Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  di Azure Machine Learning
di Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere le informazioni sullo spostamento di progetti di apprendimento automatico da ML Studio (versione classica) ad Azure Machine Learning.
- Scoprire di più su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Questo argomento illustra come visualizzare e interpretare i risultati della stima in Machine Learning Studio (versione classica). Dopo aver eseguito il training di un modello e averlo sottoposto a una stima, ossia dopo aver assegnato un punteggio a un modello, è necessario comprendere e interpretare il risultato di stima.
Esistono quattro tipi principali di modelli di Machine Learning in Machine Learning Studio (versione classica):
- Classificazione
- Raggruppamento
- Regressione
- sistemi di raccomandazione
I moduli usati per eseguire stime sulla base di questi modelli sono:
- Modulo Score Model per la classificazione e la regressione
- Modulo di assegnazione ai cluster per l'organizzazione in cluster
- Modulo Score Matchbox Recommender per i sistemi di raccomandazione
Informazioni su come scegliere i parametri per ottimizzare gli algoritmi in ML Studio (versione classica).
Per informazioni su come valutare i modelli, vedere Come valutare le prestazioni del modello.
Se non si ha familiarità con ML Studio (versione classica), vedere come creare un semplice esperimento.
Classificazione
I problemi di classificazione possono essere suddivisi in:
- Problemi con solo due classi (classificazione a due classi o binaria)
- Problemi con più di due classi (classificazione multiclasse)
Machine Learning Studio (versione classica) include moduli diversi per gestire ognuno di questi tipi di classificazione, ma i metodi per interpretare i risultati della stima sono simili.
Classificazione a due classi
Esperimento di esempio
Un esempio di un problema di classificazione a due classi è costituito dalla classificazione dei fiori Iris, Il compito è classificare i fiori Iris in base alle loro caratteristiche. Il set di dati Iris fornito in Machine Learning Studio (versione classica) è un subset del popolare set di dati Iris contenente istanze di solo due specie di fiori (classi 0 e 1). Ciascun fiore presenta quattro caratteristiche: lunghezza del sepalo, larghezza del sepalo, lunghezza del petalo e larghezza del petalo.

Figura 1. Esperimento del problema di classificazione a due classi relativo ai fiori Iris
Per risolvere il problema è stato eseguito un esperimento, come illustrato nella figura 1. È stato addestrato e valutato un modello di albero decisionale con boosting a due classi. Per visualizzare i risultati di stima tramite il modulo Score Model, fare clic sulla porta di output del modulo Score Model e quindi fare clic su Visualize (Visualizza).
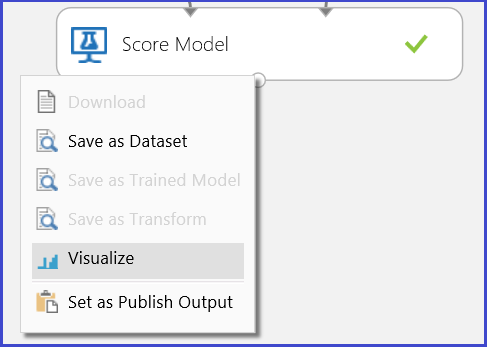
Vengono visualizzati i risultati dell'assegnazione del punteggio, come illustrato nella Figura 2.

Figura 2. Visualizza un risultato del modello di punteggio nella classificazione a due classi
Interpretazione dei risultati
Nella tabella dei risultati sono presenti sei colonne: Le quattro colonne sulla sinistra sono le quattro caratteristiche. Le due colonne di destra, Scored Labels (Etichette con punteggio) e Scored Probabilities (Probabilità con punteggio), sono i risultati predittivi. La colonna Scored Probabilities (Probabilità con punteggio) indica le probabilità che un fiore appartenga alla classe positiva (Classe 1). Il primo numero della colonna (0.028571) significa ad esempio che la probabilità che il primo fiore appartenga alla Classe 1 è pari a 0,028571. La colonna Scored Labels rappresenta invece la classe stimata per ogni fiore, Questa si basa sulla colonna Scored Probabilities. Se la probabilità calcolata di un fiore è superiore a 0,5, è predetto come Classe 1. In caso contrario, viene prevista la classe 0.
Pubblicazione come servizio Web
Dopo aver compreso e approvato i risultati della predizione, è possibile pubblicare l'esperimento come servizio web, in modo che possa essere distribuito in varie applicazioni e chiamato per ottenere predizioni di classe su un nuovo fiore di iris. Per informazioni su come modificare un esperimento di training in un esperimento di assegnazione dei punteggi e pubblicarlo come servizio Web, vedere Esercitazione 3: Distribuire il modello di rischio di credito. Questa procedura consente di ottenere un esperimento di assegnazione dei punteggi, come illustrato nella figura 3.

Figura 3. Esperimento di assegnazione dei punteggi per un problema di classificazione a due classi relativo ai fiori Iris
A questo punto è necessario impostare l'input e l'output per il servizio Web. L'input è la porta di input di destra del modulo Score Model, che corrisponde alle caratteristiche del fiore Iris. La scelta dell'output varia a seconda che si sia interessati a una classe stimata (etichetta valutata), a una probabilità stimata o a entrambe. In questo esempio si suppone di essere interessati a entrambe. Per selezionare le colonne di output desiderate, usare un modulo Select Columns in Data set. Clicca su Seleziona colonne nel set di dati, su Avvia selettore colonne, e seleziona Etichette con punteggio e Probabilità con punteggio. Dopo aver impostato la porta di output di Select Columns in Data set e averlo eseguito di nuovo, fare clic su PUBLISH WEB SERVICE (PUBBLICA SERVIZIO WEB) per provare a pubblicare l'esperimento di assegnazione dei punteggi. L'esperimento finale si presenta come nella figura 4.

Figura 4. Esperimento finale di punteggio per un problema di classificazione binaria dell'iris
Dopo aver eseguito il servizio Web e aver immesso alcuni valori funzione di un'istanza di test, il risultato sarà composto da due numeri: il primo numero rappresenta l'etichetta con punteggio e il secondo la probabilità con punteggio. Con una probabilità pari a 0,9655, si stima che il fiore appartenga alla Classe 1.
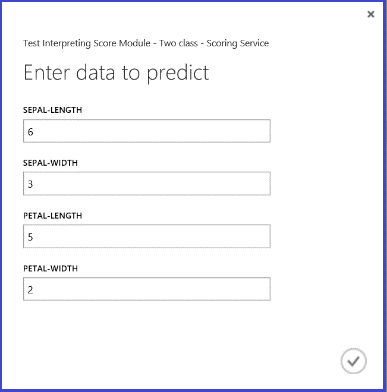

Figura 5. Risultato del servizio Web relativo alla classificazione a due classi dei fiori Iris
Classificazione multiclasse
Esperimento di esempio
In questo esperimento, esegui un'attività di riconoscimento di lettere come esempio di classificazione multiclasse. Il classificatore tenta di stimare una determinata lettera %28class%29 in base ad alcuni valori di attributo scritti a mano estratti dalle immagini scritte a mano.
Nei dati di training sono presenti 16 funzioni estratte da immagini di lettere scritte a mano. Le ventisei lettere formano le nostre ventisei classi. Nella figura 6 è illustrato un esperimento che eseguirà il training di un modello di classificazione multiclasse per il riconoscimento delle lettere e una stima dello stesso set di funzioni su un set di dati di test.
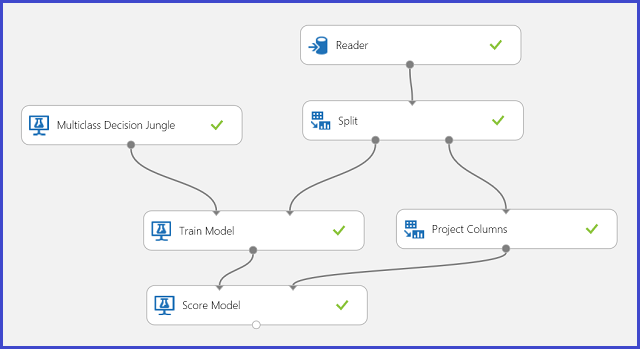
Figura 6. Esperimento per un problema di classificazione multiclasse relativo al riconoscimento delle lettere
Per visualizzare i risultati del modulo Score Model, fare clic sulla porta di output del modulo Score Model e quindi fare clic su Visualize, come illustrato nella figura 7.
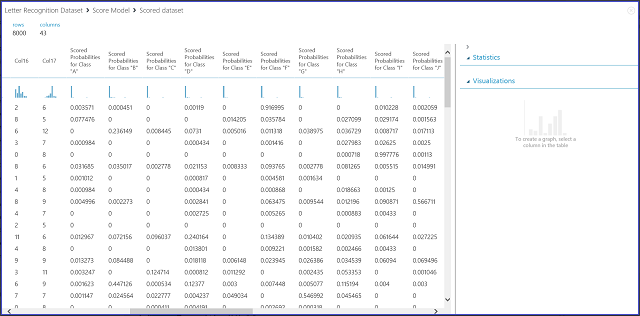
Figura 7. Visualizzare i risultati del modello di punteggio nella classificazione multiclasse
Interpretazione dei risultati
Le 16 colonne di sinistra rappresentano i valori delle caratteristiche del set di test. Le colonne denominate "Scored Probabilities for Class 'XX'" (Probabilità con punteggio per la classe "XX") corrispondono alla colonna "Scored Probabilities" (Probabilità con punteggio) nel caso di classificazione a due classi. Indicano infatti la probabilità che la voce corrispondente appartenga a una determinata classe. Ad esempio, per la prima voce, esiste una probabilità di 0,003571 che sia una "A", di 0,000451 che sia una "B" e così via. L'ultima colonna, denominata Etichette con punteggio, corrisponde alla colonna Scored Labels nella classificazione a due classi. Seleziona la classe con la probabilità calcolata più elevata come classe prevista per l'elemento corrispondente. Ad esempio, per la prima voce, l'etichetta valutata è "F" perché ha la probabilità più alta di essere "F" (0,916995).
Pubblicazione come servizio Web
È anche possibile ottenere l'etichetta con punteggio per ogni voce e la relativa probabilità. La logica di base è trovare la probabilità più alta tra tutte le probabilità con punteggio. A tale scopo, usare il modulo Execute R Script. Il codice R è illustrato nella figura 8, il risultato dell'esperimento nella figura 9.

Figura 8. Codice R per l'estrazione delle etichette con punteggio e delle probabilità associate alle etichette
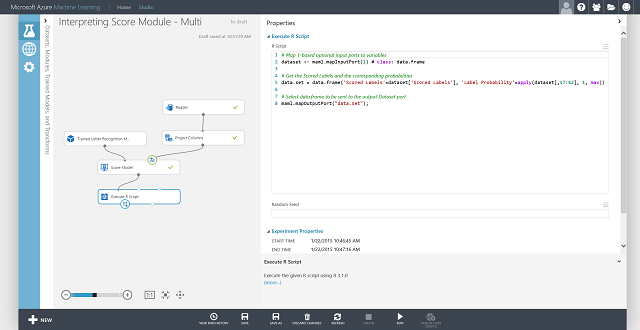
Figura 9. Esperimento finale di assegnazione dei punteggi per un problema di classificazione multiclasse relativo al riconoscimento delle lettere
Dopo aver pubblicato ed eseguito il servizio Web, nonché aver immesso alcuni valori funzione di input, verrà restituito un risultato simile a quello della figura 10. Questa lettera scritta a mano, con le sue 16 caratteristiche estratte, viene stimata come una "T" con probabilità 0,9715.
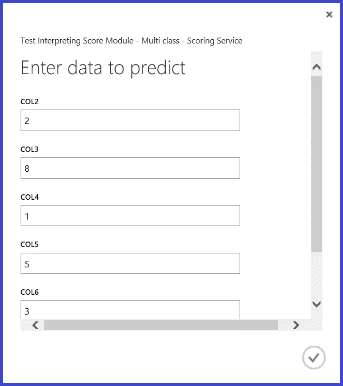

Figura 10. Risultato del servizio Web relativo alla classificazione multiclasse
Regressione
I problemi di regressione differiscono dai problemi di classificazione per alcuni aspetti. Nei problemi di classificazione, infatti, si tenta di stimare classi discrete, ovvero di capire a quale classe appartenga un fiore Iris, mentre, come illustrato nell'esempio seguente, in un problema di regressione si tenta di stimare una variabile continua, ad esempio il prezzo di un'automobile.
Esperimento di esempio
Come esempio di regressione si considera la stima del prezzo di un'automobile. Si tenta quindi di stimare il prezzo di un'automobile a partire dalle sue caratteristiche, tra cui la marca, il tipo di carburante, il tipo di telaio e la ruota motrice. L'esperimento è illustrato nella figura 11.

Figura 11. Esperimento di un problema di regressione relativo al prezzo di un'automobile
Se si visualizza il modulo Score Model, si otterrà un risultato simile a quello illustrato nella figura 12.
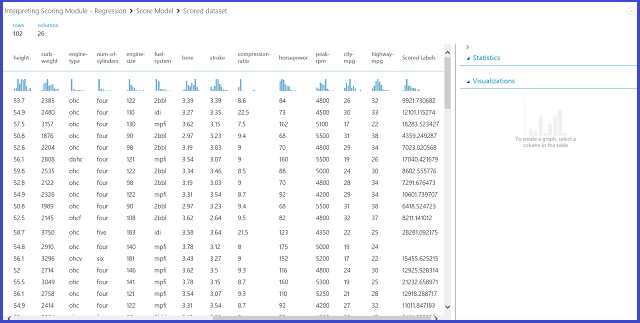
Figura 12. Risultato di assegnazione dei punteggi per un problema relativo alla stima del prezzo di un'automobile
Interpretazione dei risultati
Scored Labels è la colonna dei risultati in questo risultato di assegnazione dei punteggi. I numeri rappresentano invece il prezzo stimato per ogni automobile.
Pubblicazione come servizio Web
È possibile pubblicare l'esperimento di regressione in un servizio Web e chiamarlo per eseguire la stima del prezzo dell'automobile seguendo la stessa procedura usata per la classificazione a due classi.
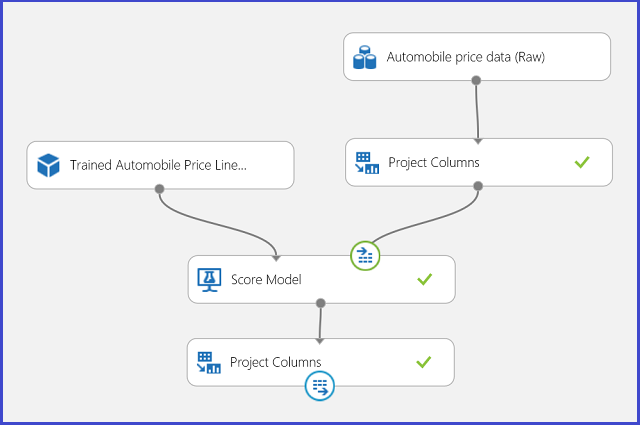
Figura 13. Esperimento di assegnazione dei punteggi di un problema di regressione relativo al prezzo di un'automobile
Eseguendo il servizio Web si otterrà un risultato simile a quello della figura 14. Il prezzo stimato per l'automobile è pari a $15.085,52.
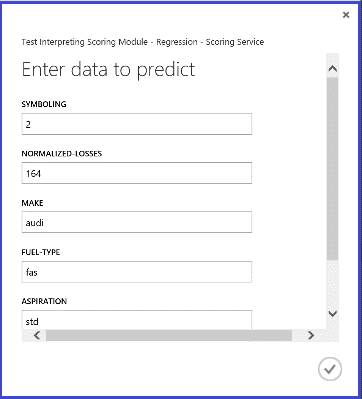

Figura 14. Risultato del servizio web per un problema di regressione del prezzo di un'automobile
Raggruppamento
Esperimento di esempio
Si userà di nuovo il set di dati Iris per creare un esperimento di clustering. In questo caso è possibile escludere dal set di dati le etichette di classe, in modo che sia composto solo dalle caratteristiche e possa essere usato per il clustering. In questo caso d'uso dell'iris, specifica che il numero di cluster deve essere due durante il processo di formazione, il che significa che raggrupperesti i fiori in due classi. L'esperimento è illustrato nella figura 15.
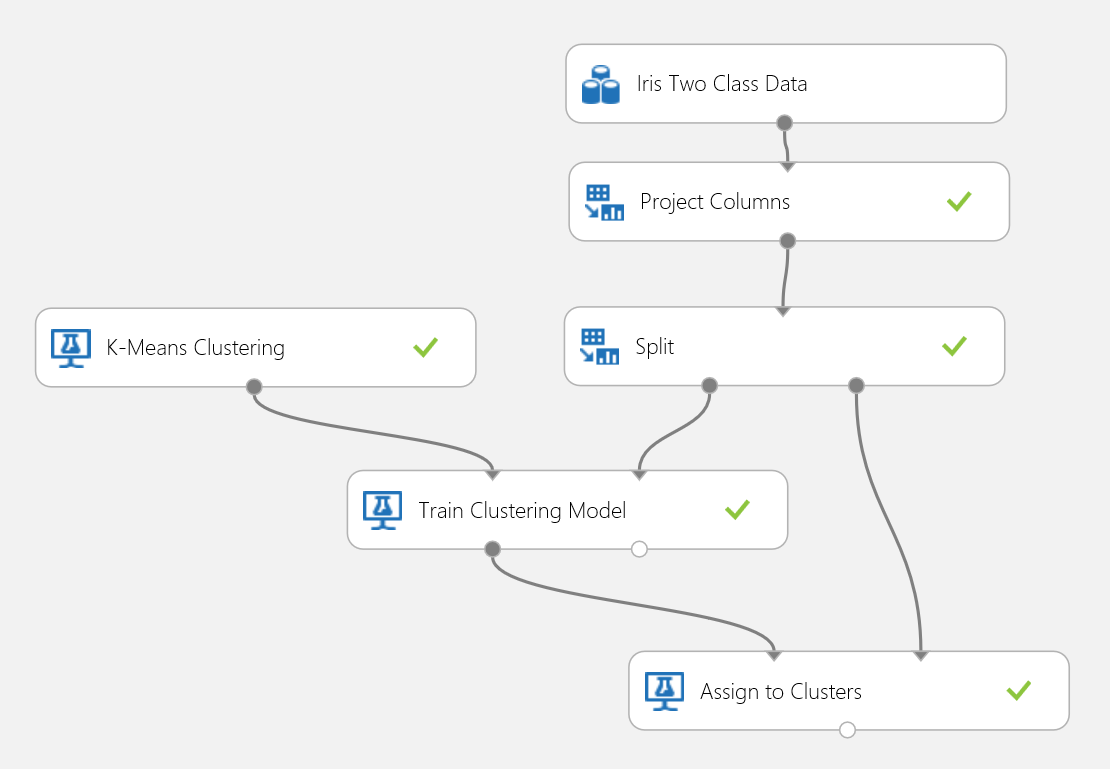
Figura 15. Esperimento sul problema del clustering dell'Iris
Il clustering è diverso dalla classificazione in quanto il set di dati di training in sé non ha etichette di verità reale. Il clustering raggruppa i dati di addestramento in cluster distinti. Durante il processo di addestramento, il modello etichetta i dati mentre impara le differenze tra le loro caratteristiche. Dopo di che, il modello addestrato potrà essere usato per classificare meglio le voci future. In un problema di clustering, ci sono due parti del risultato che ci interessano. La prima parte è etichettare il set di dati di training, e la seconda è classificare un nuovo set di dati con il modello addestrato.
Per visualizzare la prima parte del risultato, fare clic sulla porta di output sinistra di Train Clustering Model e quindi su Visualize (Visualizza). La visualizzazione è illustrata nella figura 16.
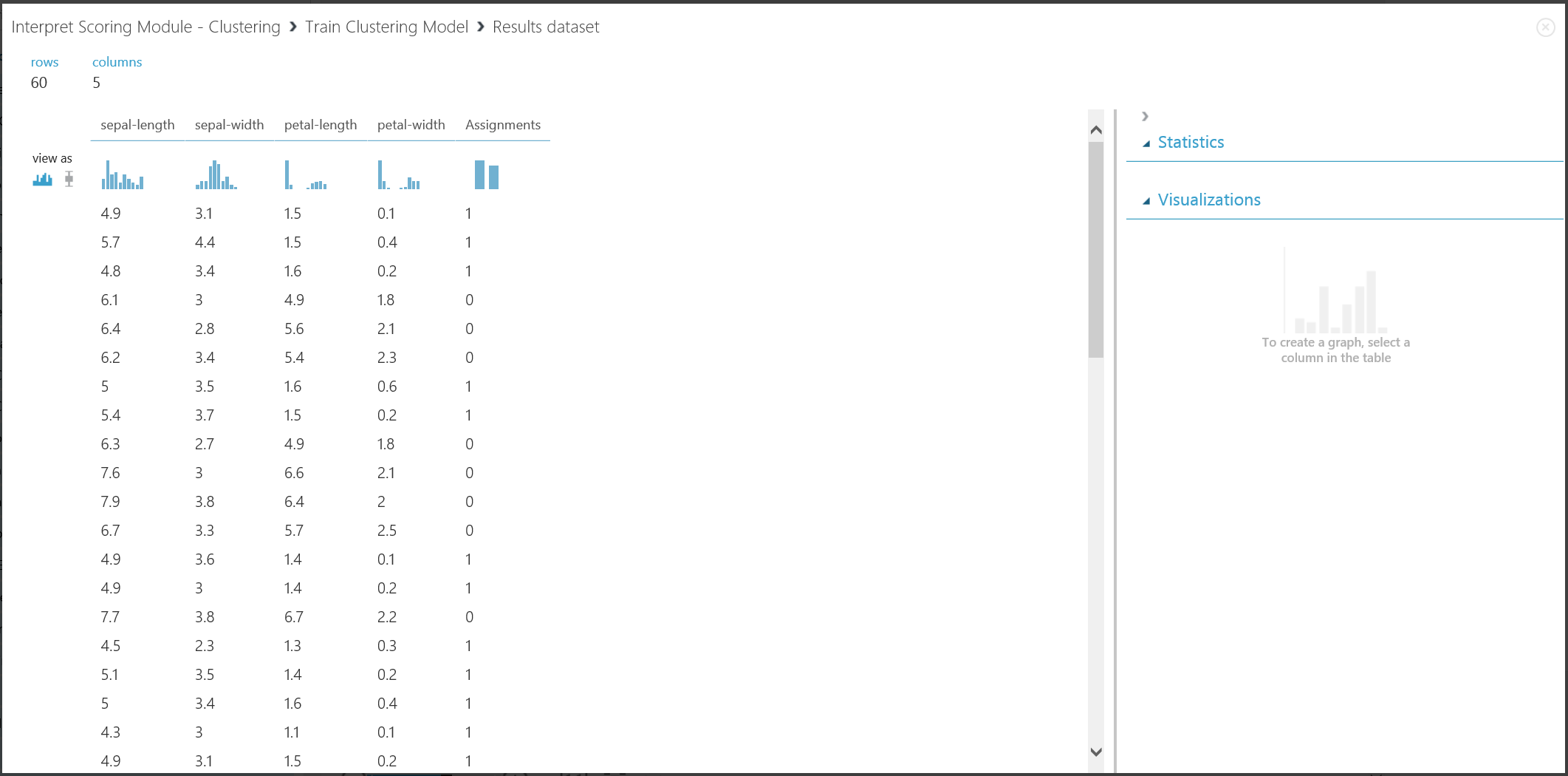
Figura 16. Visualizzazione del risultato di clustering per il set di dati di training
Il risultato della seconda parte, in cui viene eseguito il clustering delle nuove voci tramite il modello di clustering addestrato, è illustrato nella Figura 17.

Figura 17. Visualizzazione del risultato di clustering su un nuovo set di dati
Interpretazione dei risultati
Sebbene i risultati delle due parti provengano da fasi diverse dell'esperimento, risultano identici e devono essere interpretati nello stesso modo. Le prime quattro colonne sono le caratteristiche. mentre l'ultima colonna, denominata Assignments (Assegnazioni), rappresenta il risultato della stima. Le voci a cui è stato assegnato lo stesso numero si stima che appartengano allo stesso cluster, ovvero che presentino alcune analogie (in questo esperimento viene usata la distanza euclidea come parametro predefinito). Poiché è stato specificato che i cluster da usare dovessero essere due, nella colonna Assignments (Assegnazioni) le voci vengono etichettate con il valore 0 o 1.
Pubblicazione come servizio Web
È possibile pubblicare l'esperimento di clustering in un servizio Web e chiamarlo per eseguire stime di clustering seguendo la stessa procedura usata per la classificazione a due classi.
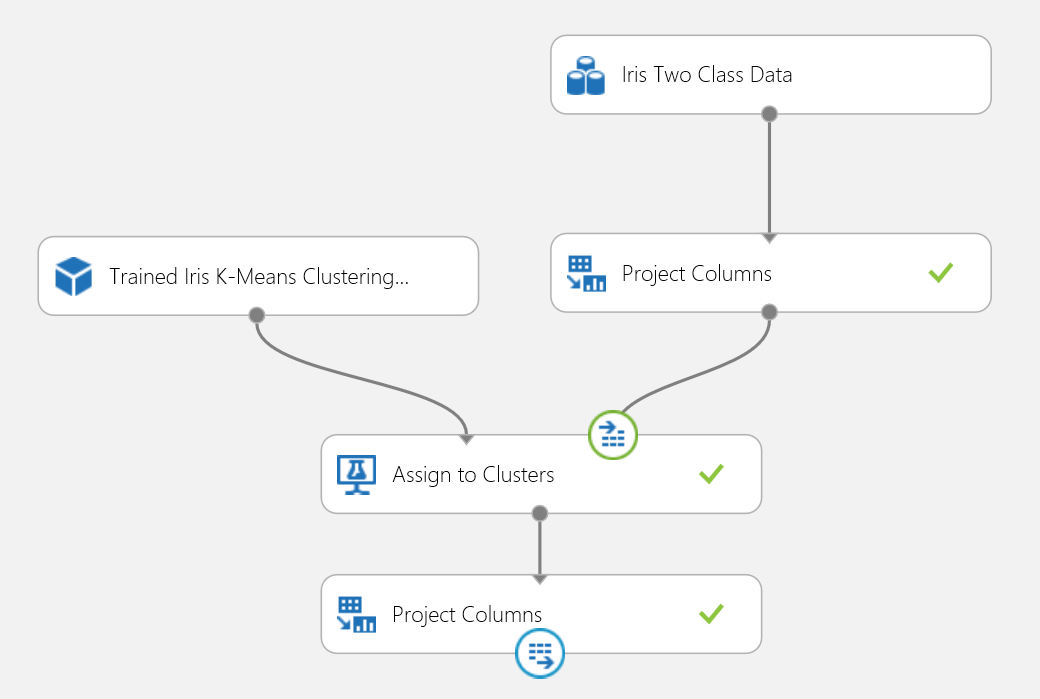
Figura 18. Esperimento di assegnazione dei punteggi di un problema di clustering relativo ai fiori Iris
Dopo aver eseguito il servizio Web si otterrà un risultato simile a quello della figura 19. Si stima che questo fiore appartenga al cluster 0.
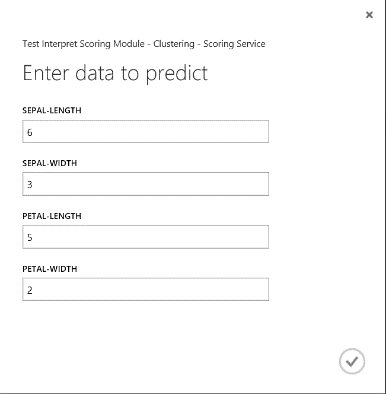

Figura 19. Risultato del servizio Web relativo alla classificazione a due classi dei fiori Iris
Sistema di raccomandazione
Esperimento di esempio
Per illustrare i sistemi di raccomandazione viene usato come esempio un problema di raccomandazione di ristoranti: consigliare i ristoranti ai clienti in base alla relativa cronologia di valutazioni. I dati di input sono costituiti da tre parti:
- Valutazioni sui ristoranti espresse dai clienti
- Dati sulle caratteristiche dei clienti
- Dati sulle caratteristiche del ristorante
Esistono diverse operazioni che è possibile eseguire con il modulo Train Matchbox Recommender in Machine Learning Studio (versione classica):
- Stimare le valutazioni per un determinato utente ed elemento
- Raccomandare elementi a un determinato utente
- Trovare gli utenti correlati a un determinato utente
- Trovare gli elementi correlati a un determinato elemento
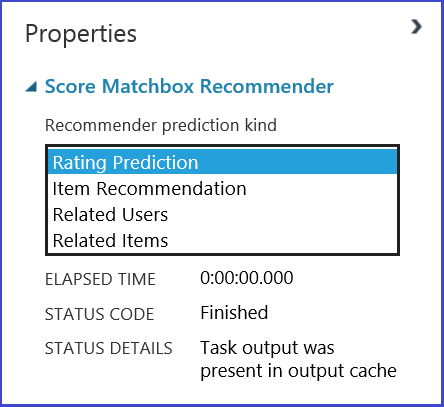
È possibile scegliere il tipo di operazione da eseguire selezionando una delle quattro opzioni disponibili nel menu Recommender prediction kind (Tipo di stima del sistema di raccomandazione). In questo caso vengono analizzati tutti i quattro scenari.
Un tipico esperimento di Machine Learning Studio (versione classica) per un sistema di raccomandazione è simile alla figura 20. Per informazioni su come usare i moduli del sistema di raccomandazione, vedere Train matchbox recommender e Score matchbox recommender.
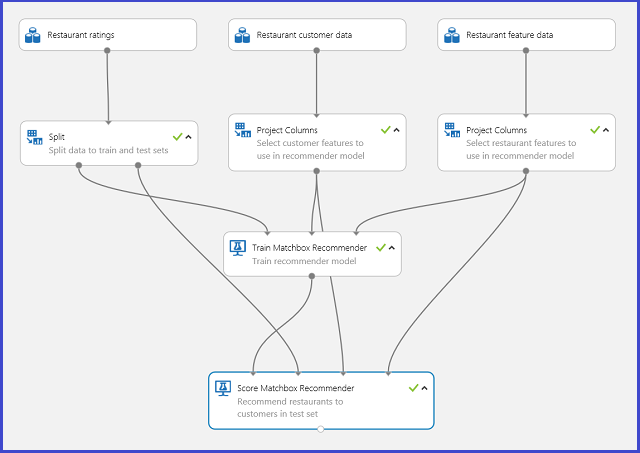
Figura 20. Esperimento per il sistema di raccomandazione
Interpretazione dei risultati
Stimare le valutazioni per un determinato utente ed elemento
Selezionando la voce Rating Prediction (Stima valutazione) in Recommender prediction kind (Tipo di stima del sistema di raccomandazione), si chiede al sistema di raccomandazione di stimare la valutazione per un determinato utente ed elemento. L'output del Score Matchbox Recommender appare come mostrato nella Figura 21.
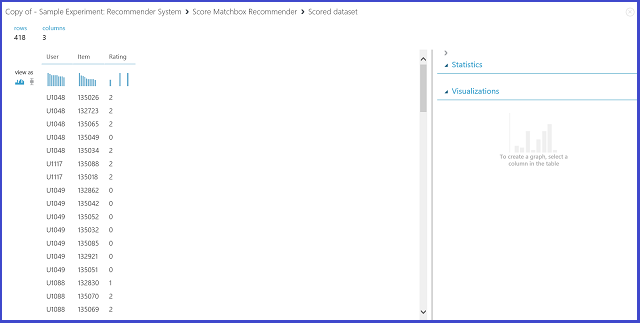
Figura 21. Visualizza il risultato del sistema di raccomandazione - previsione del punteggio
le prime due rappresentano le coppie utente-elemento ricavate dai dati di input, mentre la terza indica la valutazione stimata di un utente per un determinato elemento. Nella prima riga, ad esempio, si stima che la valutazione assegnata dal cliente U1048 al ristorante 135026 sia pari a 2.
Raccomandare elementi a un determinato utente
Selezionando la voce Item Recommendation (Raccomandazione elemento) in Recommender prediction kind (Tipo di stima del sistema di raccomandazione), si chiede al sistema di raccomandazione di consigliare elementi a un determinato utente. L'ultimo parametro da scegliere in questo scenario è Recommended item selection (Selezione elementi consigliati). L'opzione From Rated Items (for model evaluation) viene principalmente utilizzata per la valutazione del modello durante il processo di formazione. per questa fase di stima si usa l'opzione From All Items (Da tutti gli elementi). La visualizzazione dell'output del Score Matchbox Recommender è simile a quella della figura 22.
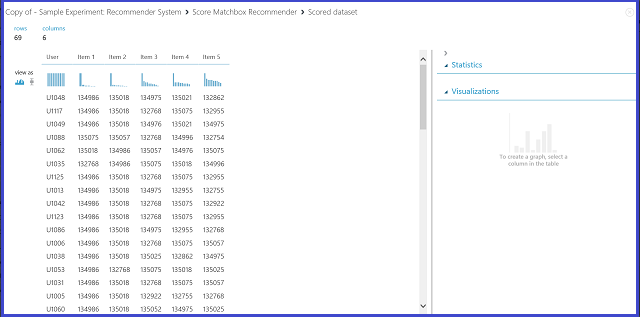
Figura 22. Visualizzazione del risultato di assegnazione dei punteggi del sistema di raccomandazione - Raccomandazione dell'elemento
La prima delle sei colonne rappresenta gli ID utente per i quali consigliare gli elementi, ricavati dai dati di input, mentre le altre cinque contengono gli elementi consigliati all'utente, in ordine decrescente di rilevanza. Nella prima riga, ad esempio, il ristorante più consigliato per il cliente U1048 è il numero 134986, seguito da 135018, 134975, 135021 e 132862.
Trovare gli utenti correlati a un determinato utente
Selezionando la voce Related Users (Utenti correlati) in Recommender prediction kind (Tipo di stima del sistema di raccomandazione), si chiede al sistema di raccomandazione di trovare utenti correlati a un determinato utente. Per utenti correlati si intendono tutti gli utenti con preferenze simili. L'ultimo parametro da scegliere in questo scenario è Related user selection (Selezione utenti correlati). L'opzione From Users That Rated Items (for model evaluation) (Da utenti che hanno valutato gli elementi (per valutazione modello)) è usata principalmente per la valutazione del modello durante il processo di addestramento. per questa fase di stima si usa l'opzione From All Users (Da tutti gli utenti). La visualizzazione dell'output del Score Matchbox Recommender appare come mostrato nella figura 23.
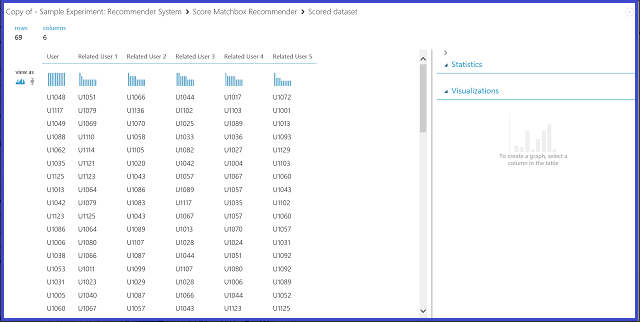
Figura 23. Visualizzazione del risultato di assegnazione dei punteggi del sistema di raccomandazione - Utenti correlati
La prima delle sei colonne rappresenta gli ID utente necessari per trovare utenti correlati, ricavati dai dati di input, mentre le altre cinque contengono gli utenti correlati stimati per l'utente, in ordine decrescente di rilevanza. Nella prima riga, ad esempio, il cliente più rilevante per il cliente U1048 è il numero U1051, seguito da U1066, U1044, U1017 e U1072.
Trovare gli elementi correlati a un determinato elemento
Selezionando la voce Related Items (Elementi correlati) in Recommender prediction kind (Tipo di stima del sistema di raccomandazione), si chiede al sistema di raccomandazione di trovare elementi correlati a un determinato elemento. Per elementi correlati si intendono tutti gli elementi che con più probabilità sono apprezzati dallo stesso utente. L'ultimo parametro da scegliere in questo scenario è Related item selection (Selezione elementi correlati). L'opzione From Rated Items (for model evaluation) viene principalmente utilizzata per la valutazione del modello durante il processo di formazione. per questa fase di stima si usa l'opzione From All Items (Da tutti gli elementi). La visualizzazione dell'output del Score Matchbox Recommender è simile a quella della Figura 24.

Figura 24. Visualizzazione del risultato di assegnazione dei punteggi del sistema di raccomandazione - Elementi correlati
La prima delle sei colonne rappresenta gli ID elemento necessari per trovare elementi correlati, ricavati dai dati di input, mentre le altre cinque contengono gli elementi correlati stimati per l'elemento, in ordine decrescente in termini di rilevanza. Nella prima riga, ad esempio, l'elemento più rilevante per l'elemento 135026 è il numero 135074, seguito da 135035, 132875, 135055 e 134992.
Pubblicazione come servizio Web
Il processo di pubblicazione di questi esperimenti come servizi Web per ottenere stime è molto simile per tutti i quattro scenari. In questo caso viene preso ad esempio il secondo scenario: raccomandare elementi a un determinato utente. È possibile seguire la stessa procedura anche per gli altri tre scenari.
Salvando il sistema di raccomandazione addestrato come modello addestrato e filtrando i dati di input in un'unica colonna ID utente, come richiesto, è possibile collegare l'esperimento come mostrato nella figura 25 e pubblicarlo come servizio web.
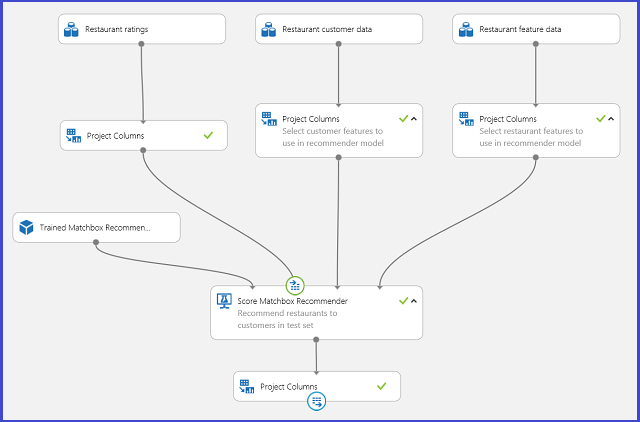
Figura 25. Esperimento di assegnazione dei punteggi per un problema di raccomandazione di ristoranti
Eseguendo il servizio Web si otterrà un risultato simile a quello della figura 26. I cinque ristoranti consigliati per l'utente U1048 sono 134986, 135018, 134975, 135021 e 132862.
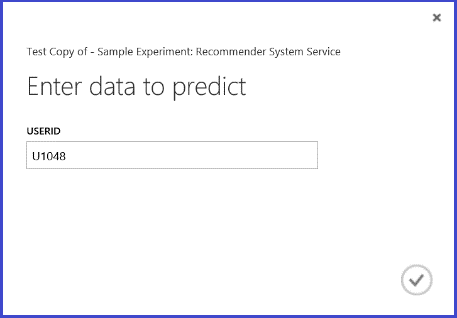

Figura 26. Risultato del servizio Web relativo al problema di raccomandazione di ristoranti