Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'attività di Azure HDInsight in Data Factory per Microsoft Fabric consente di orchestrare i tipi di processo di Azure HDInsight seguenti:
- Eseguire le query Hive
- Richiamare un programma MapReduce
- Eseguire le query Pig
- Eseguire un programma Spark
- Eseguire un programma Hadoop Stream
Questo articolo fornisce una procedura dettagliata che descrive come creare un'attività di Azure HDInsight usando l'interfaccia Data Factory.
Prerequisiti
Per iniziare, è necessario soddisfare i prerequisiti seguenti:
- Un account di locatario con una sottoscrizione attiva. Creare un account gratuito.
- Viene creata un'area di lavoro.
Aggiungere un'attività Azure HDInsight (HDI) a una pipeline tramite l'interfaccia utente
Creare una nuova pipeline di dati nell'area di lavoro.
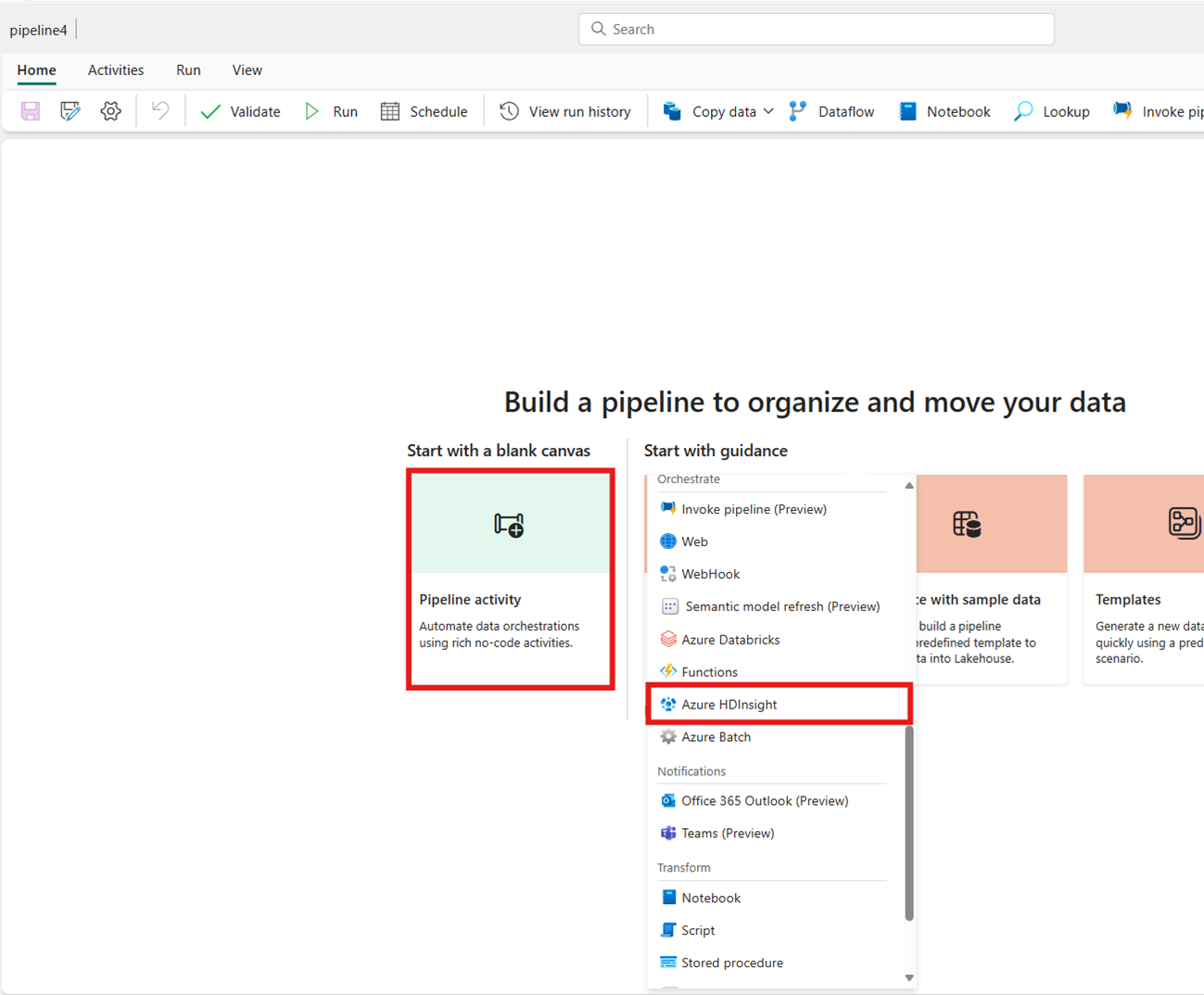
Selezionare la scheda Attività pipeline oppure selezionare la scheda Attività e selezionare Azure HDInsight.
Creazione dell'attività dalla scheda della schermata principale:
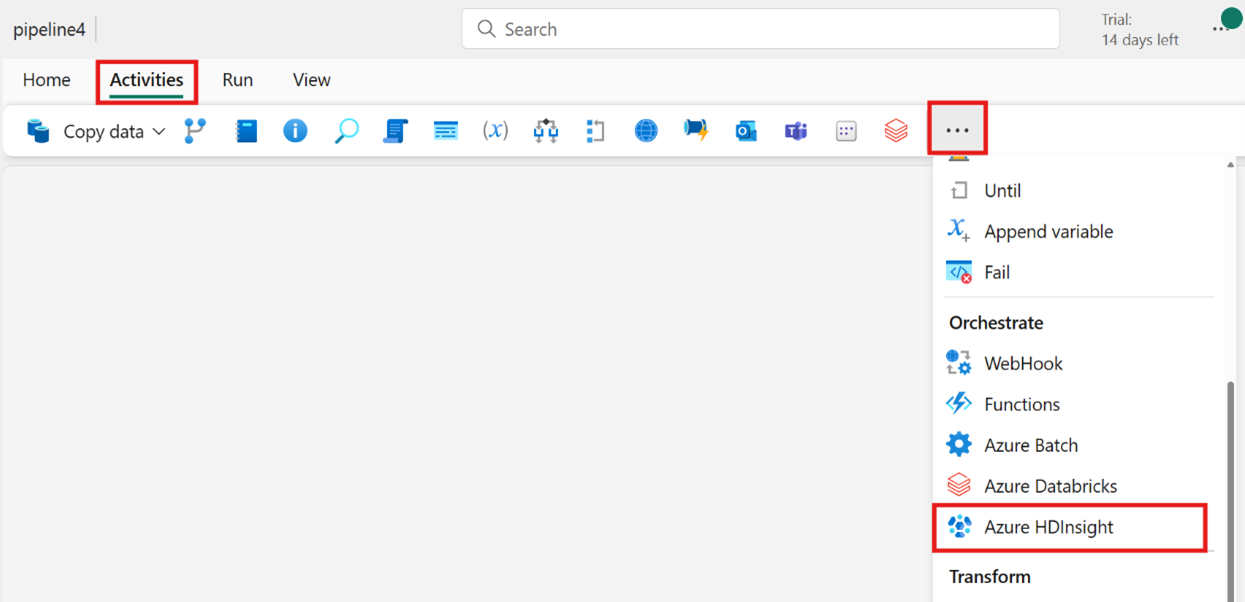
Creazione dell'attività dalla barra Attività:
Selezionare la nuova attività di Azure HDInsight nell'area di lavoro dell'editor della pipeline, se non è già selezionata.
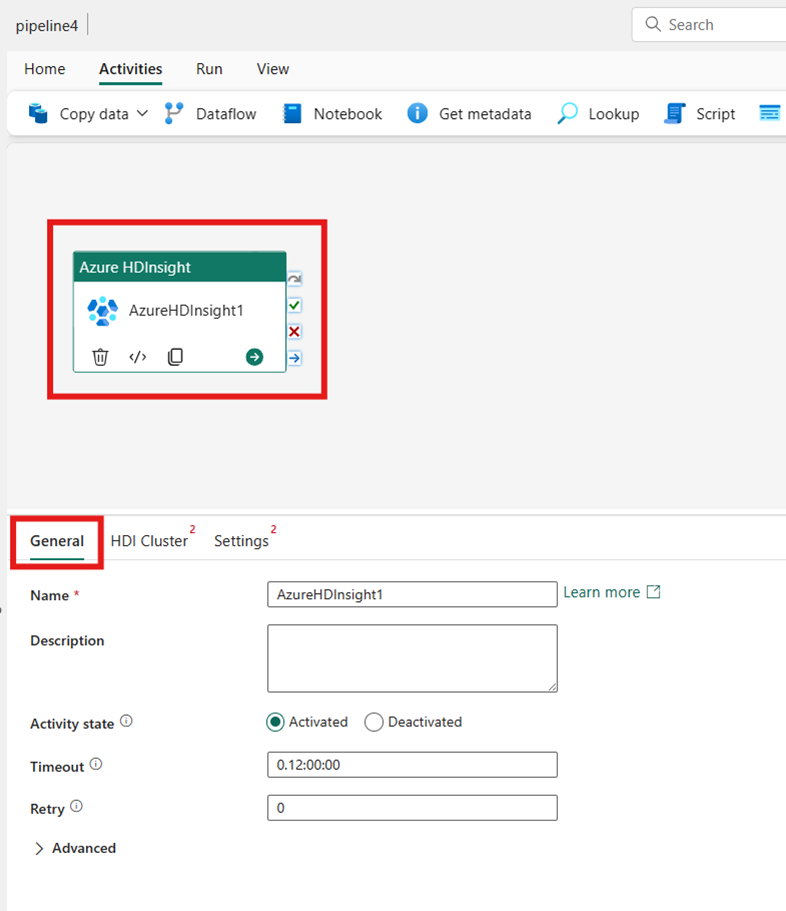
Fare riferimento alle indicazioni sulle impostazioni generali per configurare le opzioni disponibili nella scheda Impostazioni generali.

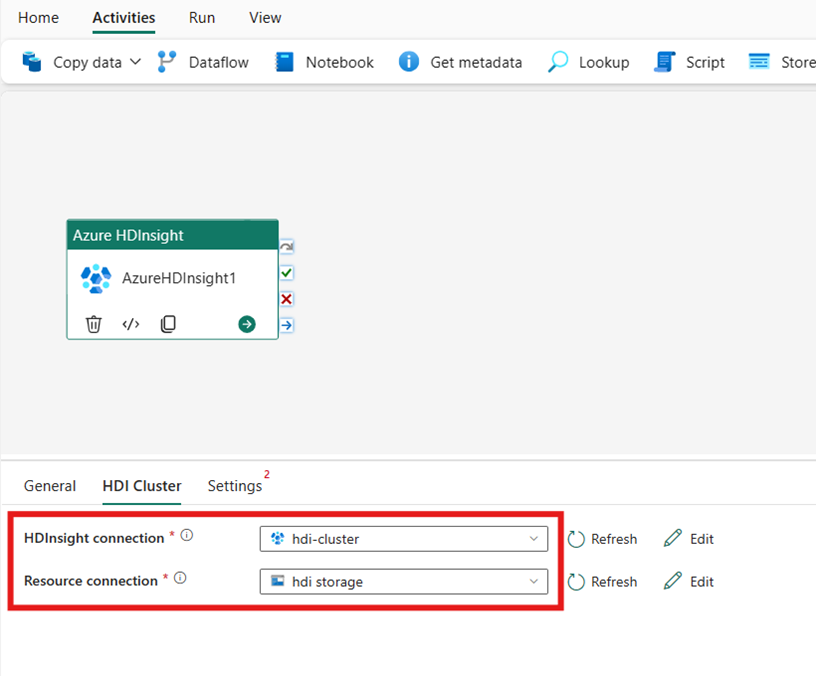
Configurare il cluster HDI
Selezionare la scheda Cluster HDI. Quindi scegliere una connessione esistente o creare una nuova connessione HDInsight.
Per Connessione risorsa scegliere l'archiviazione Blob di Azure che fa riferimento al cluster Azure HDInsight. È possibile usare un archivio Blob esistente o crearne uno nuovo.
Configurare le impostazioni
Selezionare la scheda Impostazioni per visualizzare le impostazioni avanzate per l'attività.
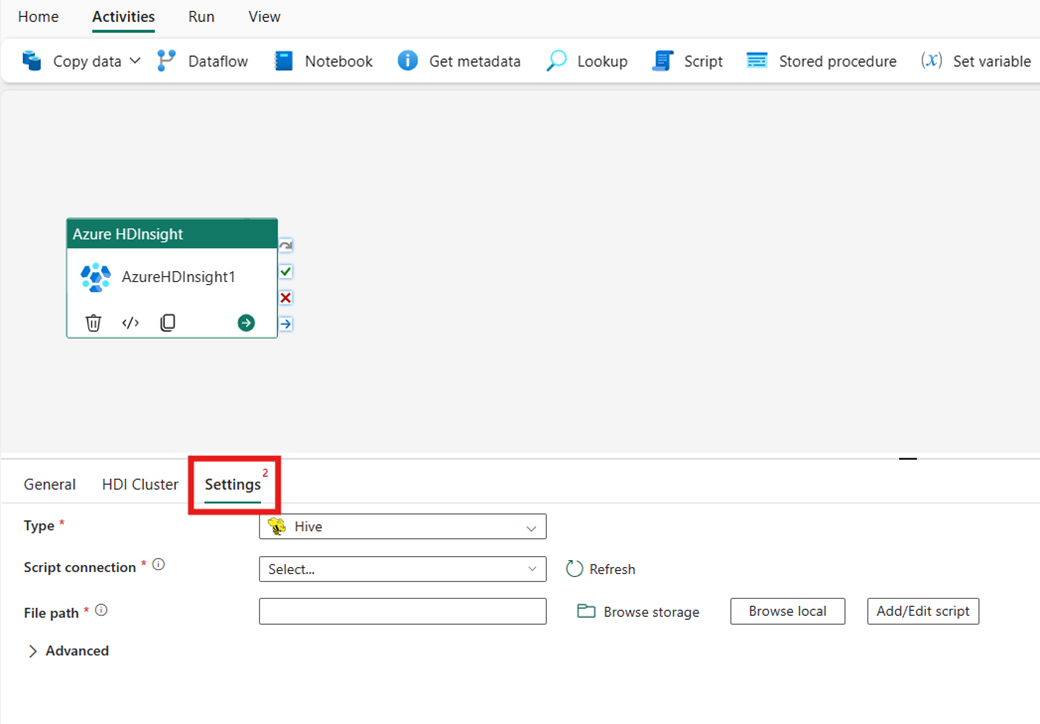
Tutte le proprietà avanzate del cluster e le espressioni dinamiche supportate nel servizio collegato Azure Data Factory e Synapse Analytics HDInsight sono ora supportate anche nell'attività azure HDInsight per Data Factory in Microsoft Fabric, nella sezione Avanzato nell'interfaccia utente. Tutte queste proprietà supportano espressioni parametriche personalizzate e facili da usare con contenuto dinamico.
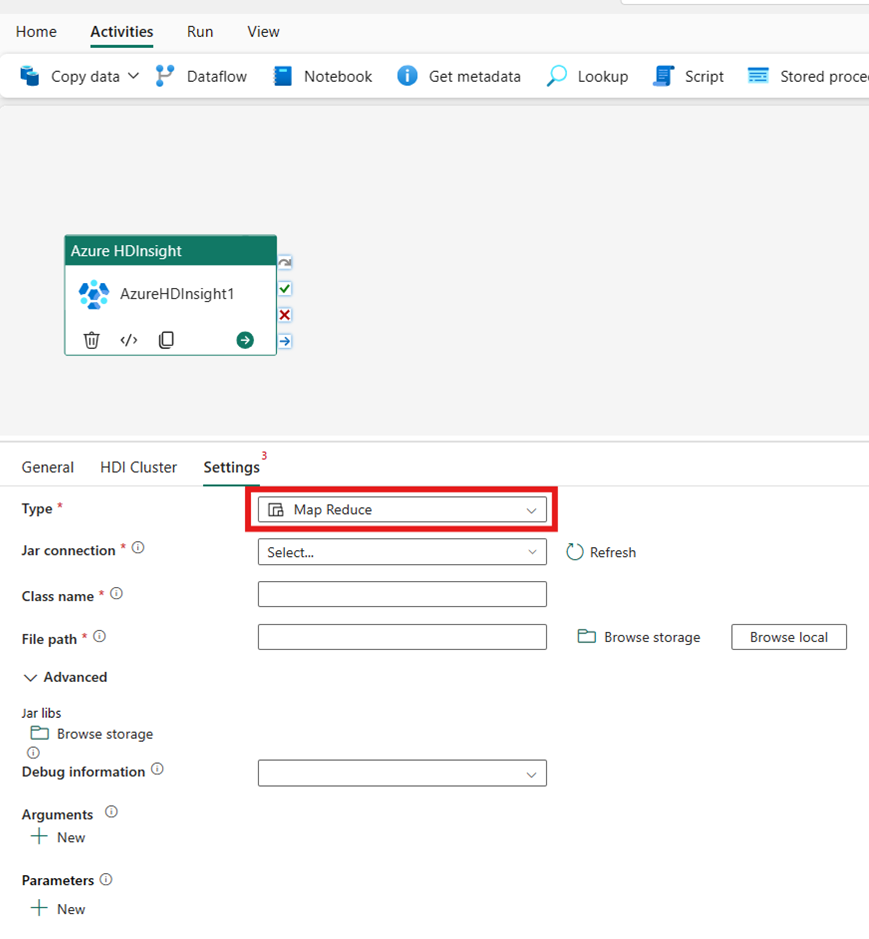
Tipo di cluster
Per configurare le impostazioni per il cluster HDInsight, scegliere prima il tipo dalle opzioni disponibili, tra cui Hive, Map Reduce, Pig, Spark eStreaming.
Alveare
Se si sceglie Hive per il Tipo, l'attività esegue una query Hive. Facoltativamente, è possibile specificare la connessione script che fa riferimento a un account di archiviazione che contiene il tipo Hive. Per impostazione predefinita, viene usata la connessione di archiviazione specificata nella scheda Cluster HDI. È necessario specificare il Percorso file da eseguire in Azure HDInsight. Facoltativamente, è possibile specificare altre configurazioni nella sezione Avanzato, Informazioni di debug, Timeout della query, Argomenti, Parametri e Variabili.
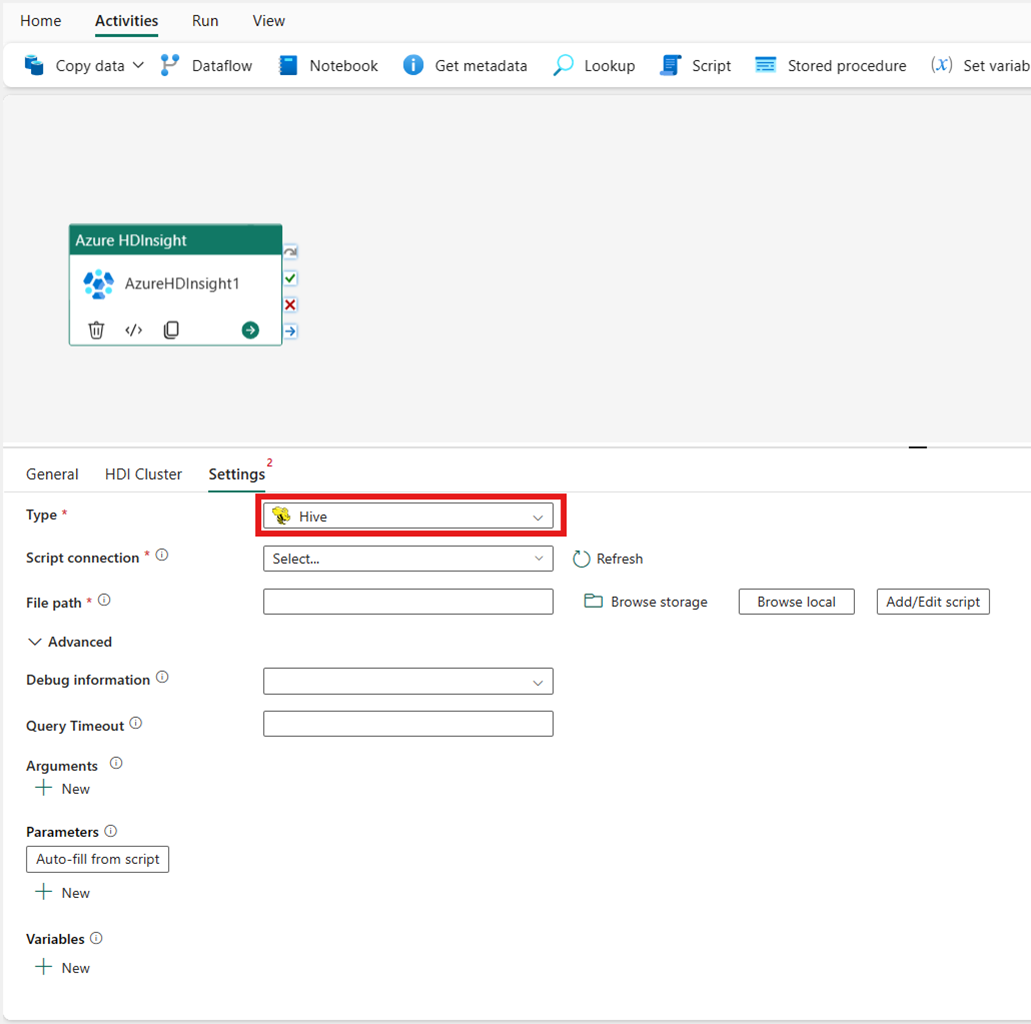
MapReduce
Se si sceglie Map Reduce per il Tipo, l'attività richiama un programma Map Reduce. Facoltativamente, è possibile specificare nella connessione Jar un riferimento a un account di archiviazione che contenga il tipo Map Reduce. Per impostazione predefinita, viene usata la connessione di archiviazione specificata nella scheda Cluster HDI. È necessario specificare il Nome della classe e il Percorso file da eseguire in Azure HDInsight. Facoltativamente, è possibile specificare altri dettagli di configurazione, ad esempio l'importazione di librerie Jar, informazioni di debug, argomenti e parametri nella sezione Avanzato.
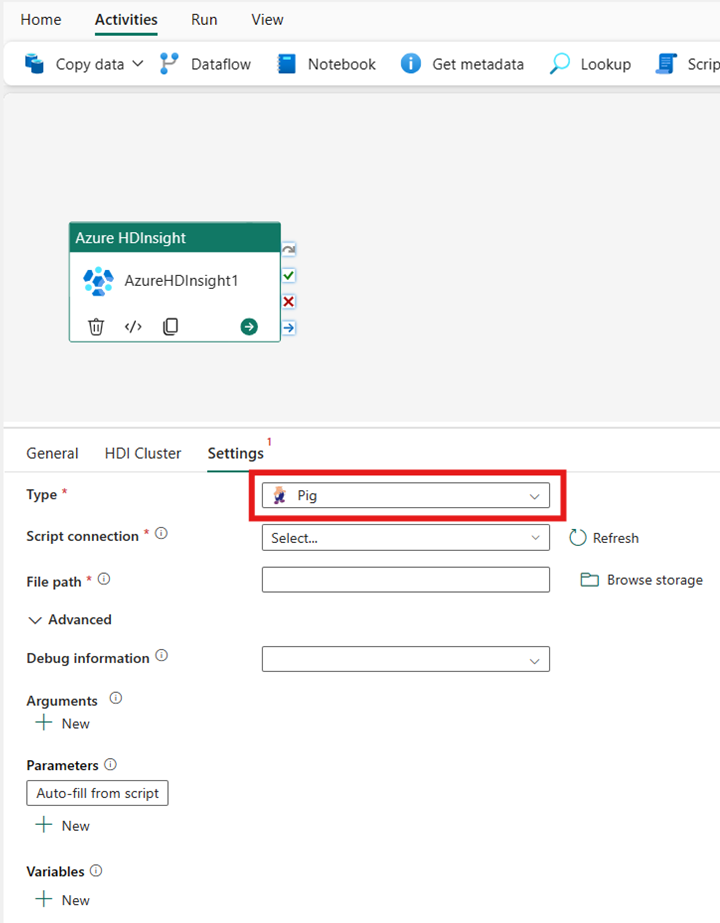
Maiale
Se si sceglie Pig per il Tipo, l'attività richiama una query Pig. Facoltativamente, è possibile specificare l'impostazione della connessione script che fa riferimento all'account di archiviazione che contiene il tipo Pig. Per impostazione predefinita, viene usata la connessione di archiviazione specificata nella scheda Cluster HDI. È necessario specificare il Percorso file da eseguire in Azure HDInsight. Facoltativamente, è possibile specificare altre configurazioni, ad esempio informazioni di debug, argomenti, parametri e variabili nella sezione Avanzato.
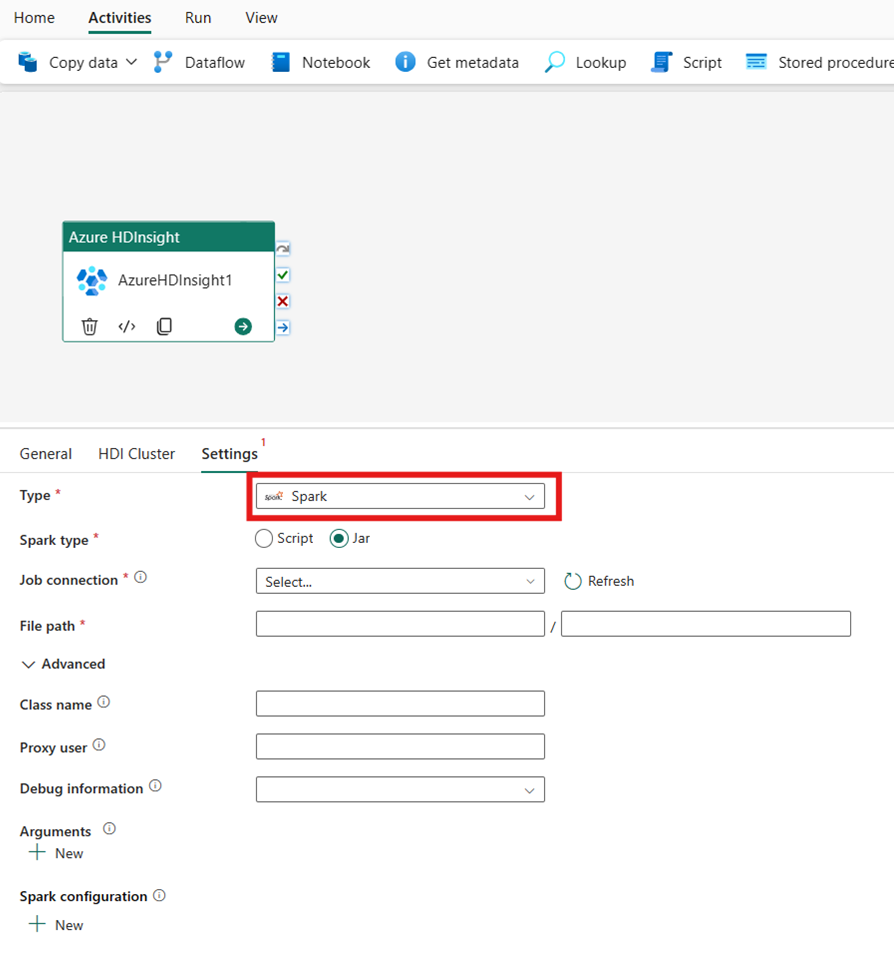
Scintilla
Se si sceglie Spark per il Tipo, l'attività richiama un programma Spark. Selezionare Script o Jar per il tipo Spark. Facoltativamente, è possibile specificare la connessione Job che si riferisce all'account di archiviazione contenente il tipo di Spark. Per impostazione predefinita, viene usata la connessione di archiviazione specificata nella scheda Cluster HDI. È necessario specificare il Percorso file da eseguire in Azure HDInsight. Facoltativamente, è possibile specificare altre configurazioni, ad esempio il nome della classe, l'utente proxy, le informazioni di debug, gli argomenti e la configurazione spark nella sezione Avanzato.
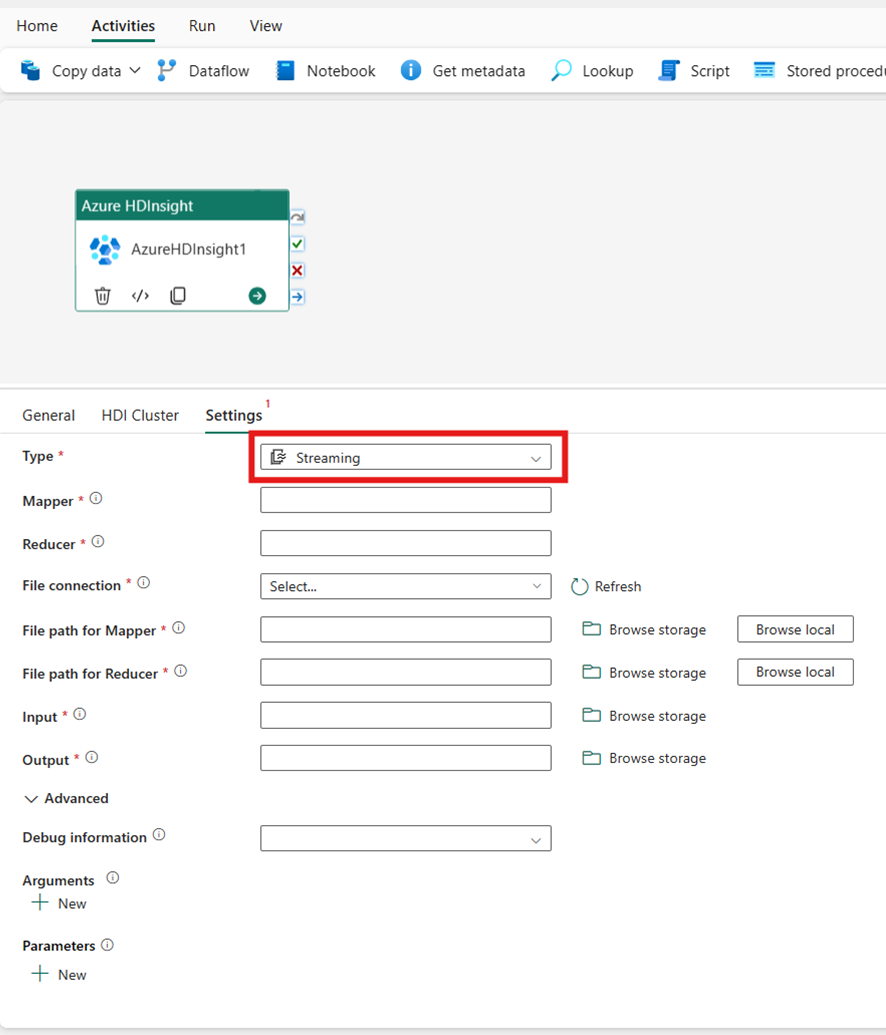
Trasmissione in diretta
Se si sceglie Streaming per il Tipo, l'attività richiama un programma di streaming. Specificare i nomi Mapper e Reducer e, facoltativamente indicare la connessione file che fa riferimento all'account di archiviazione che contiene il tipo Streaming. Per impostazione predefinita, viene usata la connessione di archiviazione specificata nella scheda Cluster HDI. È necessario specificare il Percorso file per Mapper e il Percorso file per Reducer da eseguire in Azure HDInsight. Includere anche le opzioni Input e Output per il percorso WASB. Facoltativamente, è possibile specificare altre configurazioni, ad esempio informazioni di debug, argomenti e parametri nella sezione Avanzato.
Informazioni di riferimento sulle proprietà
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| tipo | Per l'attività di streaming di Hadoop, il tipo di attività è HDInsightStreaming | Sì |
| mappatore | Specifica il nome del mapper eseguibile | Sì |
| riduttore | Specifica il nome del reducer eseguibile | Sì |
| combinatore | Specifica il nome del combiner eseguibile | NO |
| connessione al file | Riferimento a un servizio collegato di Archiviazione di Azure usato per memorizzare i programmi relativi a Mapper, Combiner e Reducer da eseguire. | NO |
| Qui sono supportate solo le connessioni Archiviazione BLOB di Azure e ADLS Gen2. Se non si specifica questa connessione, viene usata la connessione di archiviazione definita nella connessione HDInsight. | ||
| percorso del file | Fornire un elenco di percorsi per i programmi Mapper, Combiner e Reducer archiviati nell'archiviazione di Azure a cui fa riferimento la connessione. | Sì |
| ingresso | Specifica il percorso WASB del file di input per il Mapper. | Sì |
| risultato | Specifica il percorso WASB del file di output per il reducer. | Sì |
| getDebugInfo | Specifica quando i file di log vengono copiati nell'Archiviazione di Azure usata dal cluster HDInsight (o) indicata da scriptLinkedService. | NO |
| Valori consentiti: Nessuno, Sempre o Errore. Valore predefinito: None. | ||
| argomenti | Specifica una matrice di argomenti per un processo Hadoop. Gli argomenti vengono passati a ogni attività come argomenti della riga di comando. | NO |
| definisce | Specificare i parametri come coppie chiave/valore per fare riferimento a essi nello script Hive. | NO |
Salvare ed eseguire o pianificare la pipeline
Dopo aver configurato tutte le altre attività necessarie per la pipeline, passare alla scheda Home nella parte superiore dell’editor della pipeline e selezionare il pulsante Salva per salvare la pipeline. Selezionare Esegui per eseguirla direttamente o Pianificare per pianificarla. Qui è anche possibile visualizzare la cronologia delle esecuzioni o configurare altre impostazioni.
