Integrare OneLake con Azure HDInsight
Azure HDInsight è un servizio gestito basato sul cloud per l'analisi di Big Data che consente alle organizzazioni di elaborare grandi quantità di dati. Questa esercitazione illustra come connettersi a OneLake con un notebook jupyter da un cluster Azure HDInsight.
Uso di Azure HDInsight
Per connettersi a OneLake con un notebook jupyter da un cluster HDInsight:
Creare un cluster HdInsight (HDI) Apache Spark. Seguire queste istruzioni: Configurare i cluster in HDInsight.
Quando si forniscono informazioni sul cluster, tenere presente il nome utente e la password dell'account di accesso del cluster, perché saranno necessari per accedere al cluster in un secondo momento.
Creare un'identità gestita assegnata dall'utente (UAMI): creare per Azure HDInsight - UAMI e sceglierla come identità nella schermata Archiviazione .
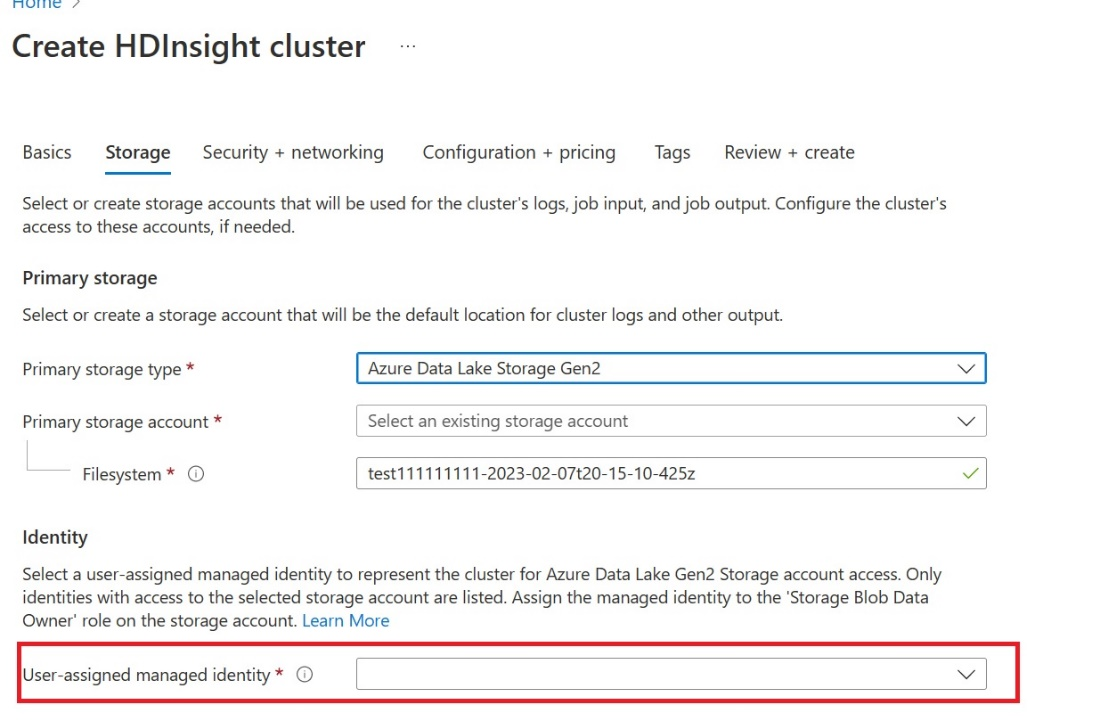
Concedere a questa interfaccia utente l'accesso all'area di lavoro Infrastruttura che contiene gli elementi. Per informazioni sulla scelta del ruolo migliore, vedere Ruoli dell'area di lavoro.
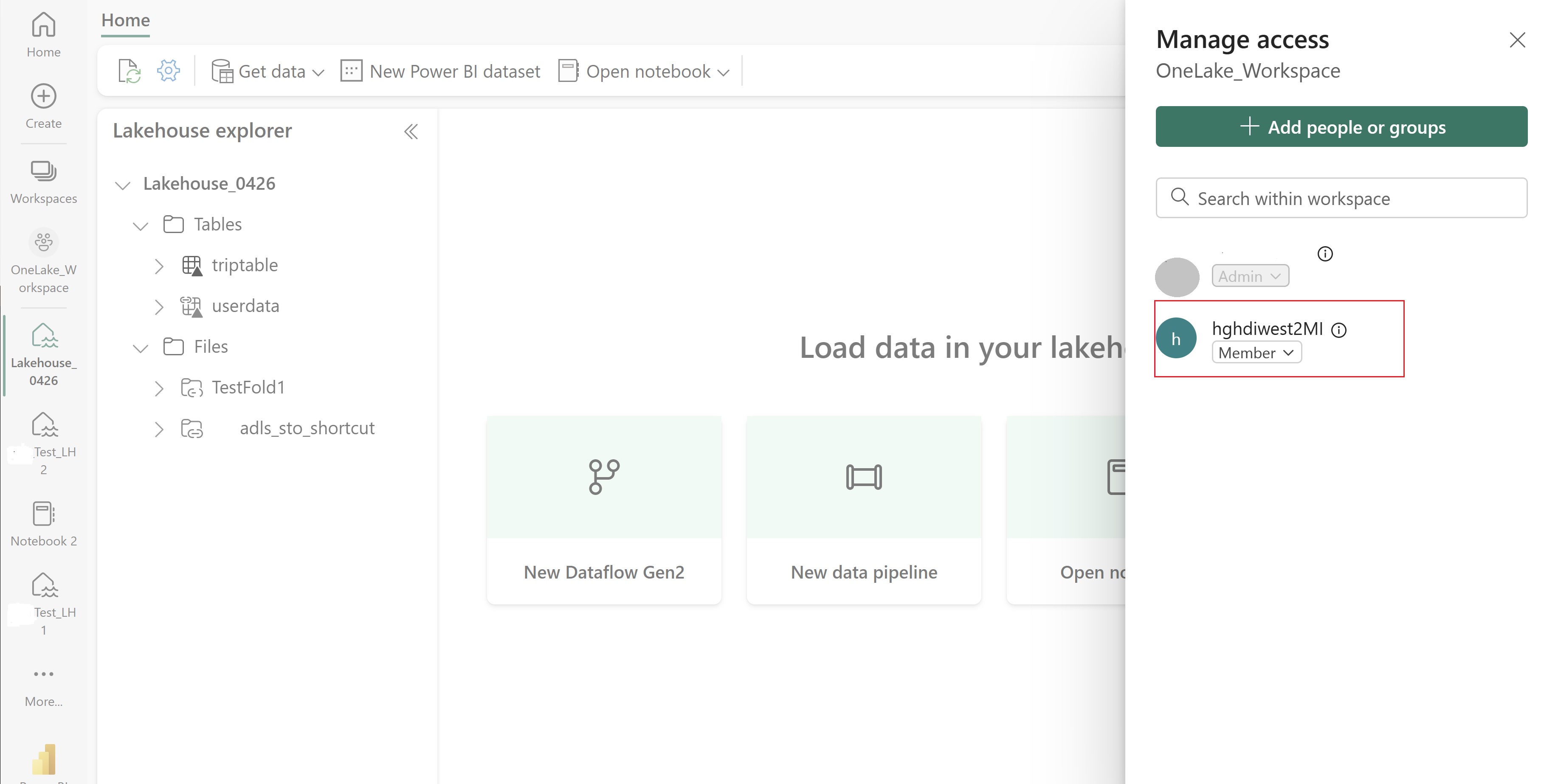
Passare al lakehouse e trovare il nome dell'area di lavoro e del lakehouse. È possibile trovarli nell'URL del lakehouse o nel riquadro Proprietà per un file.
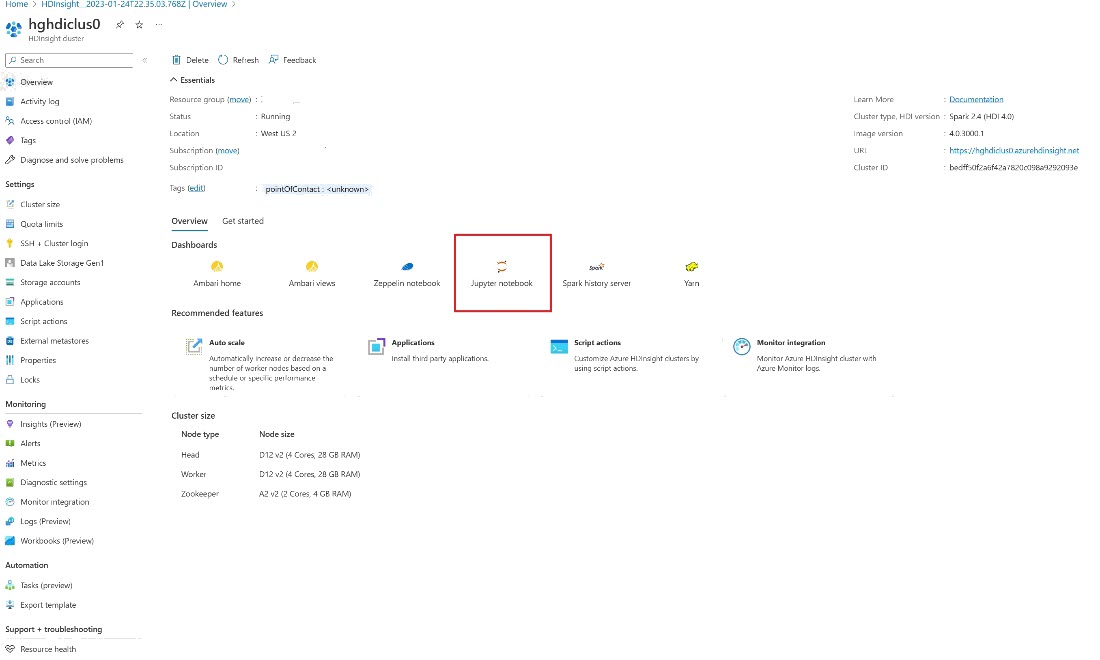
Nella portale di Azure cercare il cluster e selezionare il notebook.
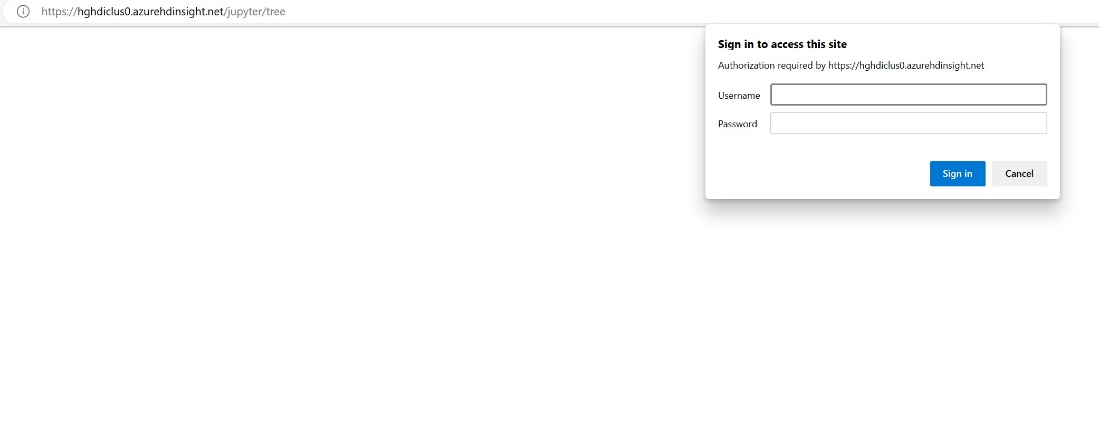
Immettere le informazioni sulle credenziali specificate durante la creazione del cluster.
Creare un nuovo notebook apache Spark.
Copiare i nomi dell'area di lavoro e del lakehouse nel notebook e compilare l'URL di OneLake per il lakehouse. È ora possibile leggere qualsiasi file da questo percorso di file.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Provare a scrivere alcuni dati nel lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Verificare che i dati siano stati scritti correttamente controllando il lakehouse o leggendo il file appena caricato.




È ora possibile leggere e scrivere dati in OneLake usando il notebook jupyter in un cluster HDI Spark.
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per