Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I servizi cloud e i dispositivi IoT generano dati di telemetria che possono essere usati per ottenere informazioni dettagliate, ad esempio il monitoraggio dell'integrità dei servizi, i processi di produzione fisici e le tendenze di utilizzo. L'esecuzione di analisi delle serie temporali è un modo per identificare le deviazioni nel modello di queste metriche rispetto al modello di base tipico.
Kusto Query Language (KQL) contiene il supporto nativo per la creazione, la manipolazione e l'analisi di più serie temporali. Questo articolo illustra come KQL viene usato per creare e analizzare migliaia di serie temporali in secondi, abilitando soluzioni e flussi di lavoro di monitoraggio quasi in tempo reale.
Creazione di serie temporali
In questa sezione creeremo un ampio set di serie temporali regolari in modo semplice e intuitivo usando l'operatore make-series e riempiremo i valori mancanti secondo le necessità.
Il primo passaggio dell'analisi delle serie temporali consiste nel partizionare e trasformare la tabella di telemetria originale in un set di serie temporali. La tabella contiene in genere una colonna timestamp, dimensioni contestuali e metriche facoltative. Le dimensioni vengono utilizzate per partizionare i dati. L'obiettivo è creare migliaia di serie temporali per partizione a intervalli di tempo regolari.
La tabella di input demo_make_series1 contiene 600.000 record di traffico arbitrario del servizio Web. Usare il comando seguente per campionare 10 record:
demo_make_series1 | take 10
La tabella risultante contiene una colonna timestamp, tre colonne dimensioni contestuali e nessuna metrica:
| Marcatempo | BrowserVer | OsVer | Paese/area geografica |
|---|---|---|---|
| 2016-08-25 09:12:35.4020000 | Chrome 51.0 | Windows 7 | Regno Unito |
| 2016-08-25 09:12:41.1120000 | Chrome 52.0 | Windows 10 | |
| 2016-08-25 09:12:46.2300000 | Chrome 52.0 | Windows 7 | Regno Unito |
| 2016-08-25 09:12:46.5100000 | Chrome 52.0 | Windows 10 | Regno Unito |
| 2016-08-25 09:12:46.5570000 | Chrome 52.0 | Windows 10 | Repubblica di Lituania |
| 2016-08-25 09:12:47.0470000 | Chrome 52.0 | Windows 8.1 | India |
| 2016-08-25 09:12:51.3600000 | Chrome 52.0 | Windows 10 | Regno Unito |
| 2016-08-25 09:12:51.6930000 | Chrome 52.0 | Windows 7 | Paesi Bassi |
| 2016-08-25 09:12:56.4240000 | Chrome 52.0 | Windows 10 | Regno Unito |
| 2016-08-25 09:13:08.7230000 | Chrome 52.0 | Windows 10 | India |
Poiché non sono presenti metriche, è possibile compilare solo un set di serie temporali che rappresenta il conteggio del traffico stesso, partizionato dal sistema operativo usando la query seguente:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| render timechart
- Usare l'operatore
make-seriesper creare un set di tre serie temporali, dove:-
num=count(): serie temporale del traffico -
from min_t to max_t step 1h: la serie temporale viene creata in segmenti di 1 ora nell'intervallo di tempo (i timestamp più antichi e più recenti dei record di tabella) -
default=0: specificare il metodo di riempimento per le caselle mancanti per creare serie temporali regolari. In alternativa, usareseries_fill_const(),series_fill_forward()series_fill_backward()eseries_fill_linear()per le modifiche -
by OsVer: partizione per sistema operativo
-
- La struttura dei dati della serie temporale effettiva è una matrice numerica del valore aggregato per ogni contenitore temporale. Viene usato
render timechartper la visualizzazione.
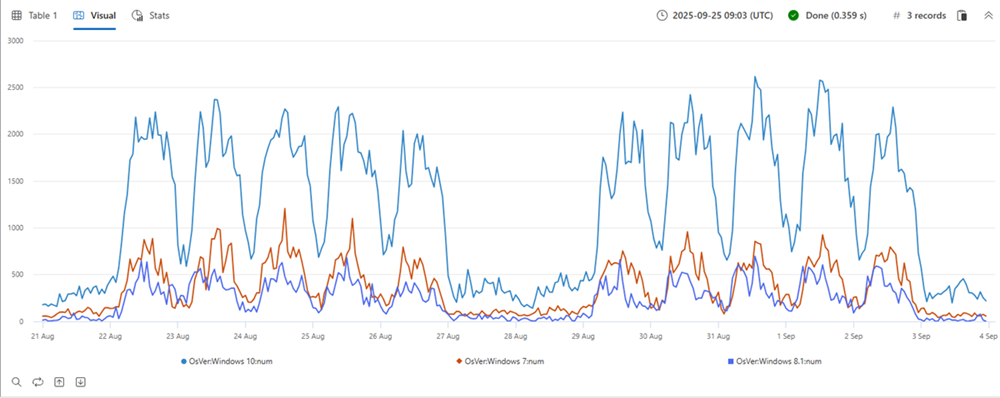
Nella tabella precedente sono presenti tre partizioni. È possibile creare una serie temporale separata: Windows 10 (rosso), 7 (blu) e 8.1 (verde) per ogni versione del sistema operativo, come illustrato nel grafico:
Funzioni di analisi delle serie temporali
In questa sezione verranno eseguite funzioni tipiche di elaborazione delle serie. Dopo aver creato un set di serie temporali, KQL supporta un elenco crescente di funzioni da elaborare e analizzare. Verranno descritte alcune funzioni rappresentative per l'elaborazione e l'analisi delle serie temporali.
Filtraggio
Il filtro è una pratica comune nell'elaborazione dei segnali e utile per le attività di elaborazione delle serie temporali (ad esempio, uniformare un segnale rumoroso, rilevamento delle modifiche).
- Esistono due funzioni di filtro generiche:
-
series_fir(): applicazione del filtro FIR. Usato per un semplice calcolo della media mobile e della differenziazione della serie temporale per il rilevamento delle modifiche. -
series_iir(): applicazione del filtro IIR. Usato per il livellamento esponenziale e la somma cumulativa.
-
-
Extendla serie temporale impostata aggiungendo una nuova serie di media mobile con una dimensione di 5 bin (denominata ma_num) alla query.
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| render timechart

Analisi della regressione
È possibile usare un'analisi di regressione lineare segmentata per stimare la tendenza della serie temporale.
- Usare series_fit_line() per adattare la linea migliore a una serie temporale per il rilevamento generale delle tendenze.
- Usare series_fit_2lines() per rilevare le variazioni di tendenza rispetto alla baseline, utili negli scenari di monitoraggio.
Esempio delle funzioni series_fit_line() e series_fit_2lines() in una query di serie temporali:
demo_series2
| extend series_fit_2lines(y), series_fit_line(y)
| render linechart with(xcolumn=x)
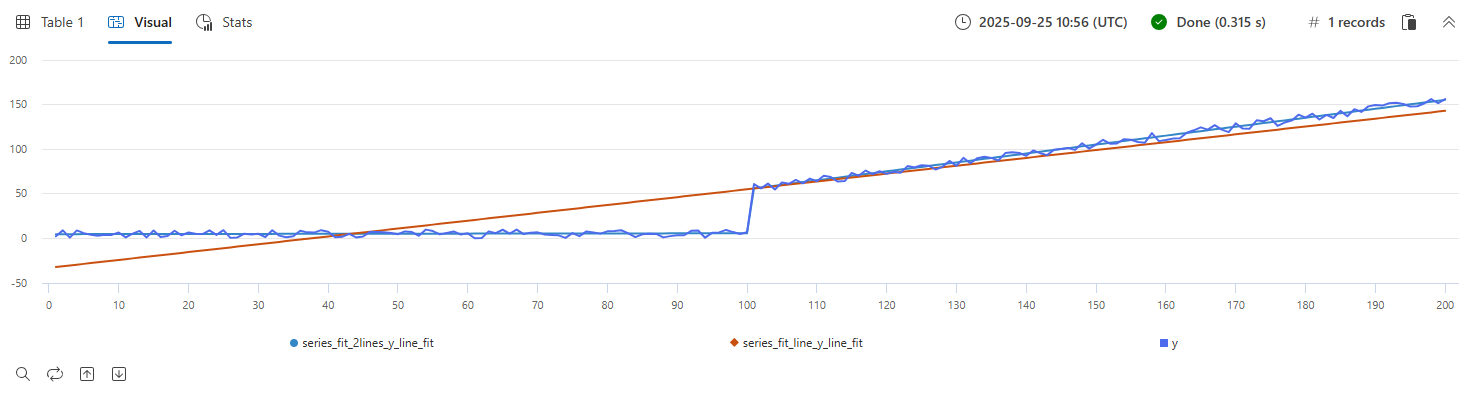
- Blu: serie temporale originale
- Verde: linea adattata
- Rosso: due linee montate
Annotazioni
La funzione ha rilevato accuratamente il punto di salto (modifica del livello).
Rilevamento della stagionalità
Molte metriche seguono modelli stagionali (periodici). Il traffico degli utenti dei servizi cloud in genere contiene modelli giornalieri e settimanali che sono più alti intorno alla metà del giorno lavorativo e al minimo di notte e nel fine settimana. I sensori IoT misurano a intervalli periodici. Le misurazioni fisiche, ad esempio temperatura, pressione o umidità, possono anche mostrare un comportamento stagionale.
L'esempio seguente applica il rilevamento della stagionalità sul traffico di un servizio web per un mese (intervalli di 2 ore):
demo_series3
| render timechart

- Usare series_periods_detect() per rilevare automaticamente i periodi della serie temporale, dove:
-
num: serie temporale da analizzare -
0.: la lunghezza minima del periodo in giorni (0 indica che non è minimo) -
14d/2h: la lunghezza massima del periodo in giorni, ovvero 14 giorni divisi in contenitori di 2 ore -
2: numero di periodi da rilevare
-
- Usare series_periods_validate() se si sa che una metrica deve avere periodi distinti specifici e si vuole verificare che esistano.
Annotazioni
Si tratta di un'anomalia se non esistono periodi distinti specifici
demo_series3
| project (periods, scores) = series_periods_detect(num, 0., 14d/2h, 2) //to detect the periods in the time series
| mv-expand periods, scores
| extend days=2h*todouble(periods)/1d
| Periodi | Punteggi | Giorni |
|---|---|---|
| 84 | 0.820622786055595 | 7 |
| 12 | 0.764601405803502 | 1 |
La funzione rileva la stagionalità giornaliera e settimanale. Il punteggio giornaliero è inferiore a quello settimanale perché i giorni del fine settimana sono diversi dai giorni feriali.
Funzioni a livello di elemento
Le operazioni aritmetiche e logiche possono essere eseguite su una serie temporale. Usando series_subtract() è possibile calcolare una serie temporale residua, ovvero la differenza tra la metrica non elaborata originale e quella smussata e cercare anomalie nel segnale residuo:
let min_t = toscalar(demo_make_series1 | summarize min(TimeStamp));
let max_t = toscalar(demo_make_series1 | summarize max(TimeStamp));
demo_make_series1
| make-series num=count() default=0 on TimeStamp from min_t to max_t step 1h by OsVer
| extend ma_num=series_fir(num, repeat(1, 5), true, true)
| extend residual_num=series_subtract(num, ma_num) //to calculate residual time series
| where OsVer == "Windows 10" // filter on Win 10 to visualize a cleaner chart
| render timechart
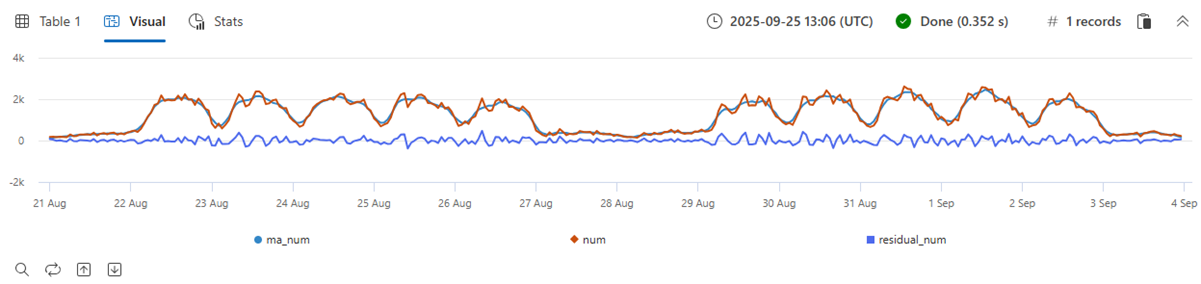
- Blu: serie temporale originale
- Rosso: serie temporale smussata
- Verde: serie temporale residua
Flusso di lavoro di serie temporali su larga scala
L'esempio seguente mostra come queste funzioni possono essere eseguite su larga scala su migliaia di serie temporali in secondi per il rilevamento anomalie. Per visualizzare alcuni record di telemetria di esempio della metrica di conteggio di lettura di un servizio di database in quattro giorni, eseguire la query seguente:
demo_many_series1
| take 4
| TIMESTAMP | Loc | Op | DB | DataRead |
|---|---|---|---|---|
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 262 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 5117853934049630089 | 241 | 0 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | -865998331941149874 | 262 | 279862 |
| 2016-09-11 21:00:00.0000000 | Loc 9 | 371921734563783410 | 255 | 0 |
E statistiche semplici:
demo_many_series1
| summarize num=count(), min_t=min(TIMESTAMP), max_t=max(TIMESTAMP)
| Num | min_t | max_t |
|---|---|---|
| 2177472 | 2016-09-08 00:00:00.0000000 | 2016-09-11 23:00:00.0000000 |
La creazione di una serie temporale in intervalli di 1 ora della metrica di lettura (totale di quattro giorni * 24 ore = 96 punti) comporta fluttuazioni normali:
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h
| render timechart with(ymin=0)
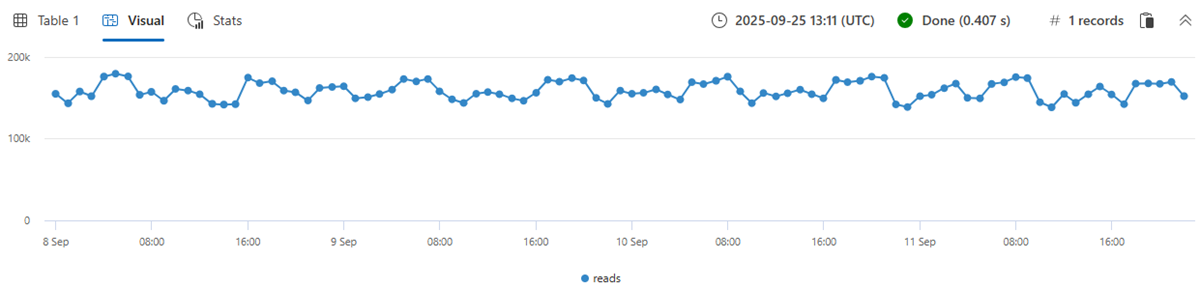
Il comportamento precedente è fuorviante, poiché la singola serie temporale normale viene aggregata da migliaia di istanze diverse che possono avere modelli anomali. Pertanto, viene creata una serie temporale per ogni istanza. Un'istanza è definita da Loc (posizione), Op (operazione) e DB (computer specifico).
Quante serie temporali è possibile creare?
demo_many_series1
| summarize by Loc, Op, DB
| count
| Conteggio |
|---|
| 18339 |
Ora si creerà un set di 18339 serie temporali della metrica del conteggio delle letture. Aggiungiamo la clausola by all'istruzione make-series, applichiamo la regressione lineare e selezioniamo le prime due serie temporali che hanno mostrato la tendenza decrescente più significativa.
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| render timechart with(title='Service Traffic Outage for 2 instances (out of 18339)')
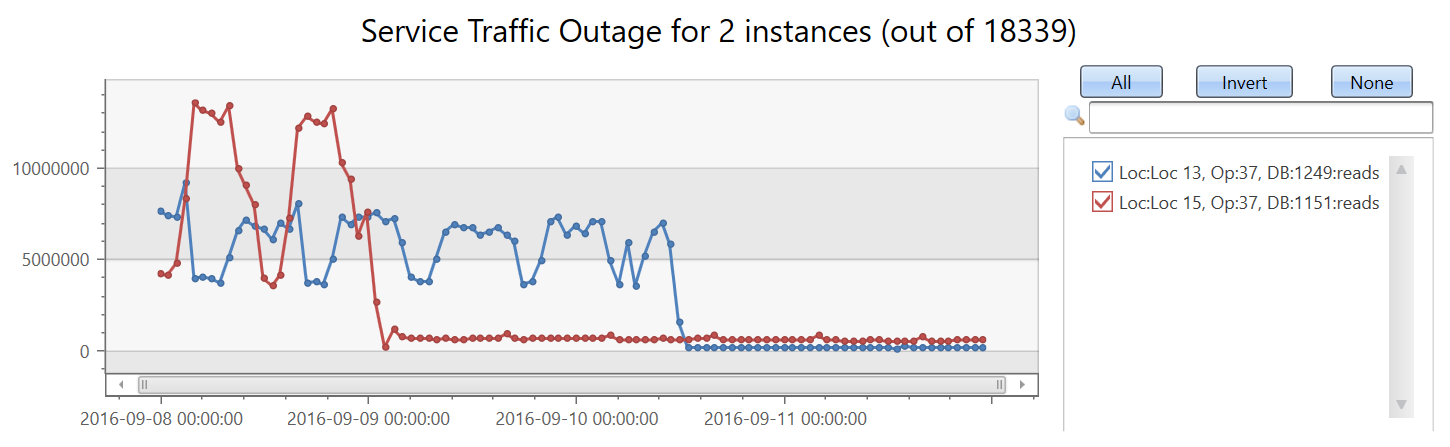
Visualizza le istanze
let min_t = toscalar(demo_many_series1 | summarize min(TIMESTAMP));
let max_t = toscalar(demo_many_series1 | summarize max(TIMESTAMP));
demo_many_series1
| make-series reads=avg(DataRead) on TIMESTAMP from min_t to max_t step 1h by Loc, Op, DB
| extend (rsquare, slope) = series_fit_line(reads)
| top 2 by slope asc
| project Loc, Op, DB, slope
| Loc | Op | DB | pendio |
|---|---|---|---|
| Loc 15 | 37 | 1151 | -102743.910227889 |
| Loc 13 | 37 | 1249 | -86303.2334644601 |
In meno di due minuti, sono state analizzate quasi 20.000 serie temporali e sono state rilevate due serie temporali anomale in cui il conteggio di lettura è stato improvvisamente eliminato.
Queste funzionalità avanzate combinate con prestazioni veloci forniscono una soluzione unica e potente per l'analisi delle serie temporali.
Contenuti correlati
- Informazioni sul rilevamento e la previsione delle anomalie con KQL.
- Informazioni sulle funzionalità di Machine Learning con KQL.