Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Data Wrangler accelera il flusso di lavoro di preparazione dei dati fornendo un'interfaccia visiva immersiva per l'analisi esplorativa dei dati. In questo articolo vengono illustrate le operazioni seguenti:
- Avviare Data Wrangler dal notebook di Fabric
- Esplorare i dati con visualizzazioni interattive e statistiche di riepilogo
- Applicare operazioni comuni di pulizia dei dati con la generazione automatica del codice
- Esporta nuovamente le funzioni riutilizzabili di Pandas o PySpark nel tuo notebook
Questo articolo è incentrato sui dataframe pandas. Per i dataframe Spark, vedere questa risorsa.
Prerequisites
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione gratuita di Microsoft Fabric.
Accedere a Microsoft Fabric.
Passare a Fabric usando il commutatore dell'esperienza in basso a sinistra della tua home page.

Limitations
- Le operazioni di codice personalizzate attualmente supportano solo i dataframe pandas.
- La visualizzazione Data Wrangler funziona meglio su monitor di grandi dimensioni. Tuttavia, è possibile ridurre o nascondere parti diverse dell'interfaccia per contenere schermi più piccoli.
Avvio di Data Wrangler
È possibile avviare Data Wrangler direttamente da un notebook di Microsoft Fabric per esplorare e trasformare qualsiasi pandas o dataframe Spark.
Per iniziare a usare i dati di esempio:
Questo frammento di codice mostra come leggere i dati di esempio in un dataframe pandas:
import pandas as pd
# Read a CSV into a Pandas DataFrame
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv")
display(df)
Nella scheda "Home" della barra multifunzione del notebook, utilizzare il menù a tendina di Data Wrangler per esplorare i DataFrame attivi disponibili per la modifica. Selezionare quello che si vuole aprire in Data Wrangler.
Suggerimento
Non è possibile aprire Data Wrangler mentre il kernel del notebook è occupato. Una cella in esecuzione deve terminare prima che Data Wrangler possa essere avviata, come illustrato in questo screenshot:

Avvia Data Wrangler da una cella
È anche possibile aprire Data Wrangler direttamente da una cella del notebook, senza passare alla barra multifunzione. Questo punto di accesso in linea rende disponibile Data Wrangler direttamente dove lavori con i DataFrame.
Quando si esegue una cella che restituisce un dataframe, viene visualizzata una richiesta di Data Wrangler a livello di cella. Selezionare il prompt per aprire il dataframe in Data Wrangler. I comandi supportati includono:
-
df.head()oppuredf.head(n) -
df.tail()oppuredf.tail(n) -
df.show()oppuredf.show(n)
Eseguire una cella che restituisce un dataframe:
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") df.head()Al termine dell'esecuzione della cella, viene visualizzato un prompt di Data Wrangler nella cella. Selezionare Apri in Data Wrangler per avviare Data Wrangler con il
dfdataframe.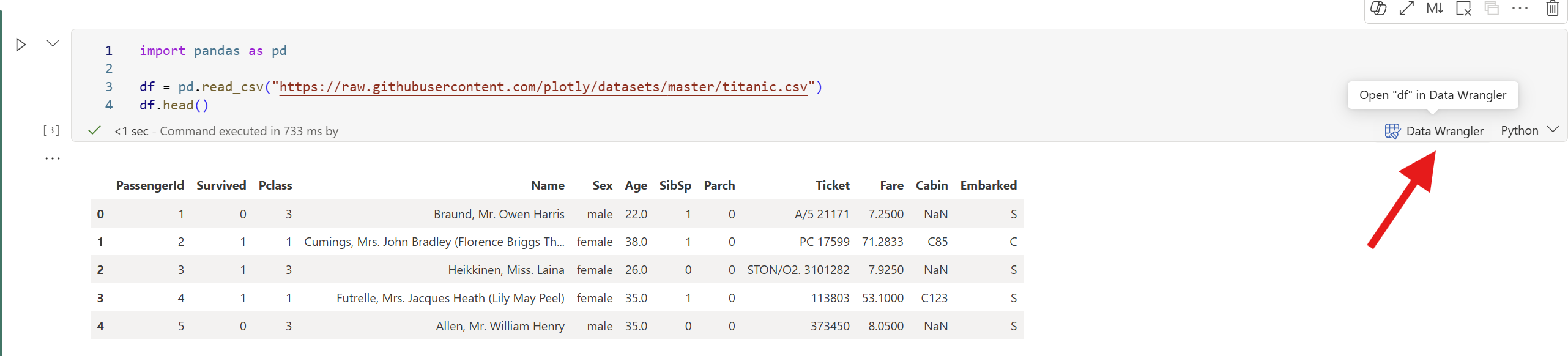

Quando una cella definisce più dataframe, il prompt fornisce un sottomenu che elenca tutti i dataframe nella cella. È possibile aprirli in Data Wrangler, anche quelli che non sono stati stampati in modo esplicito.
Esegui una cella che definisce più DataFrame:
import pandas as pd titanic_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") iris_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/iris-data.csv") titanic_df.head() iris_df.head()Al termine dell'esecuzione della cella, selezionare il prompt Data Wrangler nella cella. Un sottomenu elenca tutti i dataframe definiti nella cella. Selezionare quello da esplorare.
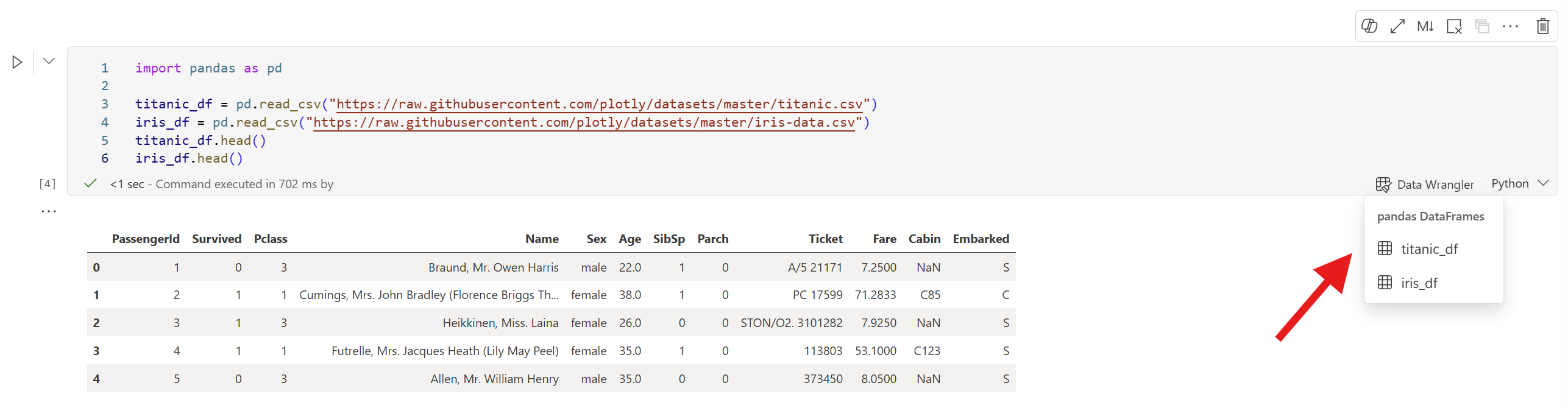

Suggerimento
Il sottomenu elenca i dataframe definiti nella cella corrente. Per aprire un dataframe da una cella precedente, eseguire una nuova cella che vi fa riferimento oppure usare l'elenco a discesa Data Wrangler nella scheda Home della barra multifunzione per esplorare tutti i dataframe attivi.
Scelta di esempi personalizzati
Per aprire un esempio personalizzato di qualsiasi dataframe attivo con Data Wrangler, selezionare Scegli esempio personalizzato dall'elenco a discesa, come illustrato in questo screenshot:

Questa azione apre una finestra di dialogo con opzioni per specificare le dimensioni del campione desiderato (numero di righe) e il metodo di campionamento (primi record, ultimi record o set casuale). Le prime 5.000 righe del dataframe fungono da dimensione di esempio predefinita, come illustrato in questo screenshot:

Visualizzazione delle statistiche di riepilogo
Quando Data Wrangler viene caricato, viene visualizzata una panoramica descrittiva del dataframe scelto nel pannello Riepilogo . Questa panoramica include informazioni sulle dimensioni del dataframe, i valori mancanti e altro ancora. Quando si seleziona una colonna nella griglia Data Wrangler, il pannello Riepilogo viene aggiornato per visualizzare statistiche descrittive su tale colonna specifica. Le informazioni rapide su ogni colonna sono disponibili anche nell'intestazione.
Suggerimento
Le statistiche e gli oggetti visivi specifici della colonna (sia nel pannello Riepilogo che nelle intestazioni di colonna) dipendono dal tipo di dati della colonna. Ad esempio, un istogramma binato di una colonna numerica viene visualizzato nell'intestazione di colonna solo se viene eseguito il cast della colonna come tipo numerico, come illustrato in questo screenshot:

Esplorazione delle operazioni di pulizia dei dati
Il pannello Operazioni fornisce un elenco ricercabile di operazioni di pulizia dei dati. Quando si seleziona un'operazione di pulizia dei dati nel pannello Operazioni , è necessario specificare una colonna o colonne di destinazione, insieme ai parametri necessari per completare l'operazione. Ad esempio, il prompt per ridimensionare numericamente una colonna richiede un nuovo intervallo di valori, come illustrato in questo screenshot:

Suggerimento
È possibile applicare un numero ristretto di operazioni dal menu di ogni intestazione di colonna, come illustrato in questo screenshot:

Anteprima e applicazione di operazioni
La griglia di visualizzazione Data Wrangler visualizza automaticamente i risultati di un'operazione selezionata e il codice corrispondente viene visualizzato automaticamente nel pannello sotto la griglia. Per eseguire il commit del codice in anteprima, selezionare Applica in una delle due posizioni. Per eliminare il codice in anteprima e provare una nuova operazione, selezionare Ignora come illustrato in questo screenshot:

Dopo aver applicato un'operazione, la griglia di visualizzazione di Data Wrangler e le statistiche di riepilogo si aggiornano per riflettere i risultati. Il codice viene visualizzato nell'elenco di operazioni di cui è stato eseguito il commit nel pannello Passaggi di pulizia , come illustrato in questo screenshot:

Suggerimento
È sempre possibile annullare il passaggio applicato più di recente. Nel pannello Passaggi di pulizia viene visualizzata un'icona del cestino quando si passa il cursore sul passaggio applicato più di recente, come illustrato in questo screenshot:

Questa tabella riepiloga le operazioni attualmente supportate da Data Wrangler:
| Operazione | Description |
|---|---|
| Sort | Ordinare una colonna in ordine crescente o decrescente |
| Filter | Filtrare le righe in base a una o più condizioni |
| Codifica one-hot | Creare nuove colonne per ogni valore univoco in una colonna esistente, che indica la presenza o l'assenza di tali valori per riga |
| Binarizer con più etichette | Suddividere i dati usando un separatore e creare nuove colonne per ogni categoria, contrassegnando 1 se una riga contiene tale categoria e 0 se non lo è |
| Modificare il tipo di colonna | Modificare il tipo di dati di una colonna |
| Eliminare colonna | Eliminare una o più colonne |
| Selezionare la colonna | Scegliere una o più colonne da mantenere ed eliminare il resto |
| Rinominare la colonna | Rinominare una colonna |
| Eliminare i valori mancanti | Rimuovere righe con valori mancanti |
| Eliminare righe duplicate | Eliminare tutte le righe con valori duplicati in una o più colonne |
| Compilare i valori mancanti | Sostituire le celle con valori mancanti con un nuovo valore |
| Trovare e sostituire | Sostituire le celle con un modello di corrispondenza esatto |
| Raggruppa per colonna e aggregazione | Raggruppare per valori di colonna e risultati aggregati |
| Rimuovere spazi bianchi | Rimuovere spazi vuoti dall'inizio e dalla fine del testo |
| Dividi testo | Dividere una colonna in più colonne in base a un delimitatore definito dall'utente |
| Convertire il testo in lettere minuscole | Convertire il testo in lettere minuscole |
| Convertire il testo in maiuscolo | Converti il testo in MAIUSCOLO |
| Ridimensionare i valori min/max | Ridimensionare una colonna numerica tra un valore minimo e massimo |
| Riempimento flash | Creare automaticamente una nuova colonna in base a esempi derivati da una colonna esistente |
Personalizzare lo schermo
In qualsiasi momento, è possibile personalizzare l'interfaccia usando la scheda "Visualizzazioni" sulla barra degli strumenti sopra la griglia di visualizzazione Data Wrangler. Questa opzione può nascondere o visualizzare riquadri diversi in base alle preferenze e alle dimensioni dello schermo, come illustrato in questo screenshot:

Salvataggio ed esportazione del codice
La barra degli strumenti sopra la griglia di visualizzazione Data Wrangler offre opzioni per salvare il codice generato. È possibile copiare il codice negli Appunti o esportarlo nel notebook come funzione. L'esportazione del codice chiude Data Wrangler e aggiunge la nuova funzione a una cella di codice nel notebook. È anche possibile scaricare il dataframe pulito come file CSV.
Suggerimento
Data Wrangler genera codice che viene eseguito solo quando si esegue manualmente la nuova cella e non sovrascrive il dataframe originale, come illustrato in questo screenshot:

È quindi possibile eseguire il codice esportato, come illustrato in questo screenshot:

Passaggi successivi
Ora che si è appreso come usare Data Wrangler con i dataframe pandas, esplorare queste risorse:
- Usare Data Wrangler con i dataframe Spark - Applicare le stesse tecniche ai dataframe Spark
- Guardare una demo live - Vedere Data Wrangler in azione con Guy in a Cube
- Prova Data Wrangler in VS Code - Usa Data Wrangler in Visual Studio Code
Hai suggerimenti? Condividi le tue idee nel forum Fabric Ideas.