Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  Azure Machine Learning
Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere le informazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Altre informazioni su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
In questo articolo è possibile ottenere informazioni sulle metriche che è possibile usare per monitorare le prestazioni del modello in Machine Learning Studio (versione classica). La valutazione delle prestazioni di un modello è una delle fasi principali nel processo di analisi scientifica dei dati. Indica quanto sia stata efficace la valutazione del punteggio (previsioni) di un set di dati da parte di un modello addestrato. Machine Learning Studio (versione classica) supporta la valutazione del modello tramite due dei moduli principali di Machine Learning:
Questi moduli consentono all'utente di osservare le prestazioni del proprio modello in termini di una serie di metriche comunemente usate in Machine Learning e nella statistica.
La valutazione dei modelli deve essere considerata insieme a:
L'argomento presenta inoltre tre scenari di apprendimento sorvegliato comuni:
- Regressione
- Classificazione binaria
- Classificazione multiclasse
Confronto tra la valutazione e la convalida incrociata
La valutazione e la convalida incrociata sono due modi standard di misurare le prestazioni del proprio modello. Entrambi generano metriche di valutazione che l'utente può usare per controllare o mettere a confronto quelle di altri modelli.
Evaluate Model prevede un set di dati con punteggio come input (o due nel caso in cui si voglia confrontare le prestazioni di due modelli diversi). È quindi necessario addestrare il modello usando il modulo Train Model e fare previsioni su un set di dati usando il modulo Score Model prima di poter valutare i risultati. La valutazione si basa sulle etichette/probabilità con punteggio insieme alle etichette vere, tutte restituite dal modulo Score Model .
In alternativa, è possibile utilizzare la convalida incrociata per eseguire automaticamente una serie di operazioni di training, punteggio e valutazione (10 ripetizioni) su diversi subset di dati di input. I dati di input vengono suddivisi in dieci partizioni, di cui una riservata per la convalida e le rimanenti usate per eseguire il training. Tale processo si ripete per 10 volte e viene calcolata una media delle metriche di valutazione. Ciò consente di determinare come verrebbero generalizzati nuovi set di dati da un modello. Il modulo Cross-Validate Model accetta un modello non addestrato e un insieme di dati etichettati e restituisce i risultati della valutazione di ognuna delle 10 suddivisioni, oltre ai risultati medi.
Nelle sezioni seguenti verranno compilati modelli di regressione e classificazione semplici e ne verranno valutate le prestazioni usando i moduli Evaluate Model e Cross-Validate Model .
Valutazione di un modello di regressione
Si supponga di voler stimare il prezzo di un'auto usando caratteristiche come dimensioni, potenza, specifiche del motore e così via. Si tratta di un tipico problema di regressione, in cui la variabile di destinazione (prezzo) è un valore numerico continuo. È possibile adattare un modello di regressione lineare che, in base ai valori di funzionalità di una determinata auto, può prevedere il prezzo di tale auto. Questo modello di regressione può essere usato per calcolare il punteggio dello stesso set di dati su cui si sta effettuando il training Dopo aver ottenuto i prezzi stimati delle automobili, è possibile valutare le prestazioni del modello esaminando quanto le stime deviano dai prezzi effettivi in media. Per illustrare questo problema, viene usato il set di dati Automobile price data (Raw) disponibile nella sezione Set di dati salvati in Machine Learning Studio (versione classica).
Creazione di un esperimento
Aggiungere i moduli seguenti all'area di lavoro in Machine Learning Studio (versione classica):
- Dati sui prezzi delle automobili (Raw)
- Regressione lineare
- Eseguire il training del modello
- Assegnare un punteggio al modello
- Valutare il modello
Connettere le porte come illustrato di seguito nella figura 1 e impostare la colonna Etichetta del modulo Train Model su prezzo.
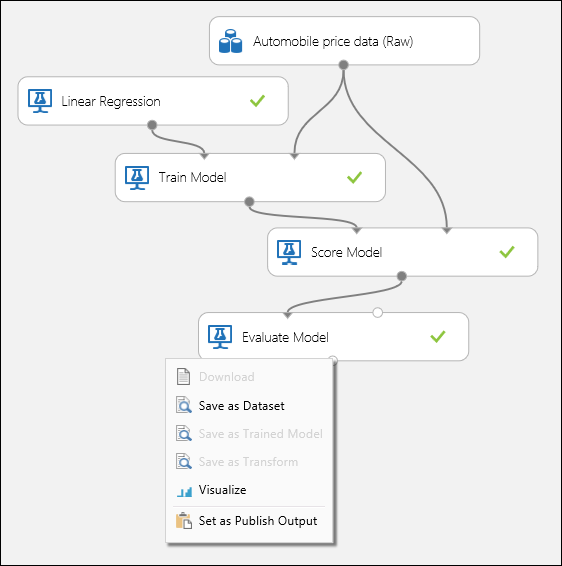
Figura 1. Valutazione di un modello di regressione.
Controllo dei risultati di valutazione
Dopo aver eseguito l'esperimento, è possibile fare clic sulla porta di output del modulo Evaluate Model (Valuta modello ) e selezionare Visualize (Visualizza ) per visualizzare i risultati della valutazione. Le metriche di valutazione disponibili per i modelli di regressione sono: errore assoluto medio, errore assoluto medio radice, errore assolutorelativo, errorequadratico relativo e coefficiente di determinazione.
In questo caso, il termine "errore" rappresenta la differenza tra il valore stimato e il valore reale. Il valore assoluto o il quadrato di questa differenza viene calcolato in genere per ottenere il margine totale dell'errore in tutte le istanze, poiché la differenza tra il valore stimato e quello reale potrebbe essere negativa in alcuni casi. Le metriche di errore misurano le prestazioni predittive di un modello di regressione in termini di deviazione media delle stime rispetto ai valori reali. Più i valori di errore sono bassi, più il modello effettua stime precise. Una metrica di errore complessivo pari a 0 indica che il modello corrisponde perfettamente ai dati.
Il coefficiente di determinazione, altrimenti noto come "valore quadratico R", rappresenta, inoltre, un modo standard di misurazione della percentuale di idoneità del modello rispetto ai dati. Può essere definito come la percentuale di variazione esplicitata dal modello. Una percentuale più elevata è migliore nel caso in cui 1 indica un'idoneità perfetta.
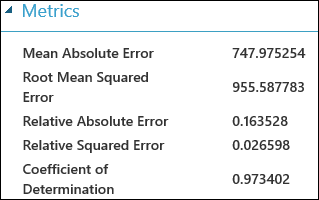
Figura 2. Metriche di valutazione della regressione lineare.
Uso della convalida incrociata
Come accennato in precedenza, è possibile eseguire automaticamente training, punteggio e valutazioni ripetute usando il modulo Cross-Validate Model . Tutto ciò che serve in questo caso è un set di dati, un modello non sottoposto a training e un modulo modello di convalida incrociata (vedere la figura seguente). È necessario impostare la colonna etichetta a prezzo nelle proprietà del modulo Cross-Validate Model.
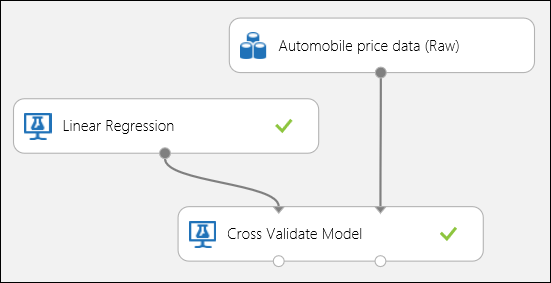
Figura 3. Esecuzione della convalida incrociata di un modello di regressione.
Dopo aver eseguito l'esperimento, è possibile esaminare i risultati della valutazione facendo clic sulla porta di output destra del modulo Cross-Validate Model. In questo modo viene fornita una visualizzazione dettagliata delle metriche di ciascuna iterazione (sezione) e i risultati medi di ciascuna delle metriche (figura 4).
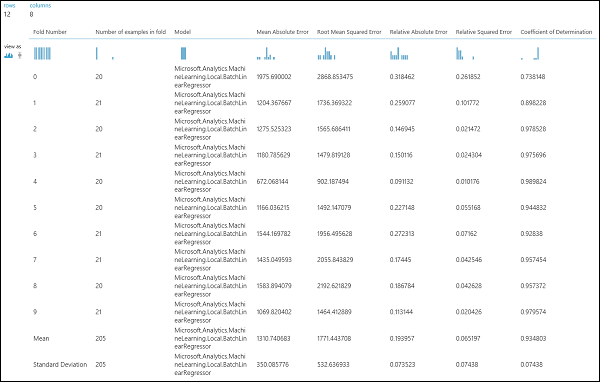
Figura 4. Risultati della convalida incrociata di un modello di regressione.
Valutazione di un modello di classificazione binaria
In uno scenario di classificazione binaria la variabile di destinazione ha solo due risultati possibili, ad esempio: {0, 1} o {false, true}, {negative, positive}. Si supponga di avere un set di dati di dipendenti adulti con alcune variabili demografiche e di occupazione e che venga richiesto di stimare il livello di reddito, una variabile binaria con i valori {"<=50 K", ">50 K"}. In altri termini, la classe negativa rappresenta il caso in cui il dipendente realizza un valore inferiore o uguale a 50.000 l'anno, mentre la classe positiva rappresenta tutti gli altri dipendenti. Come nello scenario della regressione, verrà eseguito il training di un modello, verrà calcolato il punteggio di alcuni dati e verranno valutati i risultati. La differenza principale qui è la scelta delle metriche che Machine Learning Studio (versione classica) calcola e produce. Per illustrare lo scenario di stima del livello di reddito, si userà il set di dati Adult per creare un esperimento di Studio (versione classica) e valutare le prestazioni di un modello di regressione logistica a due classi, un classificatore binario comunemente usato.
Creazione di un esperimento
Aggiungere i moduli seguenti all'area di lavoro in Machine Learning Studio (versione classica):
- Set di dati per la classificazione binaria del reddito nel censimento degli adulti
- Regressione logistica a due classi
- Eseguire il training del modello
- Assegnare un punteggio al modello
- Valutare il modello
Connettere le porte come illustrato di seguito nella figura 5 e impostare la colonna Etichetta del modulo Train Model su income.
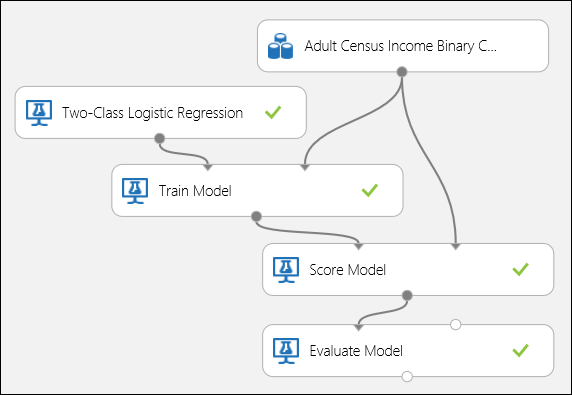
Figura 5. Valutazione di un modello di classificazione binaria.
Controllo dei risultati di valutazione
Dopo aver eseguito l'esperimento, è possibile fare clic sulla porta di output del modulo Evaluate Model (Valuta modello ) e selezionare Visualize (Visualizza ) per visualizzare i risultati della valutazione (Figura 7). Le metriche di valutazione disponibili per i modelli di classificazione binaria sono: Accuratezza, Precisione, Richiamo, Punteggio F1 e AUC. Inoltre, il modulo restituisce una matrice di confusione che mostra il numero di veri positivi, falsi negativi, falsi positivi e veri negativi, nonché curve ROC, curve di Precisione/Richiamo e curve Lift.
L'accuratezza è semplicemente la percentuale delle istanze classificate correttamente. In genere è la prima metrica che viene osservata quando si valuta un classificatore. Tuttavia, quando i dati di test sono sbilanciati (dove la maggior parte delle istanze appartiene a una delle classi) o si è più interessati alle prestazioni su una delle classi, l'accuratezza non acquisisce effettivamente l'efficacia di un classificatore. Nello scenario di classificazione del livello di reddito, si supponga di eseguire il test di alcuni dati in cui il 99% delle istanze rappresenta le persone che guadagnano una cifra inferiore o uguale a 50.000 l'anno. È possibile ottenere un'accuratezza di 0,99 stimando la classe "<=50K" per tutte le istanze. In questo caso sembra che il classificatore svolga un buon lavoro in linea generale, ma in realtà non è in grado di classificare correttamente gli individui con un reddito superiore (il restante 1%).
Per questo motivo è utile calcolare metriche aggiuntive che raccolgano aspetti più specifici della valutazione. Prima di entrare nei dettagli di tali metriche, è importante comprendere la matrice di confusione della valutazione di una classificazione binaria. Le etichette di classe nel set di training possono assumere solo due valori possibili, a cui in genere si fa riferimento come positivo o negativo. Le istanze positive e negative stimate correttamente da un classificatore si definiscono rispettivamente valori veri positivi (VP) e veri negativi (VN). Analogamente, le istanze classificate in modo errato si definiscono valori falsi positivi (FP) e falsi negativi (FN). La matrice di confusione è semplicemente una tabella che mostra il numero di istanze che rientrano in ognuna di queste quattro categorie. Machine Learning Studio (versione classica) decide automaticamente quale delle due classi nel set di dati è la classe positiva. Se le etichette di classe sono valori booleani o interi, alle istanze con etichetta 'true' o '1' viene assegnata la classe positiva. Se le etichette sono stringhe, ad esempio con il set di dati income, le etichette vengono ordinate alfabeticamente e il primo livello viene scelto come classe negativa mentre il secondo livello è la classe positiva.
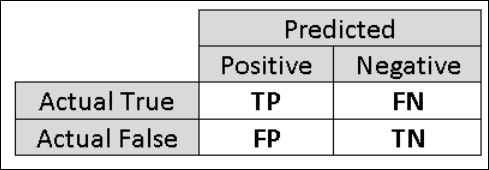
Figura 6. Matrice di confusione di classificazione binaria.
Tornando al problema della classificazione del reddito, di seguito vengono fornite alcune domande sulla valutazione, utili a comprendere le prestazioni del classificatore usato. Una domanda naturale è: "Fuori dalle persone che il modello ha previsto di guadagnare >50 K (TP+FP), quanti sono stati classificati correttamente (TP)?' Questa domanda può essere risolta esaminando la precisione del modello, ovvero la percentuale di positivi classificati correttamente: TP/(TP+FP). Un'altra domanda comune è "Tra tutti i dipendenti ad alto reddito con un reddito di >50k (TP+FN), quanti sono stati classificati correttamente dal classificatore (TP)". Questo è in realtà il richiamo, o il vero tasso positivo: TP/(TP+FN) del classificatore. Come si può notare, vi è un chiaro compromesso tra precisione e richiamo. Ad esempio, in presenza di un set di dati relativamente bilanciato, un classificatore che stima istanze soprattutto positive avrà un richiamo elevato ma una precisione più bassa, poiché molte delle istanze negative verranno classificate in modo errato dando come risultato una serie di falsi positivi. Per visualizzare un tracciato della variazione di queste due metriche, è possibile fare clic sulla curva PRECISIONE/RICHIAMo nella pagina di output dei risultati della valutazione (parte superiore sinistra della figura 7).
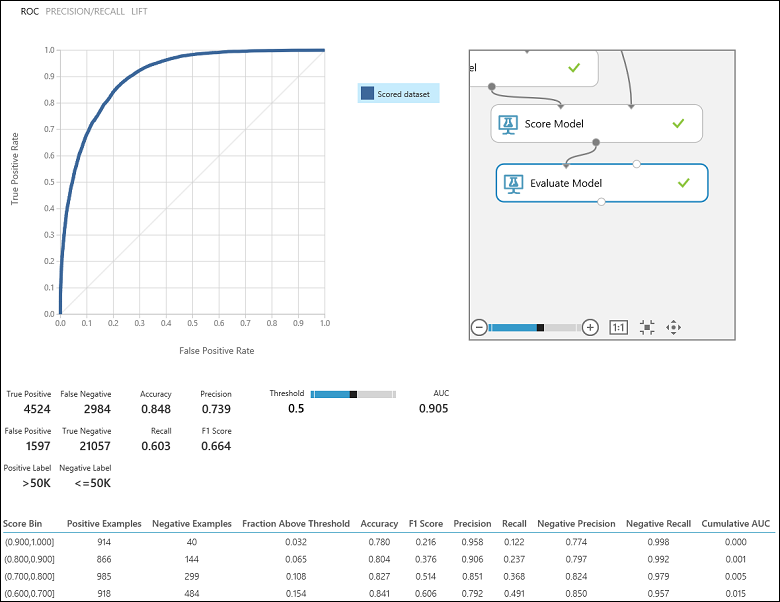
Figura 7. Risultati della valutazione della classificazione binaria.
Un'altra metrica correlata spesso usata è il punteggio F1, che prende in considerazione sia la precisione che il richiamo. È la media armonica di queste due metriche e viene calcolata come tale: F1 = 2 (precisione x richiamo) / (precisione + richiamo). Il punteggio F1 è un buon modo per riepilogare la valutazione in un singolo numero, ma è sempre consigliabile esaminare sia la precisione che il richiamo insieme per comprendere meglio il comportamento di un classificatore.
Inoltre, è possibile esaminare il tasso di veri positivi rispetto al tasso di falsi positivi nella curva ROC (Receiver Operating Characteristic) e il valore corrispondente dell'Area Sotto la Curva (AUC). Più questa curva è più vicina all'angolo superiore sinistro, migliore è la prestazione del classificatore (che sta massimizzando il tasso di vero positivo riducendo al minimo il tasso di falsi positivi). Le curve che si trovano vicino alla diagonale del tracciato risultano dai classificatori che tendono a fare delle stime al limite della casualità.
Uso della convalida incrociata
Come nell'esempio di regressione, è possibile eseguire la convalida incrociata per eseguire ripetutamente il training, il punteggio e valutare automaticamente diversi subset dei dati. Analogamente, si può utilizzare il modulo Cross-Validate Model, un modello di regressione logistica non addestrato e un set di dati. Nelle proprietà del modulo Cross-Validate Model, la colonna etichetta deve essere impostata su reddito. Dopo aver eseguito l'esperimento e aver fatto clic sulla porta di output destra del modulo Cross-Validate Model , è possibile visualizzare i valori delle metriche di classificazione binaria per ogni piega, oltre alla deviazione media e standard di ognuna.
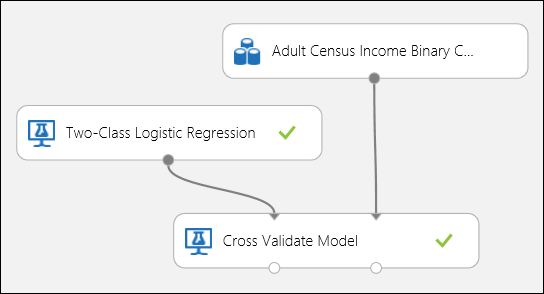
Figura 8. Convalida incrociata di un modello di classificazione binaria.
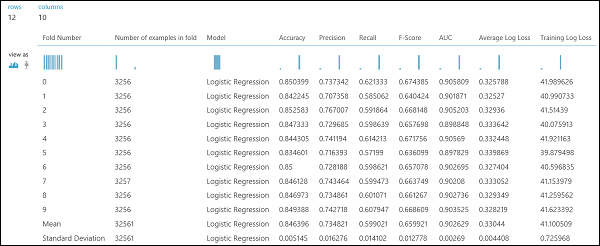
Figura 9. Risultati della convalida incrociata di un classificatore binario.
Valutazione di un modello di classificazione multiclasse
In questo esperimento si userà il popolare set di dati Iris , che contiene istanze di tre diversi tipi (classi) della pianta iris. Per ogni istanza sono disponibili quattro valori di funzionalità (lunghezza/larghezza e larghezza del petalo). Negli esperimenti precedenti è stato eseguito il training e il test dei modelli usando gli stessi set di dati. In questo caso, si userà il modulo Split Data per suddividere i dati in due subset, per addestrare sul primo e valutare il secondo. Il set di dati Iris è disponibile pubblicamente nel repository di Machine Learning UCI e può essere scaricato usando un modulo Importa dati .
Creazione di un esperimento
Aggiungere i moduli seguenti all'area di lavoro in Machine Learning Studio (versione classica):
- Importa dati
- Foresta delle decisioni multiclasse
- Divisione dei dati
- Eseguire il training del modello
- Assegnare un punteggio al modello
- Valutare il modello
Connettere le porte come mostrato in basso nella figura 10.
Impostare l'indice della colonna Label del modulo Train Model su 5. Il set di dati non dispone di una riga di intestazione ma, com'è noto, le etichette delle classi si trovano nella quinta colonna.
Fare clic sul modulo Importa dati e impostare la proprietà Origine dati su URL Web tramite HTTP e l'URL su http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Impostare la frazione di istanze da usare per il training nel modulo Split Data (ad esempio 0,7).
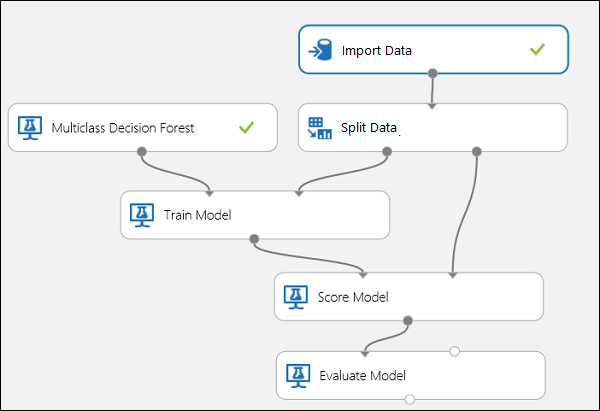
Figura 10. Valutazione di un classificatore multiclasse
Controllo dei risultati di valutazione
Esegui l'esperimento e fai clic sulla porta di output di Evaluate Model. In questo caso, i risultati di valutazione sono presentati nel formato di una matrice di confusione. La matrice mostra le istanze effettive e stimate per tutte e tre le classi.
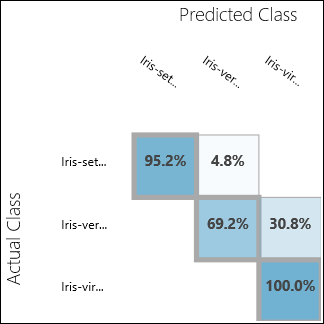
Figura 11. Risultati di valutazione della classificazione a più classi.
Uso della convalida incrociata
Come accennato in precedenza, è possibile eseguire automaticamente training, punteggio e valutazioni ripetute usando il modulo Cross-Validate Model . È necessario un set di dati, un modello non sottoposto a training e un modulo modello di convalida incrociata (vedere la figura seguente). Anche in questo caso è necessario impostare la colonna etichetta del modulo Modello di convalida incrociata (indice colonna 5 in questo caso). Dopo aver eseguito l'esperimento e aver fatto clic sulla porta di output destra del modello di convalida incrociata, è possibile esaminare i valori delle metriche per ogni piega, nonché la deviazione media e standard. Le metriche visualizzate sono simili a quelle illustrate nel caso della classificazione binaria. Tuttavia, nella classificazione multiclasse, il calcolo dei veri positivi/negativi e dei falsi positivi/negativi viene eseguito contando su base per classe, in quanto non esiste una classe positiva o negativa complessiva. Ad esempio, quando si calcola la precisione o il richiamo della classe "Iris-setosa", si presuppone che si tratti della classe positiva e di tutti gli altri come negativi.
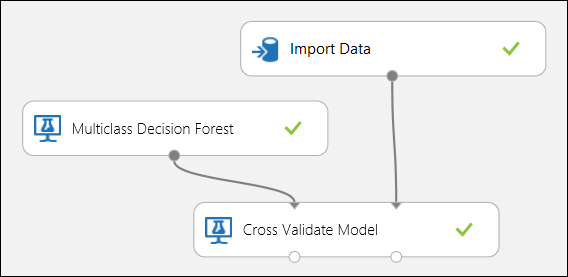
Figura 12. Convalida incrociata di un modello di classificazione a più classi.
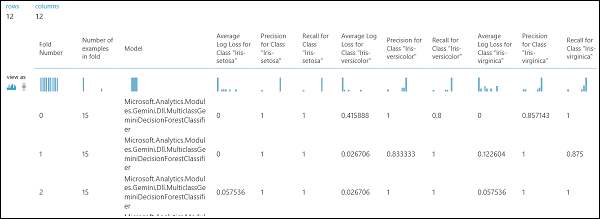
Figura 13. Risultati della convalida incrociata di un modello di classificazione multiclasse.