Usare un notebook per caricare dati nel lakehouse
Questa esercitazione illustra come leggere/scrivere dati in un lakehouse Fabric con un notebook. A tale scopo, Fabric supporta l'API Spark e l'API Pandas.
Caricare dati con un'API Apache Spark
Nella cella di codice del notebook, usare l'esempio di codice seguente per leggere i dati dall'origine e caricarli in File, Tabelle o entrambe le sezioni del lakehouse.
Per specificare il percorso da cui leggere, è possibile usare il percorso relativo se i dati provengono dal lakehouse predefinito del notebook corrente. In alternativa, se i dati provengono da un altro lakehouse, è possibile usare il percorso ABFS (Azure Blob File System) assoluto. Copiare questo percorso dal menu contestuale dei dati.
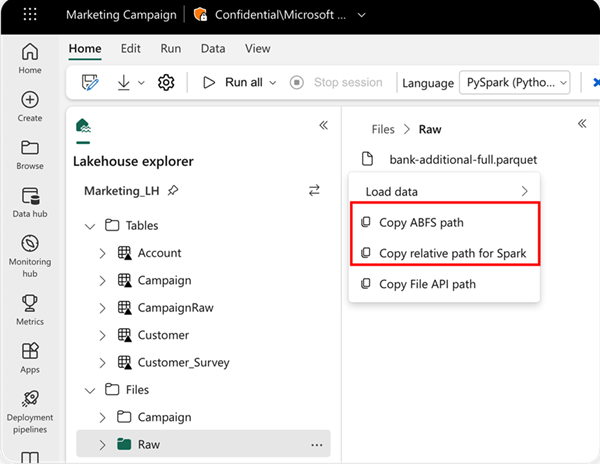
Copia percorso ABFS: questa opzione restituisce il percorso assoluto del file.
Copia percorso relativo per Spark: questa opzione restituisce il percorso relativo del file nel lakehouse predefinito.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Caricare dati con l'API Pandas
Per supportare l'API Pandas, il lakehouse predefinito viene montato automaticamente nel notebook. Il punto di montaggio è '/lakehouse/default/'. È possibile usare questo punto di montaggio per leggere/scrivere dati da/verso il lakehouse predefinito. L'opzione "Copia percorso API File" dal menu contestuale restituisce il percorso dell'API File da tale punto di montaggio. Il percorso restituito dall'opzione Copia percorso ABFSfunziona anche per l'API Pandas.
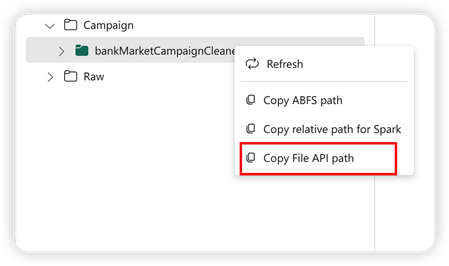
Copia percorso API File: questa opzione restituisce il percorso sotto il punto di montaggio del lakehouse predefinito.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Suggerimento
Per l'API Spark, usare l'opzione Copia percorso ABFS o Copia percorso relativo per Spark per ottenere il percorso del file. Per l'API Pandas, usare l'opzione Copia percorso ABFS o Copia percorso API File per ottenere il percorso del file.
Il modo più rapido per usare il codice con l'API Spark o l'API Pandas consiste nell'usare l’opzione Carica dati e selezionare l'API da usare. Il codice viene generato automaticamente in una nuova cella di codice del notebook.
