Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come rilevare le relazioni nel set di dati Synthea pubblico usando il collegamento semantico.
Quando si lavora con nuovi dati o senza un modello di dati esistente, può essere utile individuare automaticamente le relazioni. Questo rilevamento delle relazioni consente di:
- comprendere il modello a livello generale,
- ottenere altre informazioni dettagliate durante l'analisi esplorativa dei dati,
- convalidare i dati aggiornati o nuovi, i dati in ingresso e
- pulizia dei dati
Anche se le relazioni sono note in anticipo, una ricerca di relazioni può aiutare a comprendere meglio il modello di dati o l'identificazione dei problemi di qualità dei dati.
In questa esercitazione si inizia con un semplice esempio di base in cui si sperimentano solo tre tabelle in modo che le connessioni tra di esse siano facili da seguire. Viene quindi illustrato un esempio più complesso con un set di tabelle più grande.
In questa esercitazione si apprenderà come:
- Usare i componenti della libreria Python (SemPy) del collegamento semantico che supportano l'integrazione con Power BI e consentono di automatizzare l'analisi dei dati. Questi componenti includono:
- FabricDataFrame: struttura simile a pandas migliorata con informazioni semantiche aggiuntive.
- Funzioni per l'estrazione di modelli semantici da un'area di lavoro Fabric nel tuo notebook.
- Funzioni che automatizzano l'individuazione e la visualizzazione delle relazioni nei modelli semantici.
- Risolvere i problemi relativi al processo di individuazione delle relazioni per i modelli semantici con più tabelle e interdipendenze.
Prerequisites
Abbonati a Microsoft Fabric. In alternativa, iscriviti a una versione di prova gratuita di Microsoft Fabric.
Accedi a Microsoft Fabric.
Passare a Fabric usando il commutatore dell'esperienza in basso a sinistra della tua home page.

- Selezionare Aree di lavoro nel riquadro di spostamento sinistro per trovare e selezionare l'area di lavoro. Questa area di lavoro diventa l'area di lavoro corrente.
Seguire la procedura nel notebook
Il notebook relationships_detection_tutorial.ipynb fa parte di questo tutorial.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se si preferisce copiare e incollare il codice da questa pagina, è possibile creare un nuovo notebook.
Assicurati di collegare un lakehouse al notebook prima di iniziare a eseguire codice.
Configurare il notebook
In questa sezione viene configurato un ambiente notebook con i moduli e i dati necessari.
Eseguire l'installazione
SemPyda PyPI usando la%pipfunzionalità di installazione in linea all'interno del notebook:%pip install semantic-linkEseguire le importazioni necessarie dei moduli SemPy necessari in un secondo momento:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Importare pandas per applicare un'opzione di configurazione utile per la formattazione dell'output:
import pandas as pd pd.set_option('display.max_colwidth', None)Estrarre i dati di esempio. Per questa esercitazione si usa il set di dati Synthea di record medici sintetici (versione ridotta per semplicità):
download_synthea(which='small')
Rilevare le relazioni in un piccolo subset di tabelle Synthea
Selezionare tre tabelle da un set più grande:
-
patientsspecifica le informazioni sul paziente -
encountersspecifica i pazienti che hanno avuto incontri medici (ad esempio, un appuntamento medico, una procedura) -
providersspecifica quali operatori medici hanno trattato i pazienti
La tabella
risolve una relazione molti-a-molti tra e e può essere descritta come un'entità associativa : patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
Trovare relazioni tra le tabelle usando la funzione di
find_relationshipsSemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsVisualizzare le relazioni dataframe come grafico usando la funzione di
plot_relationship_metadataSemPy.plot_relationship_metadata(suggested_relationships)
La funzione dispone la gerarchia delle relazioni dal lato sinistro al lato destro, che corrisponde alle tabelle "from" e "to" nell'output. In altre parole, le tabelle indipendenti sul lato sinistro usano le loro chiavi esterne per fare riferimento alle tabelle di dipendenza sul lato destro. Ogni casella di entità mostra le colonne che partecipano al lato "from" o "to" di una relazione.
Per impostazione predefinita, le relazioni vengono generate come "m:1" (non come "1:m") o "1:1". Le relazioni "1:1" possono essere generate in uno o entrambi i modi, a seconda che il rapporto dei valori mappati rispetto a tutti i valori superi
coverage_thresholdin una o entrambe le direzioni. Più avanti in questa esercitazione viene illustrato il caso meno frequente delle relazioni "m:m".

Risolvere i problemi di rilevamento delle relazioni
L'esempio di base mostra un rilevamento delle relazioni riuscito sui dati di Synthea puliti. In pratica, i dati sono raramente puliti, che impediscono il rilevamento riuscito. Esistono diverse tecniche che possono essere utili quando i dati non sono puliti.
Questa sezione di questa esercitazione illustra il rilevamento delle relazioni quando il modello semantico contiene dati dirty.
Iniziare modificando i DataFrame originali per ottenere dati "dirty" e stampare la dimensione dei dati "dirty".
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Per il confronto, le dimensioni di stampa delle tabelle originali:
print(len(patients)) print(len(providers))Trovare relazioni tra le tabelle usando la funzione di
find_relationshipsSemPy:find_relationships([patients_dirty, providers_dirty, encounters])L'output del codice mostra che non sono state rilevate relazioni a causa degli errori introdotti in precedenza per creare il modello semantico "dirty".
Usare la convalida
La convalida è lo strumento migliore per la risoluzione degli errori di rilevamento delle relazioni perché:
- Segnala chiaramente perché una determinata relazione non segue le regole di chiave esterna e pertanto non può essere rilevata.
- Viene eseguito rapidamente con modelli semantici di grandi dimensioni perché si concentra solo sulle relazioni dichiarate e non esegue una ricerca.
La convalida può usare qualsiasi dataframe con colonne simili a quella generata da find_relationships. Nel codice seguente il suggested_relationships dataframe fa riferimento a patients anziché patients_dirtya , ma è possibile eseguire l'aliasing dei dataframe con un dizionario:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Allentare i criteri di ricerca
In scenari più oscuro, è possibile provare ad allentare i criteri di ricerca. Questo metodo aumenta la possibilità di falsi positivi.
Impostare
include_many_to_many=Truee valutare se è utile:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)I risultati mostrano che la relazione da
encountersapatientsè stata rilevata, ma esistono due problemi:- La relazione indica una direzione da
patientsaencounters, che è un inverso della relazione prevista. Ciò è dovuto al fatto che tuttopatientsè stato coperto daencounters(Coverage Fromè 1,0) mentreencounterssono solo parzialmente coperti dapatients(Coverage To= 0,85), perché le righe dei pazienti sono mancanti. - Esiste una corrispondenza accidentale in una colonna a bassa cardinalità
GENDER, che per nome e valore coincide in entrambe le tabelle, ma non è una relazione "m:1" di interesse. La cardinalità bassa è indicata dalleUnique Count Fromcolonne eUnique Count To.
- La relazione indica una direzione da
find_relationshipsEseguire di nuovo per cercare solo le relazioni "m:1", ma con un valore inferiorecoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Il risultato mostra la direzione corretta delle relazioni da
encountersaproviders. Tuttavia, la relazione daencountersapatientsnon viene rilevata perchépatientsnon è univoca, quindi non può trovarsi sul lato "Uno" della relazione "m:1".Allentare sia
include_many_to_many=Truechecoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Ora entrambe le relazioni di interesse sono visibili, ma c'è molto più rumore:
- La corrispondenza a bassa cardinalità su
GENDEResiste. - È stata trovata una corrispondenza di cardinalità "m:m" più elevata in
ORGANIZATION, il che rende evidente cheORGANIZATIONè probabilmente una colonna denormalizzata in entrambe le tabelle.
- La corrispondenza a bassa cardinalità su
Allinea i nomi delle colonne
Per impostazione predefinita, SemPy considera come corrispondenze solo gli attributi che mostrano la somiglianza nei nomi, sfruttando il fatto che i progettisti di database solitamente chiamano le colonne correlate nello stesso modo. Questo comportamento consente di evitare relazioni spurie, che si verificano più frequentemente con chiavi integer a cardinalità bassa. Ad esempio, se ci sono 1,2,3,...,10 categorie di prodotti e 1,2,3,...,10 codici di stato dell'ordine, possono confondersi tra loro quando si esaminano solo le mappature dei valori senza tenere conto dei nomi delle colonne. Le relazioni spurie non dovrebbero essere un problema con le chiavi simili a GUID.
SemPy esamina una somiglianza tra nomi di colonna e nomi di tabella. La corrispondenza è approssimativa e senza distinzione tra maiuscole e minuscole. Ignora le sottostringhe "decorator" rilevate più di frequente, ad esempio "id", "code", "name", "key", "pk", "fk". Di conseguenza, i pattern di corrispondenza più tipici sono:
- Un attributo denominato 'column' nell'entità 'foo' corrisponde a un attributo denominato 'column' (anche 'COLUMN' o 'Column') nell'entità 'bar'.
- un attributo denominato 'column' nell'entità 'foo' corrisponde a un attributo denominato 'column_id' in 'bar'.
- Un attributo denominato 'bar' nell'entità 'foo' corrisponde a un attributo denominato 'code' in 'bar'.
Associando prima i nomi delle colonne, il rilevamento viene eseguito più velocemente.
Abbina i nomi delle colonne
- Per comprendere quali colonne sono selezionate per un'ulteriore valutazione, usare l'opzione
verbose=2(verbose=1elenca solo le entità in fase di elaborazione). - Il
name_similarity_thresholdparametro determina la modalità di confronto delle colonne. La soglia di 1 indica che si è interessati solo alle corrispondenze al 100%.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);L'esecuzione a 100% somiglianza non tiene conto delle piccole differenze tra i nomi. Nell'esempio le tabelle hanno una forma plurale con suffisso "s", che non restituisce alcuna corrispondenza esatta. Questa operazione viene gestita correttamente con il predefinito
name_similarity_threshold=0.8.- Per comprendere quali colonne sono selezionate per un'ulteriore valutazione, usare l'opzione
Rieseguire con l'impostazione predefinita
name_similarity_threshold=0.8:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Si noti che l'ID per la forma
patientsplurale viene ora confrontato con singolarepatientsenza aggiungere troppi altri confronti spuri al tempo di esecuzione.Rieseguire con l'impostazione predefinita
name_similarity_threshold=0:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Il passaggio
name_similarity_thresholda 0 è l'altro estremo e indica che si desidera confrontare tutte le colonne. Questo è raramente necessario e comporta un aumento del tempo di esecuzione e corrispondenze spurie che devono essere esaminate. Osservate il numero di confronti nell'output dettagliato.
Riepilogo dei suggerimenti per la risoluzione dei problemi
- Iniziare dalla corrispondenza esatta per le relazioni "m:1", ovvero il valore predefinito
include_many_to_many=Falseecoverage_threshold=1.0. Questo è in genere ciò che vuoi. - Usare una concentrazione ristretta su subset più piccoli delle tabelle.
- Usare la convalida per rilevare i problemi di qualità dei dati.
- Per comprendere quali colonne sono considerate per la relazione, usare
verbose=2. Ciò può comportare una grande quantità di output. - Tenere presente i compromessi degli argomenti di ricerca.
include_many_to_many=Trueecoverage_threshold<1.0possono produrre relazioni spurie che potrebbero essere più difficili da analizzare e dovranno essere filtrate.
Rilevare le relazioni nel set di dati Synthea completo
L'esempio di base semplice è stato uno strumento pratico per l'apprendimento e la risoluzione dei problemi. In pratica, è possibile iniziare da un modello semantico, ad esempio il set di dati Synthea completo, che include molte più tabelle. Esplorare il set di dati synthea completo come indicato di seguito.
Leggere tutti i file dalla directory synthea/csv :
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Trovare relazioni tra le tabelle usando la funzione di
find_relationshipsSemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsVisualizzare le relazioni:
plot_relationship_metadata(suggested_relationships)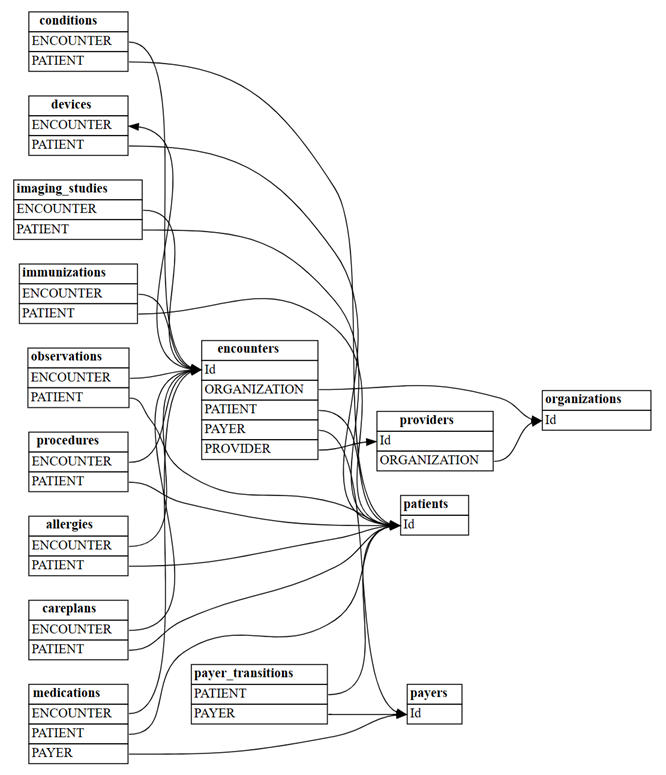
Contare il numero di nuove relazioni "m:m" che verranno individuate con
include_many_to_many=True. Queste relazioni si aggiungono alle relazioni "m:1" mostrate in precedenza; pertanto, è necessario filtrare in basemultiplicitya :suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']È possibile ordinare i dati delle relazioni in base a varie colonne per ottenere una comprensione più approfondita della loro natura. Ad esempio, è possibile scegliere di ordinare l'output in base a
Row Count FromeRow Count To, che consentono di identificare le tabelle di dimensioni maggiori.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)In un modello semantico diverso, potrebbe essere importante concentrarsi sul numero di valori Null
Null Count FromoCoverage To.Questa analisi consente di comprendere se una delle relazioni potrebbe non essere valida e se è necessario rimuoverle dall'elenco dei candidati.

Contenuti correlati
Vedere altre esercitazioni per il collegamento semantico/SemPy:
- Esercitazione: Ripulire i dati con dipendenze funzionali
- Esercitazione: Analizzare le dipendenze funzionali in un modello semantico di esempio
- Esercitazione: Individuare le relazioni in un modello semantico usando il collegamento semantico
- Esercitazione: Estrarre e calcolare le misure di Power BI da un Jupyter Notebook