Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Introduzione
I partner Microsoft, inclusi fornitori di software indipendenti (ISV) come se stessi, possono creare soluzioni di intelligenza artificiale generative tramite diversi approcci pro-code e low-code. Per supportare l'utente in questo processo, Microsoft sta creando indicazioni per gli ISV per consentire di creare meglio queste soluzioni.
Poiché gli ISV puntano a gestire query e attività specializzate, aumenta la complessità delle soluzioni di intelligenza artificiale generative. Queste complesse soluzioni di intelligenza artificiale generative richiedono precauzioni uniche durante lo sviluppo e il monitoraggio e l'osservazione coerenti in tutta la produzione. Osservando il comportamento e gli output del prodotto, è possibile identificare rapidamente le aree per la crescita, risolvere tempestivamente i rischi e i problemi e migliorare ulteriormente le prestazioni per l'applicazione.
Creazione e messa in funzione di applicazioni copilote
Per comprendere come l'osservabilità influisce sull'applicazione dall'inizio del ciclo di vita della soluzione, è fondamentale considerare il ciclo di vita in tre fasi principali: ideazione del caso d'uso, creazione della soluzione e messa in funzione per l'uso dopo la distribuzione.
Immagine intitolata Ciclo di vita LLM nel mondo reale. È composto da tre cerchi, collegati con frecce e circondati da una freccia più grande con etichetta "gestione". Il primo cerchio viene etichettato come "Ideating/Exploring" e include "try prompts", "Hypothesis" e "Find LLMs". Deriva dalla freccia dell'esigenza aziendale ed è collegata al secondo cerchio con una freccia con etichetta "progetto di avanzamento". Il secondo cerchio è contrassegnato come "Compilazione/aumento" ed è composto da "generazione aumentata di recupero", "gestione delle eccezioni", "progettazione richiesta o ottimizzazione avanzata" e "valutazione". Il secondo cerchio si connette all'ultimo cerchio con "prepararsi per la distribuzione dell'app". L'ultimo cerchio è il più grande, viene etichettato come "operazionalizzazione" ed è costituito da "distribuire app/interfaccia utente LLM", "quota e gestione dei costi", "filtro del contenuto", "implementazione/staging sicura" e "monitoraggio". L'ultimo cerchio è collegato al secondo cerchio con "invia feedback", mentre il secondo è connesso al primo con 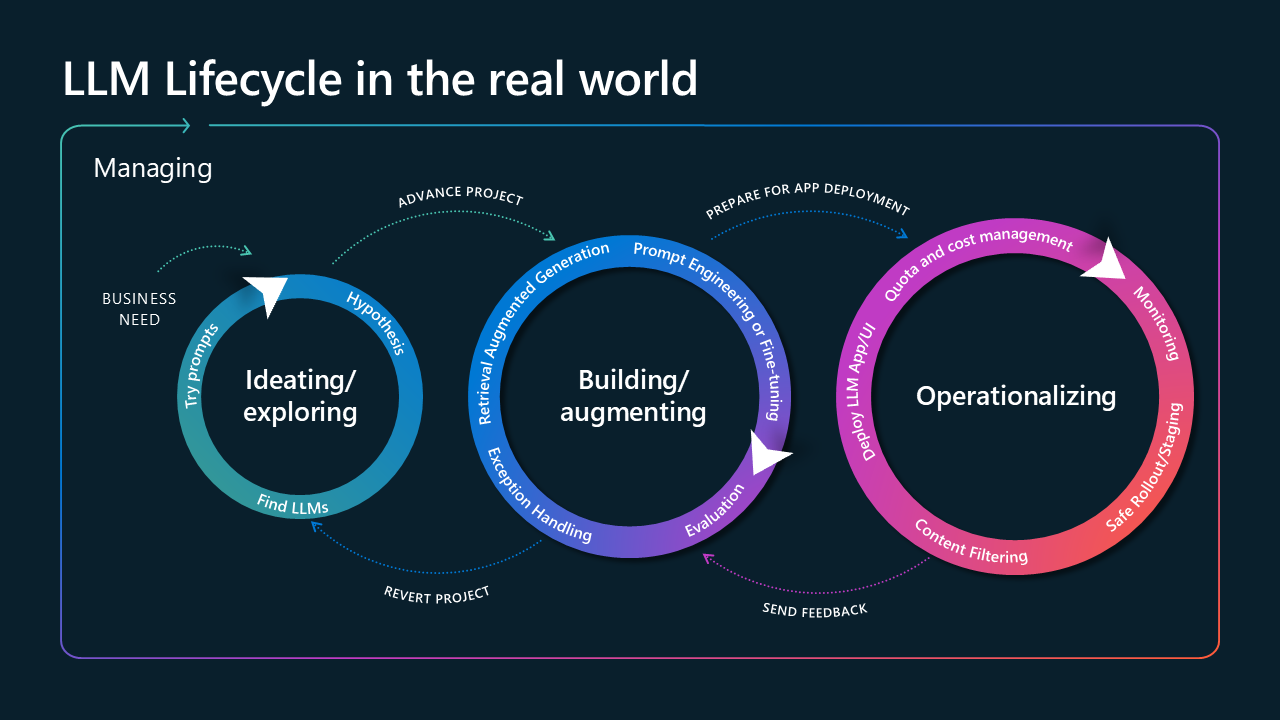
La prima fase è costituita dall'identificazione del caso d'uso e dall'ideazione di approcci tecnologici per crearlo. Dopo aver identificato un percorso per la compilazione dell'applicazione, si entra nella seconda fase, costituita dallo sviluppo e dalla valutazione dell'applicazione. Dopo aver distribuito l'applicazione nell'ambiente di produzione, entra nell'ultima fase, in cui può essere osservata e aggiornata.
Le informazioni dettagliate sull'osservabilità ottenute dalla seconda e dalla terza fase diventano fondamentali quando tornano alle fasi precedenti per eseguire aggiornamenti e distribuzioni. Eseguendo test continui e recuperando metriche per informare i processi precedenti, è possibile ottimizzare l'applicazione.
È importante comprendere quali azioni è possibile eseguire per praticare l'osservabilità in diversi punti del processo. A livello generale, durante il ciclo di vita dell'applicazione vengono eseguite le azioni di osservabilità seguenti:
Prima fase
- Persone non tecniche come i product manager praticano l'osservabilità ideando le qualità chiave della loro applicazione.
- Gli stakeholder possono definire quali metriche sono più importanti per misurare le prestazioni dell'applicazione, ad esempio metriche di rischio e sicurezza, metriche di qualità o metriche di esecuzione.
- Teams può definire gli obiettivi per le metriche, ad esempio il coinvolgimento degli utenti e la gestione dei costi.
- Gli utenti tecnici si concentrano sull'identificazione di piattaforme, strumenti e metodi che possono abilitare con maggiore successo la compilazione dell'applicazione.
- Questo passaggio può includere la scelta di un modello da usare, la scelta di un modello linguistico di grandi dimensioni (LLM) e l'identificazione delle origini dati chiave da trarre.
Seconda fase
- Durante questa fase, gli sviluppatori e i data scientist possono impostare la propria soluzione in modo che sia facilmente monitorata e iterazione. Per promuovere l'osservabilità in un secondo momento, gli ISV possono:
- Creare set di dati golden e set di dati di conversazione a più turni automatizzati per la valutazione copilota.
- Eseguire, eseguire e valutare il flusso con un subset di dati.
- Creare varianti per la valutazione del modello con richieste diverse.
- Eseguire i prezzi e l'ottimizzazione delle risorse per ridurre i costi LLM per eseguire l'iterazione e la compilazione.
- Gli sviluppatori si concentrano sull'esecuzione di esperimenti in tutto lo sviluppo e sulla valutazione della qualità dell'applicazione prima di distribuirla nell'ambiente di produzione. Durante questa fase, è fondamentale:
- Valutare le prestazioni complessive dell'applicazione con set di dati di test usando metriche predefinite, tra cui il modello e l'efficacia della richiesta.
- Confrontare i risultati di questi test, stabilire una linea di base e quindi distribuire il codice nell'ambiente di produzione.
Terza fase
- Molti esperimenti vengono eseguiti mentre l'applicazione viene usata attivamente nell'ambiente di produzione. È importante monitorare la soluzione per assicurarsi che funzioni in modo adeguato. Durante questa fase:
- La strumentazione dei dati di telemetria incorporata nell'app genera tracce, metriche e log pertinenti.
- I servizi cloud generano integrità OpenAI di Azure e altre metriche pertinenti.
- L'archiviazione di telemetria personalizzata contiene dati su tracce, metriche, log, utilizzo, consenso e altre metriche pertinenti.
- Le esperienze predefinite del dashboard consentono agli sviluppatori, ai data scientist e agli amministratori di monitorare le prestazioni e l'integrità del sistema delle API LLM nell'ambiente di produzione.
- Il feedback degli utenti finali viene inviato agli sviluppatori e ai data scientist per la valutazione per migliorare la soluzione.
La raccolta di dati e dati di telemetria offre informazioni dettagliate sulle aree da affrontare e migliorare in futuro. Eseguendo passaggi preliminari durante la fase di ideazione, ad esempio l'identificazione delle metriche appropriate e l'esecuzione di valutazioni rigorose della soluzione durante la compilazione dell'applicazione, è possibile preparare la soluzione per il successo in un secondo momento.
Sfide di osservabilità nell'intelligenza artificiale generativa
Anche se l'osservabilità in generale può richiedere agli ISV di superare molti ostacoli, le soluzioni di intelligenza artificiale generative introducono considerazioni e sfide specifiche.
Valutazione qualitativa
Poiché le risposte alle richieste di intelligenza artificiale generative vengono fornite in formato linguaggio naturale, devono essere valutate in modo univoco. Ad esempio, possono essere controllati per verificare le qualità, ad esempio la terra e la pertinenza.
Gli ISV devono considerare la route migliore per misurare queste qualità, sia che scelgano metriche manuali di valutazione o di intelligenza artificiale con un essere umano nel ciclo per la convalida finale.
Indipendentemente dal modo in cui viene valutata, è probabile che siano necessari set di dati preesistenti per confrontare le risposte alle richieste. Queste operazioni di preparazione possono comportare più lavoro durante lo sviluppo dell'applicazione, in quanto si identifica una risposta ideale agli argomenti di richiesta comuni.
Intelligenza artificiale responsabile
Nuove considerazioni e aspettative per l'IA etica introducono la necessità di monitorare privacy, sicurezza, inclusione e altro ancora. Gli ISV devono monitorare questi attributi per promuovere la sicurezza dell'utente finale, ridurre i rischi e ridurre al minimo le esperienze utente negative.
I sei principi dell'IA responsabile di Microsoft aiutano a promuovere sistemi di IA sicuri, etici e affidabili. Per promuovere questi valori all'interno della soluzione, la valutazione dell'applicazione rispetto a questi standard è fondamentale.
Metriche di monitoraggio dei costi e utilizzo
I token sono l'unità di misura principale per le applicazioni di intelligenza artificiale generativa e tutte le richieste e le risposte vengono tokenizzate in modo che possano essere misurate. Tenere traccia del numero di token usati è essenziale, perché influisce sul costo per l'esecuzione dell'applicazione.
Metriche dell'utilità
Il monitoraggio della soddisfazione degli utenti e dell'impatto aziendale dell'applicazione è fondamentale come le metriche di prestazioni o qualità. Poiché l'intelligenza artificiale interagisce con i clienti in modi diversi, esistono nuove considerazioni per il monitoraggio dell'engagement e della conservazione dei clienti.
Misurare l'utilità delle risposte dell'intelligenza artificiale può essere eseguita in molti modi diversi. Ad esempio, i imbuti di richiesta e risposta tengono traccia del tempo necessario per l'interazione per ottenere una risposta utilizzabile o utile. È anche importante prendere in considerazione il rilevamento del tempo in cui l'utente interagisce con l'intelligenza artificiale, la lunghezza della conversazione e il numero di volte in cui l'utente accetta la risposta fornita. Negli scenari in cui l'utente può modificare la risposta, è essenziale misurare la distanza di modifica o la misura in cui modificano la risposta.
Metriche delle prestazioni
L'IA richiede sistemi sempre più complessi e ad alte prestazioni che devono essere gestiti correttamente per garantire che la soluzione possa elaborare in modo rapido ed efficiente richieste e dati. Poiché l'intelligenza artificiale generativa crea contenuti qualitativi con un elevato grado di varietà, è importante disporre di sistemi per valutare e testare l'intelligenza artificiale in scenari diversi.
Poiché le interazioni LLM sono più complesse di un'applicazione tipica, devono essere misurate a più livelli per identificare i problemi con latenza. Ad esempio, i tempi di tokenizzazione della richiesta dell'utente, la generazione di una risposta e la restituzione della risposta a un utente possono essere misurate separatamente o nel suo complesso. Ogni singolo componente del flusso di lavoro deve essere valutato per identificare le aree per i potenziali problemi.
La possibilità di osservare la soluzione dipende anche dal metodo di distribuzione. Gli ISV adottano in genere uno dei due modelli di distribuzione per le applicazioni copilote. È possibile distribuire e gestire le applicazioni in un ambiente proprietario o distribuire applicazioni in un ambiente appartenente ai clienti.
Per altre informazioni sul modo in cui la distribuzione influisce sull'osservabilità tra i tipi di soluzioni, vedere la guida all'osservabilità del codice.
Metriche da monitorare e valutare
Nell'area di autenticazione ISV delle applicazioni di intelligenza artificiale generative e dei modelli di Machine Learning, è importante valutare continuamente la soluzione e intervenire tempestivamente per limitare i comportamenti indesiderati. Il monitoraggio delle metriche correlate all'esperienza utente o al feedback, alle protezioni e all'intelligenza artificiale responsabile, alla coerenza dell'output, alla latenza e ai costi è essenziale per ottimizzare le prestazioni delle applicazioni copilot.
Valutazione qualitativa con metriche assistita dall'intelligenza artificiale
Per misurare le informazioni qualitativhe, gli ISV possono usare le metriche assistita dall'intelligenza artificiale per monitorare le proprie soluzioni. Le metriche assistita dall'intelligenza artificiale usano LEM come GPT-4 per valutare le metriche in modo analogo al giudizio umano, che offre un input più dettagliato sulle funzionalità della soluzione.
Queste metriche richiedono in genere parametri come la domanda, la risposta e qualsiasi contesto circostante dalla conversazione. In generale rientrano in due categorie:
- Monitoraggio delle metriche di rischio e sicurezza per contenuti ad alto rischio, ad esempio violenza, autolesionismo, contenuto sessuale e contenuto odioso
- Le metriche di qualità di generazione tengono traccia delle misurazioni qualitativhe, ad esempio:
- Base del modo in cui la risposta del modello è allineata con le informazioni del prompt o dell'origine di input.
- Pertinenza: la risposta del modello è correlata alla richiesta originale.
- Coerenza: la misura in cui la risposta del modello è comprensibile e simile a quella umana.
- Fluency: le lingue, la grammatica e la sintassi della risposta del modello.
Le metriche come queste consentono agli ISV di valutare più facilmente la qualità delle risposte dell'applicazione. Forniscono una valutazione rapida e misurabile di molti valori diversi che possono essere difficili da interpretare.
Standard di IA responsabili
Microsoft si impegna a rispettare gli standard per l'IA responsabile. Per supportare questo problema, è stato stabilito un set di standard di IA responsabile che consentono di attenuare i rischi associati all'IA generativa:
- Responsabilità
- Trasparenza
- Equità
- Inclusività
- Affidabilità e sicurezza
- Privacy e sicurezza
Gli ISV possono monitorare le metriche che li notificano quando si verifica un problema. Queste notifiche possono includere metriche qualitativamente assistita dall'intelligenza artificiale che visualizzano risposte o richieste di contenuti dannosi o avvisi ISV per determinati errori o messaggi contrassegnati.
Ad esempio, Azure OpenAI offre soluzioni in grado di misurare la percentuale di richieste filtrate e risposte che non hanno restituito contenuto a causa del filtro del contenuto. Gli ISV devono monitorare le richieste che restituiscono questi errori e hanno lo scopo di ridurre la quantità che si verificano.
Utilizzo e soddisfazione dei clienti
Alcune funzionalità di intelligenza artificiale possono essere monitorate in modo analogo ad altri tipi di applicazioni, ad esempio il monitoraggio della conservazione dei clienti e del tempo dedicato all'uso dell'applicazione. Esistono tuttavia molte differenze nel monitoraggio della soddisfazione dei clienti che si applicano in modo specifico all'IA:
- Reazione dell'utente alla risposta. Questa operazione può essere misurata tramite metriche semplici come se un utente reagisce a una risposta con un pollice verso l'alto o verso il basso.
- Modifiche dell'utente alla risposta. Negli scenari in cui l'utente può modificare la risposta dell'intelligenza artificiale in base alle proprie esigenze, è possibile ottenere informazioni dettagliate monitorando la quantità di modifica della risposta da parte dell'utente. Ad esempio, un messaggio di posta elettronica bozza che l'utente ha modificato drasticamente non era utile come un messaggio di posta elettronica bozza inviato così come è.
- Utilizzo della risposta da parte dell'utente. Valutare se l'utente esegue un'azione tramite l'applicazione in risposta all'intelligenza artificiale. Se un'intelligenza artificiale suggerisce di eseguire un'azione tramite l'applicazione, misurare la frequenza degli utenti che accettano il suggerimento.
L'obiettivo di molte applicazioni di intelligenza artificiale è creare una risposta che l'utente trova utile. L'uso di un imbuto di richiesta e risposta è un modo comune per misurare la velocità con cui la soluzione può generare una risposta utile. Questo imbuto misura la quantità di tempo e le interazioni necessarie per la soluzione per creare una risposta con cui l'utente mantiene o termina la conversazione.
In questo concetto, l'imbuto inizia quando un utente invia una richiesta. Man mano che l'intelligenza artificiale genera risposte con cui l'utente può interagire, l'imbuto si restringe man mano che le risposte si avvicinano a ciò che l'utente vuole. Ad esempio, l'utente può modificare la risposta di intelligenza artificiale o richiedere una risposta leggermente diversa. Una volta che l'utente è soddisfatto dell'interazione, ha le informazioni specifiche che stava cercando e termina l'imbuto. La misurazione del numero di interazioni necessarie per passare da ampia a utile e specifica è utile per determinare l'efficacia dell'applicazione per il cliente.
Osservando il modo in cui gli utenti interagiscono con la soluzione, è possibile fare inferenze su quanto sia utile l'applicazione. Se gli utenti usano in modo coerente gli output di LLM senza eseguire altre azioni, è probabile che la risposta sia stata utile per loro.
Monitoraggio dei costi
Poiché le risorse necessarie per eseguire un'applicazione di intelligenza artificiale generativa possono aggiungere rapidamente, è essenziale osservarle in modo coerente.
Alcune aree che possono influire sull'ottimizzazione dei costi dell'applicazione includono:
- Utilizzo della GPU
- Costi e considerazioni sull'archiviazione
- Considerazioni sulla scalabilità
Garantire visibilità su queste metriche può aiutare a mantenere sotto controllo i costi, mentre la configurazione di sistemi di avviso o processi automatici correlati a queste metriche può essere utile anche per richiedere un'azione immediata.
Ad esempio, il numero di token di richiesta e completamento usati dall'applicazione influisce direttamente sull'utilizzo della GPU e sul costo per gestire la soluzione. Monitorare attentamente l'utilizzo dei token e configurare avvisi se supera determinate soglie può aiutare a rimanere consapevoli del comportamento dell'applicazione.
Disponibilità e prestazioni della soluzione
Come per tutte le soluzioni, il monitoraggio coerente delle applicazioni di intelligenza artificiale può contribuire a migliorare un livello elevato di prestazioni. Una delle principali differenze tra le applicazioni di intelligenza artificiale generative e altre è il concetto di tokenizzazione, che deve essere considerato quando si misurano le prestazioni.
Gli ISV che creano soluzioni di intelligenza artificiale generative possono misurare:
- Ora di rendering del primo token
- Token di cui è stato eseguito il rendering al secondo
- Richieste al secondo che l'applicazione può gestire
Anche se tutte queste metriche possono essere misurate come un gruppo, è anche importante notare che le macchine virtuali hanno più livelli. Ad esempio, il tempo necessario per generare una risposta da parte dell'intelligenza artificiale è costituito dal tempo necessario per:
- Ricevere la richiesta dall'utente
- Elaborare la richiesta tramite la tokenizzazione
- Dedurre eventuali informazioni mancanti pertinenti
- Generare una risposta
- Compilare queste informazioni in una risposta tramite detokenizzazione
- Inviare di nuovo questa risposta all'utente
La misurazione di ognuno di questi passaggi consente di identificare i ritardi e la posizione in cui si verificano, consentendo di risolvere il problema all'origine.
Altre tecniche di valutazione dell'intelligenza artificiale generative
Set di dati golden
Un Golden Dataset è una raccolta di risposte di esperti alle domande utente realistiche usate per fornire una garanzia di qualità copilota. Queste risposte non vengono usate per eseguire il training del modello, ma possono essere confrontate con le risposte fornite dal modello alla stessa domanda dell'utente.
Anche se non è una metrica che è possibile misurare, avere una risposta standardizzata di alta qualità, è possibile confrontare le risposte di LLM per aiutare gli output della soluzione. In questo modo, la creazione di set di dati Golden Data per la valutazione delle prestazioni di copilot consente di accelerare il processo di valutazione copilota.
Simulazione di conversazioni a più turni
La cura manuale dei set di dati di valutazione può essere principalmente limitata alle conversazioni a turno singolo a causa della difficoltà di creare chat a più turni naturali. Invece di scrivere interazioni con script per confrontare le risposte del modello, gli ISV possono sviluppare conversazioni simulate per testare le capacità di conversazione a più turni del copilot.
Questa simulazione può generare un dialogo consentendo all'intelligenza artificiale di interagire con un utente virtuale semplice. Questo utente interagirà quindi con l'intelligenza artificiale tramite uno script pregenerato di prompt o li genera tramite intelligenza artificiale, consentendo di creare un numero elevato di conversazioni di test da valutare. È anche possibile usare analizzatori umani per interagire con l'applicazione e generare conversazioni più lunghe da esaminare.
Valutando le interazioni dell'applicazione all'interno di una conversazione più lunga, è possibile valutare in che modo identifica in modo efficace la finalità dell'utente e usa il contesto in tutta la conversazione. Poiché molte soluzioni di intelligenza artificiale generative sono concepite per basarsi su più interazioni utente, è essenziale valutare il modo in cui l'applicazione gestisce le conversazioni a più turni.
Strumenti di sviluppo per iniziare
Gli sviluppatori ISV e i data scientist devono usare strumenti e metriche per valutare le soluzioni LLM. Microsoft offre molte opzioni disponibili per l'esplorazione.
Studio AI della piattaforma Azure
Azure AI Studio offre funzionalità di osservabilità per la gestione dei modelli, i benchmark dei modelli, la traccia, la valutazione e l'ottimizzazione della soluzione LLM.
Supporta due tipi di metriche automatizzate per valutare le applicazioni di intelligenza artificiale generative: le metriche di Machine Learning tradizionali e le metriche assistita dall'intelligenza artificiale. È anche possibile usare il playground di chat e le funzionalità correlate per testare facilmente il modello.
Prompt flow
Flusso prompt è una suite di strumenti di sviluppo progettati per semplificare il ciclo di sviluppo end-to-end delle applicazioni di intelligenza artificiale basate su LLM, dalla creazione di prototipi e test, alla distribuzione e al monitoraggio. L'SDK del flusso di richiesta fornisce:
- Analizzatori predefiniti che supportano analizzatori personalizzati basati su codice o basati su prompt tramite Prompty per soddisfare le esigenze di valutazione specifiche dell'attività.
- Traccia prompt che tiene traccia degli input, degli output e del contesto delle richieste e consente agli sviluppatori di identificare le cause e le origini dei problemi del modello
- Monitoraggio dei dashboard, inclusi il sistema (ad esempio, l'utilizzo dei token, latenza) e le metriche personalizzate dalla valutazione per supportare l'osservabilità preliminare e post-distribuzione in Azure AI Studio e Application Insights.
Altri strumenti
Prompty è una classe di asset indipendente dal linguaggio per la creazione e la gestione delle richieste LLM. Consente di velocizzare il processo di sviluppo fornendo opzioni per progettare, testare e migliorare le soluzioni.
PyRIT (Python Risk Identification Tool for Generative AI) è il framework di automazione aperto di Microsoft per sistemi di intelligenza artificiale generativi di red-team. Consente di valutare l'affidabilità dei copiloti contro diverse categorie di danni.
Passaggi successivi
Progettando l'applicazione di intelligenza artificiale generativa tenendo presente l'osservabilità e il monitoraggio, è possibile valutarne la qualità dallo sviluppo attraverso la produzione. Introduzione agli strumenti disponibili per iniziare a sviluppare l'applicazione o esplorare le opzioni per il monitoraggio di una soluzione già in produzione.
Risorse aggiuntive
How to Evaluate LLMs: A Complete Metric Framework - Microsoft Research
Altre indicazioni sulla valutazione dell'applicazione LLM
Introduzione al flusso di richiesta - Azure Machine Learning | Microsoft Learn
Informazioni sulla configurazione e l'inizio dell'uso del flusso di richiesta