Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'agente dati di Fabric consente alle organizzazioni di creare sistemi di conversazione usando l'intelligenza artificiale generativa. Connettendo i modelli semantici di Power BI come origini dati, i team possono porre domande in linguaggio naturale e ricevere risposte accurate e complesse senza scrivere query DAX o SQL complesse.
Tuttavia, la qualità delle risposte di intelligenza artificiale dipende molto dal modo in cui si preparano le origini dati. Anche se l'agente dati di Fabric supporta più tipi di origine dati, tra cui lakehouses, warehouse, eventhouse e onlogies, questa guida è incentrata in modo specifico sui modelli semantici di Power BI e illustra le procedure consigliate per configurarle per ottimizzare l'accuratezza e la pertinenza.
Funzionamento dell'agente dei dati di Fabric
L'agente dati usa un'architettura a più livelli in cui le domande utente passano attraverso un agente di orchestrazione. Orchestrator determina l'origine dati appropriata e richiama strumenti specializzati, incluso lo strumento di generazione DAX per i modelli semantici di Power BI per generare, convalidare ed eseguire query.
Flusso di elaborazione delle query
Analisi delle domande: L'agente elabora le domande degli utenti tramite Azure OpenAI, garantendo la conformità ai protocolli di sicurezza e alle autorizzazioni e rispettando i principi di intelligenza artificiale responsabile Microsoft.
Selezione origine dati: Il sistema valuta la domanda rispetto alle origini disponibili usando le informazioni sullo schema e le istruzioni di intelligenza artificiale fornite.
Generazione di query: Per i modelli semantici, lo strumento di generazione DAX genera query DAX basate su schema, metadati (sinonimi, valori min e max di colonne numeriche, metadati visivi del report e altro ancora), contesto configurato nei dati di preparazione per intelligenza artificiale e cronologia delle conversazioni.
Formattazione della risposta: L'agente formatta i risultati in risposte leggibili con tabelle, riepiloghi o informazioni dettagliate in base alle istruzioni dell'agente.

Preparazione per l'intelligenza artificiale: Rendere il modello semantico pronto per l'IA
La funzionalità Prep for AI di Power BI offre tre componenti di configurazione che influisce direttamente sul modo in cui l'agente dati di Fabric interpreta il modello semantico. È possibile accedere a questi componenti sia in Power BI Desktop che nel servizio Power BI. Power BI Copilot utilizza anche Prep per le configurazioni AI, quindi investire tempo nella configurazione di questi elementi avvantaggia sia Copilot che le risposte degli agenti dei dati.
Importante
Quando si eseguono query su modelli semantici, lo strumento di generazione DAX usato dall'agente dati si basa esclusivamente sui metadati e sulla preparazione del modello semantico per le configurazioni di intelligenza artificiale. Lo strumento di generazione DAX ignora le istruzioni aggiunte a livello di agente dati per la generazione di query DAX. La preparazione appropriata per la configurazione di intelligenza artificiale è essenziale per ottenere risultati accurati.
Schemi di dati di intelligenza artificiale
Gli schemi di dati di intelligenza artificiale consentono di definire un subset mirato del modello per la definizione delle priorità di intelligenza artificiale. Sebbene l'agente dati abbia la propria selezione di tabelle quando si aggiunge un modello semantico come origine dati, configura prima lo schema in Preparazione per l'Intelligenza Artificiale. Lo strumento di generazione DAX usa questo schema per la creazione di query DAX.
È possibile configurare questo schema in Power BI Desktop o nel servizio Power BI selezionando Prep data for AI (Prep data for AI) dalla barra multifunzione Home. Passare quindi alla scheda Semplificare lo schema dei dati . Da qui selezionare le tabelle, le colonne e le misure che l'intelligenza artificiale deve usare per generare risposte. Per istruzioni dettagliate sulla configurazione, vedere Impostare uno schema di dati di intelligenza artificiale.

Quando si aggiunge il modello semantico all'agente dati, selezionare le stesse tabelle definite in Preparazione per intelligenza artificiale per garantire un comportamento coerente. Prima di tutto, definire l'ambito dell'agente dati (i tipi di domande a cui deve rispondere). Selezionare quindi solo gli oggetti pertinenti. Questo approccio riduce l'ambiguità, migliora l'accuratezza e riduce la latenza della risposta.
Lo strumento di generazione DAX si basa sui metadati del modello per interpretare le domande. Usare nomi chiari e descrittivi per tabelle, colonne e misure che riflettono il modo in cui gli utenti fanno naturalmente riferimento ai dati. Ad esempio, usare "Total Revenue" anziché "TR_AMT" o "Sales Region" anziché "DIM_GEO_01". Queste indicazioni sono particolarmente importanti per i modelli di grandi dimensioni con campi sovrapposti o denominati in modo analogo, in cui i nomi ambigui possono causare una generazione di query non corretta.
Esempio: Risoluzione dell'ambiguità dei campi
| Senza schema di dati di intelligenza artificiale | Con lo schema dei dati di intelligenza artificiale |
|---|---|
Un utente chiede: "What were our sales last quarter?" il modello semantico contiene più misure correlate alle vendite: Total Revenue, Gross Sales, Net Sales e Sales After Returns. L'intelligenza artificiale restituisce Gross Sales, ma il team usa in genere Net Sales per la creazione di report trimestrali. |
Dopo aver configurato lo schema dei dati di intelligenza artificiale in modo da includere solo Net Sales ed escludere le altre misure non pertinenti, la stessa domanda ora restituisce la metrica prevista. L'intelligenza artificiale non deve più indovinare quale sia la misura di "vendite" intesa dall'utente. |
Suggerimenti per gli schemi di dati di intelligenza artificiale
Per ottenere risultati coerenti e accurati, assicurarsi di selezionare le stesse tabelle nell'agente dati di Fabric definite anche tramite schemi di dati di intelligenza artificiale in Preparazione per intelligenza artificiale.
Quando si seleziona lo schema, includere anche oggetti dipendenti. Ad esempio, se una misura Total Revenue fa riferimento a due altre misure che dipendono da colonne aggiuntive, includere tutti gli oggetti dipendenti nello schema. Per identificare le dipendenze, usare la funzione get_measure_dependencies dalla libreria Semantic Link Labs .
Se si dispone di un modello semantico di grandi dimensioni, la ridenominazione manuale di tutti gli oggetti può essere noiosa. Usare il server MCP di modellazione di Power BI affinché un LLM generi nomi business-friendly per le tabelle, le colonne e le misure. Esaminare e convalidare le modifiche prima di salvarle per assicurarsi che non interrompano le espressioni DAX, le relazioni o altri oggetti dipendenti.
Risposte verificate
Le risposte verificate sono risposte visive approvate dall'utente che attivano domande specifiche. Forniscono risposte coerenti e affidabili a domande comuni o complesse che altrimenti potrebbero essere interpretate in modo non corretto. Poiché le risposte verificate vengono archiviate a livello di modello semantico (non a livello di report), funzionano in qualsiasi agente dati che usa lo stesso modello. Per altre informazioni, vedere Preparare i dati per l'intelligenza artificiale - Risposte verificate.
Quando si usano risposte verificate con l'agente dati, il sistema non restituisce la visualizzazione di Power BI stessa. Usa invece le domande utente e le proprietà dell'oggetto visivo (colonne, misure, filtri) per influenzare la generazione di query DAX. Questo approccio significa che le risposte verificate migliorano l'accuratezza della risposta guidando lo strumento di generazione DAX verso la struttura di query corretta. Quando un utente pone una domanda all'agente dati, il sistema verifica innanzitutto una corrispondenza esatta o semanticamente simile alla richiesta definita nella risposta verificata prima di generare una nuova risposta.

Esempio: Gestione della terminologia a livello di area
| Senza risposta verificata | Con risposta verificata |
|---|---|
Un utente chiede: "Show me performance by territory" l'intelligenza artificiale interpreta "territory" come categoria di prodotti perché nella tabella Products è presente una colonna Territory. L'utente intendeva effettivamente le aree di vendita. |
Si crea una risposta verificata usando un oggetto visivo vendite a livello di area con domande trigger come "What is the sales performance by territory?", "Mostra le vendite suddivise in base al territorio" e "Come vengono distribuite le vendite tra aree?" Ora, quando gli utenti chiedono prestazioni sul territorio, ottengono risposte accurate in modo coerente in base agli oggetti usati nell'oggetto visivo delle vendite a livello di area. |
Suggerimenti di configurazione per le risposte verificate
- Usare cinque o sette domande di attivazione per ogni risposta verificata per coprire le variazioni naturali.
- Includere formulazioni formali e di conversazione che gli utenti potrebbero provare.
- Configurare fino a tre filtri per il sezionamento flessibile senza creare più risposte verificate.
- Se si rinominano tabelle, colonne o misure a cui si fa riferimento in una risposta verificata, aggiornare la risposta verificata e salvarla di nuovo per rendere effettive le modifiche.
Istruzioni per l'intelligenza artificiale
Le istruzioni di intelligenza artificiale in Preparazione per intelligenza artificiale forniscono contesto, logica di business e linee guida direttamente sul modello semantico. Consentono di chiarire la terminologia, guidare gli approcci di analisi e fornire contesto aziendale e semantico critico che l'intelligenza artificiale non comprenderebbe altrimenti.
È possibile configurare queste istruzioni in Power BI Desktop o nel servizio Power BI selezionando Prep data for AI (Prep data for AI ) dalla barra multifunzione Home e quindi passando alla scheda Aggiungi istruzioni per intelligenza artificiale . Per istruzioni dettagliate sulla configurazione, vedere la documentazione relativa alle istruzioni per l'intelligenza artificiale.

Le istruzioni di intelligenza artificiale sono linee guida non strutturate che l'LLM interpreta, ma non c'è alcuna garanzia che li segua esattamente. Istruzioni chiare e specifiche sono più efficaci di quelle complesse o in conflitto.
Come accennato in precedenza, lo strumento di generazione DAX fa riferimento solo alle istruzioni di intelligenza artificiale configurate in Preparazione per l'intelligenza artificiale del modello semantico. Le istruzioni dell'agente dati non vengono passate allo strumento e vengono ignorate durante l'esecuzione di query su modelli semantici. Per questo motivo, non aggiungere istruzioni specifiche del modello semantico a livello di agente dati. Mantenere invece tutte le istruzioni del modello semantico in Prep for AI in cui lo strumento di generazione DAX può usarle. Le istruzioni dell'agente dati devono includere solo indicazioni che si applicano a tutte le origini dati configurate nell'agente, ad esempio preferenze di formattazione delle risposte generali, regole di routing tra origini, abbreviazioni comuni, tono e così via. Si noti anche che, a differenza di altre origini dati, l'agente dati non supporta istruzioni o descrizioni dell'origine dati per i modelli semantici.
Esempio: Definizione della terminologia aziendale
| Senza istruzioni di intelligenza artificiale | Con le istruzioni per l'intelligenza artificiale |
|---|---|
| Un utente chiede: "Chi sono stati i migliori performer del mese scorso?" L'intelligenza artificiale non comprende il significato di "top performer" nell'organizzazione e restituisce un errore o richiede chiarimenti. | Si aggiunge un'istruzione: "Un top performer è un rappresentante vendite che ottiene 110% o più della quota mensile. Usare la tabella Rep_Performance e filtrare dove Quota_Attainment >= 1.1" Ora l'intelligenza artificiale interpreta correttamente la domanda e restituisce i risultati corretti. |
Modelli di istruzioni efficaci
- Definizioni del periodo di tempo: "La stagione di punta va da novembre a gennaio. La stagione fuori stagione è da febbraio ad aprile."
- Preferenze delle metriche: "Quando gli utenti chiedono informazioni sulla redditività, usare la misura di Contribution_Margin, non Gross_Profit."
- Instradamento Sorgente Dati: "Per domande sull'inventario, dare priorità alla tabella Warehouse_Inventory rispetto a Sales_Orders."
- Raggruppamenti predefiniti: "Se non specificato diversamente, analizzare i ricavi in base al trimestre fiscale anziché al mese di calendario".
Oltre a Prep per intelligenza artificiale, lo strumento di generazione di query DAX usa anche i metadati degli oggetti visivi del report, ad esempio titolo visivo, colonne, misure, filtri e così via per migliorare l'accuratezza delle query.
Flusso di lavoro di implementazione consigliato
Ottimizzare il modello semantico: Iniziare ottimizzando il modello semantico per le prestazioni. Le prestazioni scarse dell'agente dati spesso derivano da un modello semantico non progettato correttamente, da misure DAX inefficienti o da una combinazione dei due. Quando un utente pone una domanda, l'agente dati genera una query DAX e la esegue sul modello. Un modello ben ottimizzato usa meno risorse e consente di ottenere un'esecuzione più rapida delle query. In un'interfaccia conversazionale gli utenti si aspettano risposte rapide, quindi le prestazioni lente influisce direttamente sull'esperienza utente e sull'adozione.
Inoltre, un modello gonfio con colonne, tabelle e misure non necessarie crea più rumore per lo strumento di generazione DAX da analizzare, riducendo così l'accuratezza della risposta. Ottimizzando il modello in anticipo, si evitano anche problemi di prestazioni man mano che i dati aumentano e il modello diventa più complesso. Per altre informazioni, vedere il corso Ottimizzare un modello per le prestazioni in Power BI .
Usare Best Practice Analyzer e Semantic Model Memory Analyzer in un notebook di Fabric per identificare problemi quali tipi di dati non corretti, colonne non necessarie, colonne a cardinalità elevata e modelli DAX inefficienti. Aggiungere descrizioni a tabelle, colonne e misure per aiutare l'LLM a comprendere lo scopo di ogni oggetto incluso nello schema dei dati di intelligenza artificiale.
Definire la preparazione per l'intelligenza artificiale > Schema dei dati di intelligenza artificiale: in base all'ambito dell'agente dati, configurare lo schema dei dati di intelligenza artificiale in Preparazione per intelligenza artificiale selezionando solo le tabelle, le colonne e le misure pertinenti alle domande a cui l'agente deve rispondere.
Creare la preparazione per l'intelligenza artificiale > Risposte verificate: identificare le domande più comuni e configurare le risposte verificate in Preparazione per intelligenza artificiale usando oggetti visivi appropriati. Usare domande complete e robuste come indicazioni (non frasi parziali) per migliorare l'accuratezza dell'abbinamento.
Aggiungere un modello semantico all'agente dati: Prima di aggiungere istruzioni di intelligenza artificiale in Preparazione per intelligenza artificiale, testare e convalidare le risposte dall'agente dati. Questo passaggio consente di comprendere dove sono necessarie istruzioni di intelligenza artificiale per migliorare la generazione di query DAX.
Aggiungere Prep per AI > Istruzioni per l'intelligenza artificiale: in base ai risultati della convalida, definire terminologia aziendale, preferenze di analisi e priorità dell'origine dati nelle istruzioni Prep per AI (non nelle istruzioni dell'agente dati).
Preparare gli oggetti visivi del report: Esaminare i report connessi al modello semantico, inclusi gli oggetti visivi nascosti e le pagine, per assicurarsi che gli oggetti visivi abbiano titoli descrittivi. Gli elementi visivi ben strutturati aiutano l'intelligenza artificiale a fondare le risposte utilizzando i metadati visivi come il titolo visivo, la tabella, la colonna, le metriche utilizzate, i filtri applicati e altro ancora.
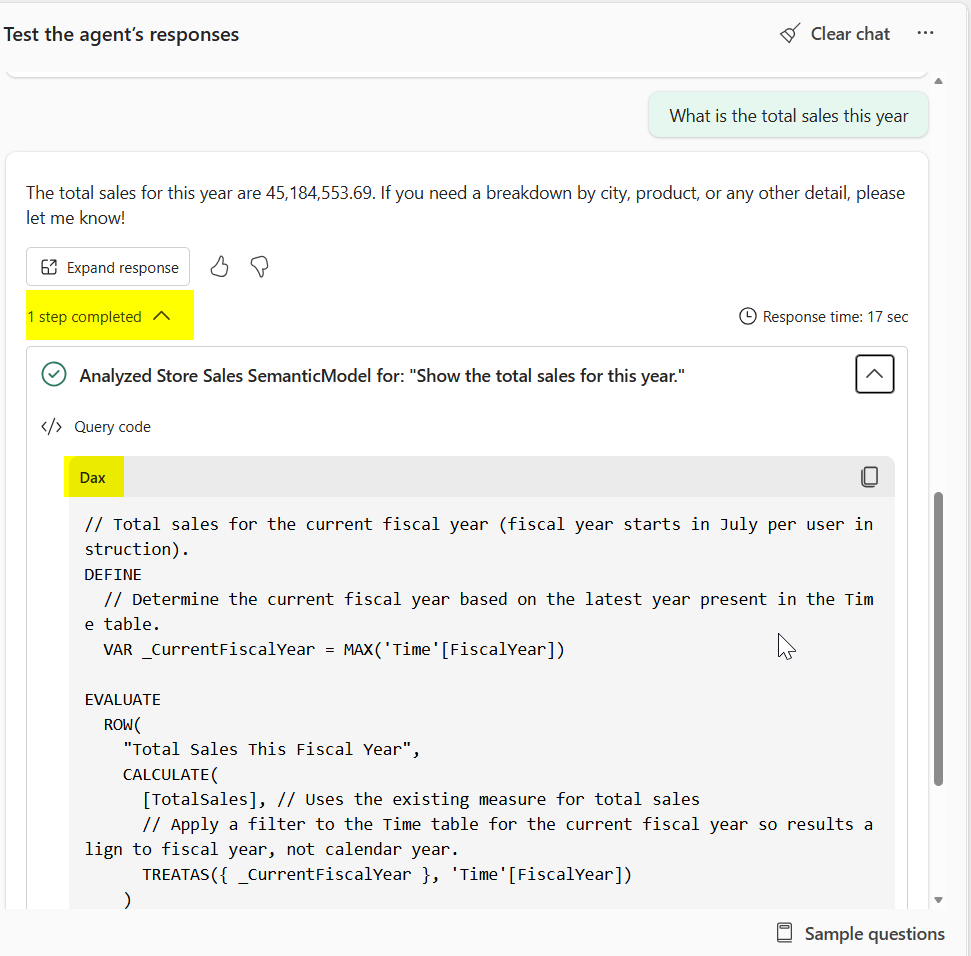
Verificare e testare DAX: L'accuratezza della risposta dipende dalla query DAX generata. Quando testi il tuo agente dati, esamina la query DAX in ciascuna risposta per verificare che sia valida e risponda correttamente alla domanda. Se i risultati non sono corretti, analizzare il DAX per identificare le configurazioni (modello semantico, schema dei dati di intelligenza artificiale, risposte verificate o istruzioni di intelligenza artificiale) devono essere rettificate.
Configurare le istruzioni dell'agente dati: Aggiungere istruzioni a livello di agente dati solo per indicazioni applicabili a tutte le origini dati configurate nell'agente. Queste linee guida includono preferenze generali di formattazione delle risposte, regole di routing tra origini, abbreviazioni comuni e tono. Non aggiungere istruzioni specifiche del modello semantico qui perché non vengono passate allo strumento di generazione DAX. Per indicazioni sulla configurazione delle istruzioni dell'agente, vedere linee guida per la configurazione.
Convalida e Itera: Gli LLM possono produrre risultati non corretti senza un contesto appropriato. Iterare continuamente la configurazione e convalidare le risposte per rafforzare la fiducia nel tuo agente dati. Per valutare le risposte a livello di codice, è possibile usare Python SDK dell'agente dati di Fabric per eseguire valutazioni automatizzate rispetto alle coppie di domande e risposte reali e analizzare le metriche di accuratezza. Si noti che l'SDK è per la valutazione solo in questo caso e non può modificare la preparazione del modello semantico per le configurazioni di intelligenza artificiale. Per informazioni dettagliate, vedere Valuta il tuo agente dati. Inoltre, coinvolgere gli stakeholder e gli utenti finali nel processo di valutazione. Il feedback garantisce che le risposte siano allineate alle aspettative e all'usabilità del mondo reale, consentendo di identificare le lacune che i controlli automatizzati potrebbero perdere.
Implementare pipeline di controllo del codice sorgente e distribuzione: Usare le pipeline di integrazione e distribuzione Git per gestire le configurazioni dell'agente dati tra aree di lavoro di sviluppo, test e produzione. Questa procedura garantisce che le modifiche alla configurazione vengano testate e convalidate prima di essere alzate di livello all'ambiente di produzione in cui gli utenti finali accedono. Per informazioni dettagliate , vedere Controllo del codice sorgente, CI/CD e ALM per l'agente dati di Fabric.


Suggerimento
Puoi usare le risorse nel repository fabric-toolbox come riferimento per aiutarti in questo flusso di lavoro. Questo repository contiene:
- Elenco di controllo per la preparazione e la configurazione del modello semantico come origine dati
- Notebook utilità agente dati con frammenti di codice utili e funzioni helper
Problemi comuni da evitare
Non usando lo schema star: I modelli semantici che usano tabelle flat denormalizzate o strutture di dati con pivot rendono DAX meno efficiente e più difficile da scrivere correttamente. DAX è ottimizzato per lo schema a stella con tabelle di fatto e di dimensione chiare. Trasforma tabelle ampie in strutture normalizzate in cui ogni riga rappresenta una singola osservazione.
Fare affidamento sui campi nascosti: Le risposte verificate non funzioneranno se fanno riferimento a colonne nascoste nel modello.
Inclusione di misure non necessarie: I modelli semantici contengono spesso misure helper e oggetti intermedi usati per migliorare l'interattività dei report. Quando si configura lo schema dei dati di intelligenza artificiale, includere solo le misure che calcolano le metriche aziendali effettive. L'esclusione delle misure helper riduce il rumore e aiuta lo strumento di generazione DAX a generare query più accurate.
Misure duplicate o sovrapposte: Più misure che calcolano metriche simili (ad esempio, Total Sales, Sales Amount, Revenue) creano ambiguità. Consolidare o distinguere chiaramente le misure ed escludere duplicati dallo schema dei dati di intelligenza artificiale.
Denominazione non descrittiva: I nomi degli oggetti, ad esempio TR_AMT, F_SLS o DIM_GEO_01 non forniscono alcun contesto per lo strumento di generazione DAX. Usare nomi chiari e descrittivi per l'azienda, ad esempio Total Revenue, Sales o Customer Geography. Se non è possibile rinominare gli oggetti, assicurarsi che le descrizioni e i sinonimi forniscano il contesto necessario per l'intelligenza artificiale per comprenderne lo scopo.
Basarsi su misure implicite: Le misure implicite possono causare risultati imprevedibili. Creare misure DAX esplicite per i calcoli su cui si desidera eseguire query e impostare il riepilogo predefinito corretto (Sum, Average, None e così via) sulle colonne numeriche per evitare aggregazioni indesiderate.
Campi di data ambigui: Più colonne di data (data ordine, data di spedizione, data di scadenza, trimestre del calendario/trimestre FY e così via) senza indicazioni chiare confondono l'intelligenza artificiale. Usare le Risposte verificate e istruzioni AI in Prep per AI per specificare quale campo data utilizzare per impostazione predefinita o per tipi di domande specifici.
Istruzioni in conflitto: Le istruzioni di intelligenza artificiale che contraddicono le configurazioni di risposta verificate creano un comportamento imprevedibile.
Ignorare il perfezionamento dello schema: I modelli di grandi dimensioni con molti campi denominati in modo simile necessitano di schemi di dati di intelligenza artificiale mirati.
Istruzioni eccessivamente complesse: Mantenere le istruzioni incentrate e specifiche. L'intelligenza artificiale interpreta ma non garantisce di seguire le indicazioni complesse e in conflitto. Le istruzioni complesse possono anche aggiungere alla latenza.
Tools
Per seguire queste linee guida, è possibile usare gli strumenti seguenti dal repository GitHub fabric-toolbox:
- Elenco di controllo con raccomandazioni. Queste sono linee guida e non tutti gli elementi nell'elenco di controllo possono essere applicabili per lo scenario in uso.
- Notebook con una collezione di strumenti in un'unica posizione.
- Server MCP di Power BI per accelerare lo sviluppo e il test in VS Code
- Libreria di lab di collegamento semantico per aggiornare il modello semantico a livello di codice nel notebook di Fabric.
Risorse aggiuntive
- Documentazione relativa ai concetti relativi all'agente dati di Fabric
- Fabric-toolbox con elenchi di controllo e notebook
- Aggiunta di un modello semantico come origine dati all'agente di dati
- Preparare i dati per l'intelligenza artificiale in Power BI
- Ottimizzare il modello semantico per Copilot
- Ottimizzare un modello per le prestazioni in Power BI - Training
- Domande frequenti sulla preparazione per l'intelligenza artificiale