Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come creare una definizione del processo Spark in Microsoft Fabric.
Il processo di creazione della definizione del processo Spark è veloce e semplice; esistono svariati modi per iniziare.
È possibile creare una definizione di processo Spark dal portale di Fabric o usando l'API REST di Microsoft Fabric. Questo articolo è incentrato sulla creazione di una definizione di processo Spark dal portale di Fabric. Per informazioni sulla creazione di una definizione di processo Spark con l'API REST, vedere API di definizione del processo Apache Spark v1 e API di definizione del processo Apache Spark v2.
Prerequisiti
Prima di iniziare, sono necessari:
- Un account tenant di Fabric con una sottoscrizione attiva. Creare un account gratuitamente.
- Un'area di lavoro in Microsoft Fabric. Per altre informazioni, vedere Creare e gestire aree di lavoro in Microsoft Fabric.
- Almeno una lakehouse nell'area di lavoro. Il lakehouse funge da file system predefinito per la definizione del processo Spark. Per altre informazioni, vedere Creare una lakehouse.
- File di definizione principale per il processo Spark. Questo file contiene la logica dell'applicazione ed è obbligatorio per eseguire un processo Spark. Ogni definizione di processo Spark può avere un solo file di definizione principale.
È necessario assegnare un nome alla definizione del processo Spark al momento della creazione. Il nome deve essere univoco nell'area di lavoro corrente. La nuova definizione del processo Spark viene creata nell'area di lavoro corrente.
Creare una definizione di processo Spark nel portale di Fabric
Per creare una definizione di processo Spark nel portale di Fabric, seguire questa procedura:
- Accedere al portale di Microsoft Fabric .
- Passare all'area di lavoro desiderata in cui si vuole creare la definizione del processo Spark.
- Selezionare Nuovo elemento>Definizione processo Spark.
- Nella scheda Nuova definizione processo Spark specificare le informazioni seguenti:
- Nome: immettere un nome univoco per la definizione del processo Spark.
- Posizione: Selezionare il percorso dell'area di lavoro.
- Selezionare Crea per creare la definizione del processo Spark.
Un punto di ingresso alternativo per creare una definizione di processo Spark è l'analisi dei dati usando un riquadro SQL ... nella home page di Fabric. È possibile trovare la stessa opzione selezionando il riquadro Generale.

Quando si seleziona il riquadro, viene richiesto di creare una nuova area di lavoro o selezionare una nuova area di lavoro esistente. Dopo aver selezionato l'area di lavoro, viene visualizzata la pagina di creazione della definizione del processo Spark.
Personalizzare una definizione di job Spark per PySpark (Python)
Prima di creare una definizione di processo Spark per PySpark, è necessario un file Parquet di esempio caricato nella lakehouse.
- Scaricare il file Parquet di esempio yellow_tripdata_2022-01.parquet.
- Vai alla lakehouse dove vuoi caricare il file.
- Caricarlo nella sezione "File" della lakehouse.
Per creare una definizione del processo Spark per PySpark:
Selezionare PySpark (Python) dal menu a discesa Lingua.
Scaricare il file di definizione di esempio createTablefromParquet.py . Caricarlo come file di definizione principale. Il file di definizione principale (job.Main) è il file che contiene la logica dell'applicazione ed è obbligatorio per eseguire un processo Spark. Per ogni definizione del processo Spark, è possibile caricare un solo file di definizione principale.
Nota
È possibile caricare il file di definizione principale dal desktop locale oppure caricare da un'istanza di Azure Data Lake Storage (ADLS) Gen2 esistente specificando il percorso ABFSS completo del file. Ad esempio:
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Facoltativamente, caricare i file di riferimento come
.pyfile (Python). I file di riferimento sono i moduli Python importati dal file di definizione principale. Proprio come il file di definizione principale, si possono caricare dal desktop o da un ADLS Gen2 esistente. Sono supportati molteplici file di riferimento.Suggerimento
Se si usa un percorso ADLS Gen2, assicurarsi che il file sia accessibile. È necessario assegnare all'account utente che esegue il processo l'autorizzazione appropriata per l'account di archiviazione. Ecco due modi diversi per concedere l'autorizzazione:
- Assegnare all'account utente un ruolo Contributore per l'account di archiviazione.
- Concedere l'autorizzazione di lettura ed esecuzione all'account utente per il file tramite l'elenco di controllo di accesso (ACL) ADLS Gen2.
Per un'esecuzione manuale, l'account dell'utente connesso corrente viene usato per eseguire il processo.
Fornire gli argomenti della riga di comando per il processo, se necessario. Usare uno spazio come una barra di divisione per separare gli argomenti.
Aggiungere il riferimento del lakehouse al processo. È necessario avere almeno un riferimento del lakehouse aggiunto al processo. Questo lakehouse è il contesto lakehouse predefinito per il processo.
Sono supportati molteplici riferimenti del lakehouse. Cercare il nome del lakehouse non predefinito e l'URL di OneLake completo nella pagina Impostazioni Spark.

Personalizzare una definizione di processo Spark per Scala/Java
Per creare una definizione del processo Spark per Scala/Java:
Selezionare Spark(Scala/Java) dal menu a discesa Lingua.
Caricare il file di definizione principale come
.jarfile (Java). Il file di definizione principale è il file che contiene la logica dell'applicazione di questo processo ed è obbligatorio per eseguire un processo Spark. Per ogni definizione del processo Spark, è possibile caricare un solo file di definizione principale. Fornire il nome della classe principale.Facoltativamente, caricare i file di riferimento come
.jarfile (Java). I file di riferimento sono i file a cui fa riferimento/importa il file di definizione principale.Fornire gli argomenti della riga di comando per il processo, se necessario.
Aggiungere il riferimento del lakehouse al processo. È necessario avere almeno un riferimento del lakehouse aggiunto al processo. Questo lakehouse è il contesto lakehouse predefinito per il processo.
Personalizzare una definizione di processo Spark per R
Per creare una definizione del processo SparkR(R):
Selezionare SparkR(R) nel menu a discesa Lingua.
Caricare il file di definizione principale come
.rfile (R). Il file di definizione principale è il file che contiene la logica dell'applicazione di questo processo ed è obbligatorio per eseguire un processo Spark. Per ogni definizione del processo Spark, è possibile caricare un solo file di definizione principale.Facoltativamente, caricare i file di riferimento come
.rfile (R). I file di riferimento sono i file a cui viene fatto riferimento/che vengono importati dal file di definizione principale.Fornire gli argomenti della riga di comando per il processo, se necessario.
Aggiungere il riferimento del lakehouse al processo. È necessario avere almeno un riferimento del lakehouse aggiunto al processo. Questo lakehouse è il contesto lakehouse predefinito per il processo.
Nota
La definizione del processo Spark viene creata nell'area di lavoro corrente.
Opzioni per personalizzare le definizioni del processo Spark
Sono disponibili alcune opzioni per personalizzare ulteriormente l'esecuzione delle definizioni del processo Spark.
Calcolo Spark: nella scheda Calcolo Spark è possibile visualizzarela versione del runtime di Fabric usata per eseguire il processo Spark. È anche possibile visualizzare le impostazioni di configurazione di Spark usate per eseguire il processo. È possibile personalizzare le impostazioni di configurazione di Spark selezionando il pulsante Aggiungi .
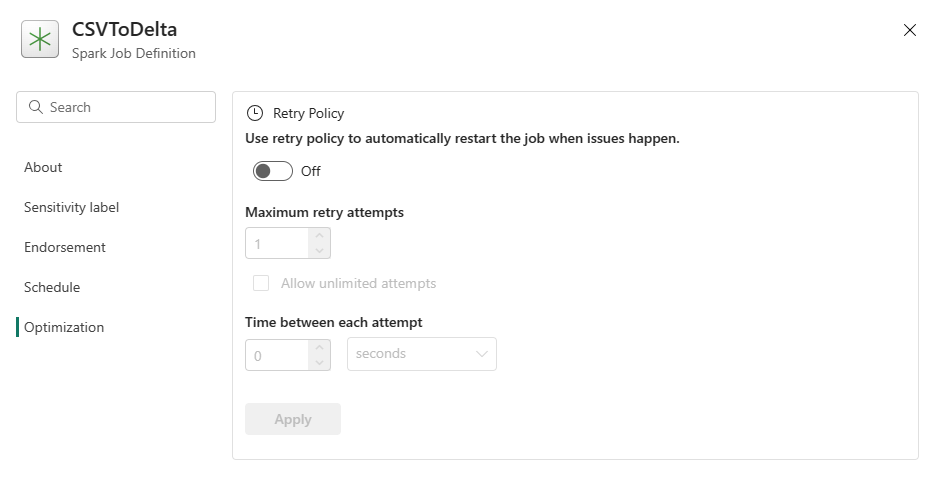
Ottimizzazione: nella scheda Ottimizzazione, è possibile abilitare e configurare i criteri di ripetizione per il processo. Se abilitato, il processo viene ritentato in caso di errore. È anche possibile impostare il numero massimo di tentativi e l'intervallo tra i nuovi tentativi. Per ogni tentativo di ripetizione, il processo viene riavviato. Assicurarsi che il processo sia idempotente.