Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:✅ endpoint di Analisi SQL e Warehouse in Microsoft Fabric
Questa esercitazione illustra come analizzare i dati con i notebook in un warehouse.
Nota
Questa esercitazione fa parte di uno scenario end-to-end . Per completare questa esercitazione, è prima necessario completare queste esercitazioni:
Creare un notebook T-SQL
Questa attività illustra come creare un notebook T-SQL.
Assicurati che l'area di lavoro creata nel primo tutorial sia aperta.
Nella barra multifunzione home
aprire l'elenco a discesa Nuova query SQL e quindi selezionareNuova query SQL nel notebook .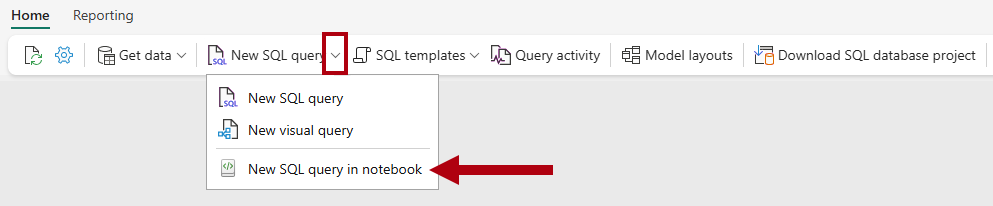
Nel riquadro
Explorer selezionare warehouseper visualizzare gli oggetti del magazzino . Per generare un modello SQL per esplorare i dati, a destra della tabella
dimension_cityselezionare i puntini (...), quindi selezionare SELECT TOP 100.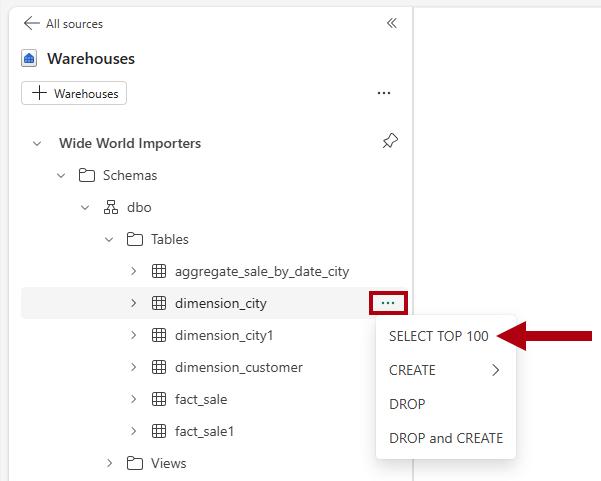
Per eseguire il codice T-SQL in questa cella, selezionare il pulsante Esegui cella per la cella di codice.
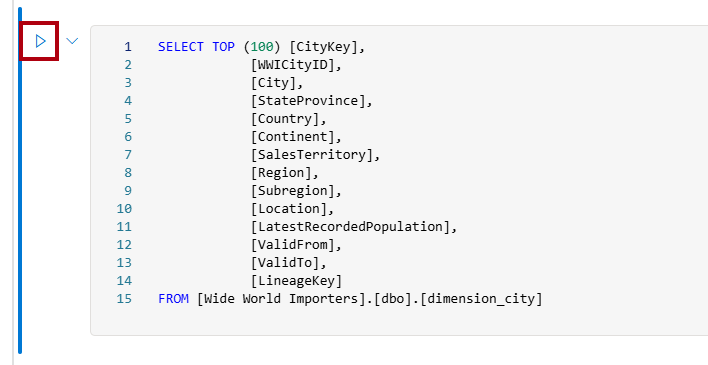
Esaminare il risultato della query nel riquadro dei risultati.


Creare un collegamento lakehouse e analizzare i dati con un notebook
In questa attività viene illustrato come creare un collegamento lakehouse e analizzare i dati con un notebook.
Apri la pagina principale dell'area di lavoro
Data Warehouse Tutorial.Selezionare + Nuovo elemento per visualizzare l'elenco completo dei tipi di elementi disponibili.
Nell'elenco, nella sezione Salvataggio dati, selezionare il tipo di elemento Lakehouse.
Nella finestra New lakehouse immettere il nome
Shortcut_Exercise.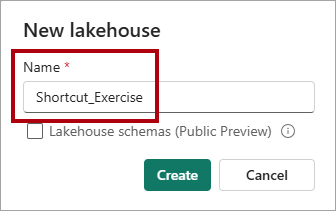
Seleziona Crea.
Quando si apre il nuovo lakehouse, nella pagina di destinazione selezionare l'opzione Nuovo collegamento.
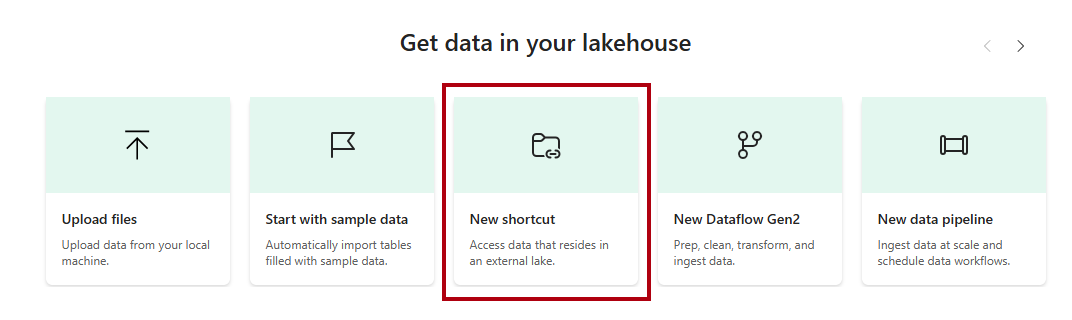
Nella finestra Nuovo collegamento selezionare l'opzione Microsoft OneLake.
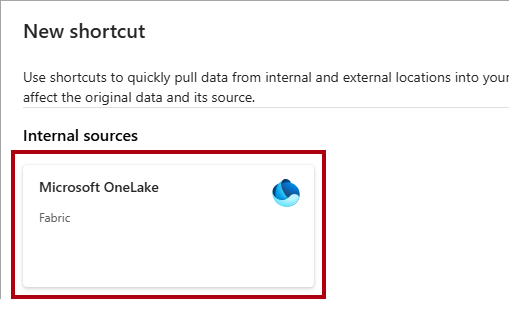
Nella finestra Seleziona un tipo di origine dati, seleziona il data warehouse
Wide World Importersche hai creato nell'esercitazione Crea un Warehouse e quindi seleziona Avanti.Nel visualizzatore oggetti OneLake espandere Tabelle, espandere lo schema
dboe quindi selezionare la casella di controllo per la tabelladimension_customer.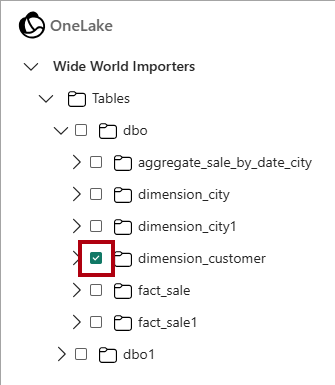
Selezionare Avanti.
Seleziona Crea.
Nel riquadro di Esplora , selezionare la tabella
dimension_customerper visualizzare in anteprima i dati, e quindi esaminare i dati recuperati dalla tabelladimension_customernel magazzino.Per creare un notebook per eseguire una query sulla tabella
dimension_customer, nella barra multifunzione Home, nell'elenco a discesa Apri notebook, selezionare Nuovo notebook.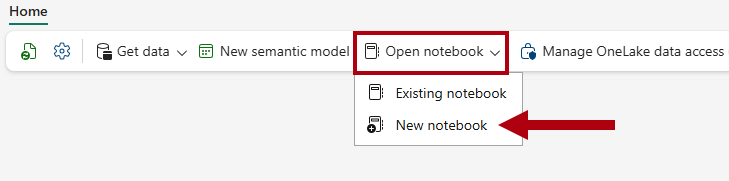
Nel riquadro Explorer , selezionare Lakehouses.
Trascina la tabella
dimension_customernella cella del notebook aperta.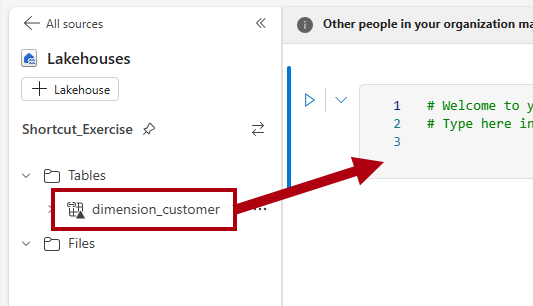
Si noti la query PySpark aggiunta alla cella del notebook. Questa query recupera le prime 1.000 righe dalla scorciatoia
Shortcut_Exercise.dimension_customer. Questa esperienza notebook è simile all'esperienza Jupyter di Visual Studio Code. È anche possibile aprire il notebook in VS Code.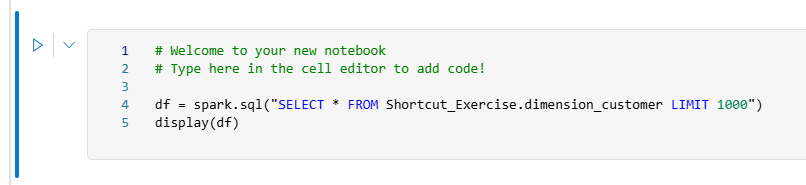
Nella barra multifunzione Home , selezionare il pulsante Esegui tutto .

Esaminare il risultato della query nel riquadro dei risultati.

