Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Concetti di base che supportano il dimensionamento, l'ottimizzazione e la risoluzione dei problemi. Leggi prima questo se sei nuovo a Spark in Fabric.
Cosa fare e cosa non fare generali
Scenario: non si ha familiarità con Spark. Che cosa sono i consigli su cosa fare e cosa non fare
| Caso d'uso | Procedure consigliate |
|---|---|
| Usare formati serializzati ottimizzati | Do: preferisce formati come Avro, Parquet o Optimized Row Columnar (ORC) perché incorporano lo schema, sono compattati e ottimizzano l'archiviazione e l'elaborazione. In Fabric, utilizzare il formato Delta per le garanzie ACID di Atomicità, Coerenza, Isolamento, Durabilità e per i benefici in termini di prestazioni. |
| Prestare attenzione con XML/JSON | Non basarsi sull'inferenza dello schema per file JSON (JavaScript Object Notation) di grandi dimensioni o XML (Extensible Markup Language), poiché Spark legge l'intero set di dati per dedurre lo schema, rallentando l'elaborazione e consumando intensamente la memoria. Fornire uno schema primario statico durante la lettura di JSON/XML o l'uso .option("samplingRatio", 0.1) per velocizzare le letture, ma tenere presente che se l'esempio non rappresenta il set di dati completo, le letture potrebbero non riuscire. Un approccio più sicuro deduce lo schema da un campione rappresentativo e lo rende persistente per tutte le letture.Evitare di analizzare file XML di grandi dimensioni. L'analisi XML viene eseguita intrinsecamente più lentamente a causa dell'elaborazione dei tag e del cast dei tipi. |
| Ottimizzare i join e i filtri | Fai: Applica la potatura delle colonne e il filtro a livello di riga prima dei join per ridurre il rimescolamento e l'uso della memoria. L'ottimizzatore Catalyst gestisce automaticamente il pushdown del predicato quando si usano le API DataFrame. Evitare le API di Resilient Distributed Dataset (RDD) perché ignorano le ottimizzazioni di Catalyst. |
| Preferisce i dataframe rispetto ai set di dati RDD | Non dimenticare: Usa i DataFrame anziché gli RDD per la maggior parte delle operazioni. I DataFrames usano l'ottimizzatore Catalyst e il motore di esecuzione Tungsten per un'esecuzione efficiente. |
| Abilitare l'esecuzione di query adattive (AQE) | Suggerimento: attivare AQE per ottimizzare dinamicamente le partizioni di mescolamento e gestire automaticamente i dati sbilanciati. |
Gestione della memoria dell'esecutore
Scenario: si vuole comprendere la gestione della memoria dell'executor per l'ottimizzazione delle prestazioni.
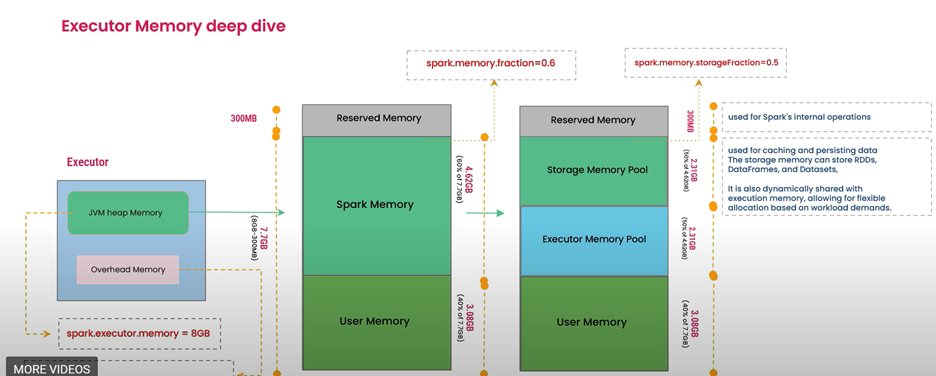
Anche se un executor è configurato con 56 GB di memoria, Spark non consente l'uso diretto di tutti i dati utente. Spark Core divide e gestisce la memoria dell'executor:
Memoria riservata: Porzione fissa riservata per l'overhead interno di sistema e Spark (ad esempio, Java Virtual Machine (JVM), componenti interni).
Memoria utente: Archivia funzioni definite dall'utente (UDF), variabili locali, strutture di dati (elenchi, mappe, dizionari) e oggetti creati durante il calcolo.
Memoria di archiviazione: Contiene dati memorizzati nella cache o persistenti, variabili di trasmissione e dati casuali che possono essere memorizzati nella cache.
Memoria di esecuzione: Usata per il calcolo intermedio (rilasci, join, ordinamenti, aggregazioni).
Condivisione dinamica della memoria: Il limite tra l'archiviazione e la memoria di esecuzione è mobile. Spark può prendere in prestito la memoria da un'area all'altra, consentendo un utilizzo flessibile della memoria.
Spill: Si verifica quando la richiesta di memoria per l'archiviazione o l'esecuzione supera la memoria disponibile dopo il prestito. Ciò forza i dati su disco, che possono influire sulle prestazioni.

Errori di memoria insufficiente (OOM)
Scenario: I processi Spark non riescono a causa di errori OOM (Out of Memory).
Driver OOM:
Gli errori OOM del driver si verificano quando il driver Spark supera la memoria allocata.
Causa comune: operazioni pesanti del driver, come collect(), countByKey() o chiamate di grandi dimensioni toPandas() che caricano troppi dati nella memoria del driver.
Mitigazione: evitare operazioni che gravano sul driver quando possibile. Se inevitabile, aumentare le dimensioni del driver e il benchmark per trovare la configurazione ottimale.
Esecutore fuori memoria (OOM):
Gli errori OOM dell'executor si verificano quando un executor Spark supera la memoria allocata.
Causa comune: trasformazioni che richiedono un uso intensivo di memoria e calcolo su set di dati di grandi dimensioni (ad esempio, join ampi, aggregazioni, mescolamenti) o set di dati memorizzati nella cache/persistenti che superano la memoria disponibile dell'executor (aree di esecuzione e archiviazione).
Mitigazione: aumentare la memoria dell'executor, se necessario, ottimizzare le frazioni di memoria Spark (spark.memory.fraction, spark.memory.storageFraction) e renderle persistenti in modo selettivo. Assicurarsi che i dati memorizzati nella cache si adattino alla memoria disponibile.
Distribuzione non uniforme dei dati
Sintomi di disallineamento
- Alcune attività richiedono più tempo rispetto ad altre nell'interfaccia utente di Spark (le attività di fase mostrano una coda pesante).
- Grande divario tra i tempi mediani e massimo di attività nelle metriche di fase.
- Fasi con grandi dimensioni di lettura o scrittura di shuffle per alcune partizioni.
Cause comuni:
- Distribuzione non uniforme dei dati per le chiavi di join/gruppo (tasti di scelta rapida).
- Partizionamento non corretto o partizioni troppo poche per il volume di dati.
- Anomalie dei dati upstream che producono record di grandi dimensioni o molte chiavi null/vuote.
Mitigazione:
- Ripartizione o unione per aumentare il parallelismo delle partizioni e bilanciare le dimensioni.
- Applicare il salting delle chiavi o il partizionamento personalizzato per distribuire chiavi calde tra le partizioni.
- Usare AQE (esecuzione di query adattiva) per unire le partizioni post-shuffle e abilitare le ottimizzazioni di skew-join.
- Usate i join di trasmissione per le tabelle di ricerca di piccole dimensioni per evitare del tutto i rimescolamenti.
- Rendere persistenti i set di dati intermedi bilanciati prima delle fasi costose ed eseguire di nuovo il processo.
Procedure consigliate per le UDF (funzioni definite dall'utente)
Scenario: è necessario applicare logica personalizzata che non può essere espressa tramite funzioni dataframe predefinite.
Usare le API del dataframe Spark ogni volta che è possibile. L'ottimizzatore Catalyst ottimizza le funzioni predefinite e le esegue in modo nativo nella JVM, in modo da offrire prestazioni ottimali.
Se è necessario utilizzare una funzione definita dall'utente (UDF), evitare le UDF Python PySpark normali. Considerare invece le alternative seguenti:
Pandas UDFs (note anche come Vectorized UDFs): Utilizzare Apache Arrow per trasferire i dati in modo efficiente tra JVM e Python. Le UDF Pandas consentono operazioni vettorializzate, migliorando significativamente le prestazioni rispetto alle UDF Python per riga.
Funzioni UDF Scala/Java: vengono eseguite direttamente sulla JVM, evitando il sovraccarico di serializzazione Python. Le funzioni definite dall'utente scala/Java in genere superano le funzioni definite dall'utente Python.
Prestare attenzione alle UDF Python. Ogni executor avvia un processo Python separato, che richiede la serializzazione e la deserializzazione dei dati tra JVM e Python. In questo modo si crea un collo di bottiglia nelle prestazioni, in particolare su larga scala.
Registrazione degli errori
Scenario: procedure consigliate per la registrazione degli errori in Fabric Spark
Usa
log4jinvece diprint(), che appesantisce fortemente il conducente. Conlog4jè possibile accedere ai log nei log dei driver e cercarli (usando il nome del logger, ad esempio PySparkLogger).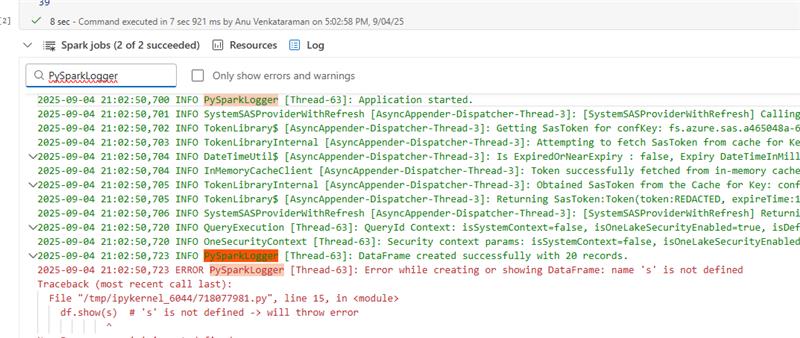
Racchiudere letture, scritture e trasformazioni in blocchi try ed except. Usare
logger.errorper le eccezioni elogger.infoper i messaggi di stato.Registrazione di Python: Ideale per le operazioni di registrazione, gli aggiornamenti dello stato o il debug di informazioni dal codice che viene eseguito solo nel driver Spark. Il modulo di registrazione di Python non viene propagato ai log dell'executor. Vedere la documentazione sullo sviluppo, l'esecuzione e la gestione dei notebook.
Spark log4j: Lo standard per la registrazione affidabile e a livello di produzione delle applicazioni in Spark si integra in modo nativo con i log driver/executor di Spark.
Esempio di utilizzo di log4j in PySpark:
import traceback # Get log4j logger log4jLogger = spark._jvm.org.apache.log4j logger = log4jLogger.LogManager.getLogger("PySparkLogger") logger.info("Application started.") try: # Create DataFrame with 20 records data = [(f"Name{i}", i) for i in range(1, 21)] # 20 records df = spark.createDataFrame(data, ["name", "age"]) logger.info("DataFrame created successfully with 20 records.") df.show(s) # 's' is not defined -> will throw error but the application will not fail except Exception as e: logger.error(f"Error while creating or showing DataFrame: {str(e)}\n{traceback.format_exc()}")Centralizzare il monitoraggio degli errori:
Usare l'estensione dell'emettitore di diagnostica (monitorare le applicazioni Apache Spark con Azure Log Analytics) nell'ambiente e collegarsi ai notebook che eseguono applicazioni Spark. L'emettitore può inviare log eventi, log personalizzati (ad esempio log4j) e metriche ad Azure Log Analytics/Archiviazione di Azure/Hub eventi di Azure. Passare il nome log4j alla proprietà :
spark.synapse.diagnostic.emitter.\<destination\>.filter.loggerName.match.Inoltre, per il debug, è anche possibile raccogliere righe/record falliti nelle tabelle Lakehouse (LH) per la cattura di dati errati a livello di record.
