Esercitazione: Usare un notebook con Apache Spark per eseguire query su un database KQL
I notebook sono entrambi documenti leggibili contenenti descrizioni e risultati dell'analisi dei dati, nonché documenti eseguibili che possono essere eseguiti per eseguire l'analisi dei dati. Questo articolo illustra come usare un notebook di Microsoft Fabric per leggere e scrivere dati in un database KQL usando Apache Spark. Questa esercitazione usa set di dati e notebook creati in modo preliminare sia in Analisi in tempo reale che negli ambienti Ingegneria dei dati in Microsoft Fabric. Per altre informazioni sui notebook, vedere Come usare i notebook di Microsoft Fabric.
In particolare, si apprenderà come:
- Creare un database KQL
- Importare un notebook
- Scrivere dati in un database KQL usando Apache Spark
- Eseguire query sui dati da un database KQL
Prerequisiti
- Un'area di lavoro con capacità abilitata per Microsoft Fabric
1- Creare un database KQL
Aprire il commutatore esperienza nella parte inferiore del riquadro di spostamento e selezionare Analisi in tempo reale.
Selezionare il riquadro Database KQL.
Nel campo Nome database KQL immettere nycGreenTaxi e quindi selezionare Crea.
Il database KQL è stato creato nel contesto dell'area di lavoro selezionata.
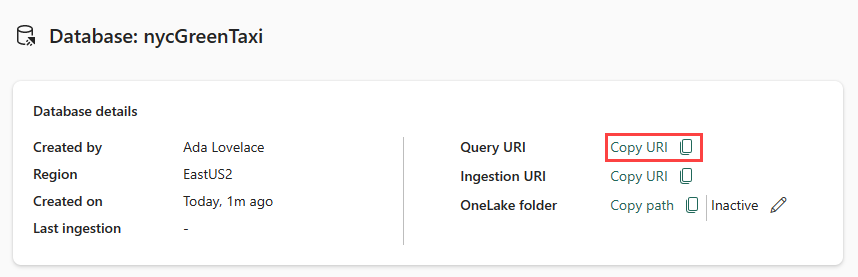
Copiare l'URI di query dalla scheda dei dettagli del database nel dashboard del database e incollarlo in un punto qualsiasi, ad esempio un Blocco note, da usare in un passaggio successivo.
2- Scaricare il notebook di Nyc GreenTaxi
È stato creato un notebook di esempio che illustra tutti i passaggi necessari per caricare i dati nel database usando il connettore Spark.
Aprire il repository degli esempi di Infrastruttura in GitHub per scaricare il notebook KQL di New York GreenTaxi.
Salvare il notebook in locale nel dispositivo.
Nota
Il notebook deve essere salvato nel
.ipynbformato di file.

3- Importare il notebook
Il resto di questo flusso di lavoro si verifica nella sezione Ingegneria dei dati del prodotto e usa un notebook Spark per caricare ed eseguire query sui dati nel database KQL.
Aprire il commutatore esperienza nella parte inferiore del riquadro di spostamento e selezionare Ingegneria dei dati.
Selezionare Importa notebook.
Nella finestra Stato importazione selezionare Carica.
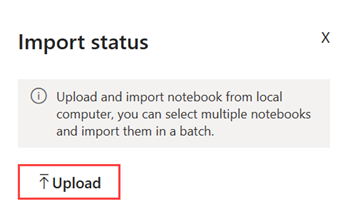
Selezionare il notebook nyc GreenTaxi scaricato in un passaggio precedente.
Al termine dell'importazione, tornare all'area di lavoro per aprire il notebook.
4- Ottenere dati
Per eseguire query sul database usando il connettore Spark, è necessario concedere l'accesso in lettura e scrittura al contenitore BLOB NYC GreenTaxi.
Selezionare il pulsante play per eseguire le celle seguenti oppure selezionare la cella e premere MAIUSC+ INVIO. Ripetere questo passaggio per ogni cella di codice.
Nota
Attendere che venga visualizzato il segno di spunta di completamento prima di eseguire la cella successiva.
Eseguire la cella seguente per abilitare l'accesso al contenitore BLOB NYC GreenTaxi.
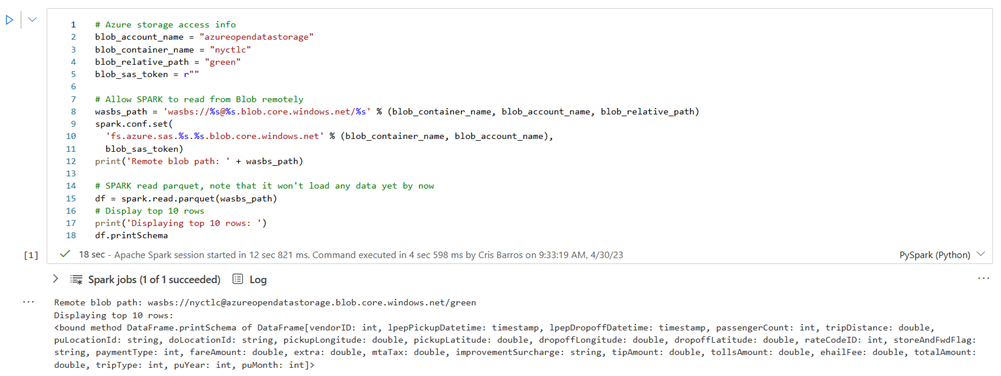
In KustoURI incollare l'URIdi query copiato in precedenza anziché il testo segnaposto.
Modificare il nome del database segnaposto in nycGreenTaxi.
Modificare il nome della tabella segnaposto in GreenTaxiData.

Eseguire la cella.
Eseguire la cella successiva per scrivere dati nel database. Il completamento di questo passaggio potrebbe richiedere alcuni minuti.




Il database include ora i dati caricati in una tabella denominata GreenTaxiData.
5- Eseguire il notebook
Eseguire le due celle rimanenti in sequenza per eseguire query sui dati dalla tabella. I risultati mostrano le prime 20 tariffe e distanze dei taxi più alte e più basse registrate per anno.

6- Pulire le risorse
Pulire gli elementi creati passando all'area di lavoro in cui sono stati creati.
Nell'area di lavoro passare il puntatore del mouse sul notebook che si vuole eliminare, selezionare il menu Altro [...] >Elimina.
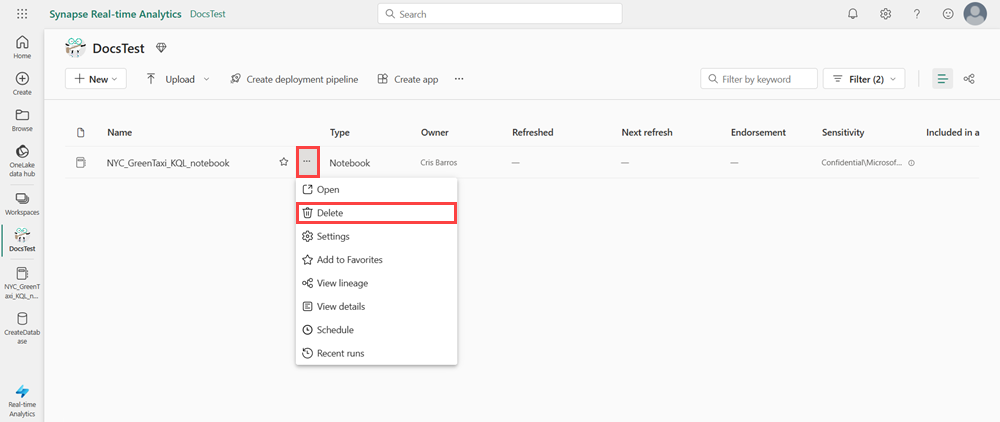
Selezionare Elimina. Non è possibile recuperare il notebook dopo averlo eliminato.

Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per