Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Crea una serie di valori aggregati specificati lungo un asse specificato.
Sintassi
T [MakeSeriesParameters| make-series [] [=] default= [ [,on] [from ...]]
Altre informazioni sulle convenzioni di sintassi.
Parametri
| Nome | Digita | Obbligatorio | Descrizione |
|---|---|---|---|
| Istogramma | string |
Nome della colonna del risultato. Il valore predefinito è un nome derivato dall'espressione. | |
| DefaultValue | scalare | Valore predefinito da utilizzare anziché valori assenti. Se non è presente alcuna riga con valori specifici di AxisColumn e GroupExpression, all'elemento corrispondente della matrice viene assegnato un valore DefaultValue. Il valore predefinito è 0. | |
| Aggregazione | string |
✔️ | Chiamata a una funzione di aggregazione, ad esempio count() o avg(), con nomi di colonna come argomenti. Vedere l' elenco delle funzioni di aggregazione. Con l'operatore make-series è possibile usare solo funzioni di aggregazione che restituiscono risultati numerici. |
| AxisColumn | string |
✔️ | Colonna in base alla quale viene ordinata la serie. In genere i valori di colonna sono di tipo datetime o timespan ma vengono accettati tutti i tipi numerici. |
| avviare | scalare | ✔️ | Valore con limite basso di AxisColumn per ogni serie da compilare. Se l'avvio non è specificato, è il primo bin o il primo passaggio con dati in ogni serie. |
| fine | scalare | ✔️ | Valore non inclusivo associato elevato di AxisColumn. L'ultimo indice della serie temporale è minore di questo valore e inizia più numero intero multiplo di passaggio minore di fine. Se la fine non è specificata, si tratta del limite superiore dell'ultimo bin o del passaggio con i dati per ogni serie. |
| passo | scalare | ✔️ | Differenza, o dimensione bin, tra due elementi consecutivi della matrice AxisColumn . Per un elenco di possibili intervalli di tempo, vedere intervallo di tempo. |
| GroupExpression | un'espressione eseguita sulle colonne che fornisce un set di valori distinti. In genere è un nome di colonna che fornisce già un set limitato di valori. | ||
| MakeSeriesParameters | Zero o più parametri separati da spazi sotto forma di Valore nome=che controllano il comportamento. Vedere i parametri di make series supportati. |
Nota
I startparametri , ende step vengono usati per compilare una matrice di valori AxisColumn . La matrice è costituita da valori tra start e end, con il step valore che rappresenta la differenza tra un elemento di matrice e quello successivo. Tutti i valori di Aggregazione vengono ordinati rispettivamente in base a questa matrice.
Parametri di make series supportati
| Nome | Descrizione |
|---|---|
kind |
Produce il risultato predefinito quando l'input dell'operatore make-series è vuoto. Valore: nonempty |
hint.shufflekey=<key> |
La shufflekey query condivide il carico delle query sui nodi del cluster, usando una chiave per partizionare i dati. Vedere query shuffle |
Nota
Le matrici generate da make-series sono limitate a 1.048.576 valori (2^20). Il tentativo di generare una matrice più grande con make-series genera un errore o una matrice troncata.
Sintassi alternativa
T| make-series [Colonna=] Aggregazione [default=DefaultValue] [, ...] onAxisColumninrange(inizio,fermarsi,passo) [by [Column=] GroupExpression [, ...]]
La serie generata dalla sintassi alternativa è diversa da quella della sintassi principale per due aspetti:
- Il valore di stop è inclusivo.
- La creazione di binning dell'asse dell'indice viene generata con bin() e non bin_at(), il che significa che l'avvio potrebbe non essere incluso nella serie generata.
È consigliabile usare la sintassi principale di make-series e non la sintassi alternativa.
Valori restituiti
Le righe di input sono disposte in gruppi con gli stessi valori dell'espressione by e dell'espressione bin_at(AxisColumn,step,start). Vengono quindi calcolate per ogni gruppo le funzioni di aggregazione specificate, generando una riga per ogni gruppo. Il risultato contiene le colonne by, AxisColumn e anche almeno una colonna per ogni aggregazione calcolata. Le aggregazioni su più colonne o risultati non numerici non sono supportate.
Questo risultato intermedio include tutte le righe che costituiscono combinazioni distinte di by e dei valori di bin_at(AxisColumn,step,start).
Infine, le righe del risultato intermedio vengono disposte in gruppi con gli stessi valori delle espressioni by e tutti i valori aggregati vengono disposti in matrici (valori di tipo dynamic). Per ogni aggregazione, è presente una colonna contenente la matrice con lo stesso nome. L'ultima colonna è una matrice contenente i valori di AxisColumn binned in base al passaggio specificato.
Nota
Anche se è possibile specificare espressioni arbitrarie per le espressioni di aggregazione e raggruppamento, è preferibile usare nomi di colonna semplici.
Elenco di funzioni di aggregazione
| Funzione | Descrizione |
|---|---|
| avg() | Restituisce un valore medio nel gruppo |
| avgif() | Restituisce una media con il predicato del gruppo |
| count() | Restituisce un conteggio del gruppo |
| countif() | Restituisce un conteggio con il predicato del gruppo |
| covarianza() | Restituisce la covarianza di esempio di due variabili casuali |
| covarianceif() | Restituisce la covarianza di esempio di due variabili casuali con predicato |
| covariancep() | Restituisce la covarianza della popolazione di due variabili casuali |
| covariancepif() | Restituisce la covarianza della popolazione di due variabili casuali con predicato |
| dcount() | Restituisce un numero approssimativo di valori distinti degli elementi del gruppo |
| dcountif() | Restituisce un numero approssimativo di valori distinti con il predicato del gruppo |
| max() | Restituisce il valore massimo nel gruppo |
| maxif() | Restituisce il valore massimo con il predicato del gruppo |
| min() | Restituisce il valore minimo nel gruppo |
| minif() | Restituisce il valore minimo con il predicato del gruppo |
| percentile() | Restituisce il valore percentile nel gruppo |
| take_any() | Restituisce un valore casuale non vuoto per il gruppo |
| stdev() | Restituisce la deviazione standard del gruppo |
| sum() | Restituisce la somma degli elementi all'interno del gruppo |
| sumif() | Restituisce la somma degli elementi con il predicato del gruppo |
| varianza() | Restituisce la varianza campione nel gruppo |
| varianceif() | Restituisce la varianza di esempio nel gruppo con predicato |
| varianza() | Restituisce la varianza della popolazione nel gruppo |
| variancepif() | Restituisce la varianza della popolazione nel gruppo con predicato |
Elenco di funzioni di analisi delle serie
| Funzione | Descrizione |
|---|---|
| series_fir() | Applica il filtro Finite Impulse Response |
| series_iir() | Applica il filtro Infinite Impulse Response |
| series_fit_line() | Trova una linea retta che rappresenta la migliore approssimazione dell'input |
| series_fit_line_dynamic() | Trova una linea che rappresenta la migliore approssimazione dell'input, restituendo un oggetto dinamico |
| series_fit_2lines() | Trova due linee che rappresentano la migliore approssimazione dell'input |
| series_fit_2lines_dynamic() | Trova due linee che rappresentano la migliore approssimazione dell'input, restituendo un oggetto dinamico |
| series_outliers() | Assegna un punteggio ai punti anomali di una serie |
| series_periods_detect() | Trova i periodi più significativi esistenti in una serie temporale |
| series_periods_validate() | Verifica se una serie temporale contiene modelli periodici di lunghezze specificate |
| series_stats_dynamic() | Restituisce più colonne con la statistica comune (min/max/varianza/deviazione standard/media) |
| series_stats() | Genera un valore dinamico con la statistica comune (min/max/varianza/deviazione standard/media) |
Per un elenco completo delle funzioni di analisi delle serie, vedere: Funzioni di elaborazione delle serie
Elenco di funzioni di interpolazione della serie
- Nota: per impostazione predefinita, le funzioni di interpolazione presuppongono
nullcome valore mancante. Pertanto, specificaredefault=double(null) inmake-seriesse si prevede di usare le funzioni di interpolazione per la serie.
Esempi
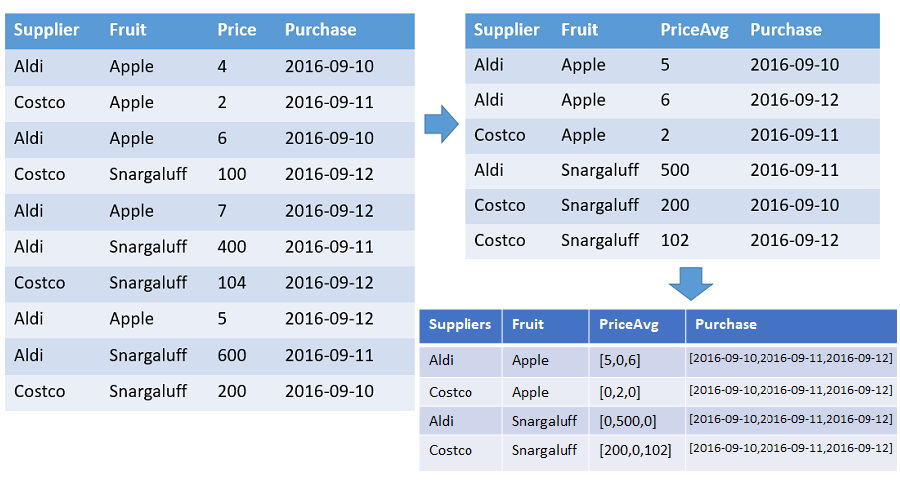
Una tabella che mostra una matrice di numeri e prezzi medi di ogni frutto offerto da ogni fornitore ordinati per timestamp con l'intervallo specificato. L'output include una riga per ogni combinazione distinta di frutta e fornitore. La colonna di output mostra la frutta, il fornitore e le matrici di conteggio, media e sequenza temporale completa (dal 1° gennaio 2016 al 10 gennaio 2016). Tutte le matrici sono ordinate in base al rispettivo timestamp e tutti i valori mancanti vengono sostituiti dai valori predefiniti (0 in questo esempio). Tutte le altre colonne di input vengono ignorate.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | Marca temporale |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.00000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:0100:00.00000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Quando l'input in make-series è vuoto, il comportamento predefinito di make-series produce un risultato vuoto.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Risultato
| Conteggio |
|---|
| 0 |
L'uso di kind=nonempty in make-series produce un risultato non vuoto dei valori predefiniti:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Risultato
| avg_metric | Marca temporale |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.00000000Z", "2017-01-02T00:00:00.00000000Z", "2017-01-03T00:00:00.00000000Z", "2017-01-04T00:00:00.00000000Z", "2017-01-05T00:00:00.00000000Z", "2017-01-06T00:00:00.00000000Z", "2017-01-07T00:00:00.00000000Z", "2017-01-08T00:00:00.00000000Z", "2017-01-09T00:00:00.00000000Z" ] |
Uso di make-series e mv-expand per riempire i valori per i record mancanti:
let startDate = datetime(2025-01-06);
let endDate = datetime(2025-02-09);
let data = datatable(Time: datetime, Value: int, other:int)
[
datetime(2025-01-07), 10, 11,
datetime(2025-01-16), 20, 21,
datetime(2025-02-01), 30, 5
];
data
| make-series Value=sum(Value), other=-1 default=-2 on Time from startDate to endDate step 7d
| mv-expand Value, Time, other
| extend Time=todatetime(Time), Value=toint(Value), other=toint(other)
| project-reorder Time, Value, other
Risultato
| Tempo | Valore | Altro |
|---|---|---|
| 2025-01-06T00:00:00Z | 10 | -1 |
| 2025-01-13T00:00:00Z | 20 | -1 |
| 2025-01-20T00:00:00Z | 0 | -2 |
| 2025-01-27T00:00:00Z | 30 | -1 |
| 2025-02-03T00:00:00Z | 0 | -2 |