Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questo articolo si apprenderà come eseguire un'analisi esplorativa dei dati tramite set di dati aperti di Azure e Apache Spark. Questo articolo analizza il set di dati dei taxi di New York City. I dati sono disponibili tramite set di dati aperti di Azure. Questo subset del set di dati contiene informazioni sulle corse in taxi: informazioni su ogni corsa, l'ora di partenza e di arrivo, i percorsi, i costi e altri attributi interessanti.
In questo articolo si apprenderà come:
- Scaricare e preparare i dati
- Analisi dei dati
- Visualizzare i dati
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Passare a Fabric usando il commutatore dell'esperienza in basso a sinistra della tua home page.

Scaricare e preparare i dati
Per iniziare, scaricare il set di dati New York City (NYC) Taxi e preparare i dati.
Creare un notebook tramite PySpark. Per le istruzioni, vedere Creare un notebook.
Nota
Dato che è stato usato il kernel PySpark, non è necessario creare contesti in modo esplicito. Il contesto Spark viene creata automaticamente quando si esegue la prima cella di codice.
In questo articolo, si useranno diverse librerie per visualizzare il set di dati. Per eseguire questa analisi, importare le librerie seguenti:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdPoiché i dati non elaborati sono in formato Parquet, è possibile usare il contesto di Spark per eseguire direttamente il pull del file in memoria come DataFrame. Usare l'API dei set di dati aperti per recuperare i dati e creare un DataFrame di Spark. Per dedurre i tipi di dati e lo schema, usare le proprietà dello schema in lettura dei DataFrame di Spark.
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Dopo aver letto i dati, eseguire alcuni filtri iniziali per pulire il set di dati. È possibile rimuovere colonne non necessarie e aggiungere colonne che estraggono informazioni importanti. Inoltre, possono essere filtrate le anomalie all'interno del set di dati.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analisi dei dati
Gli analisti dei dati hanno a disposizione un'ampia gamma di strumenti che consentono di estrarre informazioni dettagliate dai dati. In questa parte dell'articolo vengono illustrati alcuni strumenti utili disponibili nei notebook di Microsoft Fabric. In questa analisi, è necessario comprendere i fattori che producono suggerimenti più elevati sui taxi per il periodo selezionato.
Guida ad Apache Spark SQL
Prima di tutto, eseguire l'analisi esplorativa dei dati tramite Apache Spark SQL e i comandi magic con il notebook di Microsoft Fabric. Dopo aver creato la query, i risultati compariranno tramite la funzionalità predefinita chart options.
Nel notebook, creare una nuova cella e copiare il codice seguente. Usando questa query, è possibile comprendere il modo in cui gli importi medi della mancia cambiano nel periodo selezionato. Questa query consente anche di identificare altre informazioni utili, tra cui l'importo minimo/massimo della mancia al giorno e l'importo medio della tariffa.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCAl termine dell'esecuzione della query, è possibile visualizzare i risultati passando alla visualizzazione grafico. In questo esempio viene creato un grafico a linee specificando il campo
day_of_monthcome chiave eavgTipAmountcome valore. Dopo aver effettuato le selezioni, selezionare Applica per aggiornare il grafico.
Visualizzare i dati
Oltre alle opzioni di creazione di grafici dei notebook predefiniti, è possibile usare le librerie open source più diffuse per creare visualizzazioni personalizzate. Negli esempi seguenti usare Seaborn e Matplotlib, che sono librerie Python comunemente usate per la visualizzazione dei dati.
Per semplificare e ridurre i costi di sviluppo, ridurre il set di dati. Utilizzare la funzionalità di campionamento di Apache Spark predefinita. Inoltre, sia Seaborn che Matplotlib richiedono una matrice DataFrame Pandas o NumPy. Per ottenere un DataFrame Pandas, usare il comando
toPandas()per convertire il DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()È possibile comprendere la distribuzione dei suggerimenti nel set di dati. Usare Matplotlib per creare un istogramma che mostra la distribuzione dell'importo della mancia e del conteggio. In base alla distribuzione, è possibile vedere che i suggerimenti sono asimmetrici verso importi minori o pari a $10.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()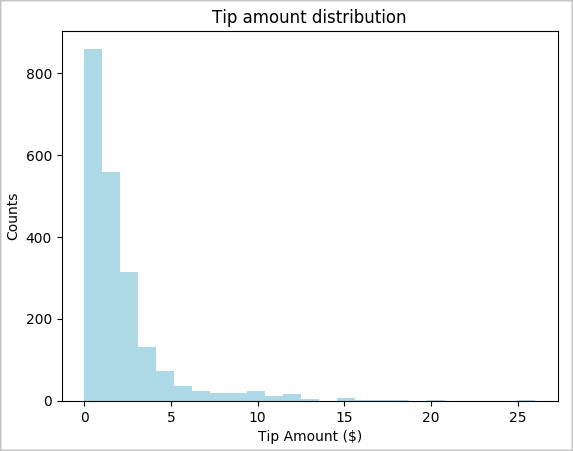
Successivamente, cecare di comprendere la relazione tra i suggerimenti per una determinata tratta e il giorno della settimana. Usare Seaborn per creare un tracciato box che riepiloghi le tendenze per ogni giorno della settimana.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()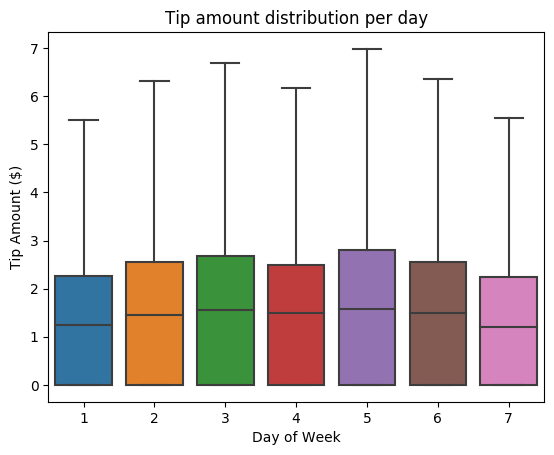
Un'altra ipotesi potrebbe essere che esiste una relazione positiva tra il numero di passeggeri e l'importo totale delle mance dei taxi. Per verificare questa relazione, eseguire il codice seguente per generare un tracciato box che illustri la distribuzione dei suggerimenti per ogni numero di passeggeri.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()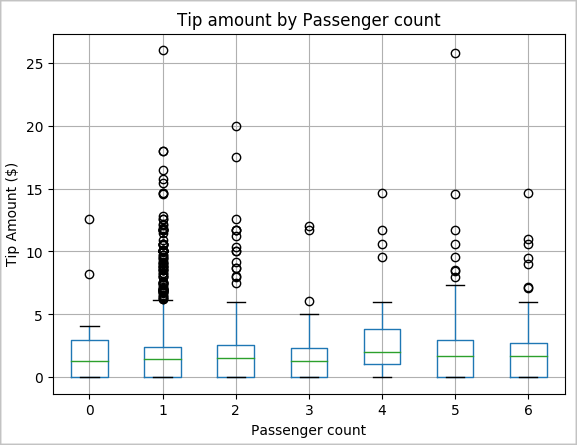
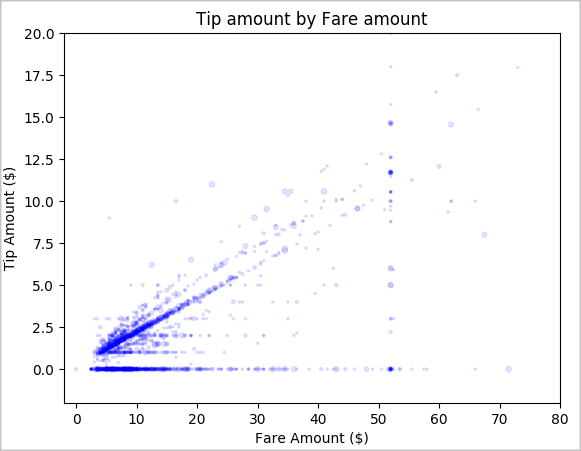
Infine, comprendere la relazione tra l'importo della tariffa e l'importo della mancia. In base ai risultati, è possibile vedere che ci sono diverse osservazioni in cui le persone non danno una mancia. Tuttavia, c’è anche una relazione positiva tra gli importi complessivi delle tariffe e le mance.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()