Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questa funzionalità si trova in Anteprima.
Fabric Runtime offre una perfetta integrazione all'interno dell'ecosistema Microsoft Fabric, offrendo un ambiente affidabile per progetti di data engineering e data science basati su Apache Spark.
Questo articolo presenta Fabric Runtime 2.0 Public Preview, il runtime più recente progettato per i calcoli di Big Data in Microsoft Fabric. Evidenzia le funzionalità e i componenti chiave che rendono questa versione un passo avanti significativo per l'analisi scalabile e i carichi di lavoro avanzati.
Fabric Runtime 2.0 incorpora i componenti e gli aggiornamenti seguenti progettati per migliorare le funzionalità di elaborazione dei dati:
- Apache Spark 4.1
- Sistema operativo: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,2
- R: 4.5.2
Importante
Il team di Microsoft Fabric sta lanciando un aggiornamento per Microsoft Fabric Runtime 2.0. Come parte di questo aggiornamento, l'aggiornamento Python introduce un cambiamento rivoluzionario per i clienti che utilizzano artefatti ambientali con librerie python e wheel. I clienti vedono uno dei due messaggi di errore con l'esecuzione della Definizione del Lavoro Notebook o Spark (SJD):
- Errore: avviso: 1 elemento deprecato (a partire dalla versione 2.13.0); per i dettagli, abilita
:setting -deprecationo:replay -deprecation. Fonte: SparkCoreService. - "LibraryManagementError": "È stato rilevato un aggiornamento all'ambiente base di Spark Python. Per favore, ripubblica l'ambientazione.|UserError"
Azioni necessarie
Ripubblica il tuo ambiente (inclusi i libreri). Per farlo, rimuovere tutte le librerie, pubblicare l'Ambiente, aggiungere di nuovo tutte le librerie e pubblicare di nuovo. Questo processo ricrea l'ambiente utilizzando il runtime Python aggiornato e risolve il problema.
Suggerimento
Fabric Runtime 2.0 include il supporto per il motore di esecuzione nativo, che può migliorare significativamente le prestazioni senza costi aggiuntivi. È possibile abilitare il motore di esecuzione nativo a livello di ambiente in modo che tutti i processi e i notebook ereditino automaticamente le funzionalità di prestazioni avanzate.
Abilitare Runtime 2.0
È possibile abilitare Runtime 2.0 a livello di area di lavoro o di elemento dell'ambiente. Usare l'impostazione dell'area di lavoro per applicare Runtime 2.0 come impostazione predefinita per tutti i carichi di lavoro Spark nell'area di lavoro. In alternativa, creare un elemento di ambiente con Runtime 2.0 da usare con notebook specifici o definizioni di processi Spark, che sostituisce l'impostazione predefinita dell'area di lavoro.
Abilitare Runtime 2.0 nelle impostazioni dell'area di lavoro
Per impostare Runtime 2.0 come predefinito per l'intera area di lavoro:
Accedere alla pagina Impostazioni area di lavoro all'interno dell'area di lavoro Fabric.
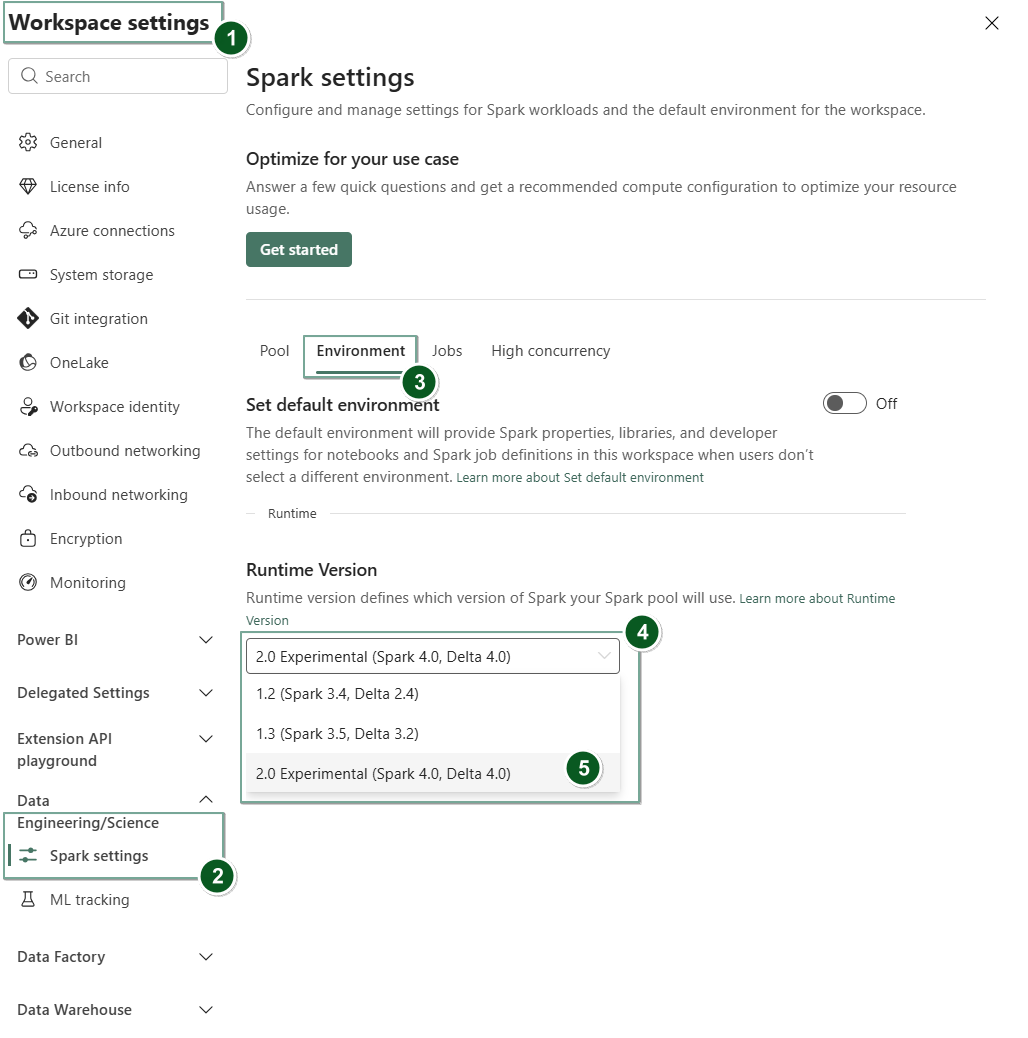
Selezionare la scheda Ingegneria dati/Scienza e quindi selezionare Impostazioni Spark.
Fare clic sulla scheda Ambiente.
Nel menu a tendina della versione Runtime , seleziona Anteprima pubblica 2.0 (Spark 4.1, Delta 4.2) e salva le tue modifiche.
Runtime 2.0 è impostato come runtime predefinito per l'area di lavoro.

Abilitare Runtime 2.0 in un elemento Ambiente
Per utilizzare Runtime 2.0 con notebook specifici o definizioni di job Spark:
Creare un nuovo elemento Environment o aprirne uno esistente.
Nel menu a tendina Runtime , seleziona Anteprima pubblica 2.0 (Spark 4.1, Delta 4.2), Salva e Pubblica le tue modifiche.
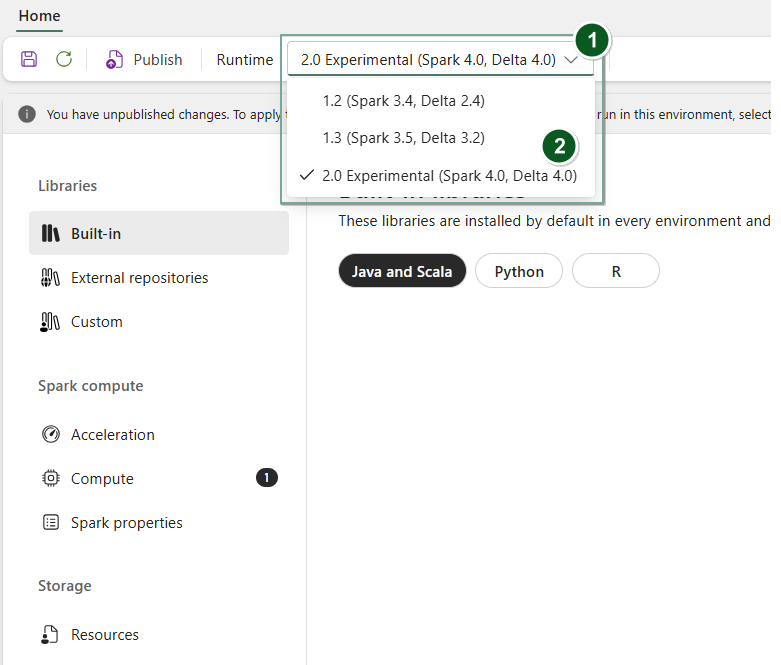
A questo punto, è possibile usare questo elemento Environment con il notebook o la definizione del processo Spark.

Ora puoi iniziare a sperimentare con i più recenti miglioramenti e funzionalità introdotti in Fabric Runtime 2.0 (Spark 4.1 e Delta Lake 4.2).
Anteprima pubblica
La fase di anteprima pubblica di Fabric Runtime 2.0 ti dà accesso a nuove funzionalità e API sia da Spark 4.1 che da Delta Lake 4.2. L'anteprima consente di usare immediatamente i miglioramenti più recenti basati su Spark e Delta, oltre a garantire una corretta preparazione e transizione per modifiche migliorate e migliorate, ad esempio le versioni più recenti di Java, Scala e Python.
Suggerimento
Per informazioni aggiornate, un elenco dettagliato delle modifiche e delle note sulla versione specifiche per i runtime di Fabric, controllare e iscriversi a Release e aggiornamenti dei runtime di Spark.
Punti salienti
Miglioramenti del motore di esecuzione e prestazioni
Fabric Runtime 2.0 include il motore di esecuzione nativo, che offre miglioramenti significativi delle prestazioni rispetto a Spark open source. Il motore usa l'elaborazione vettorializzata per accelerare le query Spark nell'infrastruttura lakehouse senza richiedere modifiche al codice.
Funzionalità principali delle prestazioni in Runtime 2.0:
- Fino a sei volte più veloce: i benchmark mostrano fino a sei volte più veloci prestazioni rispetto a Spark open source nei carichi di lavoro TPC-DS.
- Analisi CSV vettorializzata: il motore di esecuzione nativo include un parser CSV vettorializzato che accelera l'inserimento CSV e i carichi di lavoro di query. L'analisi JSON vettorializzata e il supporto di Spark Structured Streaming sono pianificati per gli aggiornamenti futuri.
Per abilitare il motore di esecuzione nativo, vedere Motore di esecuzione nativo per Fabric Data Engineering.
Apache Spark 4.1
Apache Spark 4.0 ha segnato una pietra miliare significativa come versione inaugurale nella serie 4.x, incarnando lo sforzo collettivo della vivace community open source. Fabric Runtime 2.0 ora viene eseguito in Apache Spark 4.1, che si basa su tale base con miglioramenti aggiuntivi.
In questa versione Spark SQL è notevolmente arricchita con potenti nuove funzionalità progettate per aumentare l'espressività e la versatilità per i carichi di lavoro SQL, ad esempio il supporto dei tipi di dati VARIANT, le funzioni definite dall'utente SQL, le variabili di sessione, la sintassi pipe e le regole di confronto di stringhe. PySpark vede l'impegno continuo sia per l'ampiezza funzionale che per l'esperienza di sviluppo complessiva, introducendo un'API nativa per i grafici, una nuova API per le origini dati Python, il supporto per UDTF Python e la profilatura unificata per gli UDF di PySpark, insieme a numerosi altri miglioramenti. Structured Streaming si evolve con aggiunte chiave che offrono maggiore controllo e facilità di debug, in particolare l'introduzione dell'API Stato arbitrario v2 per una gestione più flessibile dello stato e l'origine dati stato per semplificare il debug.
È possibile controllare l'elenco completo e le modifiche dettagliate qui:
Annotazioni
In Spark 4.x SparkR è deprecato e potrebbe essere rimosso in una versione futura.
Delta Lake 4.2
Delta Lake 4.2 si basa sulle precedenti versioni di Delta Lake, continuando l'impegno a rendere Delta Lake interoperabile tra i formati, più facile da gestire e più performante. Include nuove potenti funzionalità, ottimizzazioni delle prestazioni e miglioramenti fondamentali per il futuro di data lakehouse aperti.
Per l'elenco completo e i cambiamenti dettagliati introdotti con Delta Lake 3.3, 4.0, 4.1 e 4.2, vedi:
Layout e ottimizzazione dei dati
Runtime 2.0 supporta le funzionalità di layout e ottimizzazione dei dati per le tabelle Delta:
- Ordinamento Z: organizzare i dati all'interno di file di tabella Delta in base alle colonne specificate per migliorare le prestazioni delle query per le query filtrate.
- Clustering liquido: approccio flessibile al clustering che ottimizza automaticamente il layout dei dati senza manutenzione manuale.
- Caricamento parallelo di snapshot Delta: il motore di esecuzione nativo carica gli snapshot della tabella Delta in parallelo, riducendo il tempo di avvio delle query per tabelle di grandi dimensioni.
Importante
Le funzionalità specifiche di Delta Lake 4.2 sono sperimentali e funzionano solo sulle esperienze Spark, come Notebook e Definizioni di Lavoro Spark. Se è necessario usare le stesse tabelle Delta Lake in più carichi di lavoro di Microsoft Fabric, non abilitare tali funzionalità. Per saperne di più su quali versioni e funzionalità di protocollo sono compatibili in tutte le esperienze Microsoft Fabric, consulta l'interoperabilità del formato di tabella Delta Lake.
Gestione del calcolo in Runtime 2.0
Runtime 2.0 supporta le funzionalità di gestione di calcolo seguenti:
- Profili di risorse: configurare le allocazioni di risorse predefinite per le sessioni Spark in modo che corrispondano ai requisiti del carico di lavoro e controllino i costi.
- Pool live personalizzati (anteprima): creare pool spark dedicati pre-riscaldati che riducono il tempo di avvio della sessione. I pool live personalizzati sono disponibili in anteprima per i carichi di lavoro runtime 2.0.
Limitazioni e note
- Le funzionalità specifiche di Delta Lake 4.x sono sperimentali e funzionano solo su esperienze Spark, ad esempio notebook e definizioni di processi Spark. Se è necessario usare le stesse tabelle Delta Lake in più carichi di lavoro di Fabric, non abilitare tali funzionalità. Per altre informazioni, vedere Interoperabilità in formato tabella Delta Lake.
- Il runtime 2.0 è disponibile in anteprima pubblica. Alcune funzionalità e API possono cambiare prima della disponibilità generale.
- L'estensione VS Code per Fabric Spark supporta Runtime 2.0 per lo sviluppo di definizioni di job Spark e notebook.
Contenuti correlati
- Runtime di Apache Spark in Fabric - Panoramica, controllo delle versioni e supporto di più runtime
- Guida alla migrazione di Spark Core
- Guide alla migrazione di SQL, set di dati e DataFrame
- Guida alla migrazione di Structured Streaming
- Guida alla migrazione di MLlib (Machine Learning)
- Guida alla migrazione di PySpark (Python in Spark)
- Guida alla migrazione di SparkR (R in Spark)