Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione richiede 15 minuti e descrive come accumulare dati in modo incrementale in un lakehouse usando Dataflow Gen2.
L'accumulo incrementale di dati in una destinazione dati richiede una tecnica per caricare solo dati nuovi o aggiornati nella destinazione dei dati. Questa tecnica può essere eseguita usando una query per filtrare i dati in base alla destinazione dei dati. Questa esercitazione illustra come creare un flusso di dati per caricare dati da un'origine OData in un lakehouse e come aggiungere una query al flusso di dati per filtrare i dati in base alla destinazione dei dati.
I passaggi principali di questo tutorial sono i seguenti:
- Creare un flusso di dati per caricare dati da un'origine OData in un data lakehouse.
- Aggiungere una query al flusso di dati per filtrare i dati in base alla destinazione dei dati.
- (Facoltativo) utilizzare notebook e pipeline per ricaricare i dati.
Prerequisiti
È necessario disporre di un'area di lavoro abilitata per Microsoft Fabric. Se non è già disponibile, vedere Creare un'area di lavoro. Inoltre, l'esercitazione presuppone che si stia usando la visualizzazione diagramma in Dataflow Gen2. Per verificare se si sta utilizzando la Visualizzazione Diagramma, nella barra multifunzione superiore, andare su Visualizza e assicurarsi che sia selezionata la Visualizzazione Diagramma.
Creare un flusso di dati per caricare dati da un'origine OData in un lakehouse
In questa sezione, creerai un flusso di dati per caricare i dati da un'origine OData in un lakehouse.
Creare un nuovo lakehouse nell'area di lavoro.
Creare un nuovo Dataflow Gen2 nell'area di lavoro.
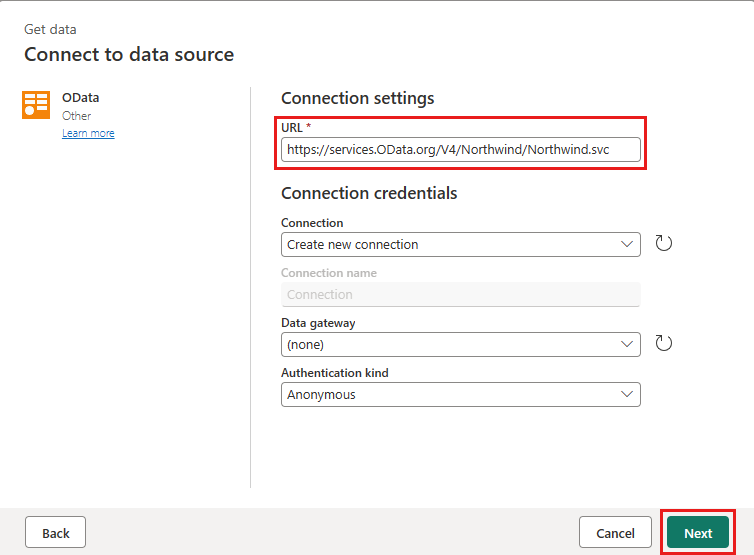
Aggiunge una nuova origine al flusso di dati. Selezionare l'origine OData e immettere l'URL seguente:
https://services.OData.org/V4/Northwind/Northwind.svc
Selezionare la tabella Ordini e selezionare Avanti.
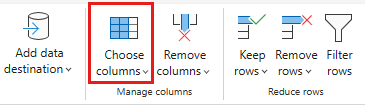
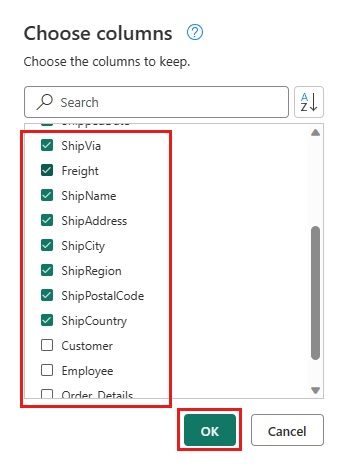
Selezionare le colonne seguenti da conservare:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry
Modificare il tipo di dati di
OrderDate,RequiredDateeShippedDateindatetime.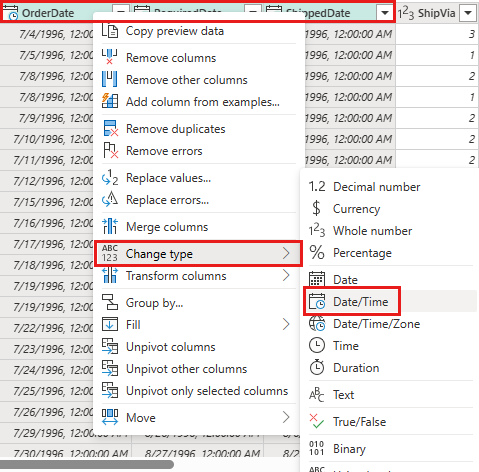
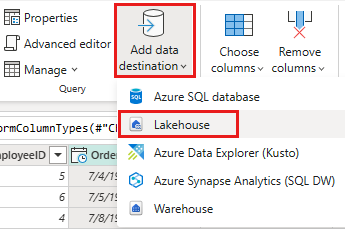
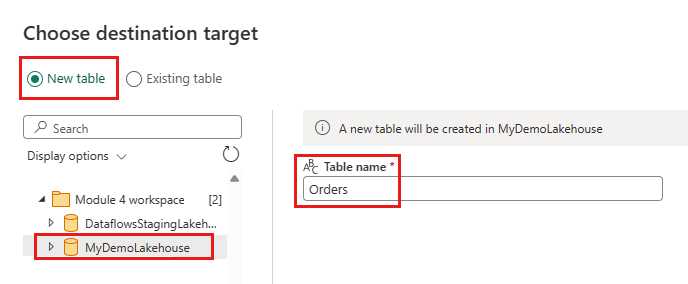
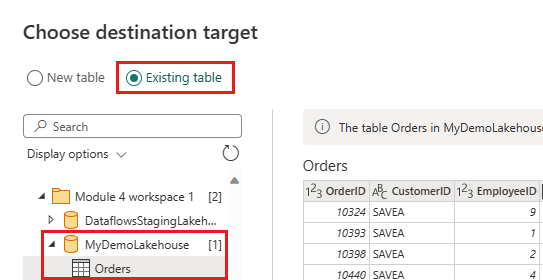
Configurare la destinazione dei dati nel lakehouse tramite le impostazioni seguenti:
- Destinazione dei dati:
Lakehouse - Lakehouse: selezionare il lakehouse creato nel passaggio 1.
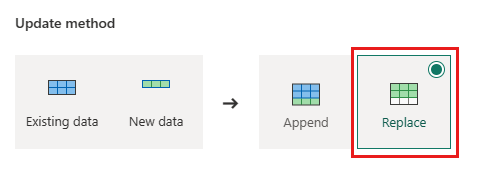
- Nuovo nome tabella:
Orders - Metodo di aggiornamento:
Replace
- Destinazione dei dati:
selezionare Avanti e pubblicare il flusso di dati.



Ora hai creato un flusso di dati per caricare i dati da un'origine OData in un lakehouse. Questo flusso di dati viene usato nella sezione successiva per aggiungere una query al flusso di dati per filtrare i dati in base alla destinazione dei dati. Successivamente, è possibile usare il flusso di dati per ricaricare i dati tramite notebook e pipeline.
Aggiungere una query al flusso di dati per filtrare i dati in base alla destinazione dei dati
In questa sezione viene aggiunta una query al flusso di dati per filtrare i dati in base ai dati nel lakehouse di destinazione. La query ottiene il valore massimo OrderID nel lakehouse all'inizio del refresh del flusso di dati e utilizza il massimo OrderId per ottenere solo gli ordini con un OrderId superiore dall'origine, da aggiungere come appendice alla destinazione dei dati. Ciò presuppone che gli ordini vengano aggiunti all'origine in ordine crescente di OrderID. In caso contrario, è possibile usare una colonna diversa per filtrare i dati. Ad esempio, è possibile usare la colonna OrderDate per filtrare i dati.
Nota
I filtri OData vengono applicati all'interno di Fabric dopo la ricezione dei dati dall'origine dati, tuttavia, per le origini di database come SQL Server, il filtro viene applicato nella query inviata all'origine dati back-end e vengono restituite solo righe filtrate al servizio.
Dopo l'aggiornamento del flusso di dati, riaprire il flusso di dati creato nella sezione precedente.
Crea una nuova query denominata
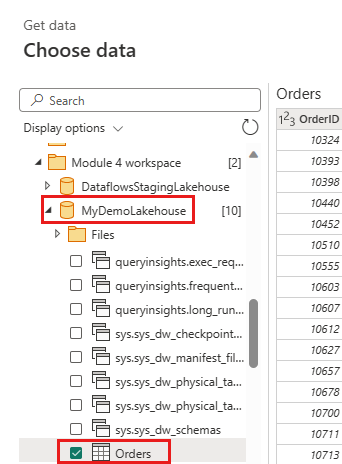
IncrementalOrderIDe ottieni dati dalla tabella Ordini nel lakehouse che hai creato nella sezione precedente.

Disabilitare la messa in scena di questa query.
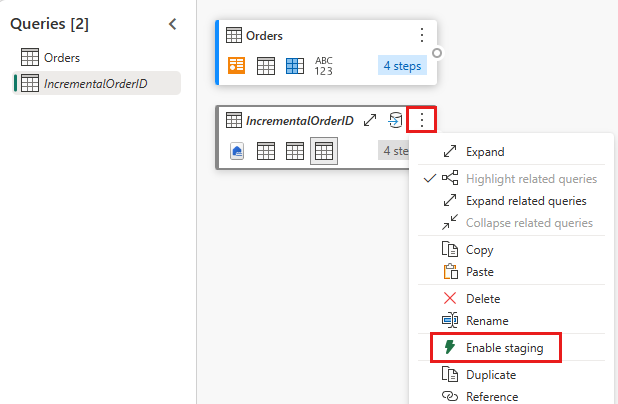
Nell'anteprima dei dati, fare clic con il pulsante destro del mouse sulla colonna
OrderIDe scegliere Drill-down.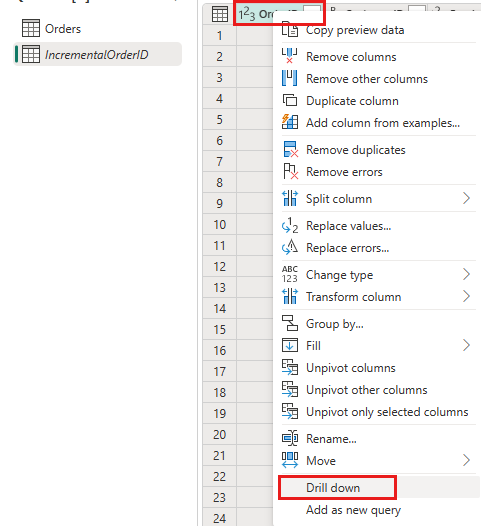
Nella barra multifunzione, selezionare Strumenti elenco ->Statistiche ->Massimo.
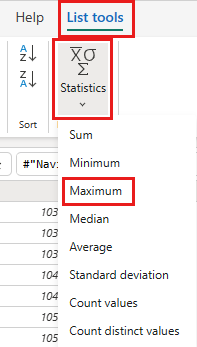
È ora disponibile una query che restituisce il valore orderID massimo nel lakehouse. Questa query viene usata per filtrare i dati dall'origine OData. La sezione successiva aggiunge una query al flusso di dati per filtrare i dati dall'origine OData in base al valore orderID massimo nel lakehouse.
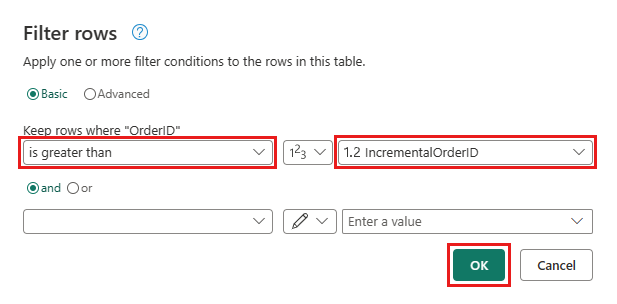
Ritorna alla query Ordini e aggiungi un nuovo passaggio per filtrare i dati. Usare le seguenti impostazioni:
- Colonna:
OrderID - Operazione:
Greater than - Valore: parametro
IncrementalOrderID

- Colonna:
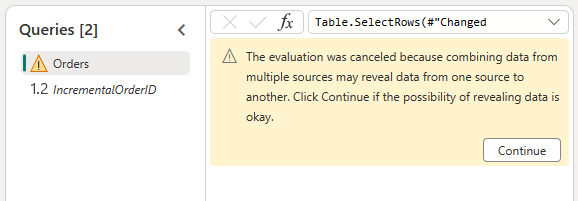
Consente di combinare i dati dall'origine OData e dal lakehouse confermando la finestra di dialogo seguente:
Aggiorna la destinazione dei dati per utilizzare le seguenti impostazioni:
- Metodo di aggiornamento:
Append

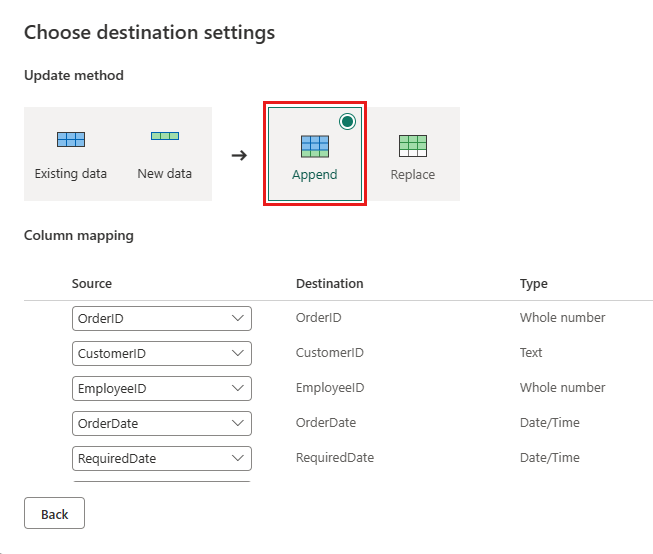
- Metodo di aggiornamento:
Pubblicare il flusso di dati.
Il flusso di dati contiene ora una query che filtra i dati dall'origine OData in base al valore orderID massimo nel lakehouse. Ciò significa che solo i dati nuovi o aggiornati vengono caricati nel lakehouse. La sezione successiva usa il flusso di dati per ricaricare i dati tramite notebook e pipeline.
(Opzionale) ricaricare i dati attraverso notebook e pipeline
Facoltativamente, è possibile ricaricare dati specifici tramite notebook e pipeline. Con il codice Python personalizzato nel notebook, rimuovere i dati precedenti dal lakehouse. Creando quindi una pipeline in cui si esegue prima il notebook ed eseguendo in sequenza il flusso di dati, si ricaricano i dati dall'origine OData nel lakehouse. I notebook supportano più lingue, ma questa esercitazione usa PySpark. Pyspark è un'API Python per Spark e viene usata in questa esercitazione per eseguire query Spark SQL.
Creare un nuovo notebook nell'area di lavoro.
Aggiungere il codice PySpark seguente al notebook:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Eseguire il notebook per verificare che i dati siano stati rimossi dal lakehouse.
Crea una nuova pipeline nella tua area di lavoro.
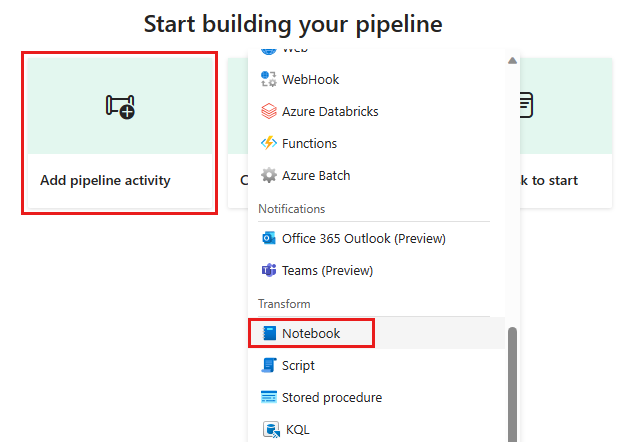
Aggiungere una nuova attività di notebook alla pipeline e selezionare il notebook creato nel passaggio precedente.
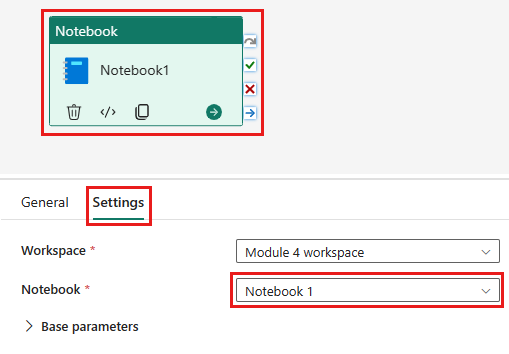
Aggiungere una nuova attività del flusso di dati alla pipeline e selezionare il flusso di dati creato nella sezione precedente.
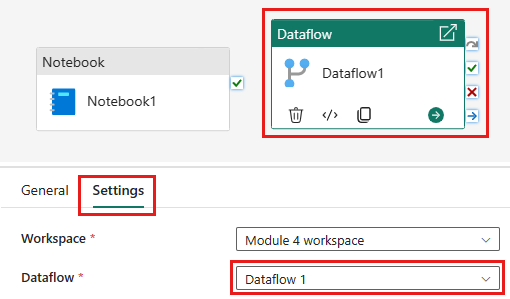
Collegare l'attività del notebook all'attività del flusso di dati con un trigger di operazione riuscita.
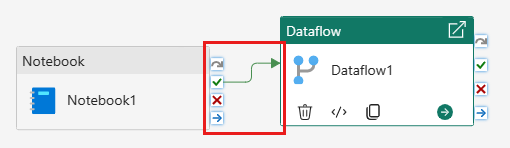
Salvare ed eseguire la pipeline


Ora disponi di una pipeline che rimuove i dati obsoleti dal deposito dati e ricarica i dati dall'origine OData nel deposito dati. Con questa configurazione, è possibile ricaricare regolarmente i dati dall'origine OData nel lakehouse.