Configurare i cluster di HDInsight con Apache Hadoop, Apache Spark, Apache Kafka e altro ancora
Informazioni su come configurare e configurare Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query o Apache HBase o in HDInsight. Informazioni su come personalizzare i cluster e proteggerli aggiungendoli a un dominio.
Un cluster Hadoop è costituito da alcune macchine virtuali (nodi) che vengono usate per l'elaborazione distribuita di attività. Azure HDInsight gestisce i dettagli di implementazione dell'installazione e della configurazione dei singoli nodi. È quindi necessario specificare solo le informazioni di configurazione generali.
Importante
La fatturazione del cluster HDInsight inizia dopo la creazione del cluster e si interrompe solo quando questo viene eliminato. La fatturazione avviene con tariffa oraria, perciò si deve sempre eliminare il cluster in uso quando non lo si usa più. Informazioni su come eliminare un cluster
Se si usano più cluster, sarà necessario creare una rete virtuale e, se si usa un cluster Spark, è anche consigliabile usare Hive Warehouse Connector. Per altre informazioni, vedere Pianificare una rete virtuale per Azure HDInsight e Integrare Apache Spark e Apache Hive con Hive Warehouse Connector.
Metodi di installazione del cluster
La tabella seguente illustra i diversi metodi che è possibile usare per configurare un cluster HDInsight.
| Cluster creati con | Web browser | Riga di comando | REST API | SDK |
|---|---|---|---|---|
| Azure portal | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Interfaccia della riga di comando di Azure | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Modelli di Gestione risorse di Azure | ✅ |
Questo articolo illustra la configurazione nel portale di Azure, in cui è possibile creare un cluster HDInsight.
Nozioni di base
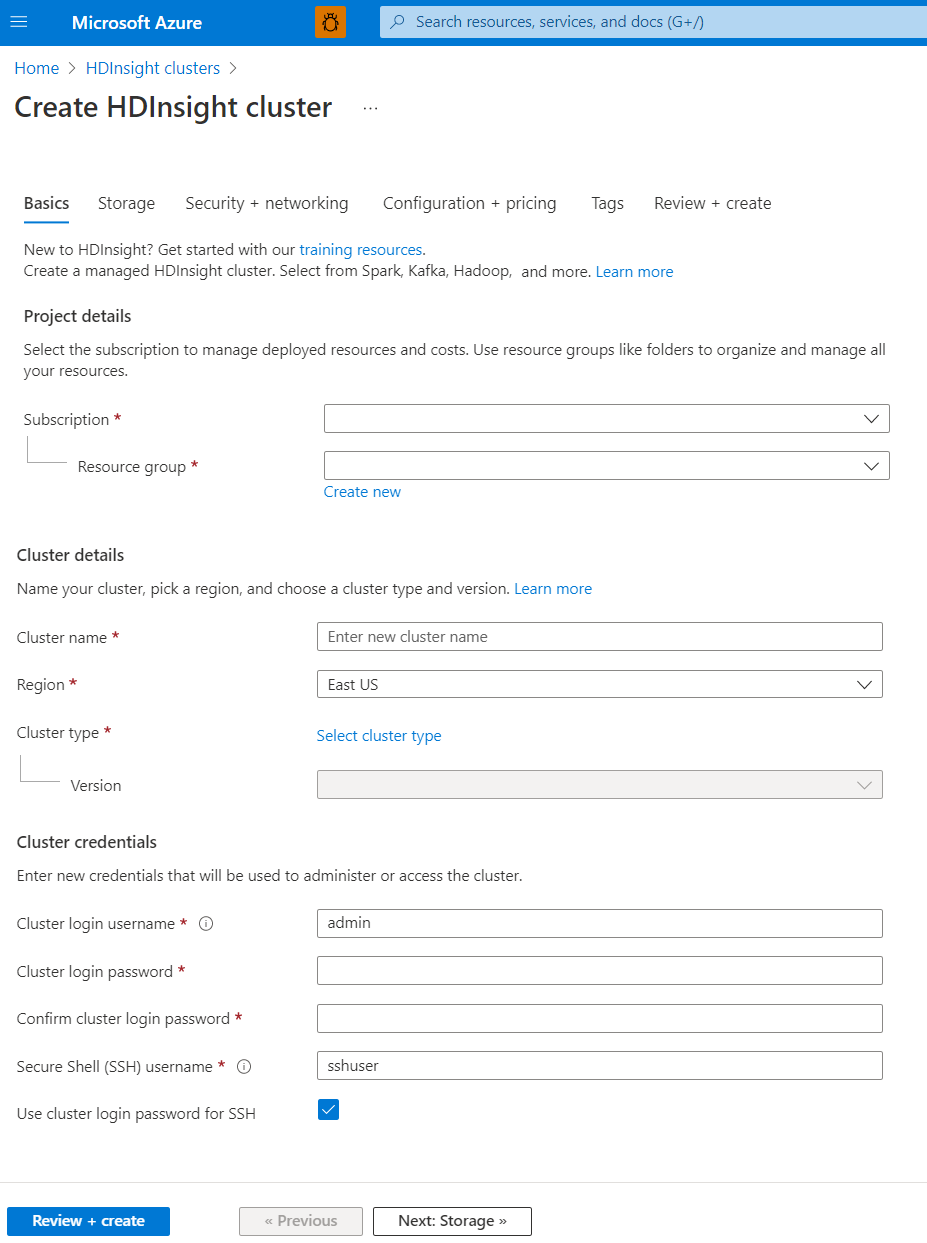
Dettagli di progetto
Azure Resource Manager consente di usare le risorse nell'applicazione come gruppo, detto gruppo di risorse di Azure. È quindi possibile distribuire, aggiornare, monitorare o eliminare tutte le risorse per l'applicazione in un'unica operazione coordinata.
Dettagli del cluster
Nome cluster
I nomi dei cluster HDInsight presentano le restrizioni seguenti:
- Caratteri consentiti: a-z, 0-9, A-Z
- Lunghezza massima: 59
- Nomi riservati: apps
- L'ambito del nome del cluster comprende tutto Azure, in tutte le sottoscrizioni. Il nome del cluster deve quindi essere univoco in tutto il mondo.
- I primi sei caratteri devono essere univoci all'interno di una rete virtuale
Paese
Non è necessario specificare il percorso del cluster in modo esplicito: il cluster si trova nella stessa posizione delle risorse di archiviazione predefinite. Per un elenco delle aree supportate, selezionare l'elenco a discesa Area nei prezzi di HDInsight.
Tipo di cluster
In Azure HDInsight sono attualmente disponibili i tipi di cluster seguenti, ognuno con un set di componenti per offrire determinate funzionalità.
Importante
I cluster HDInsight sono disponibili i vari tipi, ognuno per un carico di lavoro o una tecnologia specifici. Non esiste alcun metodo supportato per creare un cluster che combina più tipi, ad esempio HBase in un cluster. Se la soluzione richiede tecnologie che vengono distribuite tra più tipi di cluster HDInsight, una rete virtuale di Azure è in grado di connettere i tipi di cluster necessari.
| Tipo di cluster | Funzionalità |
|---|---|
| Hadoop | Query batch e analisi dei dati archiviati |
| HBase | Elaborazione di grandi quantità di dati NoSQL senza schema |
| Interactive Query | Caching in memoria per query Hive interattive e più rapide |
| Kafka | Piattaforma di streaming open source distribuita che può essere usata per compilare applicazioni e pipeline di dati in streaming in tempo reale. |
| Spark | Elaborazione in memoria, query interattive, elaborazione di flussi di micro batch |
Versione
Scegliere la versione di HDInsight per questo cluster. Per altre informazioni, vedere Versioni supportate di HDInsight.
Credenziali del cluster
Con i cluster HDInsight è possibile configurare due account utente durante la creazione del cluster:
- Nome utente dell'account di accesso del cluster: il nome utente predefinito è admin. Usa la configurazione di base nel portale di Azure. A volte si chiama "Utente cluster" o "utente HTTP".
- Nome utente Secure Shell (SSH): usato per connettersi al cluster tramite SSH. Per altre informazioni, vedere l'articolo su come usare SSH con HDInsight.
Il nome utente HTTP presenta le restrizioni seguenti:
- Caratteri speciali consentiti:
_e@ - Caratteri non consentiti:
#;."',/:!*?$()[]{}<>|&--=+%~^space' - Lunghezza massima: 20
Il nome utente SSH presenta le restrizioni seguenti:
- Caratteri speciali consentiti:
_e@ - Caratteri non consentiti:
#;."',/:!*?$()[]{}<>|&--=+%~^space' - Lunghezza massima: 64
- Nomi riservati: hadoop, utenti, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a, adm
actuser, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Storage
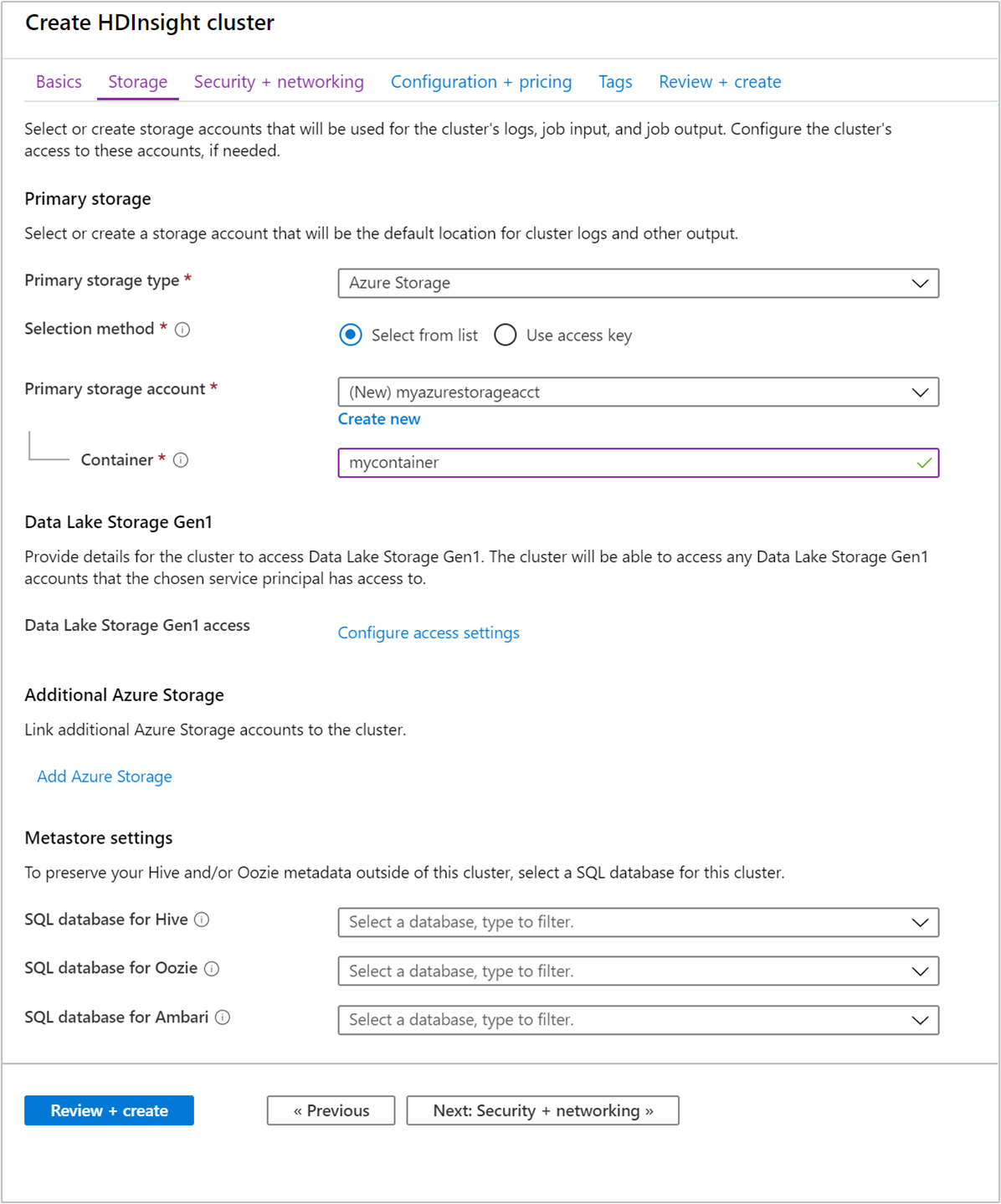
Sebbene l'installazione locale di Hadoop usi Hadoop Distributed File System (HDFS) per l'archiviazione nel cluster, nel cloud vengono usati degli endpoint di archiviazione connessi al cluster. L'uso dell'archiviazione cloud consente di eliminare in modo sicuro i cluster HDInsight usati per il calcolo mantenendo comunque i dati.
I cluster HDInsight possono usare le opzioni di archiviazione seguenti:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Archiviazione di Azure utilizzo generico v2
- Archiviazione di Azure utilizzo generico v1
- Archiviazione di Azure BLOB in blocchi (supportato solo come risorsa di archiviazione secondaria)
Per altre informazioni sulle opzioni di archiviazione con HDInsight, vedere Confrontare le opzioni di archiviazione per l'uso con i cluster Azure HDInsight.
Avviso
L'uso di un account di archiviazione aggiuntivo in una località diversa rispetto al cluster HDInsight non è supportato.
Durante la configurazione, per l'endpoint di archiviazione predefinito si specifica un contenitore BLOB di un account di archiviazione di Azure o Data Lake Storage. L'archiviazione predefinita include log di sistema e applicazioni. Facoltativamente, è possibile specificare degli account di archiviazione di Azure aggiuntivi e degli account di Data Lake Storage a cui il cluster può accedere. Il cluster HDInsight e l'account di archiviazione da esso dipendente devono trovarsi nella stessa posizione di Azure.
Nota
La funzionalità che richiede il trasferimento sicuro trasmette tutte le richieste all'account dell'utente tramite una connessione sicura. Questa funzionalità è supportata solo dal cluster HDInsight versione 3.6 o successiva. Per altre informazioni, vedere Creare un cluster Apache Hadoop con account di archiviazione con trasferimento sicuro in Azure HDInsight.
Importante
L'abilitazione del trasferimento di archiviazione sicura dopo la creazione di un cluster può causare errori usando l'account di archiviazione e non è consigliabile. È preferibile creare un nuovo cluster usando un account di archiviazione con trasferimento sicuro già abilitato.
Nota
Azure HDInsight non trasferisce, sposta o copia automaticamente i dati archiviati in Archiviazione di Azure da un'area a un'altra.
Impostazioni metastore
È possibile creare dei metastore Hive o Apache Oozie facoltativi. Tuttavia, non tutti i tipi di cluster supportano i metastore e Azure Synapse Analytics non è compatibile con i metastore.
Per altre informazioni, vedere Use external metadata stores in Azure HDInsight (Usare archivi di metadati esterni in Azure HDInsight).
Importante
Quando si crea un metastore personalizzato, non usare un nome di database contenente trattini, segni meno o spazi. perché in quel caso il processo di creazione del cluster non andrebbe a buon fine.
Database SQL per Hive
Per conservare le tabelle Hive dopo aver eliminato il cluster HDInsight, usare un metastore personalizzato. Sarà quindi possibile associare il metastore a un altro cluster HDInsight.
Un metastore HDInsight creato per una versione del cluster HDInsight non può essere condiviso tra versioni diverse del cluster HDInsight. Per un elenco di versioni di HDInsight, vedere Versioni supportate di HDInsight.
Importante
Il metastore predefinito fornisce un database SQL di Azure con un limite DTU di livello base 5 (non aggiornabile)! Adatto a scopi di test di base. Per carichi di lavoro di grandi dimensioni o di produzione, è consigliabile eseguire la migrazione a un metastore esterno.
Database SQL per Oozie
Per ottenere un miglioramento delle prestazioni quando si usa Oozie, usare un metastore personalizzato. Un metastore può anche fornire l'accesso ai dati di processo Oozie dopo l'eliminazione del cluster.
Database SQL per Ambari
Ambari viene usato per monitorare i cluster HDInsight, apportare modifiche alla configurazione e archiviare le informazioni di gestione del cluster e la cronologia dei processi. La funzionalità personalizzata del database Ambari consente di distribuire un nuovo cluster e configurare Ambari in un database esterno gestito. Per altre informazioni, vedere Database Ambari personalizzato.
Importante
Non è possibile riutilizzare un metastore Oozie personalizzato. Per usare un metastore Oozie personalizzato, è necessario specificare un database SQL di Azure vuoto al momento della creazione del cluster HDInsight.
Sicurezza e rete
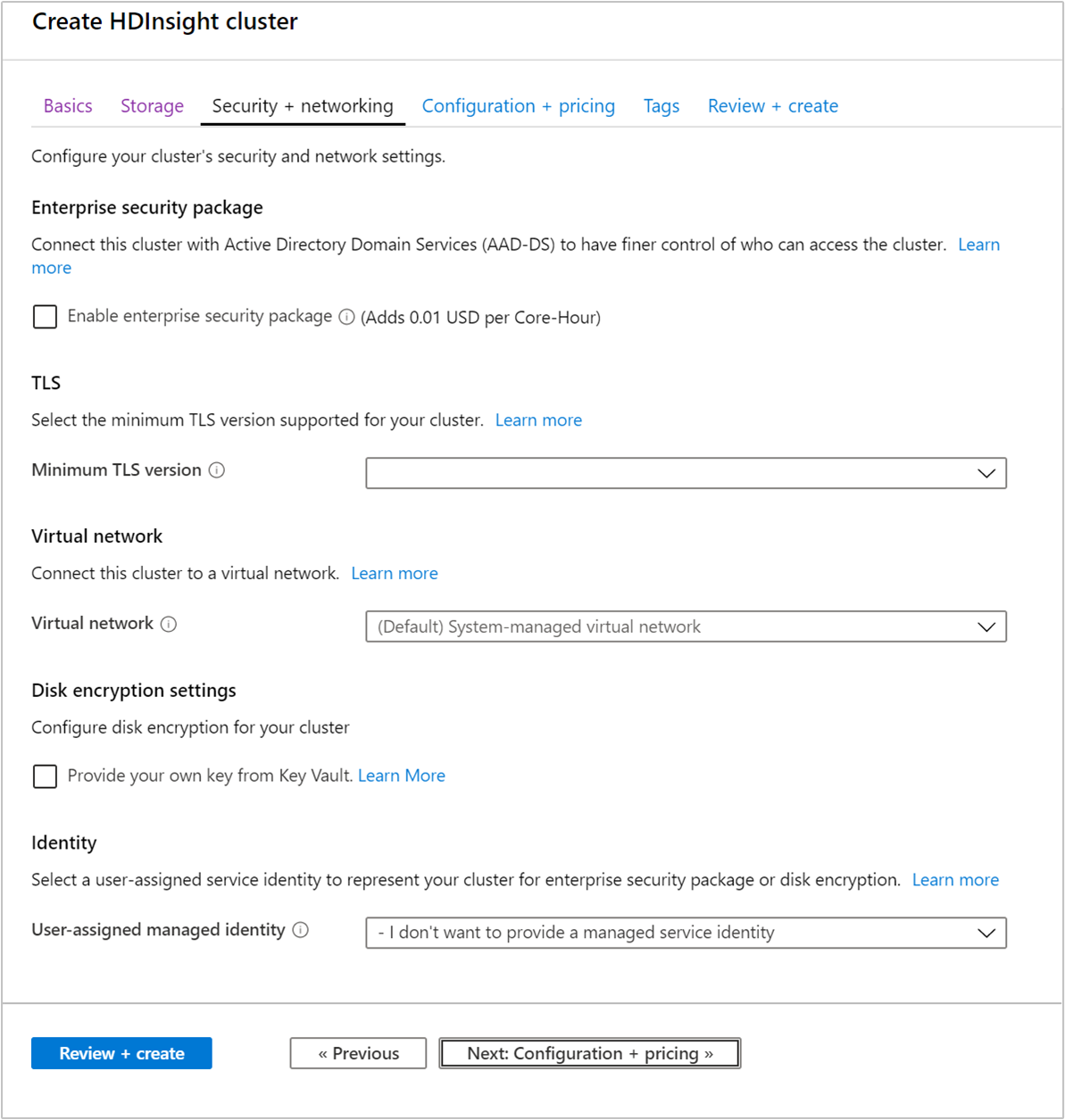
Enterprise Security Package
Per i tipi di cluster Hadoop, Spark, HBase, Kafka e Interactive Query, è possibile scegliere di abilitare Enterprise Security Package. Questo pacchetto offre la possibilità di configurare un cluster più sicuro usando Apache Ranger e l'integrazione con Microsoft Entra ID. Per altre informazioni, vedere Panoramica della sicurezza aziendale in Azure HDInsight.
Il Pacchetto di sicurezza aziendale consente di integrare HDInsight con Active Directory e Apache Ranger. È possibile creare più utenti usando il Pacchetto di sicurezza aziendale.
Per altre informazioni sulla creazione di un cluster HDInsight aggiunto al dominio, vedere Create domain-joined HDInsight sandbox environment (Creare un ambiente sandbox HDInsight aggiunto al dominio).
TLS
Per altre informazioni, vedere Transport Layer Security
Rete virtuale
Se la soluzione richiede tecnologie che vengono distribuite tra più tipi di cluster HDInsight, una rete virtuale di Azure è in grado di connettere i tipi di cluster necessari. Questa configurazione consente ai cluster e al codice in essi distribuito di comunicare direttamente tra loro.
Per altre informazioni sull'uso di una rete virtuale di Azure con HDInsight, vedere Pianificare una rete virtuale per HDInsight.
Per un esempio dell'uso di due tipi di cluster in una rete virtuale di Azure, vedere Usare lo streaming strutturato Apache Spark con Apache Kafka. Per altre informazioni sull'uso di HDInsight con una rete virtuale, inclusi requisiti di configurazione specifici per la rete virtuale, vedere Pianificare una rete virtuale per HDInsight.
Impostazione di crittografia del disco
Per altre informazioni, vedere Crittografia dischi con chiavi gestite dal cliente.
Proxy REST Kafka
Questa impostazione è disponibile solo per il tipo di cluster Kafka. Per altre informazioni, vedere Uso di un proxy REST.
Identità
Per altre informazioni, vedere Identità gestite in Azure HDInsight.
Configurazione e prezzi
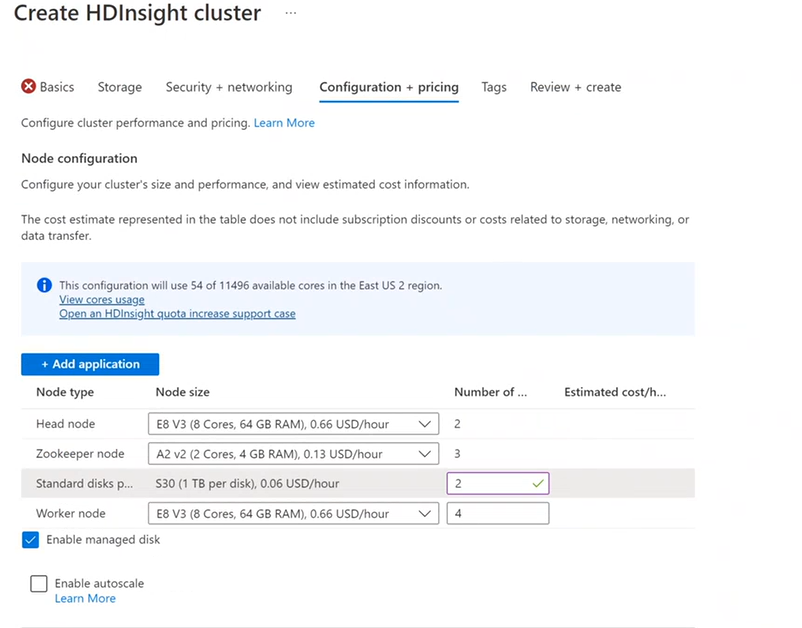
Viene addebitato l'utilizzo del nodo a condizione che il cluster esista. La fatturazione inizia con la creazione del cluster e si interrompe quando il cluster viene eliminato. I cluster non possono essere allocati o messi in attesa.
Configurazione nodi
Ogni tipo di cluster ha il proprio numero di nodi, una terminologia specifica per i nodi e dimensioni predefinite delle macchine virtuali. Nella tabella seguente, il numero di nodi per ogni tipo di nodo è indicato tra parentesi.
| Type | Nodi | Diagramma |
|---|---|---|
| Hadoop | Nodo head (2), nodo di lavoro (1+) | 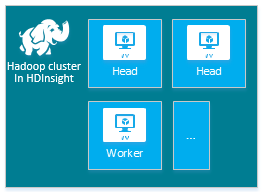
|
| HBase | Server head (2), server di area (1+), nodo master/ZooKeeper (3) | 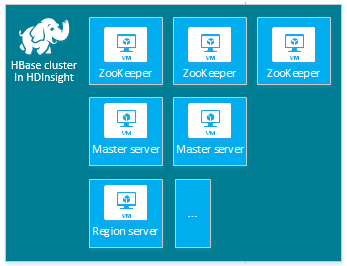
|
| Spark | Nodo head (2), nodo del ruolo di lavoro (1+), nodo ZooKeeper (3) (gratuito per le dimensioni della macchina virtuale ZooKeeper A1) | 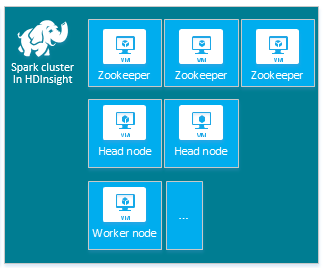
|
Per altre informazioni, vedere Configurazione del nodo predefinito e dimensioni della macchina virtuale per i cluster in "Componenti e versioni di Hadoop in HDInsight"
Il costo del cluster HDInsight è determinato dal numero di nodi e dalle dimensioni delle macchine virtuali per i nodi.
Diversi tipi di cluster hanno diversi tipi, numeri e dimensioni di nodi:
- Tipo di cluster Hadoop predefinito:
Due nodi head
Quattro nodi di lavoro
Se si sta solo provando HDInsight, è consigliabile usare un nodo di lavoro. Per altre informazioni sui prezzi di HDInsight, vedere Prezzi di HDInsight.
Nota
Il limite relativo alle dimensioni del cluster dipende dalla sottoscrizione di Azure. Per aumentare il limite, contattare il team del supporto fatturazione di Azure.
Quando si usa il portale di Azure per configurare il cluster, le dimensioni del nodo sono disponibili tramite la scheda Configurazione e prezzi. Nel portale è anche possibile visualizzare il costo associato alle diverse dimensioni dei nodi.
Dimensioni delle macchine virtuali
Quando si distribuiscono i cluster, scegliere le risorse di calcolo in base alla soluzione da distribuire. Per i cluster HDInsight vengono usate le macchine virtuali seguenti:
- Macchine virtuali serie A e D1-4: Dimensioni delle macchine virtuali Linux per l'uso generico
- Macchine virtuali serie D11-14: Dimensioni ottimizzate per la memoria delle macchine virtuali Linux
Per scoprire quale valore usare per specificare le dimensioni di macchina virtuale durante la creazione di un cluster tramite SDK diversi o quando si usa Azure PowerShell, vedere VM sizes to use for HDInsight clusters (Dimensioni delle macchine virtuali da usare per i cluster HDInsight). In questo articolo collegato, usare il valore della casella Dimensioni delle tabelle.
Importante
Se in un cluster sono necessari più di 32 nodi di lavoro, è necessario selezionare una dimensione del nodo head con almeno 8 core e 14 GB di RAM.
Per ulteriori informazioni, vedere Dimensioni delle macchine virtuali in Azure. Per informazioni sui prezzi delle varie dimensioni, vedere Prezzi di HDInsight.
Allegato del disco
Nota
I dischi aggiunti sono configurati solo per le directory locali di Gestione nodi e non per le directory del nodo dati
Il cluster HDInsight include spazio su disco predefinito basato sullo SKU. Se si eseguono alcune applicazioni di grandi dimensioni, è possibile che lo spazio su disco non sia sufficiente, con errore LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE completo del disco e errori del processo.
È possibile aggiungere altri dischi al cluster usando la nuova directory locale di NodeManager. Al momento della creazione del cluster Hive e Spark, è possibile selezionare e aggiungere il numero di dischi ai nodi di lavoro. Il disco selezionato, di dimensioni pari a 1 TB, farà parte delle directory locali di NodeManager.
- Dalla scheda Configurazione e prezzi
- Selezionare l'opzione Abilita disco gestito
- Da dischi Standard immettere il numero di dischi
- Scegliere il nodo del ruolo di lavoro
È possibile verificare il numero di dischi dalla scheda Rivedi e crea , in Configurazione cluster
Aggiunta di un'applicazione
L'applicazione HDInsight è un'applicazione che gli utenti possono installare in un cluster HDInsight basato su Linux. È possibile usare applicazioni fornite da Microsoft, terze parti o sviluppate dall'utente. Per altre informazioni, vedere Installare applicazioni Apache Hadoop di terze parti in Azure HDInsight.
La maggior parte delle applicazioni HDInsight viene installata in un nodo perimetrale vuoto. Un nodo perimetrale vuoto è una macchina virtuale Linux in cui sono installati e configurati gli stessi strumenti client del nodo head. Il nodo perimetrale può essere usato per accedere al cluster e per testare e ospitare le applicazioni client. Per altre informazioni, vedere Usare nodi perimetrali vuoti in HDInsight.
Azioni script
L'uso di script durante la creazione consente di installare componenti aggiuntivi o personalizzare la configurazione di un cluster. Gli script vengono chiamati tramite un' azione script, ovvero un'opzione di configurazione che può essere usata da portale di Azure, dai cmdlet di Windows PowerShell per HDInsight o da .NET SDK per HDInsight. Per altre informazioni, vedere Personalizzare cluster HDInsight mediante le azioni script.
Nel cluster è possibile eseguire alcuni componenti Java nativi, come Apache Mahout e Cascading, sotto forma di file JAR (Java Archive). Questi file JAR possono essere distribuiti in Archiviazione di Azure e inviati ai cluster HDInsight usando i meccanismi di invio dei processi Hadoop. Per altre informazioni, vedere Inviare processi Apache Hadoop a livello di codice.
Nota
In caso di problemi durante la distribuzione di file JAR in cluster HDInsight o nella chiamata di file JAR in cluster HDInsight, contattare il Supporto Microsoft.
Cascading non è supportato da HDInsight, quindi in caso di problemi non è possibile rivolgersi al Supporto Microsoft. Per gli elenchi dei componenti supportati, vedere Novità delle versioni cluster incluse con HDInsight.
In alcuni casi è opportuno configurare i file di configurazione seguenti durante il processo di creazione:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Per altre informazioni, vedere Personalizzare cluster HDInsight tramite Bootstrap.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per