire le librerie negli ambienti Fabric