Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I flussi di dati sono una tecnologia self-service e basata sul cloud per la preparazione dei dati. Questo articolo si descrive come creare il primo flusso di dati, come ottenere i dati per il flusso di dati e infine come trasformare i dati e pubblicare il flusso di dati.
Prerequisiti
Prima di cominciare, sono necessari i seguenti prerequisiti:
- Un account tenant Microsoft Fabric con una sottoscrizione attiva. Creare un account gratuito.
- Assicurarsi di avere un'area di lavoro abilitata per Microsoft Fabric: Creare un'area di lavoro.
Creazione di un flusso di dati
In questa sezione, creerai il tuo primo flusso di dati.
Annotazioni
A partire da aprile 2026, tutti i nuovi elementi di Dataflow Gen2 vengono creati con il supporto CI/CD e l'integrazione di Git per impostazione predefinita. L'opzione per creare elementi di Dataflow Gen2 senza supporto CI/CD non è più disponibile. I flussi di dati non CI/CD esistenti continuano a funzionare.
Passare all'area di lavoro Microsoft Fabric passando al portale Microsoft Fabric, selezionare Workspaces dal riquadro di spostamento a sinistra e quindi selezionare l'area di lavoro dall'elenco.
Selezionare +Nuovo elemento e quindi selezionare Flusso di dati Gen2.
Screenshot con l'enfasi sulla selezione di Dataflow Gen2.
Recupero dei dati
Otteniamo alcuni dati. In questo esempio i dati vengono recuperati da un servizio OData. La procedura seguente descrive come inserire i dati nel flusso di dati.
Nell'editor del flusso di dati selezionare Recupera dati e quindi selezionare Altro.
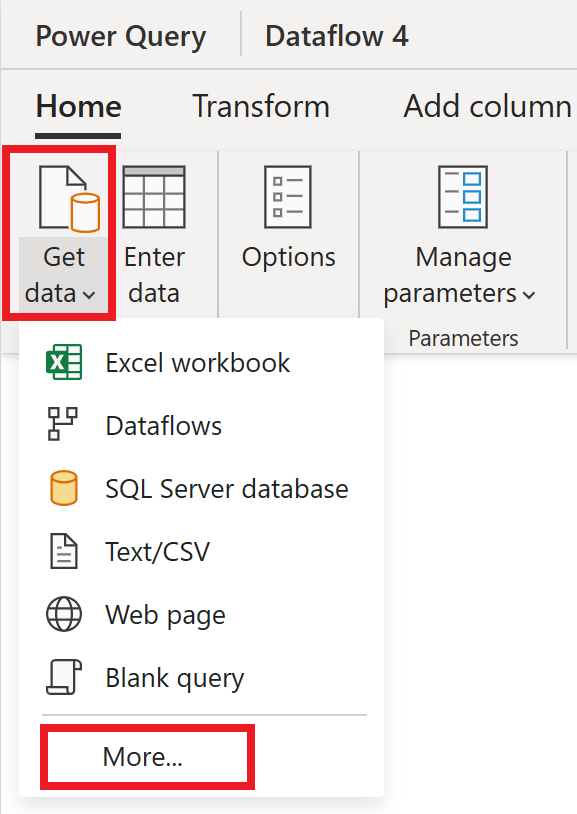
In Scegli origine dati selezionare Visualizza altro.
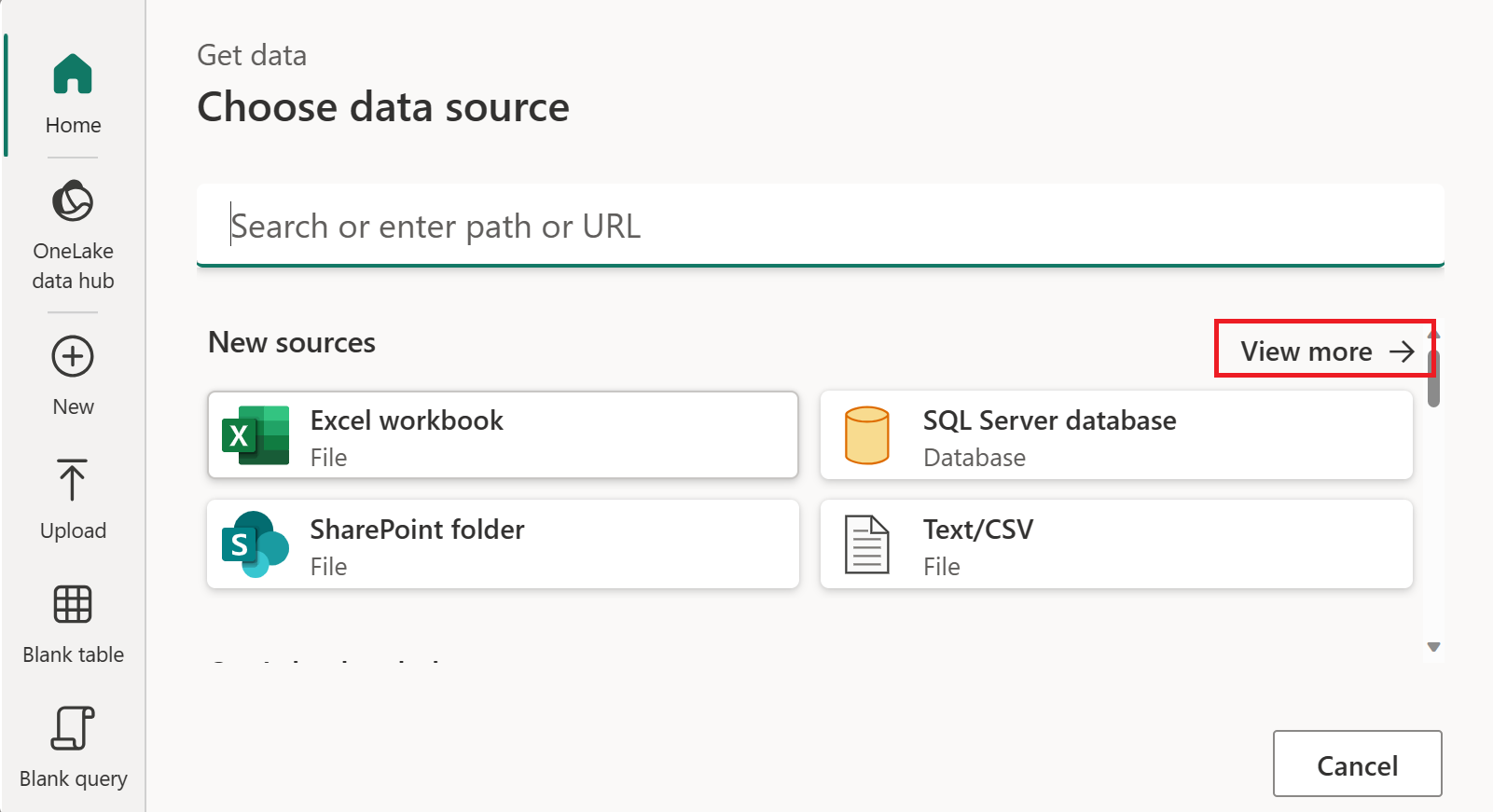
In Nuova origine selezionare Altro>OData come origine dati.

Immettere l'URL
https://services.odata.org/v4/northwind/northwind.svc/e quindi selezionare Avanti.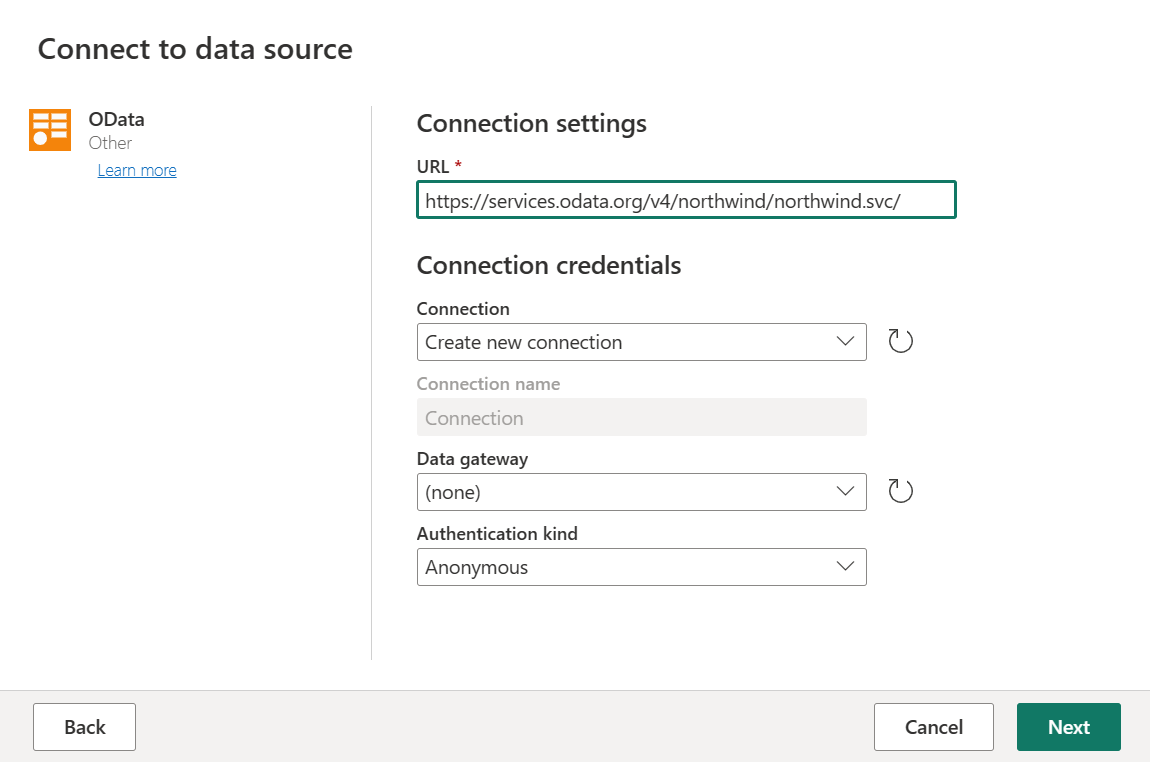
Selezionare le tabelle Ordini e Clienti, quindi selezionare Crea.
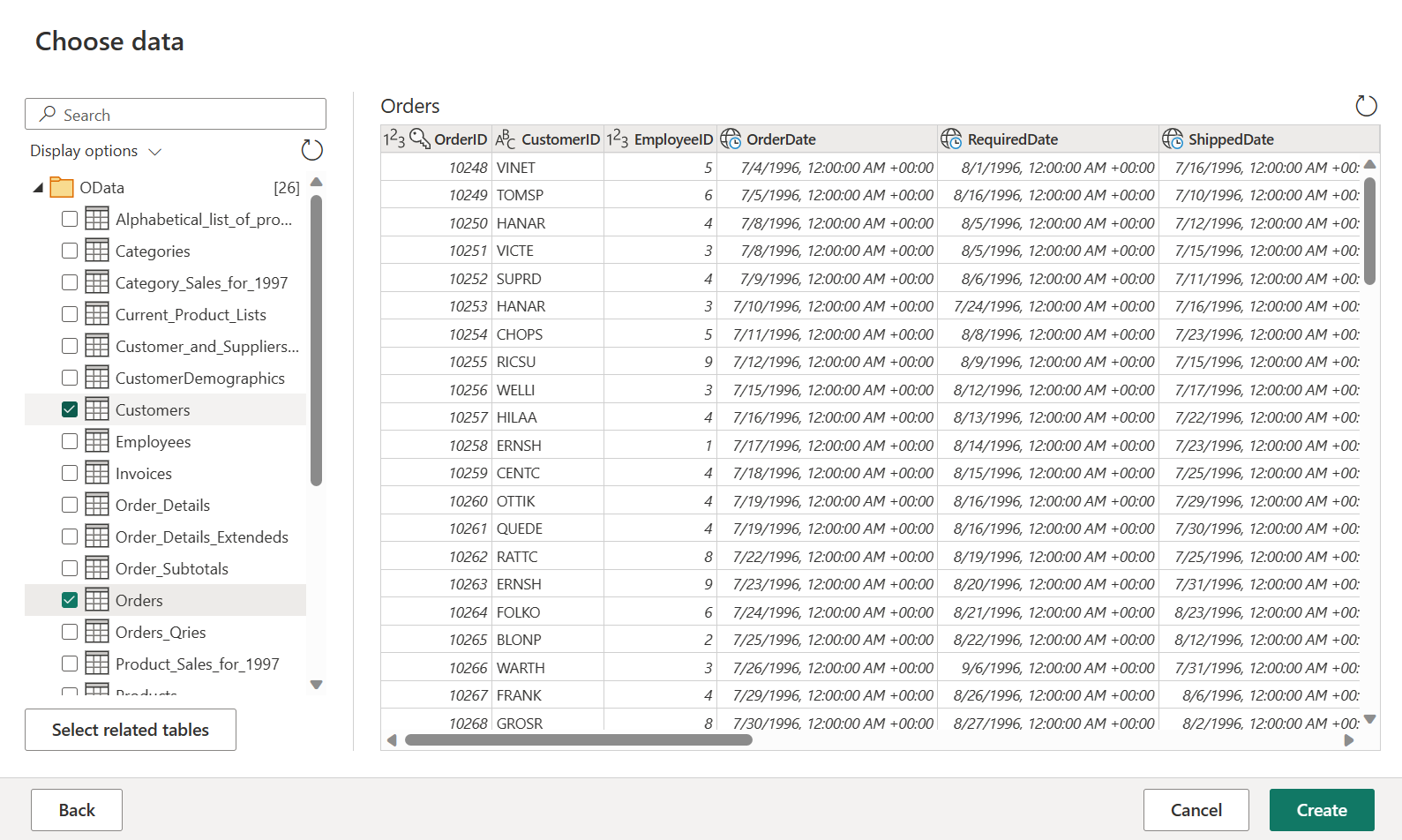



Per altre informazioni sull'esperienza e sulle funzionalità di recupero dei dati, consulta la panoramica di recupero dei dati.
Applicare le trasformazioni e pubblicare
Hai caricato i tuoi dati nel tuo primo flusso di dati. Felicitazioni! È ora possibile applicare un paio di trasformazioni per inserire questi dati nella forma necessaria.
Si trasformano i dati nell'editor di Power Query. È possibile trovare una panoramica dettagliata dell'editor di Power Query in Il Power Query'interfaccia utente, ma questa sezione illustra i passaggi di base:
Assicurarsi che gli strumenti di profilatura dei dati siano attivati. Passare a Home>Opzioni>Opzioni globali, quindi selezionare tutte le opzioni in Profilo colonna.
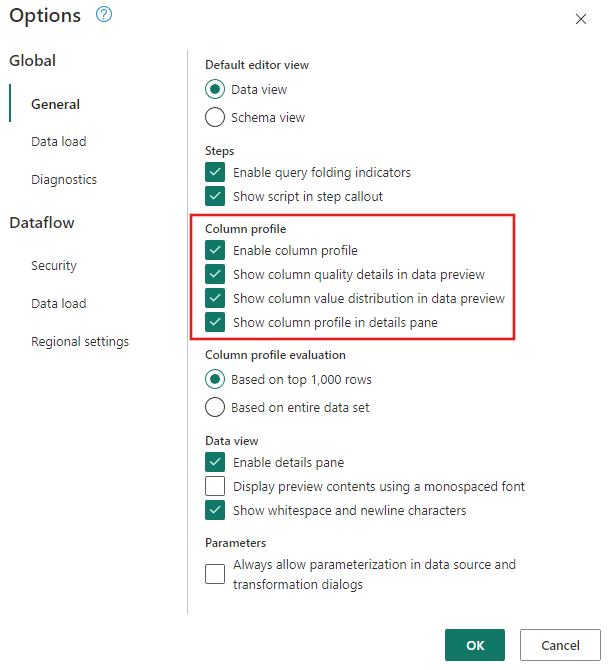
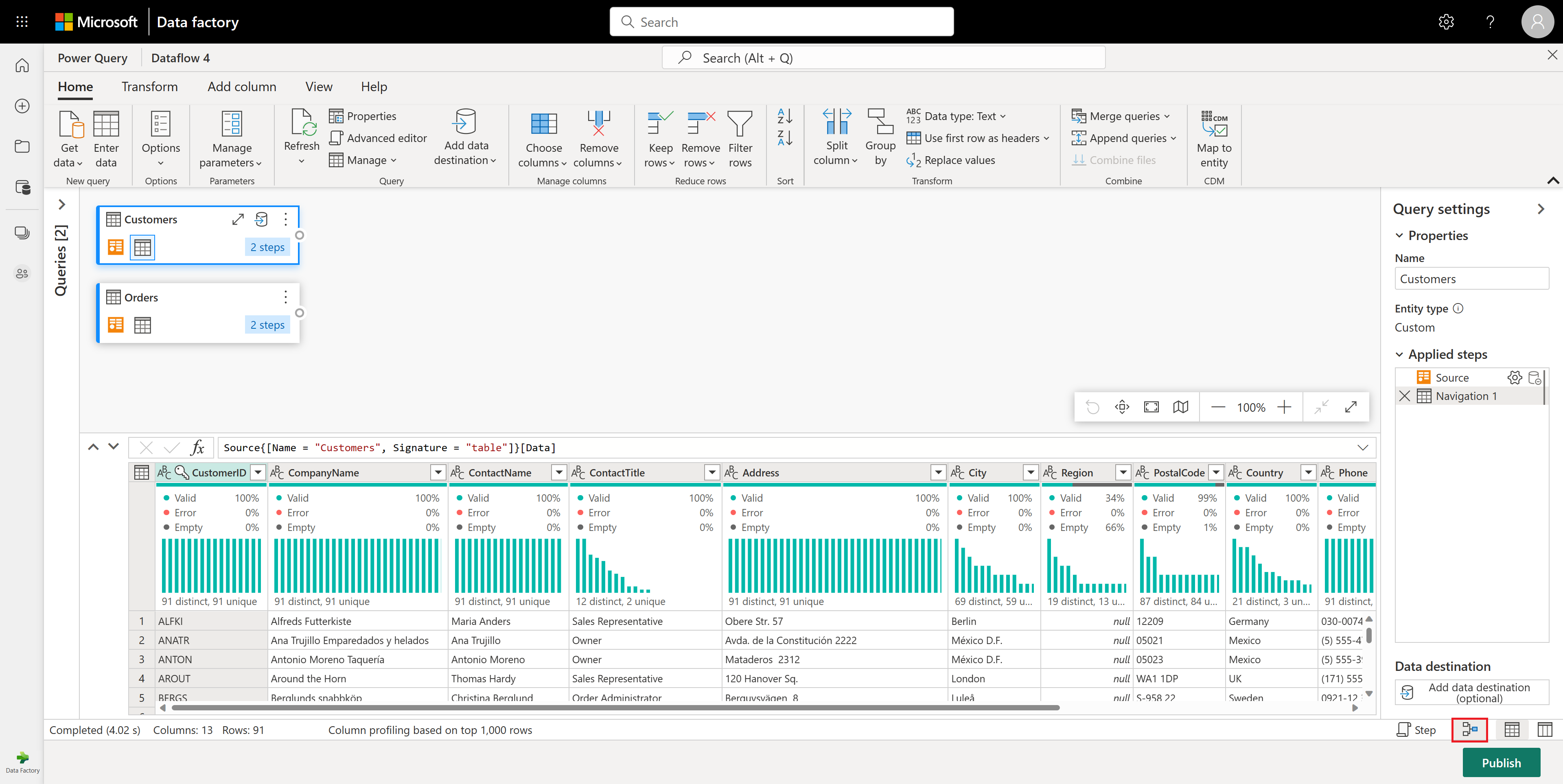
Assicurarsi inoltre di abilitare la visualizzazione diagramma usando le configurazioni layout nella barra multifunzione View nella barra multifunzione dell'editor di Power Query oppure selezionando l'icona della visualizzazione diagramma sul lato inferiore destro della finestra Power Query.
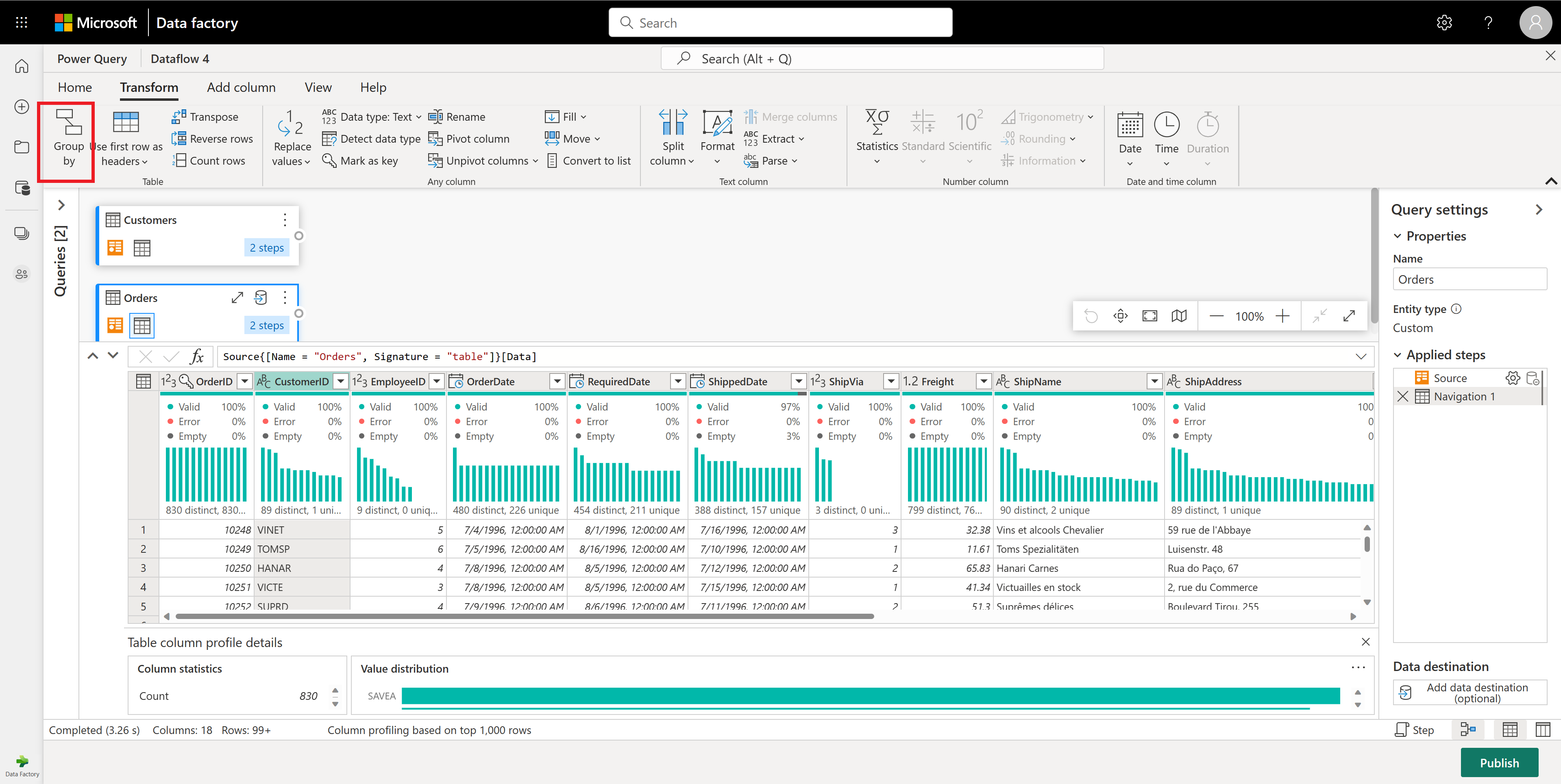
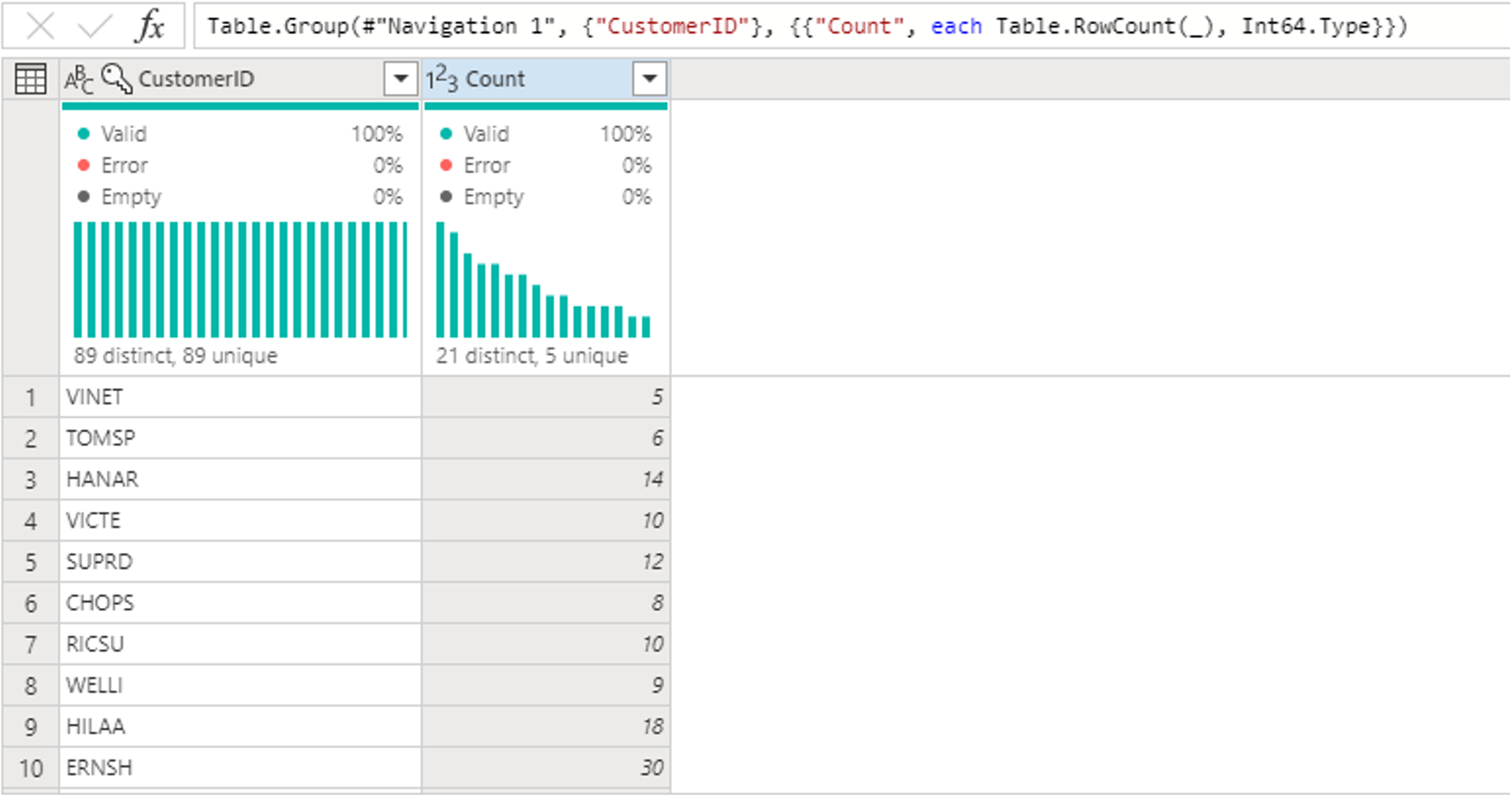
Nella tabella Orders calcolare il numero totale di ordini per cliente: selezionare la colonna CustomerID nell'anteprima dei dati e quindi selezionare Raggruppa per nella scheda Trasforma della barra multifunzione.
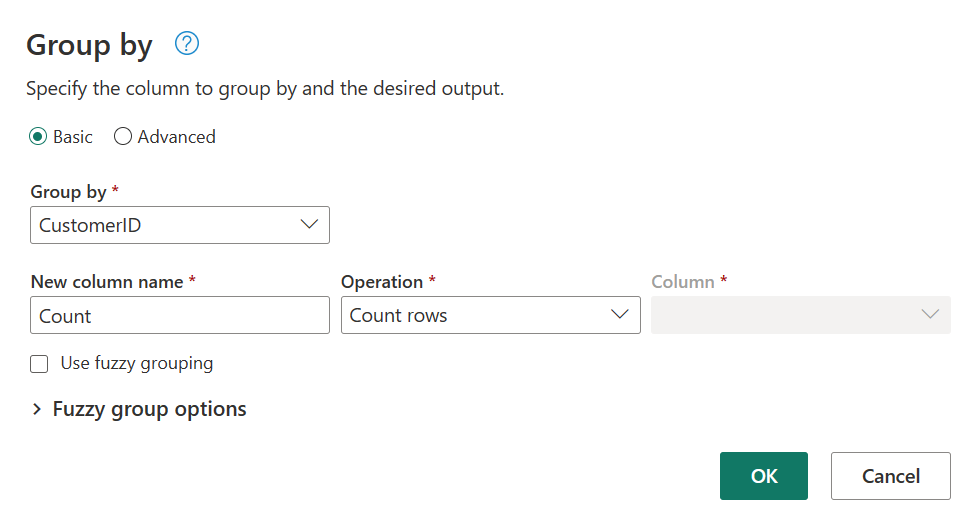
Si esegue un conteggio delle righe come aggregazione all'interno di Raggruppa per. Per altre informazioni sulle funzionalità Group By , vedere Raggruppamento o riepilogo delle righe.
Dopo il raggruppamento dei dati nella tabella Ordini, si otterrà una tabella con due colonne: CustomerID e Count.
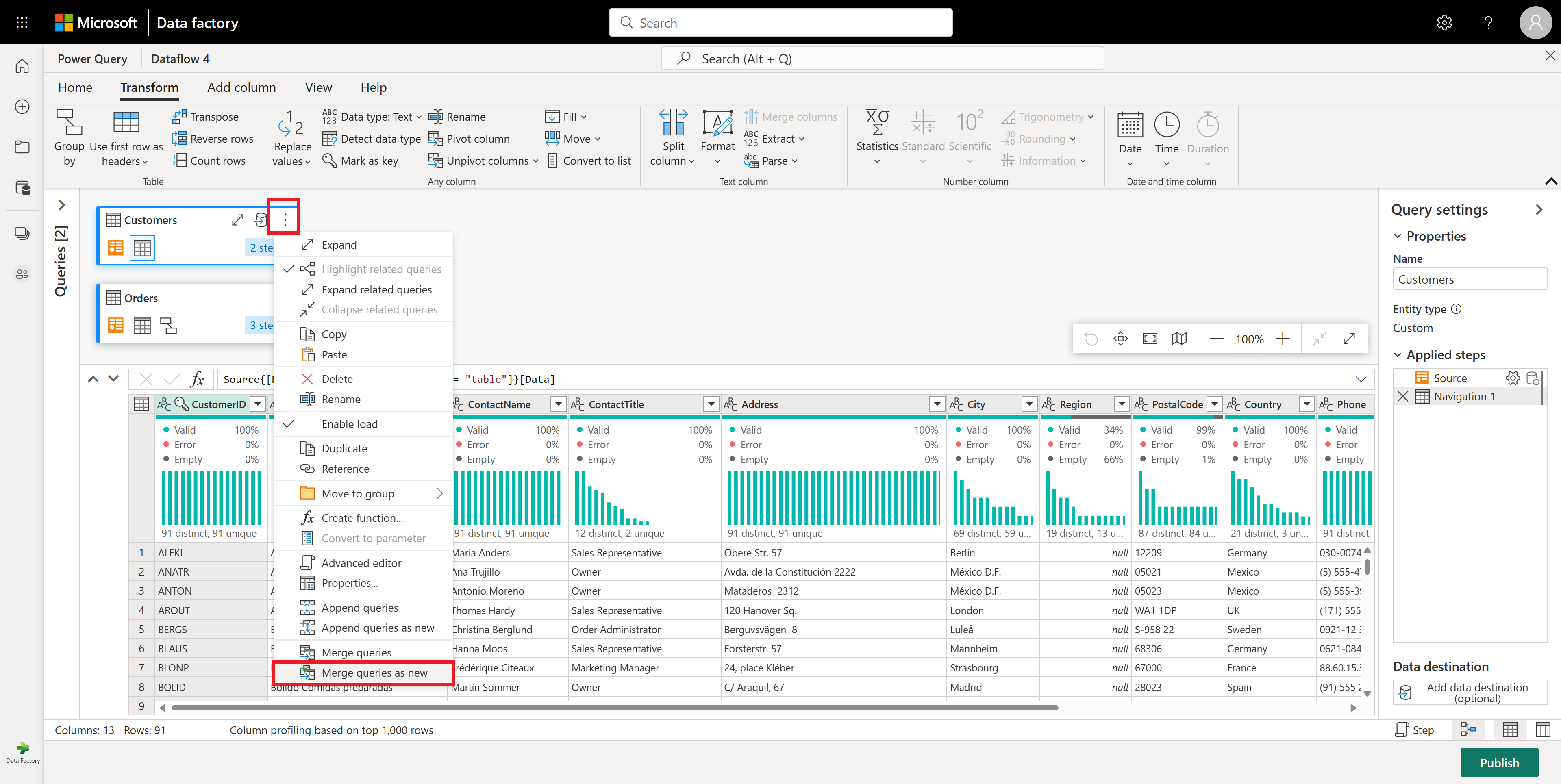
Successivamente, desideri combinare i dati della tabella Customers con il conteggio degli ordini per ciascun cliente: seleziona la query Customers nella Vista Diagramma e usa il menu "⋮" per accedere alla trasformazione Unisci query come nuova.
Configurare l'operazione di merge selezionando CustomerID come colonna corrispondente in entrambe le tabelle. Quindi scegliere OK.
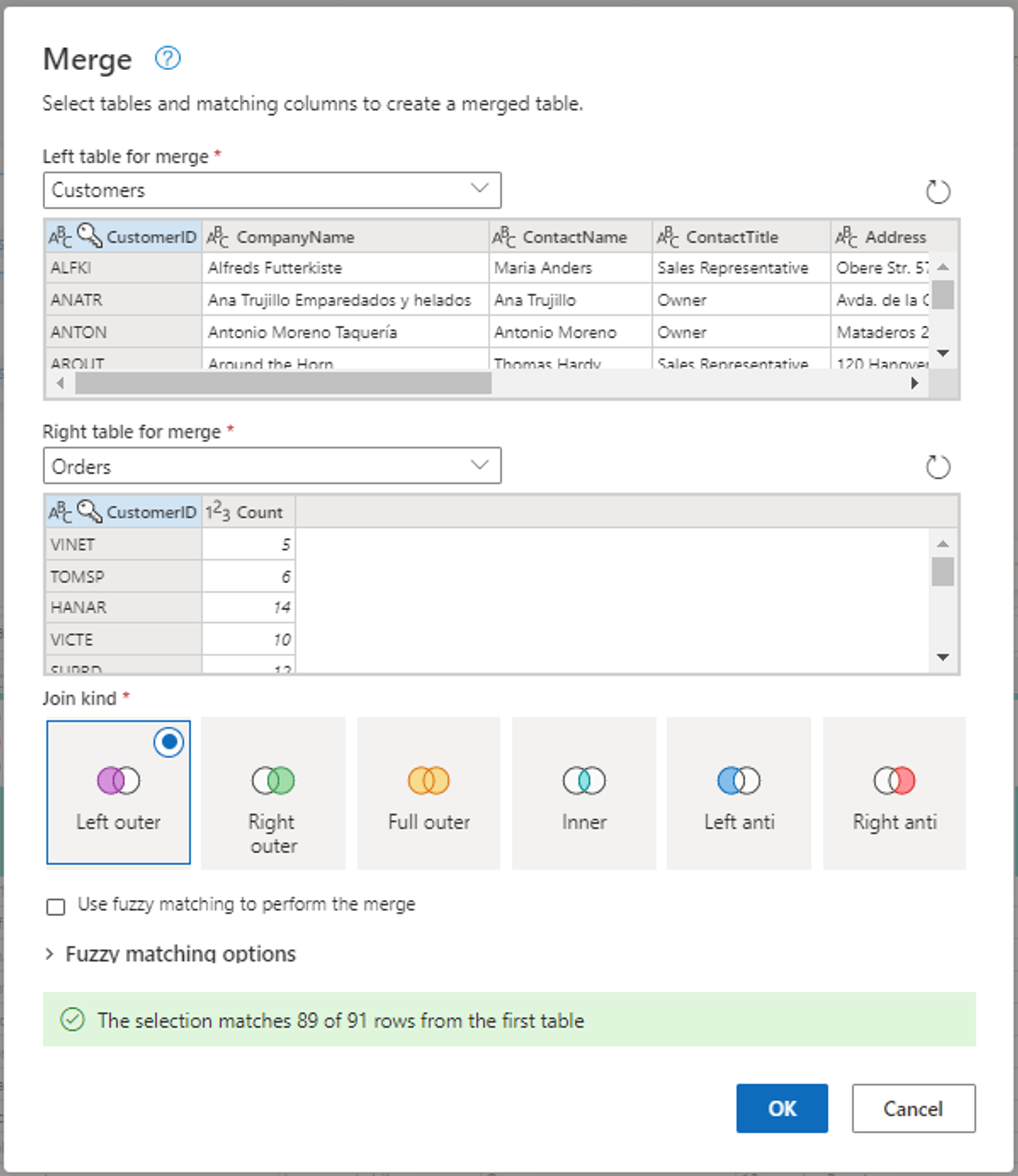
Screenshot della finestra di unione, con la tabella di sinistra impostata sulla tabella Clienti e la tabella di destra impostata sulla tabella Ordini. La colonna IDCliente è selezionata sia nella tabella Clienti che nella tabella Ordini. Inoltre, il tipo di join è impostato su Left Outer. Tutte le altre opzioni sono sui valori predefiniti.
È ora disponibile una nuova query con tutte le colonne della tabella Customers e una colonna con dati annidati dalla tabella Orders.

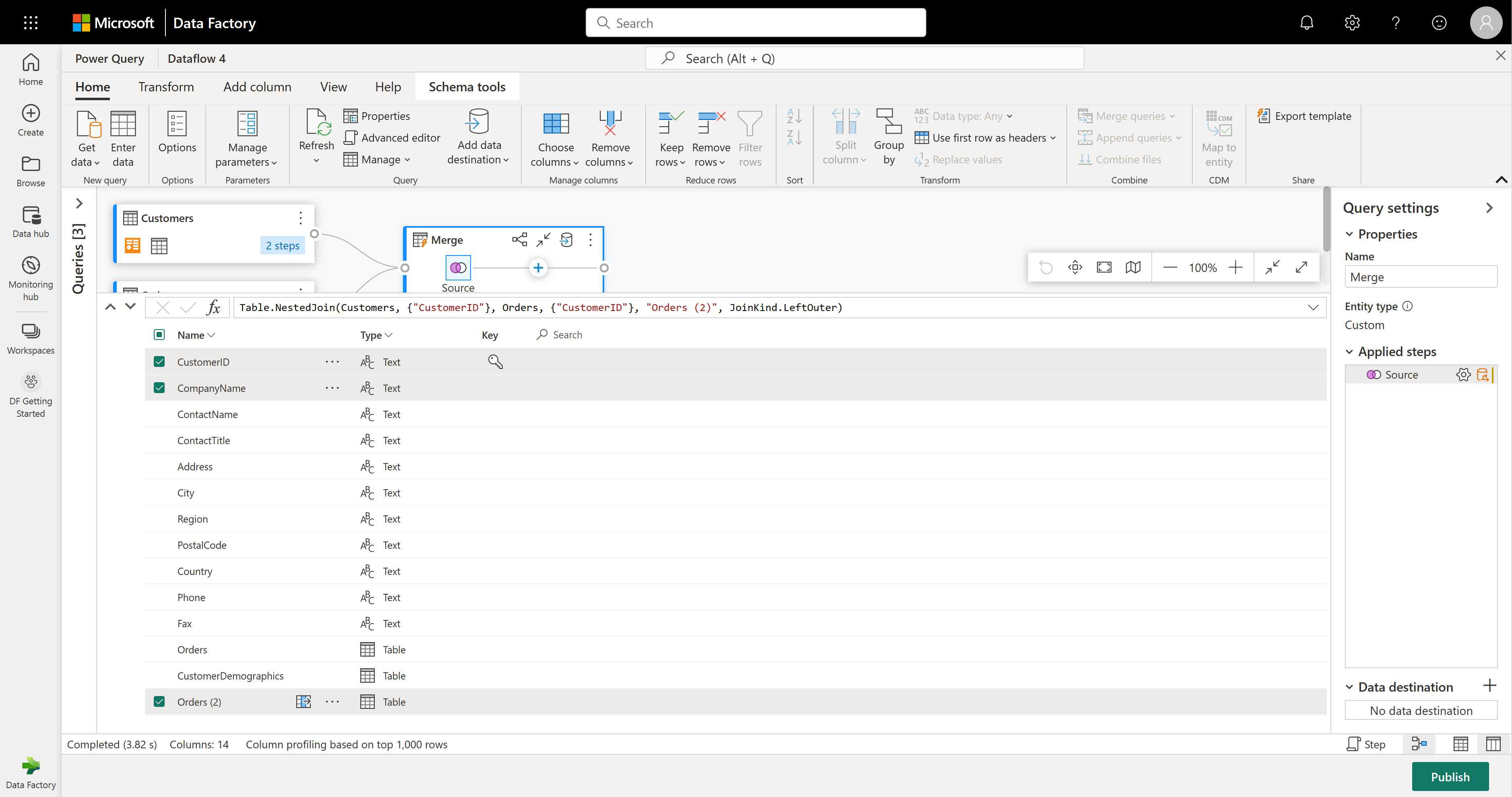
Si esaminerà ora solo alcune colonne della tabella Customers. A tale scopo, attivare la visualizzazione schema selezionando il pulsante Visualizzazione schema nell'angolo in basso a destra dell'editor del flusso di dati.
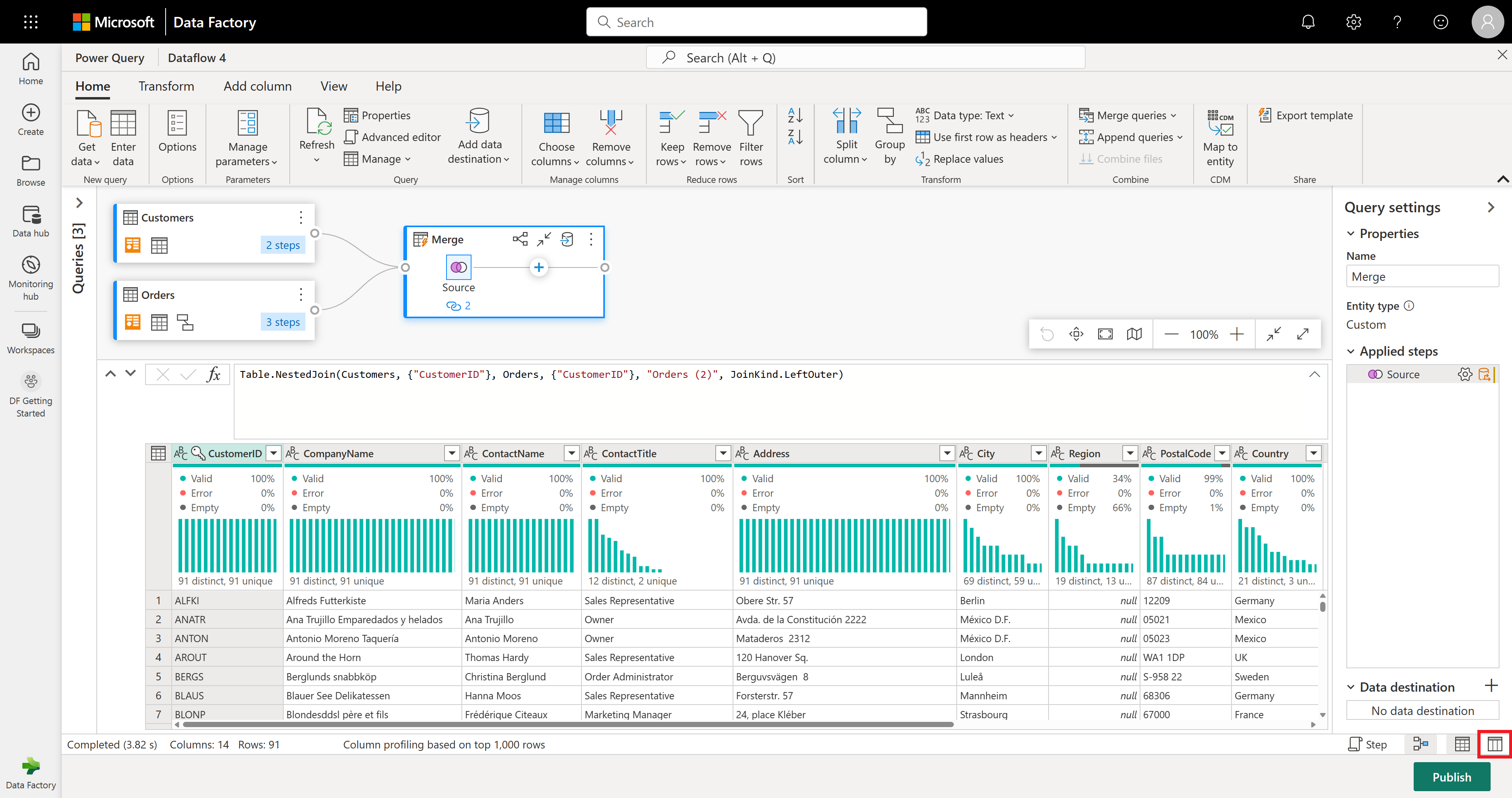
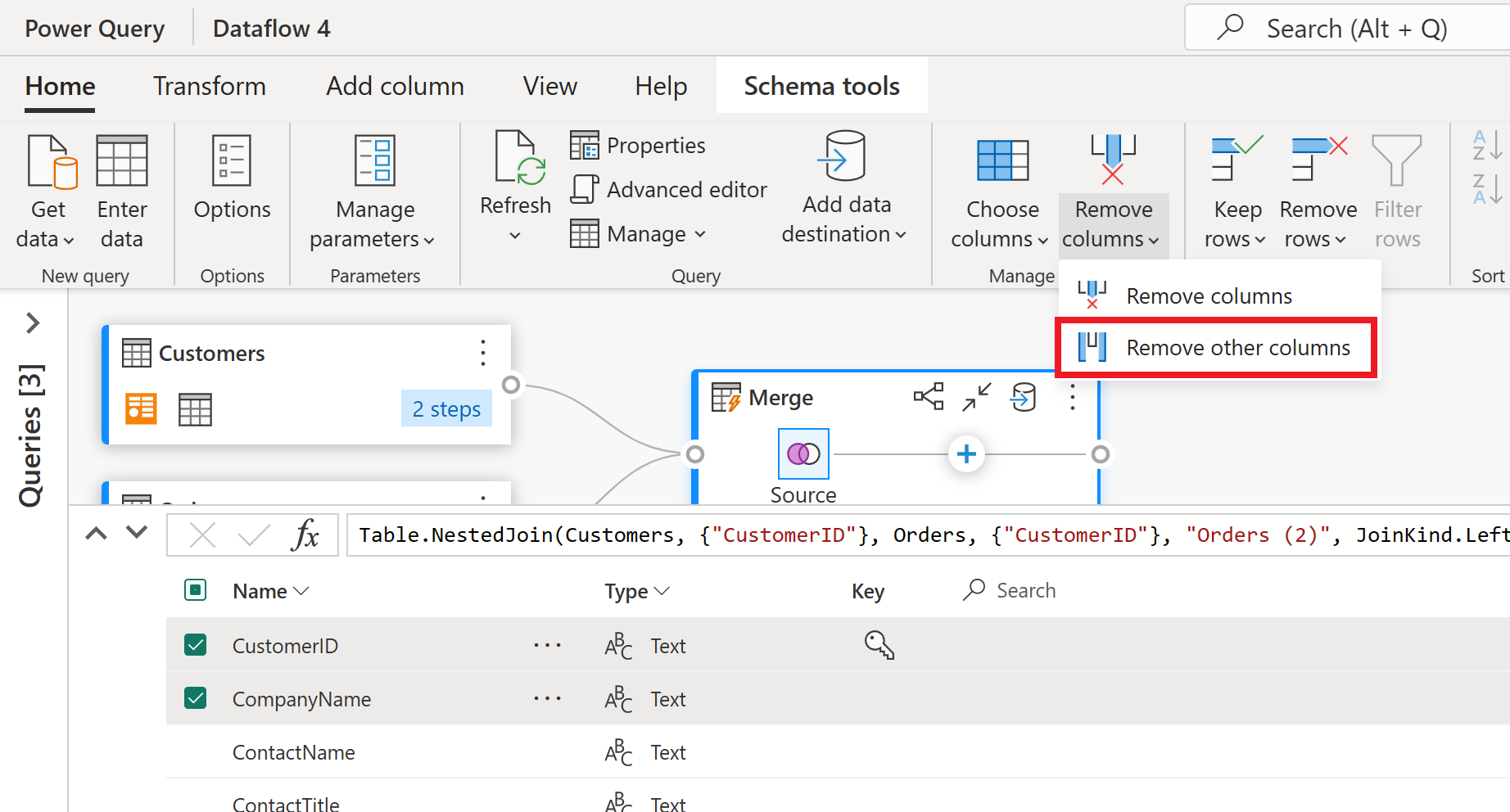
Nella visualizzazione schema verranno visualizzate tutte le colonne della tabella. Selezionare CustomerID, CompanyName e Orders (2). Passare quindi alla scheda Strumenti schema , selezionare Rimuovi colonne e scegliere Rimuovi altre colonne. In questo modo vengono contenute solo le colonne desiderate.
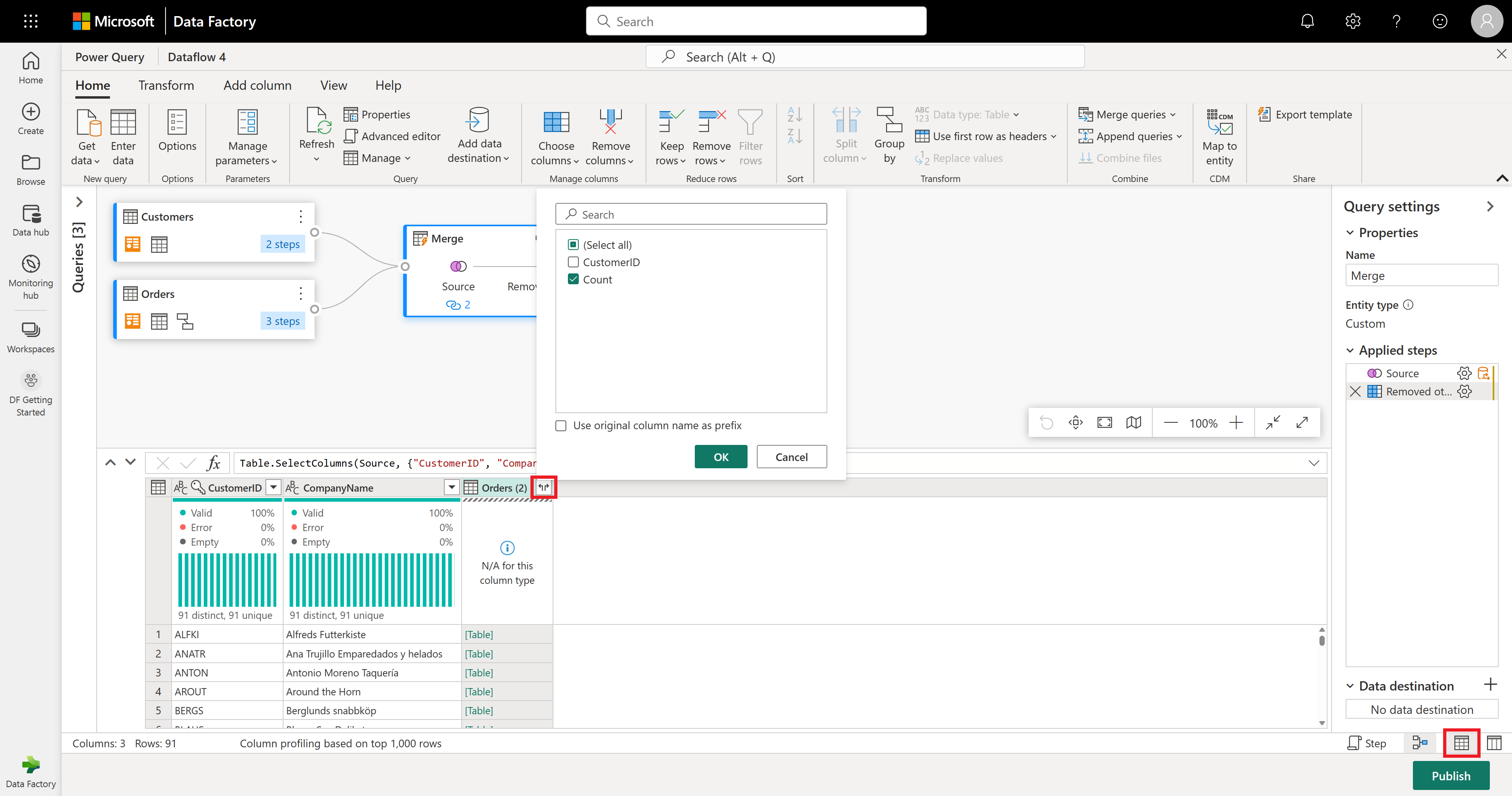
La colonna Orders (2) contiene dettagli aggiuntivi dal passaggio di merge. Per visualizzare e usare questi dati, selezionare il pulsante Mostra visualizzazione dati nell'angolo inferiore destro accanto a Mostra visualizzazione schema. Nell'intestazione di colonna Orders (2) selezionare quindi l'icona Espandi colonna e selezionare la colonna Conteggio . In questo modo viene aggiunto il numero di ordini per ogni cliente alla tabella.
Ora è possibile classificare i clienti in base al numero di ordini effettuati. Selezionare la colonna Conteggio, quindi passare alla scheda Aggiungi colonna e selezionare Colonna classificazione. Verrà aggiunta una nuova colonna che mostra la classificazione di ogni cliente in base al numero di ordini.
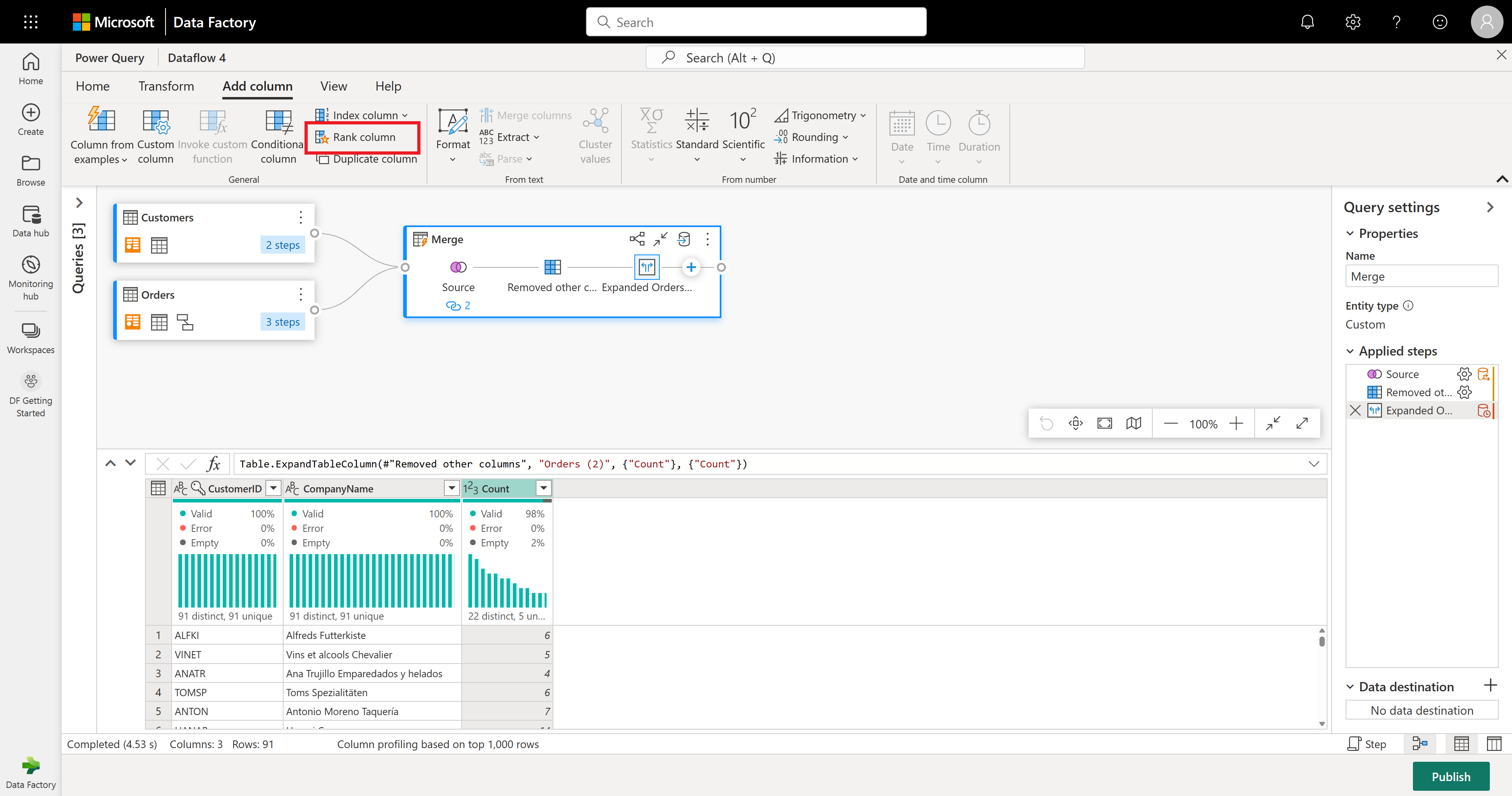
Mantenere le impostazioni predefinite in Colonna di Classifica. Quindi, selezionare OK per applicare questa trasformazione.
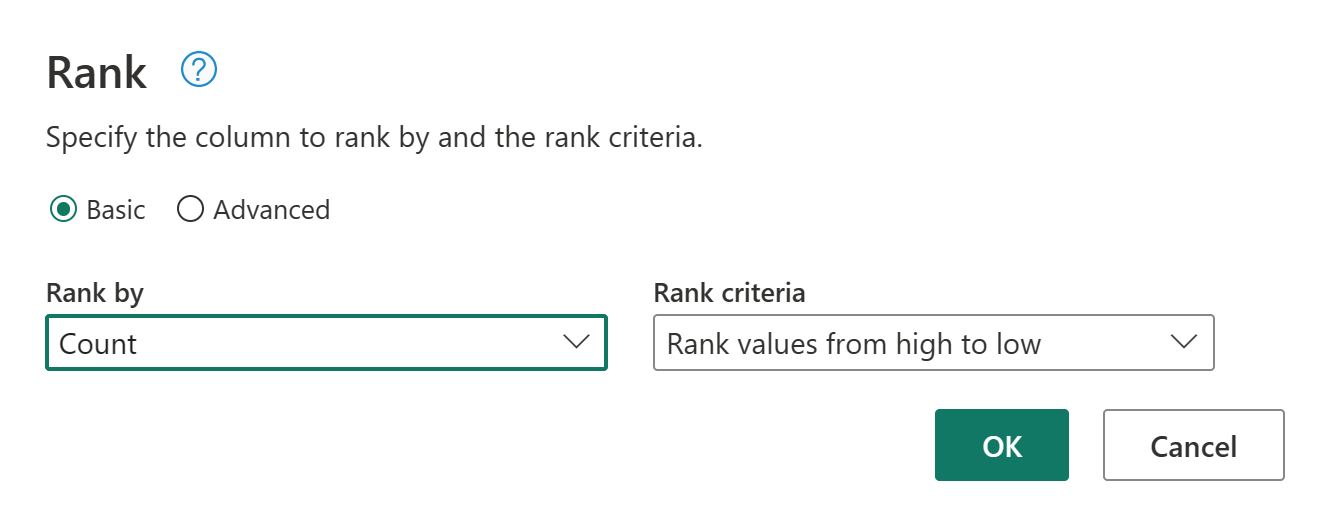
Rinominare ora la query risultante come Clienti classificati usando il riquadro Impostazioni query sul lato destro della schermata.

Sei pronto a definire la destinazione dei tuoi dati. Nel riquadro Impostazioni query scorrere fino alla fine e selezionare Scegli destinazione dati.
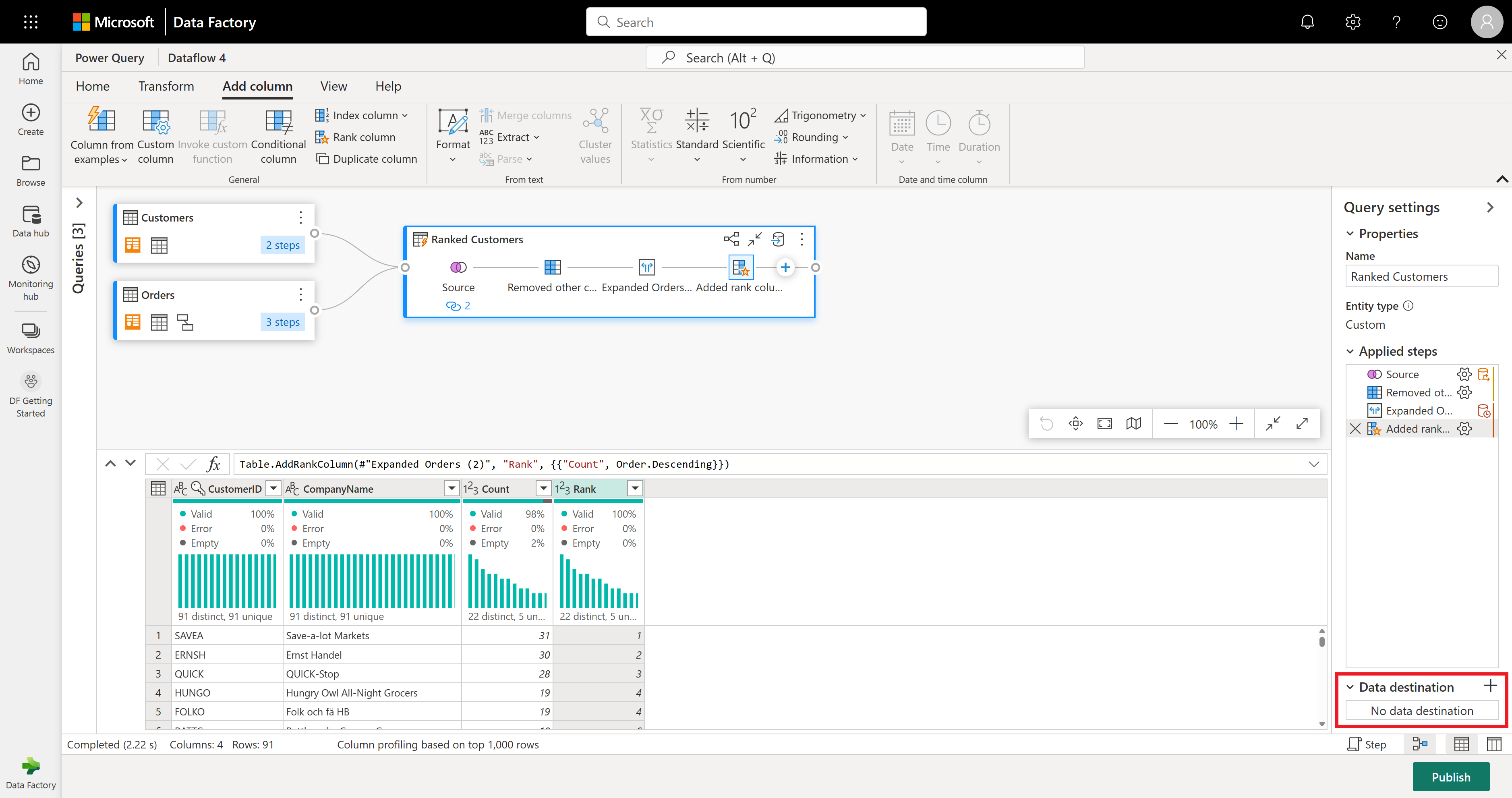
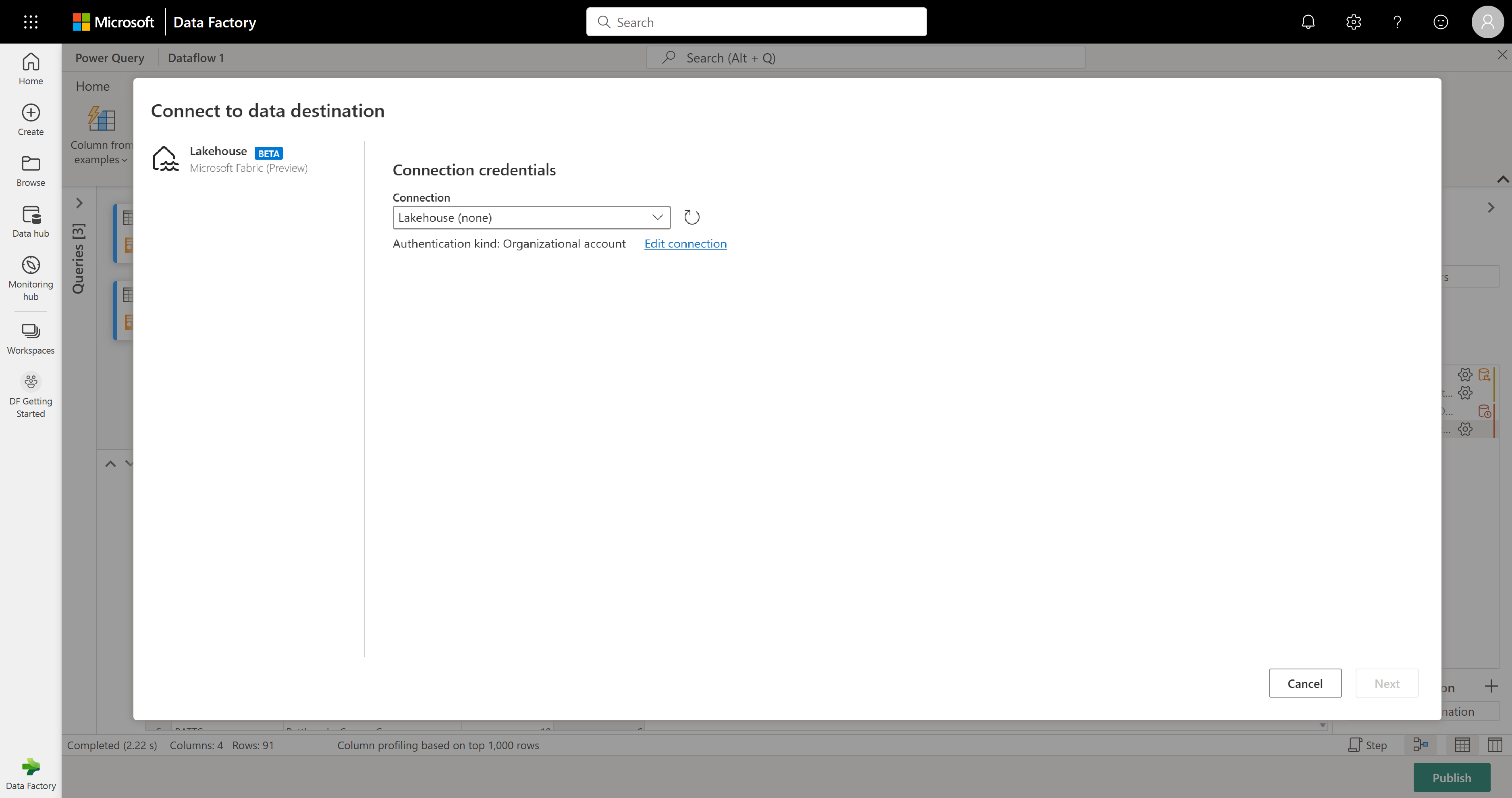
È possibile inviare i risultati a una lakehouse, se ne hai una, o ignorare questo passaggio se non se ne ha una. Qui è possibile selezionare il lakehouse e la tabella da usare per i dati e scegliere se aggiungere nuovi dati (Accoda) o sostituire quello che c'è (Sostituisci).

Il flusso di dati è ora pronto per la pubblicazione. Esaminare le query nella visualizzazione diagramma, quindi selezionare Pubblica.
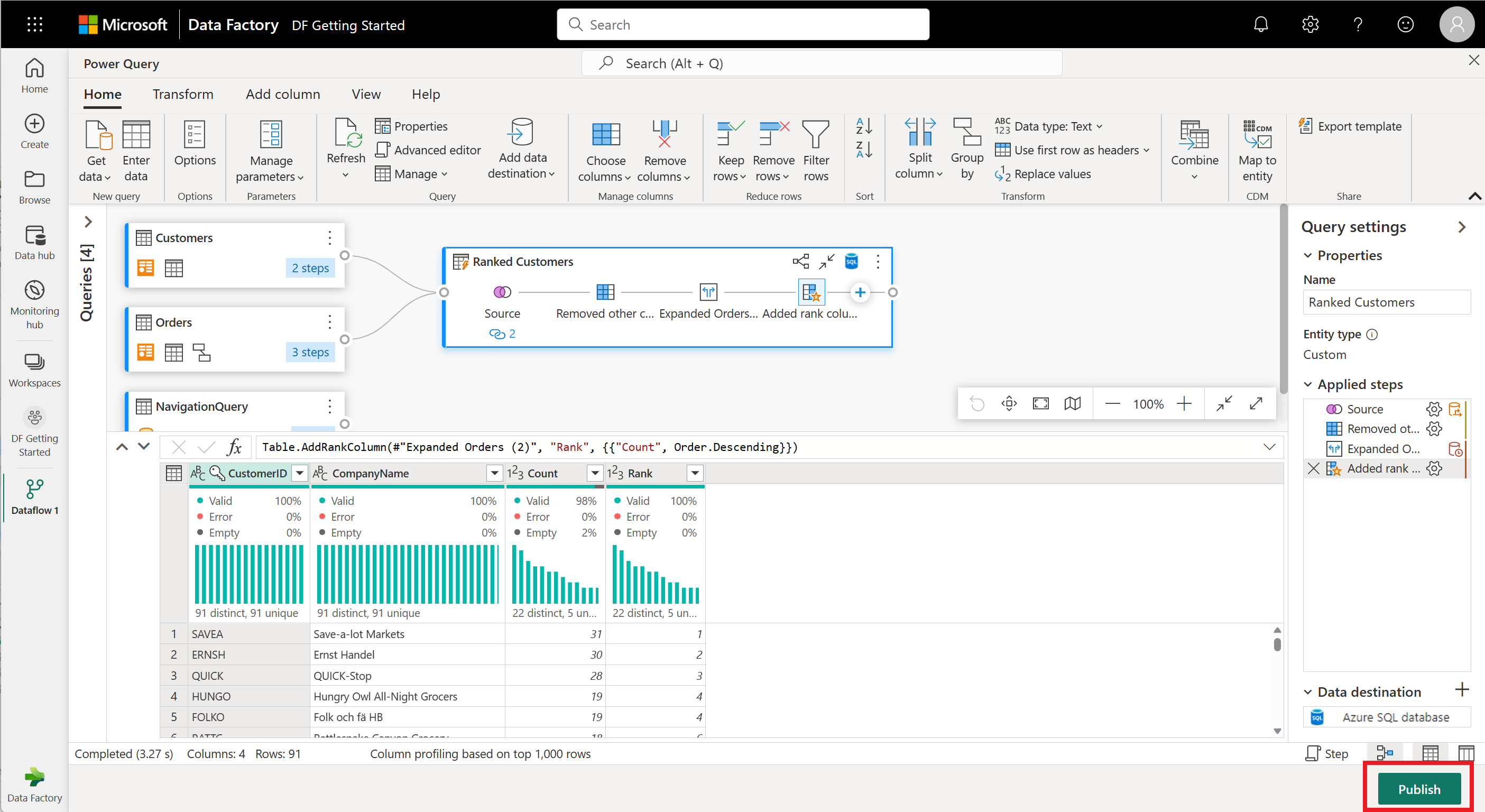
Selezionare Pubblica nell'angolo in basso a destra per salvare il flusso di dati. Tornerai alla tua area di lavoro, dove un'icona di caricamento accanto al nome del flusso di dati indica che è in fase di pubblicazione. Quando la rotazione scompare, il flusso di dati è pronto per l'aggiornamento.
Importante
La prima volta che si crea un dataflow Gen2 in un'area di lavoro, Fabric configura alcuni elementi in background (Lakehouse e Warehouse) che consentono l'esecuzione del flusso di dati. Questi elementi sono condivisi da tutti i flussi di dati nell'area di lavoro e non è consigliabile eliminarli. Non sono destinati a essere usati direttamente e in genere non sono visibili nell'area di lavoro, ma possono essere visualizzati in altre posizioni, ad esempio Notebook o analisi SQL. Cercare i nomi che iniziano con
DataflowStagingper individuarli.Nella propria area di lavoro, selezionare l'icona Pianifica aggiornamento.

Attivare l'aggiornamento pianificato, selezionare Aggiungi un altro orario e configurare l'aggiornamento come illustrato nello screenshot seguente.
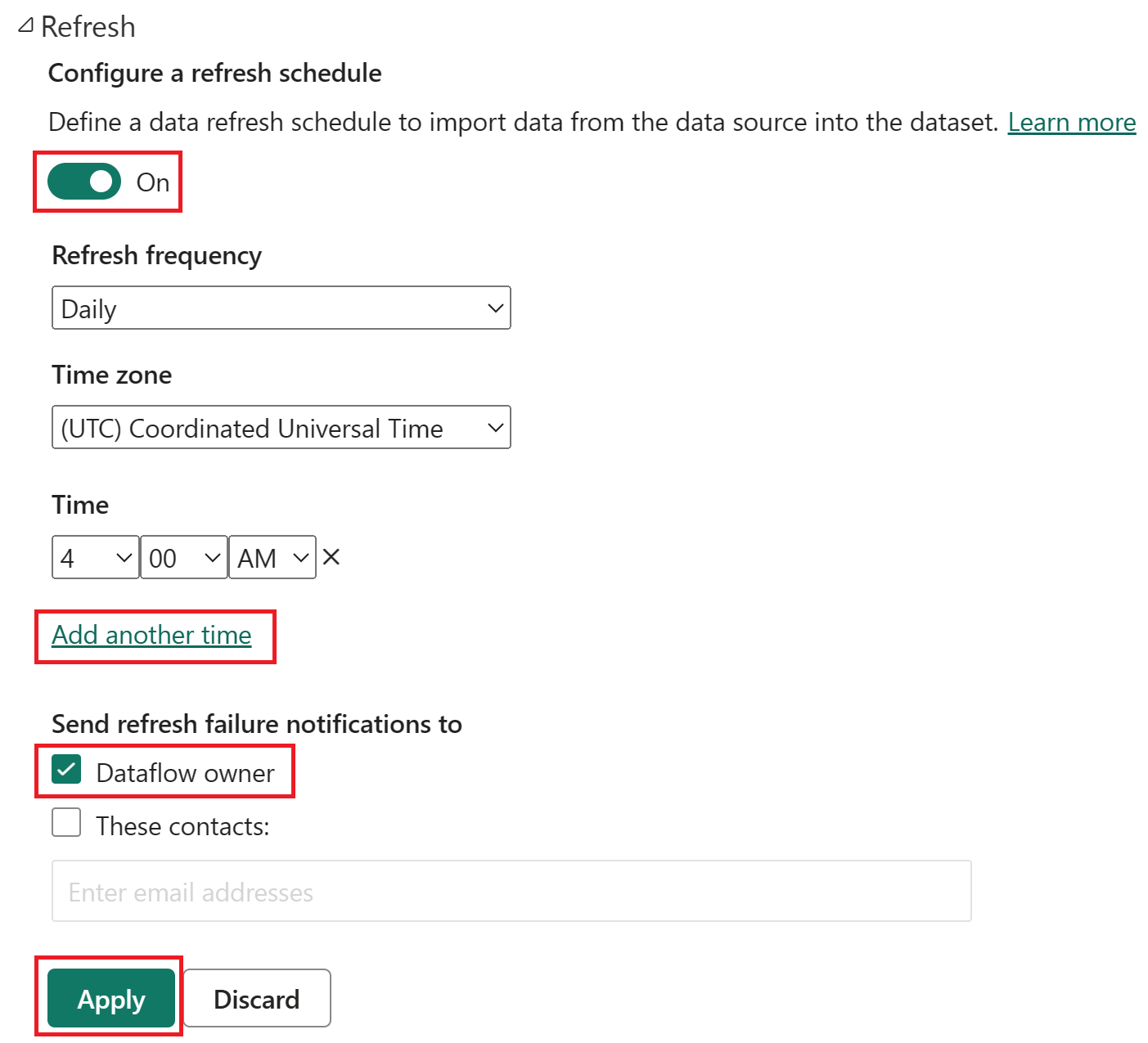
Screenshot delle opzioni di aggiornamento pianificato, con l'aggiornamento pianificato attivato, la frequenza di aggiornamento impostata su Giornaliero, il fuso orario impostato su Tempo Coordinato Universale e l'ora impostata sulle 4:00. Sono evidenziati il pulsante On, la selezione Aggiungi un altro orario, il proprietario del flusso di dati e il pulsante Applica.













Pulire le risorse
Se non si intende continuare a usare questa applicazione, eliminare il flusso di dati seguendo questi passaggi:
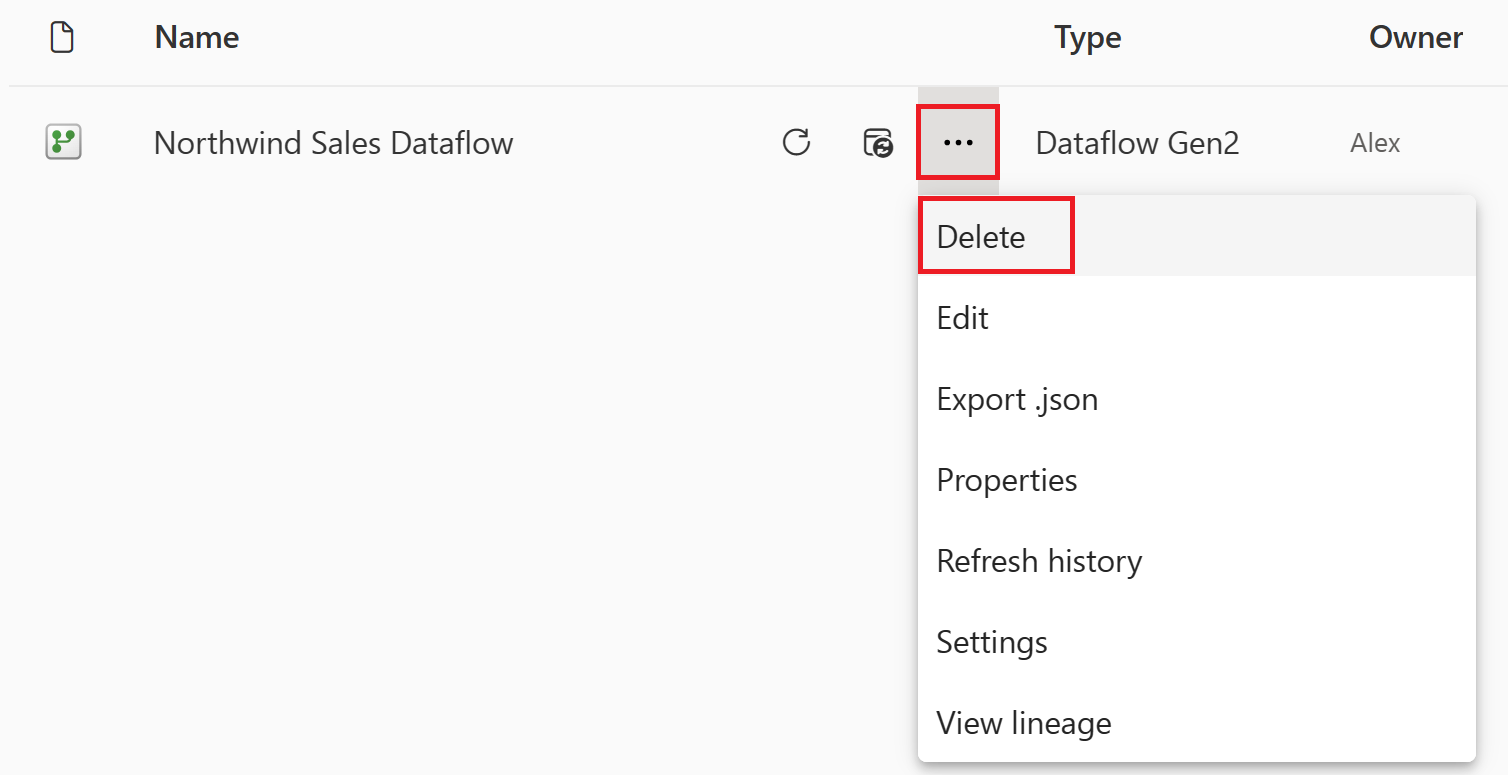
Passare all'area di lavoro Microsoft Fabric.
Selezionare i puntini di sospensione verticali accanto al nome di un flusso di dati, quindi selezionare Elimina.
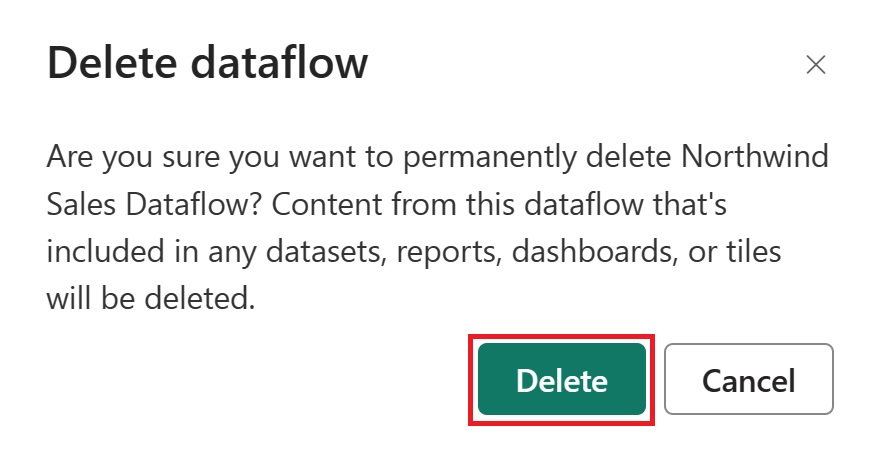
Scegliere Elimina per confermare l'eliminazione del flusso di dati.
Contenuto correlato
Il flusso di dati in questo esempio illustra come caricare e trasformare i dati in Dataflow Gen2. Hai imparato come:
- Creare un Dataflow Gen2.
- Trasforma i dati.
- Configurare le impostazioni di destinazione per i dati trasformati.
- Esegui e pianifica la tua pipeline.
Passare all'articolo successivo per informazioni su come creare la prima pipeline.