Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le scorciatoie in Microsoft OneLake unificano i tuoi dati tra domini, cloud e account, trasformando OneLake nel singolo lago di dati virtuale per l'intera azienda. Esperienze Fabric e motori analitici possono connettersi alle origini dati esistenti, tra cui Azure, Amazon Web Services (AWS) e OneLake tramite uno spazio dei nomi comune. OneLake gestisce tutte le autorizzazioni e le credenziali, pertanto non è necessario configurare separatamente ogni carico di lavoro Fabric per connettersi a ogni origine dati. Inoltre, è possibile usare le scorciatoie per eliminare le copie marginali dei dati e ridurre la latenza dei processi associati alle copie dei dati e alla preparazione.
Che cosa sono le scorciatoie?
Le scorciatoie sono oggetti in OneLake che puntano ad altre posizioni di archiviazione. La posizione può essere interna o esterna a OneLake. La posizione a cui punta un collegamento è il percorso di destinazione del collegamento. Il percorso in cui viene visualizzato il collegamento è il percorso di scelta rapida.
Le scorciatoie vengono visualizzate come cartelle in OneLake e qualsiasi carico di lavoro o servizio che ha accesso a OneLake può usarle. Le scorciatoie si comportano come collegamenti simbolici. Sono un oggetto indipendente dalla destinazione. Se elimini una scorciatoia, la destinazione rimane invariata. Se si sposta, si rinomina o si elimina un percorso di destinazione, il collegamento può interrompersi.

Dove è possibile creare scorciatoie?
È possibile creare collegamenti nei lakehouse e nei database di Kusto Query Language (KQL).
È possibile usare il portale di Fabric per creare collegamenti in modo interattivo ed è possibile usare l'API REST per creare collegamenti a livello di codice.
Lakehouse
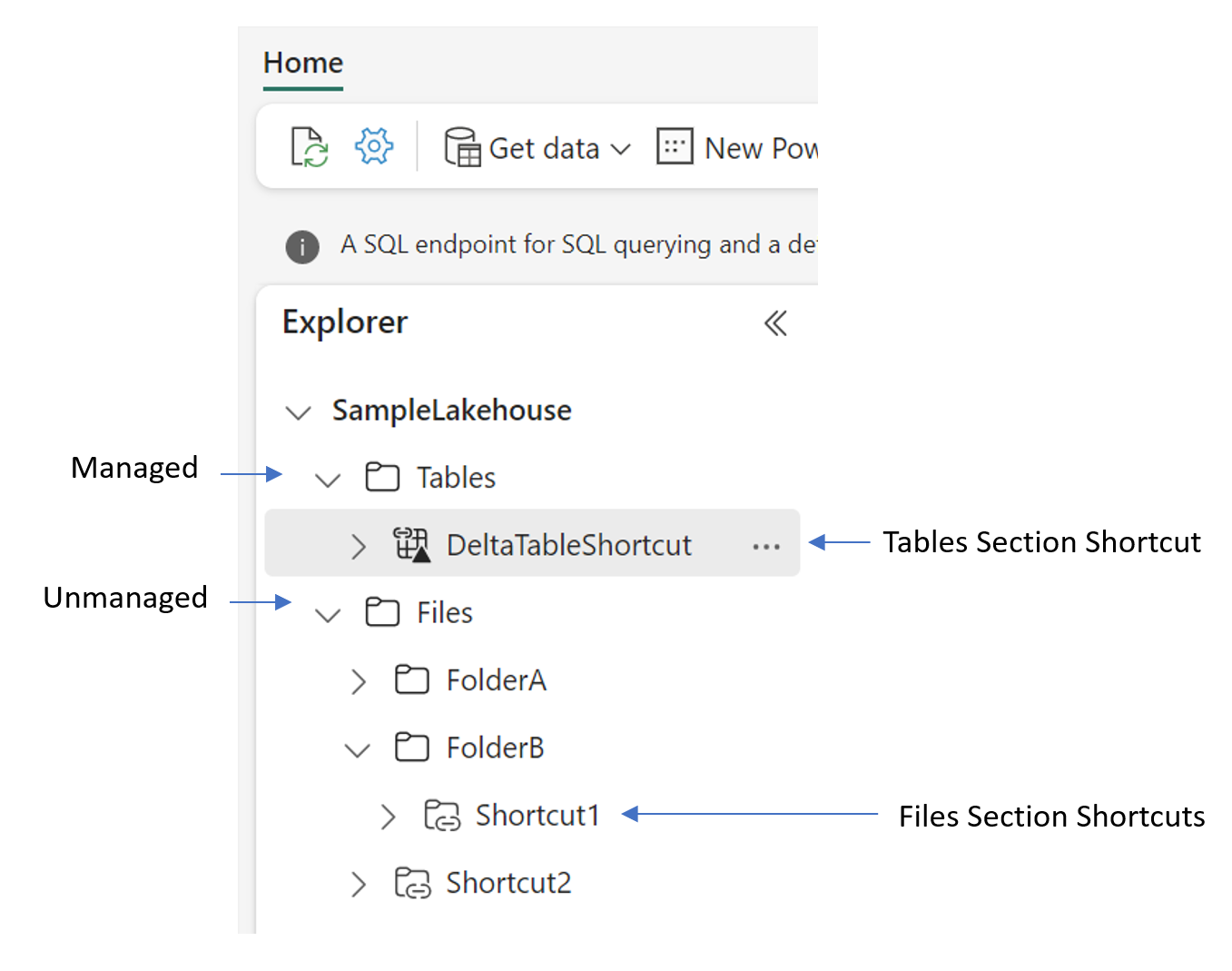
Quando si creano collegamenti in una lakehouse, è necessario comprendere la struttura di cartelle dell'elemento. Lakehouses ha due cartelle di primo livello: la cartella Tables e la cartella Files . La cartella tabelle è per i set di dati strutturati. La cartella dei file è per dati non strutturati o semistrutturati.
Nella cartella tabelle è possibile creare collegamenti solo al livello superiore. OneLake non supporta i collegamenti nelle sottodirectory della cartella tabelle. I collegamenti nella sezione tabelle in genere puntano a origini interne di OneLake o si collegano ad altri asset di dati che rispettano il formato di tabella Delta. Se la destinazione del collegamento contiene dati nel formato Delta Parquet, il lakehouse sincronizza automaticamente i metadati e riconosce la cartella come tabella. I collegamenti nella sezione tabelle possono essere collegati a una singola tabella o a uno schema, ovvero una cartella padre per più tabelle.
Nota
Il formato Delta non supporta tabelle con spazi nel nome. OneLake non riconosce alcuna scorciatoia contenente uno spazio nel nome come tabella Delta nella lakehouse.
Nella cartella dei file non sono previste restrizioni sulla posizione in cui è possibile creare collegamenti. È possibile creare collegamenti a qualsiasi livello della gerarchia di cartelle. L'individuazione delle tabelle non viene eseguita nella cartella dei file. I collegamenti qui possono puntare a sistemi di archiviazione interni di OneLake ed esterni con dati in qualsiasi formato.
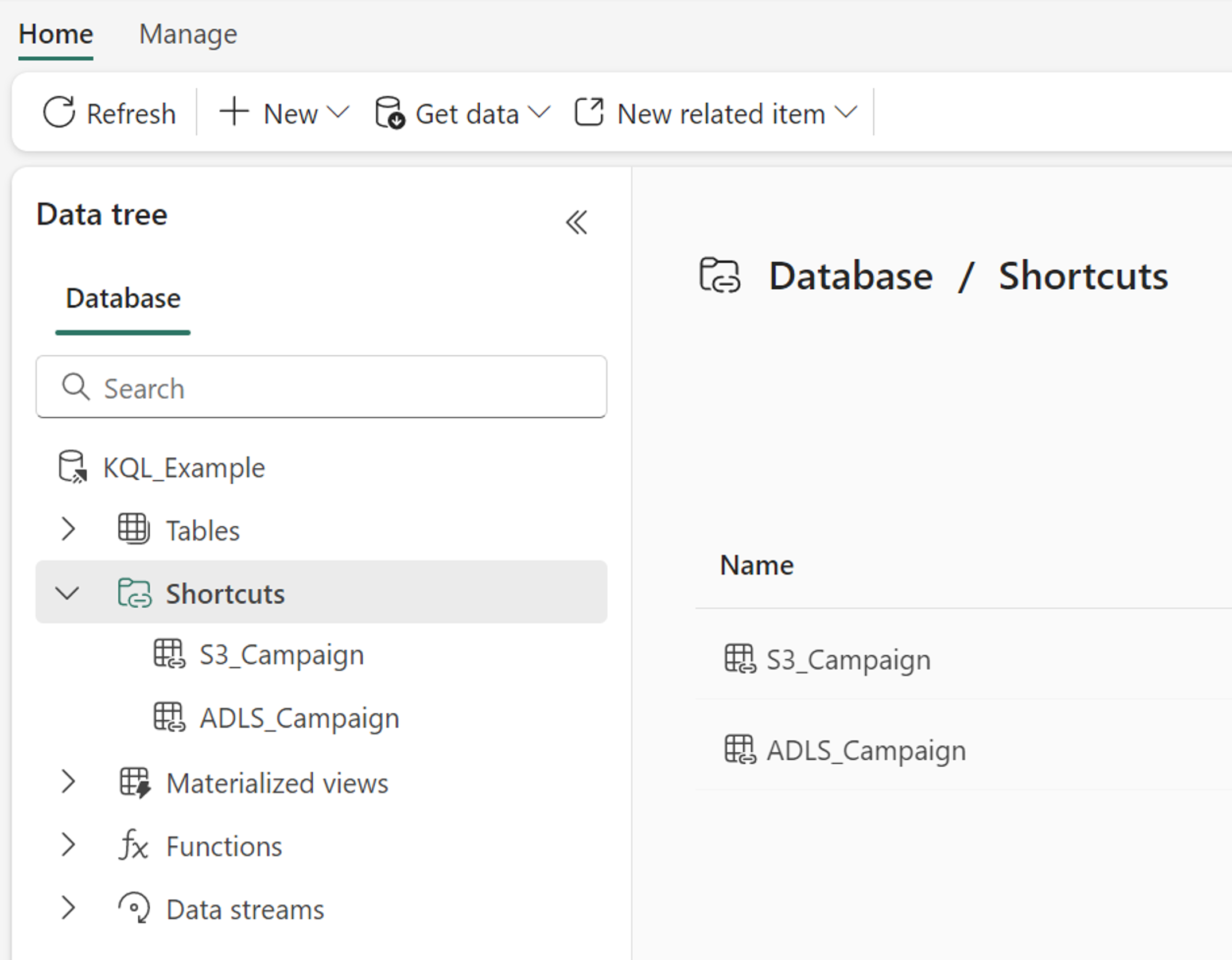
Database KQL
Quando si crea un collegamento in un database KQL, viene visualizzato nella cartella Collegamenti del database. Il database KQL tratta le scorciatoie come tabelle esterne. Per eseguire una query sulla scorciatoia, usare la funzione external_table del Linguaggio di query Kusto.
Dove è possibile accedere ai collegamenti?
Qualsiasi servizio Fabric o non Fabric che può accedere ai dati in OneLake può usare scorciatoie. Le scorciatoie sono trasparenti per qualsiasi servizio che accede ai dati tramite l'API OneLake. I collegamenti vengono visualizzati come un'altra cartella nel lago. Apache Spark, SQL, Analysis Services e Intelligenza in tempo reale possono tutti usare scorciatoie per l'esecuzione di query sui dati.
Apache Spark
I notebook Apache Spark e i processi Apache Spark possono usare le scorciatoie create in OneLake. Usare percorsi di file relativi per leggere i dati direttamente dalle scorciatoie. Inoltre, se si crea un collegamento nella sezione Tabelle della lakehouse e si trova nel formato Delta, è possibile leggerlo come tabella gestita usando la sintassi SQL di Apache Spark.
df = spark.read.format("delta").load("Tables/MyShortcut")
display(df)
df = spark.sql("SELECT * FROM MyLakehouse.MyShortcut LIMIT 1000")
display(df)
SQL
È possibile leggere le scorciatoie nella sezione Tabelle di un lakehouse tramite l'endpoint di analisi SQL per il lakehouse. È possibile accedere all'endpoint di analisi SQL tramite il selettore di modalità del lakehouse o tramite SQL Server Management Studio (SSMS).
SELECT TOP (100) *
FROM [MyLakehouse].[dbo].[MyShortcut]
Intelligence in tempo reale
Le scorciatoie nei database KQL vengono riconosciute come tabelle esterne. Per eseguire una query sulla scorciatoia, usare la funzione external_table del Linguaggio di query Kusto.
external_table('MyShortcut')
| take 100
Servizi di Analisi
Puoi creare modelli semantici per le lakehouse contenenti collegamenti nella sezione Tabelle della lakehouse. Quando il modello semantico viene eseguito in modalità Direct Lake, Analysis Services può leggere i dati direttamente dalla scorciatoia.
Servizi non Fabric
Le applicazioni e i servizi all'esterno di Fabric possono anche accedere ai collegamenti tramite l'API OneLake. OneLake supporta un sottoinsieme delle API di archiviazione BLOB e ADLS Gen2. Per altre informazioni sull'API OneLake, consultare Accesso a OneLake con le API.
https://onelake.dfs.fabric.microsoft.com/MyWorkspace/MyLakhouse/Tables/MyShortcut/MyFile.csv
Tipi di scorciatoie
Le scorciatoie OneLake supportano più origini dati del file system. Queste fonti includono le posizioni interne di OneLake e le fonti esterne o non Microsoft.
È anche possibile creare collegamenti a percorsi locali o con restrizioni di rete utilizzando il gateway dati locale Fabric (OPDG).
Collegamenti interni di OneLake
Usare le scorciatoie interne di OneLake per fare riferimento ai dati all'interno degli elementi Fabric esistenti, tra cui:
- Database di KQL
- Case sul Lago
- Cataloghi replicati di Azure Databricks
- Database con supporto di mirroring
- Modelli semantici
- Basi di dati SQL
- Magazzini
Per istruzioni su come creare un collegamento interno, vedere Creare un collegamento OneLake interno.
Il collegamento può puntare a una posizione della cartella all'interno dello stesso elemento, tra gli elementi all'interno della stessa area di lavoro, o anche tra elementi in aree di lavoro diverse. Quando si crea un collegamento tra gli elementi, i tipi di elemento non devono necessariamente corrispondere. Ad esempio, è possibile creare una scorciatoia in una lakehouse che punta ai dati in un data warehouse.
Quando un utente accede ai dati da un'altra posizione di OneLake tramite un collegamento, OneLake usa l'identità dell'utente chiamante per autorizzare l'accesso ai dati. L'utente deve disporre delle autorizzazioni nella posizione di destinazione per leggere i dati.
Importante
Quando gli utenti accedono alle scorciatoie tramite i modelli semantici di Power BI usando DirectLake su SQL o motori T-SQL in modalità Delegated Identity, l'identità dell'utente chiamante non viene passata alla destinazione della scorciatoia. Invece, viene trasmessa l'identità del proprietario dell'elemento chiamato, che delega l'accesso all'utente chiamante. Per risolvere questa limitazione, usare i modelli semantici di Power BI in modalità DirectLake su OneLake o T-SQL in modalità identità utente.
Collegamenti esterni a OneLake
Per istruzioni dettagliate su come creare un tipo di collegamento specifico, selezionare un articolo da questo elenco di origini esterne supportate:
- Tasti di scelta rapida di Amazon S3
- Collegamenti compatibili con Amazon S3
- Scorciatoie Azure Data Lake Storage (ADLS) Gen 2
- Azure Blob Storage collegamenti
- Scelte rapide da Dataverse
- Scorciatoie di Google Cloud Storage
- Scelte rapide di Iceberg
- scorciatoie OneDrive e SharePoint
Memorizzazione nella cache
La memorizzazione delle scorciatoie nella cache può ridurre i costi di uscita associati all'accesso ai dati tra cloud. Man mano che OneLake legge i file tramite un collegamento esterno, il servizio archivia i file in una cache per l'area di lavoro Fabric. OneLake risponde alle successive richieste di lettura dalla cache anziché al provider di archiviazione remoto. È possibile impostare il periodo di conservazione per i file memorizzati nella cache tra 1 e 28 giorni. Ogni volta che si accede al file, il periodo di conservazione viene reimpostato. Se l'archiviazione remota fornisce una versione più recente del file rispetto alla versione della cache, OneLake gestisce la richiesta dal provider di archiviazione remoto e aggiorna il file nella cache. Se non si accede a un file entro il periodo di conservazione selezionato, viene eliminato dalla cache. I singoli file di dimensioni superiori a 1 GB non vengono memorizzati nella cache.
Nota
La memorizzazione nella cache dei collegamenti supporta attualmente i collegamenti di Google Cloud Storage (GCS), S3, S3 compatibili e gateway dati locali.
La memorizzazione nella cache è supportata anche per i collegamenti Amazon S3 in sede che usano l'autenticazione con entità del servizio di Microsoft Entra.
Per abilitare la memorizzazione dei collegamenti nella cache, aprire il pannello Impostazioni area di lavoro. Scegliere la scheda OneLake. Impostare l'impostazione della cache su Attivo e selezionare il periodo di conservazione .
È possibile cancellare la cache in qualsiasi momento. Nella stessa pagina delle impostazioni selezionare il pulsante Reimposta cache. Questa azione rimuove tutti i file dalla cache dei collegamenti in questa area di lavoro.

Come le scorciatoie utilizzano le connessioni cloud
I collegamenti rapidi ADLS e S3 delegano l'autorizzazione usando le connessioni cloud. Quando si crea un nuovo collegamento ADLS o S3, è possibile creare una nuova connessione o selezionare una connessione esistente per l'origine dati. La configurazione di una connessione per un collegamento è un'operazione di associazione. Solo gli utenti con autorizzazione per la connessione possono eseguire l'operazione di associazione. Se non si dispone dell'autorizzazione per la connessione, non è possibile creare nuovi collegamenti usando tale connessione.
Per ulteriori informazioni su come visualizzare e aggiornare le connessioni cloud, vedere Gestire le connessioni per i collegamenti.
Sicurezza delle scorciatoie
Sono necessarie determinate autorizzazioni per gestire e usare le scorciatoie. La sicurezza dei tasti di scelta rapida di OneLake illustra le autorizzazioni necessarie per creare collegamenti e accedere ai dati tramite di essi.
In che modo le scorciatoie gestiscono le eliminazioni?
I collegamenti non supportano le eliminazioni a catena. Quando si elimina un collegamento, si elimina solo l'oggetto collegamento. I dati nella destinazione di scelta rapida rimangono invariati. Tuttavia, se si elimina un file o una cartella all'interno di un collegamento e si dispone delle autorizzazioni nella destinazione collegamento per eseguire l'operazione di eliminazione, si elimina anche il file o la cartella nella destinazione.
Si consideri, ad esempio, una lakehouse con il seguente percorso: MyLakehouse\Files\MyShortcut\Foo\Bar.
MyShortcut è un collegamento che punta a un account ADLS Gen2 che contiene le directory Foo\Bar.
Se si elimina MyLakehouse\Files\MyShortcut, si elimina il collegamento MyShortcut dal lakehouse, ma i file e le directory nell'account ADLS Gen2 Foo\Bar rimangono invariati.
Se si elimina MyLakehouse\Files\MyShortcut\Foo\Bare si dispone delle autorizzazioni di scrittura nell'account ADLS Gen2, eliminare la directory Barra dall'account ADLS Gen2.
Visualizzazione del tracciamento dell'area di lavoro
Quando si creano collegamenti rapidi tra più elementi di Fabric all'interno di un'area di lavoro, è possibile visualizzare le relazioni tramite la visualizzazione della derivazione dell'area di lavoro. Selezionare il pulsante Visualizzazione Lineage ( ) nell'angolo superiore destro di Esplora risorse di lavoro.
) nell'angolo superiore destro di Esplora risorse di lavoro.

Nota
La visualizzazione lineage è limitata a una singola area di lavoro. I collegamenti alle posizioni esterne all'area di lavoro selezionata non vengono visualizzati.
Limitazioni e considerazioni
- Ogni elemento "Fabric" supporta fino a 100.000 collegamenti. In questo contesto, il termine elemento si riferisce ad app, lakehouse, magazzini dati, report e altro ancora.
- Un singolo percorso di OneLake supporta fino a 10 scorciatoie.
- Il numero massimo di scorciatoie dirette a scorciatoie di collegamenti è 5.
- I nomi dei collegamenti rapidi OneLake, i percorsi di origine e i percorsi di destinazione non possono contenere i caratteri "%" o "+".
- I collegamenti non supportano caratteri non latini.
- La derivazione per i collegamenti ai data warehouse e ai modelli semantici non è attualmente disponibile.
- Un collegamento Fabric si sincronizza con l'origine quasi istantaneamente, ma il tempo di propagazione può variare a causa delle prestazioni dell'origine dati, delle visualizzazioni memorizzate nella cache o dei problemi di connettività di rete.
- L'API Tabella potrebbe richiedere fino a un minuto per riconoscere le nuove scorciatoie.