Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
si applica a:✅database SQL in Microsoft Fabric
È possibile immettere dati nel database SQL in Fabric usando istruzioni Transact-SQL (T-SQL) ed è anche possibile importare dati nel database usando altri componenti di Microsoft Fabric, ad esempio la funzionalità Dataflow Gen2 o le pipeline. Per lo sviluppo, è possibile connettersi a qualsiasi strumento che supporti il protocollo TDS (Tabular Data Stream), ad esempio Visual Studio Code o SQL Server Management Studio.
Per iniziare questa sezione, è possibile usare i dati di esempio SalesLT forniti come punto di partenza.
Prerequisites
- Completare tutti i passaggi precedenti di questa esercitazione.
Aprire l'editor di query nel portale di Fabric
Apri il database SQL nel database Fabric che hai creato nell'ultimo passaggio dell'esercitazione. È possibile trovarla nella barra di spostamento del portale di Fabric o individuarla nell'area di lavoro per questa esercitazione.
Selezionare il pulsante Dati di esempio . Ci vorranno solo pochi istanti per popolare il tuo database di esercitazione con i dati di esempio SalesLT.
Controllare l'area Notifiche per assicurarsi che l'importazione sia stata completata prima di procedere.
Le notifiche mostrano quando l'importazione dei dati di esempio è stata completata. Ora, il tuo database SQL in Fabric contiene lo schema
SalesLTe le tabelle associate.

Usare il database SQL nell'editor SQL
L'editor SQL basato sul Web per il database SQL in Fabric fornisce un'interfaccia di esplorazione di oggetti e esecuzione di query di base. Viene aperto automaticamente un nuovo database SQL in Fabric nell'editor SQL e un database esistente può essere aperto nell'editor SQL aprendolo nel portale di Infrastruttura.
Sono disponibili diversi elementi nella barra degli strumenti dell'editor Web, tra cui aggiornamento, impostazioni, un'operazione di query e la possibilità di ottenere informazioni sulle prestazioni. Queste funzionalità verranno usate in questa esercitazione.
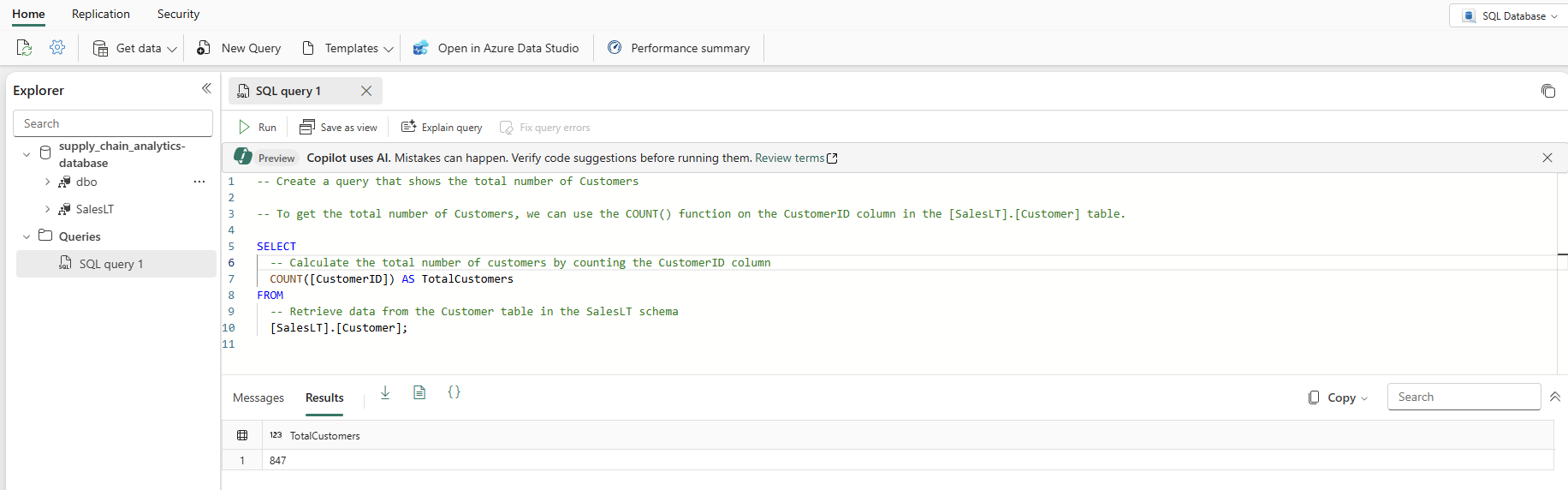
Nella visualizzazione database selezionare Nuova query dalla barra delle icone. Verrà visualizzato un editor di query con la funzionalità di intelligenza artificiale Copilot che consente di scrivere il codice. Il copilot per il database SQL può essere utile per completare una query o crearne una.
Digitare un commento T-SQL nella parte superiore della query, ad esempio
-- Create a query that shows the total number of customerse premere INVIO. Si ottiene un risultato simile al seguente:
Premendo il tasto "Tab" viene implementato il codice suggerito:
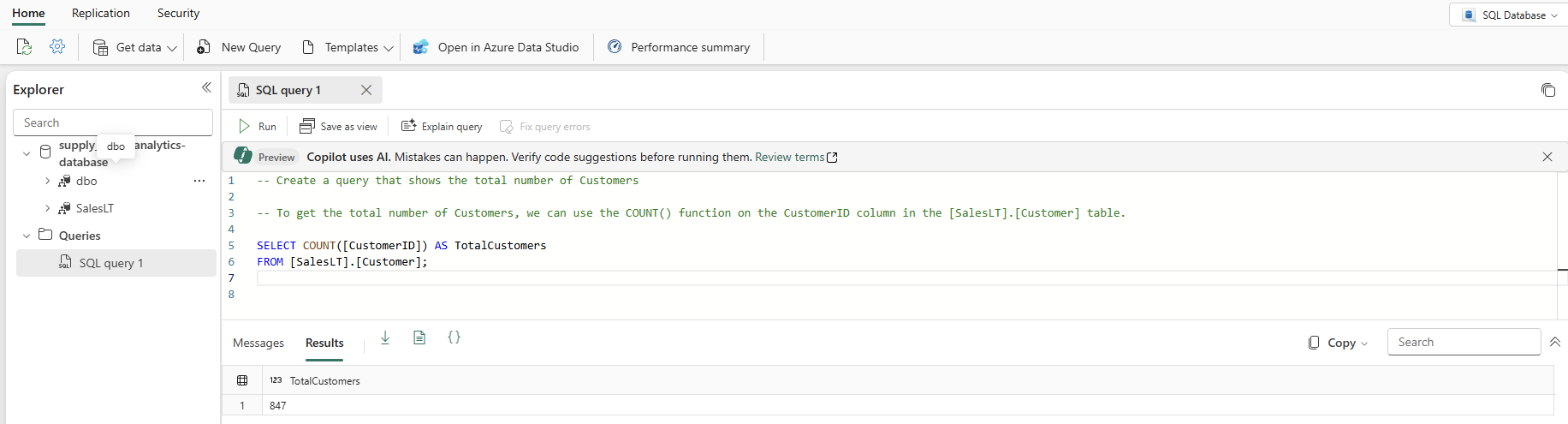
Selezionare Spiega query nella barra dell'icona dell'editor di query per inserire commenti nel codice per spiegare ogni passaggio principale:
Note
Copilot tenta di capire meglio la finalità, ma è consigliabile controllare sempre il codice creato prima di eseguirlo e testare sempre in un ambiente separato dall'ambiente di produzione.



In un ambiente di produzione potrebbero essere presenti dati già in un formato normalizzato per le operazioni quotidiane dell'applicazione, simulate qui con i dati SalesLT . Quando si crea una query, questa viene salvata automaticamente nell'elemento Query nel riquadro Esplora. La query dovrebbe essere visualizzata come "Query SQL 1". Per impostazione predefinita, il sistema numera le query come "QUERY SQL 1", ma è possibile selezionare i puntini di sospensione accanto al nome della query per duplicare, rinominare o eliminare la query.
Inserire dati usando Transact-SQL
È stato chiesto di creare nuovi oggetti per tenere traccia della supply chain dell'organizzazione, quindi è necessario aggiungere un set di oggetti per l'applicazione. In questo esempio si creerà un singolo oggetto in un nuovo schema. È possibile aggiungere altre tabelle per normalizzare completamente l'applicazione. È possibile aggiungere altri dati, ad esempio più componenti per prodotto, avere più informazioni sul fornitore e così via. Più avanti in questa esercitazione si vedrà come eseguire il mirroring dei dati nell'endpoint di analisi SQL e come eseguire query sui dati con un'API GraphQL per regolare automaticamente quando gli oggetti vengono aggiunti o modificati.
I passaggi seguenti usano uno script T-SQL per creare uno schema, una tabella e i dati per i dati simulati per l'analisi della supply chain.
Selezionare il pulsante Nuova query sulla barra degli strumenti del database SQL per creare una nuova query.
Incollare lo script seguente nell'area Query e selezionare Esegui per eseguirlo. Lo script T-SQL seguente:
- Crea uno schema denominato
SupplyChain. - Crea una tabella denominata
SupplyChain.Warehouse. - Popola la
SupplyChain.Warehousetabella con alcuni dati del prodotto creati in modo casuale daSalesLT.Product.
/* Create the Tutorial Schema called SupplyChain for all tutorial objects */ CREATE SCHEMA SupplyChain; GO /* Create a Warehouse table in the Tutorial Schema NOTE: This table is just a set of INT's as Keys, tertiary tables will be added later */ CREATE TABLE SupplyChain.Warehouse ( ProductID INT PRIMARY KEY -- ProductID to link to Products and Sales tables , ComponentID INT -- Component Identifier, for this tutorial we assume one per product, would normalize into more tables , SupplierID INT -- Supplier Identifier, would normalize into more tables , SupplierLocationID INT -- Supplier Location Identifier, would normalize into more tables , QuantityOnHand INT); -- Current amount of components in warehouse GO /* Insert data from the Products table into the Warehouse table. Generate other data for this tutorial */ INSERT INTO SupplyChain.Warehouse (ProductID, ComponentID, SupplierID, SupplierLocationID, QuantityOnHand) SELECT p.ProductID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS ComponentID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierID, ABS(CHECKSUM(NEWID())) % 10 + 1 AS SupplierLocationID, ABS(CHECKSUM(NEWID())) % 100 + 1 AS QuantityOnHand FROM [SalesLT].[Product] AS p; GOIl database SQL nel database Fabric ora include le informazioni di Magazzino. Questi dati verranno usati in un passaggio successivo di questa esercitazione.
- Crea uno schema denominato
È possibile selezionare queste tabelle nel riquadro Esplora risorse e visualizzare i dati della tabella. Non è necessario scrivere una query per visualizzarla.
Inserire dati usando una pipeline di Microsoft Fabric
Un altro modo per importare ed esportare dati dal database SQL in Fabric consiste nell'usare una pipeline di Microsoft Fabric. Le pipeline offrono invece un'alternativa all'uso dei comandi, usando un'interfaccia utente grafica. Una pipeline è un raggruppamento logico di attività che insieme eseguono un'attività di inserimento dati. Le pipeline consentono di gestire le attività di estrazione, trasformazione e caricamento (ETL) anziché gestirle singolarmente.
Le pipeline di Microsoft Fabric possono contenere un flusso di dati. Dataflow Gen2 usa un'interfaccia di Power Query che consente di eseguire trasformazioni e altre operazioni sui dati. Questa interfaccia verrà usata per inserire dati dalla società Northwind Traders , con cui Contoso collabora. Attualmente usano gli stessi fornitori, quindi verranno importati i dati e verranno visualizzati i nomi di questi fornitori usando una visualizzazione che verrà creata in un altro passaggio di questa esercitazione.
Per iniziare, visualizza la vista SQL del database di esempio nel portale Fabric, se non è già aperta.
Selezionare il pulsante Recupera dati dalla barra dei menu.
Selezionare Nuovo flusso di dati Gen2.
Nella visualizzazione Power Query selezionare il pulsante Recupera dati . Verrà avviato un processo guidato anziché passare a una determinata area dati.
Nella casella di ricerca di Scegli origine dati digitare odata.
Selezionare OData nei risultati Nuove origini .
Nella casella di testo URL della vista Connetti all'origine dati, digitare il testo:
https://services.odata.org/v4/northwind/northwind.svc/per il feed Open Data del database di esempioNorthwind. Selezionare il pulsante Avanti per continuare.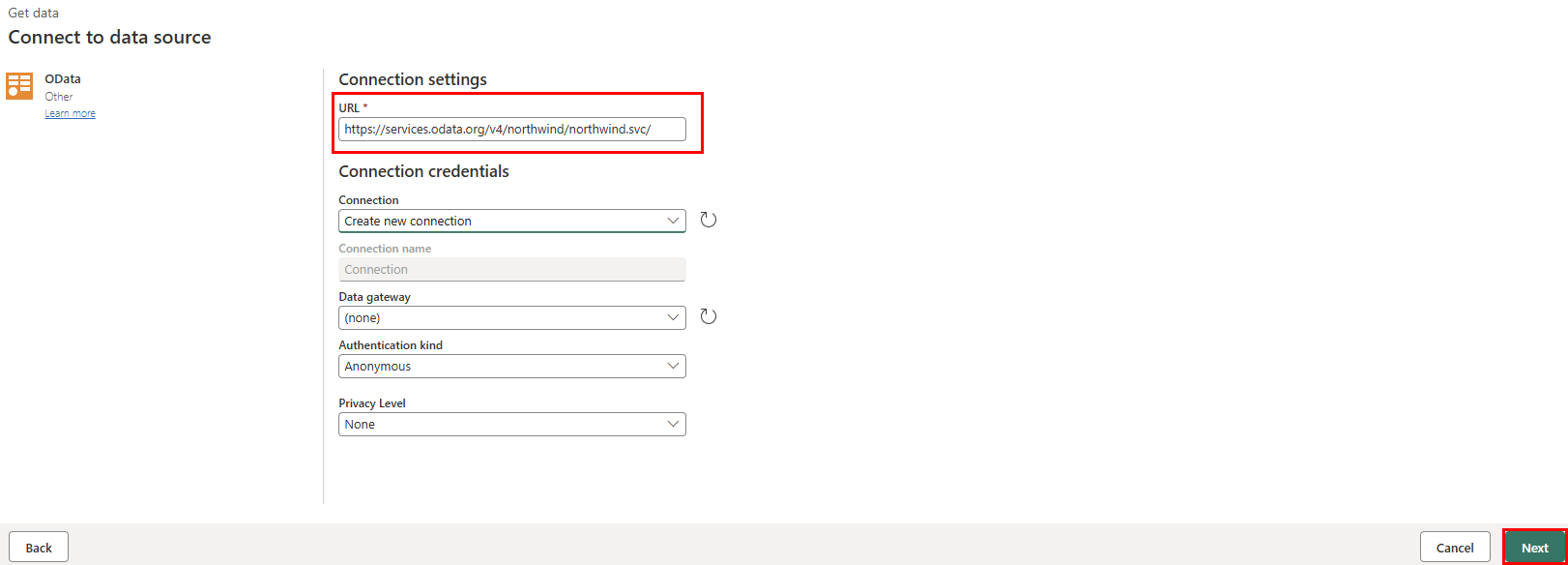
Scorrere verso il basso fino alla tabella Suppliers dal feed OData e selezionare la casella di controllo accanto. Selezionare quindi il pulsante Crea .
Selezionare ora il + segno più accanto alla sezione Destinazione dati di Impostazioni query e selezionare Database SQL dall'elenco.
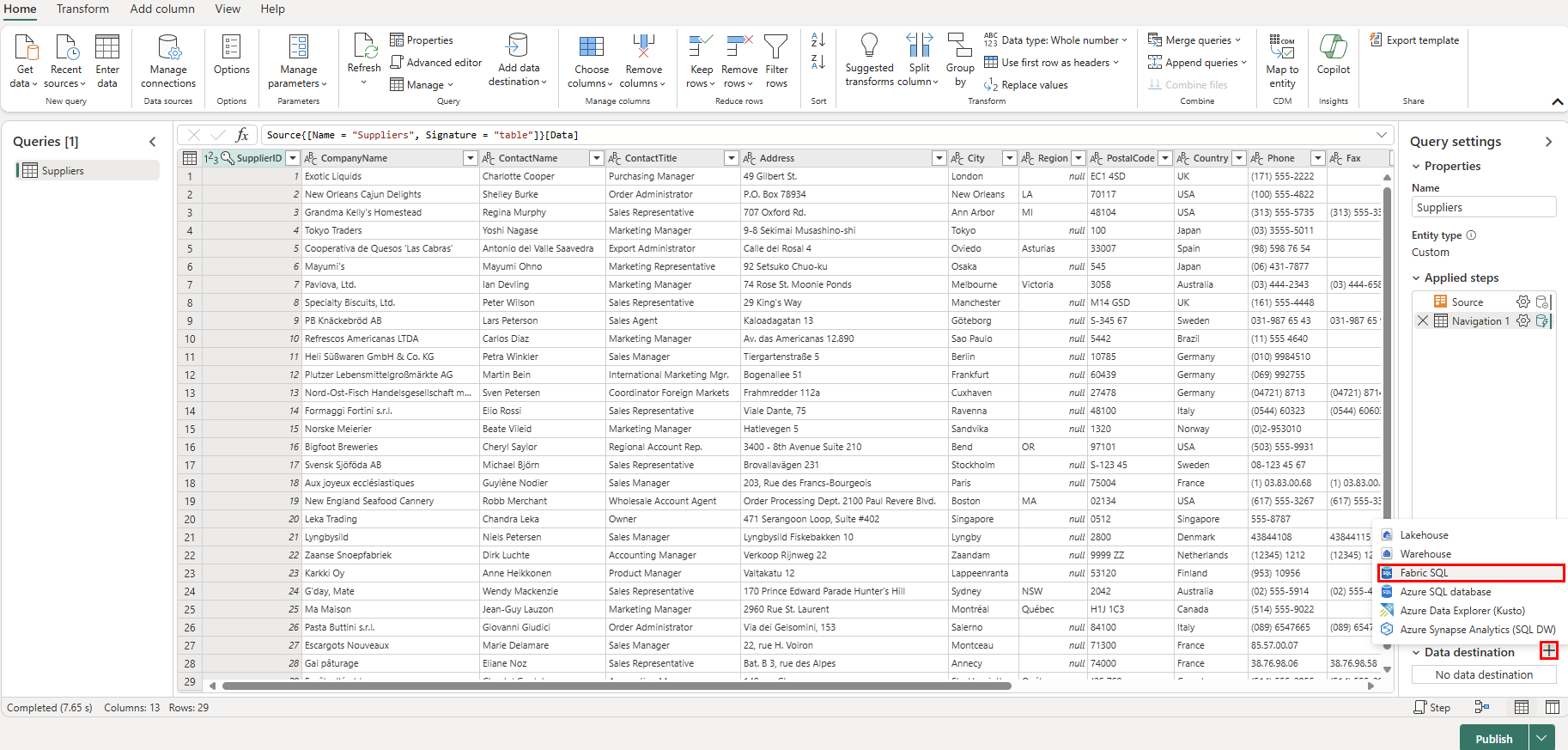
Nella pagina Connetti alla destinazione dati verificare che il tipo di autenticazione sia impostato su Account aziendale. Selezionare Accedi e immettere le credenziali di Microsoft Entra ID per il database.
Una volta stabilita la connessione, selezionare il pulsante Avanti .
Selezionare il nome dell'area di lavoro creato nel primo passaggio di questa esercitazione nella sezione Scegliere la destinazione di destinazione .
Selezionare il database visualizzato sotto di esso. Assicurarsi che il pulsante di opzione Nuova tabella sia selezionato e lasciare il nome della tabella come Fornitori e selezionare il pulsante Avanti .
Lasciare il dispositivo di scorrimento Usa impostazioni automatiche impostato nella visualizzazione Scegli impostazioni di destinazione e selezionare il pulsante Salva impostazioni .
Selezionare il pulsante Pubblica per avviare il trasferimento dei dati.
Si torna alla visualizzazione Area di lavoro, in cui è possibile trovare il nuovo elemento Flusso di dati.

Quando la colonna Aggiornata mostra la data e l'ora correnti, è possibile selezionare il nome del database in Esplora risorse e quindi espandere lo
dboschema per visualizzare la nuova tabella. Potrebbe essere necessario selezionare l'icona Aggiorna sulla barra degli strumenti.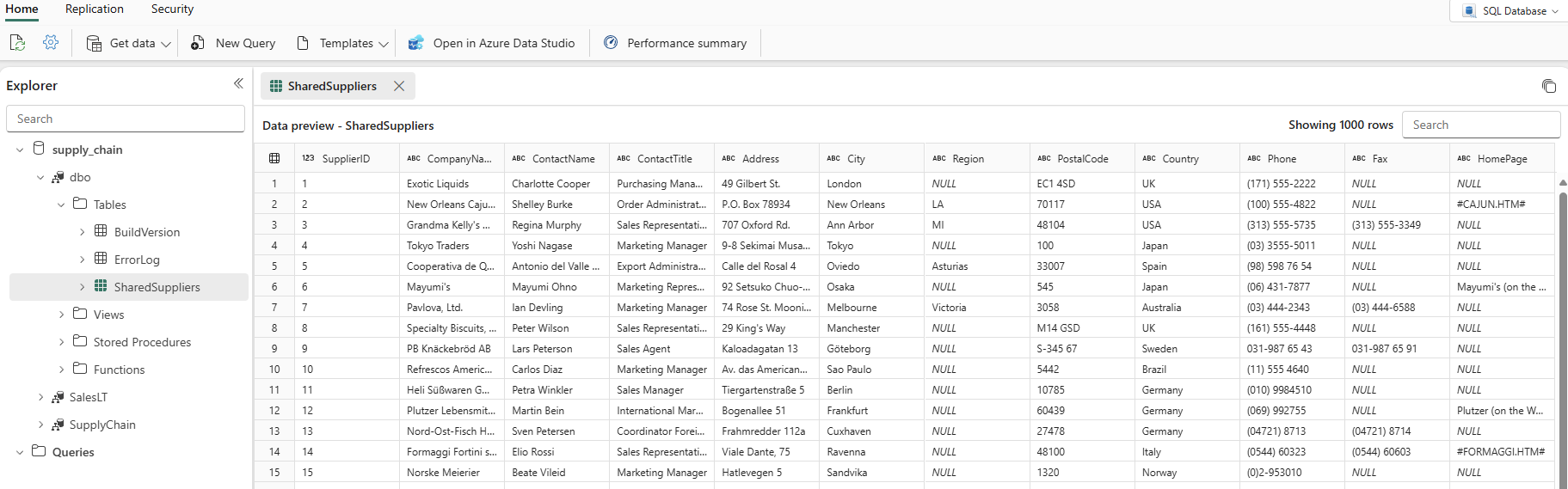




I dati vengono ora inseriti nel database. È ora possibile creare una query che combina i dati della Suppliers tabella usando questa tabella terziaria. Questa operazione verrà eseguita più avanti nell'esercitazione.