Illustrare il processo di data factory
Flussi di lavoro basati sui dati
Le pipeline, ovvero i flussi di lavoro basati su dati, in Azure Data Factory eseguono in genere i quattro passaggi seguenti:
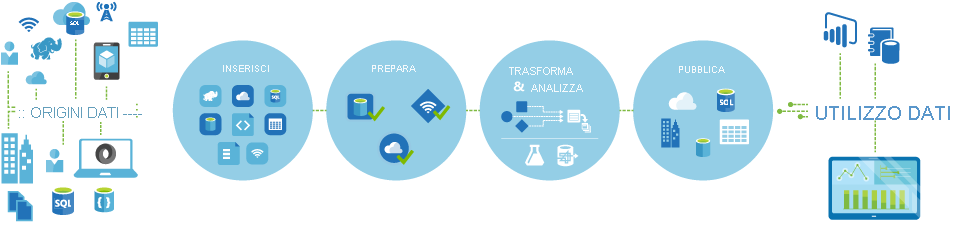
Connettersi e raccogliere
Il primo passaggio nella creazione di un sistema di orchestrazione consente ne definire e collegare tutte le origini dati richieste, come database, condivisioni file e servizi Web FTP. Il passaggio successivo consiste nell'inserire i dati necessari in una posizione centralizzata per l'elaborazione successiva.
Trasformare e arricchire
I servizi di calcolo, come Databricks e Machine Learning, possono essere usati per preparare o produrre dati trasformati in una pianificazione gestibile e controllata in modo da alimentare gli ambienti di produzione con dati puliti e trasformati. In alcuni casi è anche possibile integrare i dati di origine con dati aggiuntivi per facilitare l'analisi o consolidarli tramite un processo di normalizzazione da usare in un esperimento di Machine Learning come esempio.
Pubblica
Dopo che i dati non elaborati sono stati ottimizzati in un formato utilizzabile e pronto per l'azienda tramite la fase di trasformazione e arricchimento, è possibile caricare i dati in Azure Data Warehouse, nel database SQL di Azure, in Azure Cosmos DB o in qualsiasi motore di analisi a cui gli utenti aziendali possono fare riferimento dai propri strumenti di Business Intelligence.
Monitoraggio
Azure Data Factory ha il supporto incorporato per il monitoraggio delle pipeline tramite Monitoraggio di Azure, API, PowerShell, log di Monitoraggio di Azure e i pannelli di integrità nel portale di Azure, per monitorare le percentuali di esito positivo e negativo delle attività e delle pipeline pianificate.