Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Applica a:✅ Warehouse in Microsoft Fabric
Questo articolo illustra il funzionamento delle pipeline di integrazione e distribuzione Git per i warehouse in Microsoft Fabric. Informazioni su come configurare un collegamento al repository, gestire i magazzini e implementarli in ambienti diversi. Il controllo del codice sorgente per Fabric Warehouse è attualmente una funzionalità di anteprima.
Per scenari diversi, è possibile usare sia l'integrazione Git sia le Pipeline di distribuzione:
- Usare progetti di database Git e SQL per gestire modifiche incrementali, collaborazione in team e cronologia di commit in singoli oggetti di database.
- Usare le pipeline di distribuzione per promuovere le modifiche al codice in ambienti di pre-produzione e di produzione diversi.
Integrazione con Git
L'integrazione git in Microsoft Fabric consente agli sviluppatori di integrare i processi di sviluppo, gli strumenti e le procedure consigliate direttamente nella piattaforma Fabric. Consente agli sviluppatori che sviluppano in Fabric di:
- Eseguire il backup e versionare il loro lavoro
- Ripristinare le fasi precedenti in base alle esigenze
- Collaborare con altri utenti o lavorare da soli usando i rami Git
- Applicare le funzionalità degli strumenti familiari di controllo del codice sorgente per gestire gli elementi di Fabric
Per altre informazioni sul processo di integrazione con Git vedere:
- Che cos'è Microsoft Fabric integrazione Git?
- Concetti di base nell'integrazione Git
- Nozioni di base sull'integrazione Git
Configurare un collegamento al controllo del codice sorgente
Dalla pagina Impostazioni area di lavoro è possibile configurare facilmente un collegamento al repository per eseguire il commit e la sincronizzazione delle modifiche.
- Per configurare la connessione, vedere Introduzione all'integrazione con Git. Seguire le istruzioni per connettersi a un repository Git su Azure DevOps o GitHub in qualità di provider Git.
- Una volta connessi, gli elementi, inclusi i magazzini, vengono visualizzati nel pannello Controllo del codice sorgente.
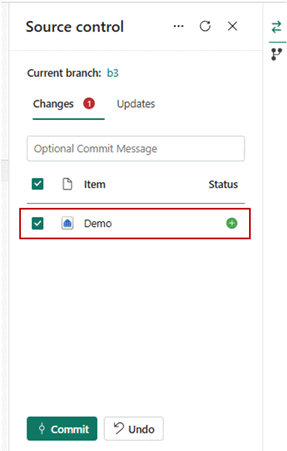
- Dopo aver connesso correttamente le istanze del magazzino al repository Git, viene visualizzata la struttura della cartella di magazzino. È ora possibile eseguire operazioni future, ad esempio la creazione di una richiesta pull.
Progetti di database per un magazzino in Git
L'immagine seguente è un esempio della struttura di file di ogni elemento del magazzino nel repository:

Quando si esegue il commit dell'elemento di magazzino nel repository Git, il magazzino viene convertito in un formato di codice sorgente come progetto di database SQL. Un progetto SQL è una rappresentazione locale degli oggetti SQL che costituiscono lo schema di un database singolo, ad esempio tabelle, stored procedure o funzioni. La struttura di cartelle degli oggetti database è organizzata per Schema/Tipo di oggetto. Ogni oggetto nel magazzino è rappresentato con un file .sql che contiene la propria definizione DDL (Data Definition Language). I dati delle tabelle di Warehouse e le funzionalità di sicurezza SQL non sono inclusi nel progetto di database SQL.
Anche le query condivise vengono sottoposte a commit nel repository ed ereditano il nome in cui vengono salvate.
Per le aree di lavoro con il controllo del codice sorgente abilitato, tutte le modifiche apportate allo schema tramite strumenti esterni (ad esempio, l'esecuzione di query in SSMS) verranno visualizzate come modifiche di cui non è stato eseguito il commit nel warehouse. Gli utenti devono esaminare ed eseguire il commit di queste modifiche tramite il controllo del codice sorgente dell'area di lavoro nel portale di Fabric.
Pipeline di distribuzione
Inoltre è possibile usare le pipeline di distribuzione per implementare il codice di magazzino in ambienti diversi, ad esempio sviluppo, test e produzione. Le pipeline di distribuzione non espongono un progetto di database.
Usare la procedura seguente per completare la distribuzione del warehouse usando la pipeline di distribuzione.
- Creare una nuova pipeline di distribuzione o aprire una pipeline di distribuzione esistente. Per altre informazioni, vedere Inizia con le pipeline di distribuzione.
- Assegnare le aree di lavoro a fasi diverse in base agli obiettivi di distribuzione.
- Selezionare, visualizzare e confrontare gli articoli, inclusi i magazzini, tra fasi diverse, come illustrato nell'esempio seguente.
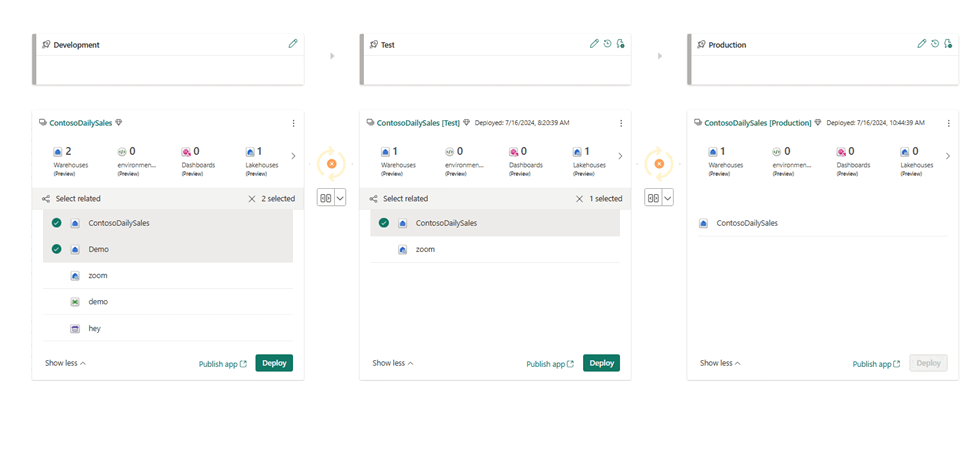
- Selezionare Implementare per implementare i magazzini nelle fasi Sviluppo, Test e Produzione.

Per ulteriori informazioni sul processo delle pipeline di distribuzione di Fabric, vedere Introduzione alle pipeline di distribuzione.
Limitazioni nel controllo del codice sorgente
- È necessario esportare o eseguire la migrazione delle funzionalità di sicurezza SQL usando un approccio basato su script. Prendere in considerazione l'uso di uno script post-distribuzione in un progetto di database SQL. È possibile configurare questo script aprendo il progetto con l'estensione progetti di database SQL disponibile in Visual Studio Code.
Limiti dell'integrazione Git
- Attualmente, se si usa
ALTER TABLEper aggiungere un vincolo o una colonna nel progetto di database, il processo di distribuzione elimina e ricrea la tabella, determinando la perdita di dati. Per mantenere la definizione e i dati della tabella, prendere in considerazione la soluzione alternativa seguente:- Creare una nuova copia della tabella nel magazzino usando
CREATE TABLEeINSERT,CREATE TABLE AS SELECT, o con Clona tabella. - Modificare la nuova definizione di tabella con nuovi vincoli o colonne, come desiderato, usando
ALTER TABLE. - Eliminare la tabella precedente.
- Rinominare la nuova tabella con il nome della tabella precedente usando sp_rename.
- Modificare la definizione della tabella precedente nel progetto di database SQL nello stesso identico modo. Il progetto di database SQL del magazzino nel controllo del codice sorgente e il magazzino live ora dovrebbero corrispondere.
- Creare una nuova copia della tabella nel magazzino usando
- L'integrazione Git di Fabric non supporta l'endpoint di analisi SQL.
- Le dipendenze tra elementi, il sequenziamento degli elementi e le lacune di sincronizzazione tra l'endpoint di analisi SQL e il magazzino dati influiscono sui flussi di lavoro di "diramarsi in un'area di lavoro nuova o esistente" e "passare a un ramo diverso" durante lo sviluppo e l'integrazione continua.
Limiti per le pipeline di distribuzione
- Attualmente, se si usa
ALTER TABLEper aggiungere un vincolo o una colonna nel progetto di database, il processo di distribuzione elimina e ricrea la tabella, determinando la perdita di dati. - Le pipeline di distribuzione di Fabric non supportano l'elemento dell'endpoint di analisi SQL.
- Dipendenze tra elementi, sequenziazione degli elementi e lacune di sincronizzazione tra l'endpoint di analisi SQL e il data warehouse influiscono sui flussi di lavoro delle pipeline di distribuzione di Fabric.
Scenari non supportati
I seguenti flussi di lavoro CI/CD non sono ufficialmente supportati quando i magazzini in spazi di lavoro diversi hanno collazioni diverse. Anche se queste operazioni potrebbero avere esito positivo senza errori, possono generare errori di metadati.
In tutti questi scenari, se si verifica una mancata corrispondenza delle regole di confronto, usare lo script Python scripts/dw-collation-error-update-tmsl/pbi_interactive.py nella casella degli strumenti Fabric GitHub repository per aggiornare le regole di confronto del set di dati (TMSL) in modo che corrispondano alle regole di confronto del warehouse.
| Scenario | Descrizione | Rischio |
|---|---|---|
| Pipeline di distribuzione | Promuovere il contenuto del magazzino dati attraverso le fasi della pipeline (ad esempio, Sviluppo → Test → Prod) quando il magazzino di destinazione è stato creato con una collazione diversa rispetto a quella dell'origine non è supportato. | La distribuzione potrebbe avere esito positivo, ma le regole di confronto del set di dati non vengono aggiornate in modo che corrispondano alle regole di confronto del data warehouse di destinazione. |
| Diramazione in un'area di lavoro nuova o esistente | L'integrazione di Git per creare una diramazione da un'area di lavoro esistente a una nuova o a un'altra area di lavoro esistente dove il warehouse ha una collatione diversa non è supportata. | Il contenuto del warehouse viene sincronizzato, ma i metadati della collazione non vengono riconciliati. |
| Passaggio di rami in un'area di lavoro | Il passaggio a un branch associato a un repository con una collation diversa in un'area di lavoro connessa a Git non è supportato. | Il contenuto sincronizzato può includere presupposti sulle regole di confronto che non corrispondono al warehouse corrente. |
| Unione di modifiche tra aree di lavoro tramite rami | L'unione di rami Git tra aree di lavoro in cui i warehouse hanno regole di confronto diverse non è supportata. | La merge può avere esito positivo a livello Git, ma la collazione del dataset risultante non riflette quella del warehouse di destinazione. |