Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere leinformazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Altre informazioni sulle Azure Machine Learning.
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Adatta a un set di dati una funzione di distribuzione di probabilità specificata
Categoria: Funzioni statistiche
Nota
Si applica a: solo Machine Learning Studio (versione classica)
I moduli di trascinamento e rilascio simili sono disponibili in Azure Machine Learning finestra di progettazione.
Panoramica del modulo
Questo articolo descrive come usare il modulo Valuta funzione probabilità in Machine Learning Studio (versione classica), per calcolare le misure statistiche che descrivono la distribuzione di una colonna, ad esempio le distribuzioni di Bernoulli, Pareto o Poisson.
Per usare questo modello, connettere un set di dati contenente almeno una colonna di valori numerici e scegliere una distribuzione di probabilità da testare. Il modulo restituisce una tabella dati contenente valori dalla funzione di probabilità specificata.
È possibile calcolare uno di questi valori per la distribuzione di probabilità scelta:
- funzione di distribuzione cumulativa (cdf)
- funzione di distribuzione cumulativa inversa (InverseCdf)
- funzione di densità di probabilità (Pdf)
Perché la distribuzione della probabilità è utile?
Quando si valutano i dati rispetto a una distribuzione di probabilità, si esegue il mapping dei valori di colonna a un set di valori con proprietà note. Conoscendo se i dati corrispondono a una di queste distribuzioni note, è possibile dedurre altre proprietà dei dati. In generale, si possono ottenere stime migliori da un modello quando è possibile identificare la distribuzione più appropriata per i dati.
La scelta della funzione di distribuzione della probabilità da usare dipende dai dati e dalle variabili da misurare. Ad esempio, alcune distribuzioni sono progettate per descrivere le probabilità dei valori discreti; altri sono destinati all'uso solo con variabili numeriche continue. Per alcune distribuzioni, è anche necessario conoscere in anticipo una media prevista, gradi di libertà e così via. Per informazioni dettagliate, vedere Distribuzioni di probabilità supportate
Come configurare la funzione Valuta probabilità
Tutte le opzioni cambiano a seconda del tipo di distribuzione di probabilità da calcolare. Se si modifica il metodo di distribuzione della probabilità, potrebbero essere state reimpostate altre selezioni.
Assicurarsi quindi di scegliere prima l'opzione Distribuzione !
Il set di dati usato come input deve contenere dati numerici. Altri tipi di dati vengono ignorati.
Per ogni analisi, è possibile applicare un singolo metodo di distribuzione di probabilità. Per calcolare una distribuzione di probabilità diversa, aggiungere un'istanza separata del modulo per ogni distribuzione che si intende testare.
Aggiungere il modulo Valuta funzione probabilità all'esperimento. È possibile trovare questo modulo nella categoria Funzioni statistiche in Machine Learning Studio (versione classica).
Connessione un set di dati contenente almeno una colonna di numeri.
Usare l'opzione Distribuzione per selezionare il tipo di distribuzione di probabilità da calcolare. Per un elenco di opzioni e per gli argomenti necessari, vedere Distribuzioni di probabilità supportate .
Impostare i parametri richiesti dalla distribuzione.
Scegliere una delle tre statistiche da creare: la funzione di distribuzione cumulativa (cdf), la funzione di distribuzione cumulativa inversa (InverseCdf) o la funzione densità di probabilità (pdf).
Per le definizioni, vedere la sezione Note tecniche.
Usare il selettore di colonna per scegliere le colonne su cui calcolare la distribuzione di probabilità selezionata.
Tutte le colonne selezionate devono avere un tipo di dati numerico.
L'intervallo di dati nella colonna deve essere valido, data la funzione di probabilità selezionata. In caso contrario, può verificarsi un errore o un risultato NaN (non un numero).
Per le colonne di tipo sparse, eventuali valori che corrispondono a zero in background non verranno elaborati.
Usare l'opzione Modalità risultato per specificare come restituire i risultati. È possibile sostituire i valori delle colonne con i valori di distribuzione di probabilità, aggiungere i nuovi valori al set di dati o restituire solo i valori di distribuzione di probabilità.
Eseguire l'esperimento oppure fare clic con il pulsante destro del mouse sul modulo Valuta funzione probabilità e scegliere Esegui selezionato.
Risultati
La tabella seguente contiene un esempio di risultati, usando l'opzione Accodamento , in una singola colonna di temperatura del set di dati di esempio Forest Fires .
| temp | StandardNormal.Cdf(temp) | StandardNormal.Pdf(temp) | FFisher.cdf(temp | FFisher.cdf(temp |
|---|---|---|---|---|
| 8.2 | 1 | 1 | 0.984774 | 0.004349 |
| 18 | 1 | 1 | 0.997896 | 0.000311 |
| 14.6 | 1 | 1 | 0.996352 | 0.000648 |
| 8.3 | 1 | 1 | 0.985201 | 0.004187 |
| 11,4 | 1 | 1 | 0.993147 | 0.001502 |
Le intestazioni delle colonne generate contengono la distribuzione della probabilità usata.
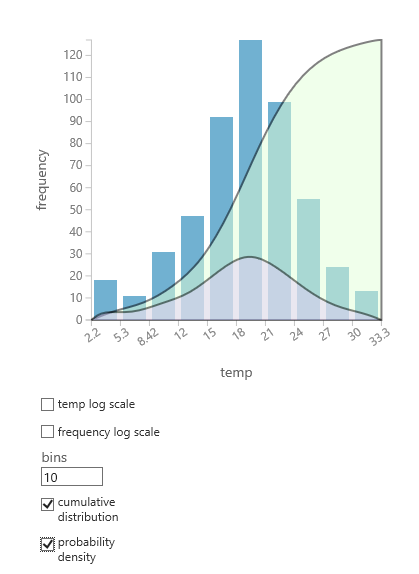
Se non si è certi della distribuzione di probabilità probabilmente adatta ai dati, è possibile creare un grafico rapido della distribuzione cumulativa e della densità di probabilità per qualsiasi colonna numerica.
- Fare clic con il pulsante destro del mouse sul set di dati o sull'output del modulo e scegliere Visualizza.
- Selezionare la colonna di interesse e nel riquadro Istogramma selezionare distribuzione cumulativa o densità di probabilità.
- Un grafico della distribuzione, come illustrato di seguito, viene sovrapposto all'istogramma che rappresenta i dati.
Distribuzioni di probabilità supportate
Il modulo Valuta funzione probabilità supporta le distribuzioni seguenti:
Bernoulli
La distribuzione di Bernoulli è una distribuzione sui valori binari: in altre parole, modella la distribuzione prevista quando sono possibili solo due valori.
Per calcolare, selezionare Bernoulli e impostare le opzioni seguenti:
- Probability of success
Il parametro p specifica la probabilità che venga generata una 1. Digitare un numero (float) compreso tra 0,0 e 1,0 che specifica la probabilità di successo. Il valore predefinito è .5.
Beta
La distribuzione Beta è una distribuzione continua univariata.
Per calcolare, selezionare Beta e impostare le opzioni seguenti:
Forma
Digitare un valore per modificare la forma della distribuzione.Un parametro Shape è un parametro di una distribuzione di probabilità che non definisce la posizione o la scala. Quando si immette un valore per la forma, il parametro cambia quindi la forma della distribuzione, invece di spostarla, allungarla o ridurla.
Il valore deve essere un numero (
double). Il valore predefinito è 1.0.Scalabilità
Immettere un numero da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Limite superiore
Immettere un numero (double) che rappresenta il limite superiore della distribuzione. Il valore predefinito è 1.0.Limite inferiore
Immettere un numero (double) che rappresenta il limite inferiore della distribuzione. Il valore predefinito è 0,0.
Binomiale
La distribuzione binomiale è una distribuzione univariata discreta. La distribuzione binomiale viene usata per modellare il numero di esiti positivi in un campione. Durante il campionamento viene usata la sostituzione. Per un campionamento senza sostituzione, usare la distribuzione ipergeometrica.
Per calcolare, selezionare Binomial e impostare le opzioni seguenti:
Probability of success
Digitare un numero (float) compreso tra 0,0 e 1,0 che indica la probabilità di successo. Il valore predefinito è .5.Number of trials
Specificare il numero di versioni di valutazione.Usare un numero
integer, con un valore minimo pari a 1. Il valore predefinito è 3.
Cauchy
La distribuzione di Cauchy è una distribuzione di probabilità simmetrica continua.
Per calcolare, selezionare Cauchy e impostare le opzioni seguenti:
Località
Digitare un numero (double) che rappresenta la posizionedell'elemento 0.Specificando un valore per il parametro Location, è possibile spostare la distribuzione di probabilità verso l'alto o verso il basso su una scala numerica.
Il valore predefinito è 0,0.
Chi quadrato
La distribuzione chi-square è una somma dei quadrati di k indipendenti, standard, normali, variabili casuali.
Per calcolare, selezionare ChiSquare e impostare le opzioni seguenti:
- Numero di gradi di libertà Digitare un numero (
double) per specificare i gradi di libertà. Il valore predefinito è 1.0.
Chi quadrato con coda a destra
Questa opzione fornisce una distribuzione chi quadrata a destra.
Per calcolare, selezionare ChiSquareRightTailed e impostare le opzioni seguenti:
- Number of degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà. Il valore predefinito è 1.0.
Esponenziale
La distribuzione esponenziale è una distribuzione sui numeri reali parametrizzati da un parametro non negativo.
Per calcolare, selezionare Esponenziale e impostare le opzioni seguenti:
- Lambda
Immettere un numero (double) da usare come parametro lambda. Il valore predefinito è 1.0.
F di Fisher
Genera la probabilità della statistica Fisher per un campione, nota anche come distribuzione F-fisher. Questa distribuzione è a due code.
Per calcolare, selezionare FFisher e impostare le opzioni seguenti:
Numerator degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà usati nel numeratore. Il valore predefinito è 3.0.Denominator degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà usati nel denominatore. Il valore predefinito è 6.0.
F di Fisher con coda a destra
Crea una distribuzione Di Fisher con coda destra. La distribuzione di Fisher è nota anche come distribuzione F di Fisher, distribuzione di Snedecor o distribuzione Fisher-Snedecor. Questa particolare forma della distribuzione ha una coda a destra.
Per calcolare, selezionare FFisherRightTailed e impostare le opzioni seguenti:
Numerator degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà usati nel numeratore. Il valore predefinito è 3.0.Denominator degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà usati nel denominatore. Il valore predefinito è 6.0.
Gamma
La distribuzione gamma è una famiglia di distribuzioni di probabilità continue con due parametri. Ad esempio, chi quadrato è un caso speciale della distribuzione gamma.
Per calcolare, selezionare Gamma e impostare le opzioni seguenti:
Scalabilità
Immettere un valore da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Località
Digitare un numero (double) che rappresenta la posizionedell'elemento 0.Specificando un valore per il parametro Location, è possibile spostare la distribuzione di probabilità verso l'alto o verso il basso su una scala numerica.
Il valore predefinito è 0,0.
Valori estremi generalizzati
Crea una distribuzione sviluppata per gestire i valori estremi. La distribuzione generalizzata dei valori estremi è effettivamente un gruppo di distribuzioni di probabilità continue che combina le distribuzioni di Gumbel, Fréchet e Weibull (note anche come distribuzioni dei valori estremi di tipo I, II e III).
Per altre informazioni sulla teoria dei valori estremi, vedere questo articolo in Wikipedia: Fisher-Tippet-Gnedenko theorem.
Per calcolare, selezionare GeneralizedValues e impostare le opzioni seguenti:
Forma
Digitare un valore per modificare la forma della distribuzione.Un parametro Shape è un parametro di una distribuzione di probabilità che non definisce la posizione o la scala. Quando si immette un valore per la forma, il parametro cambia quindi la forma della distribuzione, invece di spostarla, allungarla o ridurla.
Il valore deve essere un numero (
double). Il valore predefinito è 1.0.Scalabilità
Immettere un valore da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Località
Digitare un numero (double) che rappresenta la posizionedell'elemento 0.Digitando un valore per il parametro Location, è possibile spostare la distribuzione di probabilità verso l'alto o verso il basso su una scala numerica.
Il valore predefinito è 0,0.
Geometrica
La distribuzione geometrica è una distribuzione su interi positivi parametrizzati da un numero reale positivo.
Per calcolare, selezionare Geometric e impostare le opzioni seguenti:
- Probability of success
Digitare un numero (float) compreso tra 0,0 e 1,0 che indica la probabilità di successo. Il valore predefinito è .5.
Nota
Questa implementazione della distribuzione geometrica non genera zero.
GumbelMax
La distribuzione di Gumbel è una delle diverse distribuzioni di valori estremi. L'opzione GumbelMax implementa la distribuzione generalizzata dei valori estremi massimi di tipo 1.
Per calcolare, selezionare GumbelMax e impostare le opzioni seguenti:
Scalabilità
Immettere un valore da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Località
Digitare un numero (double) che rappresenta la posizionedell'elemento 0.Digitando un valore per il parametro Location, è possibile spostare la distribuzione di probabilità verso l'alto o verso il basso su una scala numerica.
Il valore predefinito è 0,0.
GumbelMin
La distribuzione di Gumbel è una delle diverse distribuzioni di valori estremi. La distribuzione di Gumbel è nota anche distribuzione dei valori estremi (dei minimi) o distribuzione di tipo I dei valori estremi (dei minimi). L'opzione GumbelMin implementa la distribuzione Minimum Extreme Value Type 1.
Per calcolare, selezionare GumbelMin e deve impostare le opzioni seguenti:
Scalabilità
Immettere un valore da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Località
Digitare un numero (double) che rappresenta la posizionedell'elemento 0.Digitando un valore per il parametro Location, è possibile spostare la distribuzione di probabilità verso l'alto o verso il basso su una scala numerica.
Il valore predefinito è 0,0.
Ipergeometrica
La distribuzione ipergeometrica è una distribuzione di probabilità discreta che descrive il numero di successi in una sequenza di n deriva da una popolazione finita senza sostituzione, proprio come la distribuzione binomiale descrive il numero di successi per i disegni con sostituzione.
Per calcolare, selezionare Hypergeometric e impostare le opzioni seguenti:
Numero di campioni
Digitare un numero intero che indica il numero di campioni da usare. Il valore predefinito è 9.Number of success
Immettere un valore Integer che definisce il valore per l'esito positivo. Il valore predefinito è 24.Population size
Specificare la dimensione della popolazione da usare quando si stima la distribuzione ipergeometrica.
Laplace
La distribuzione di Laplace è una distribuzione sui numeri reali, parametrizzata da una media e da un parametro di scala.
Per calcolare, selezionare Laplace distribution e impostare le opzioni seguenti:
Scalabilità
Immettere un valore da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Località
Digitare un numero (double) che rappresenta la posizionedell'elemento 0.Digitando un valore per il parametro Location, è possibile spostare la distribuzione di probabilità verso l'alto o verso il basso su una scala numerica.
Il valore predefinito è 0,0.
Logistica
La distribuzione logistica è simile alla distribuzione normale, ma non prevede alcun limite sul lato sinistro della distribuzione. La distribuzione logistica viene usata nei modelli di regressione logistica e reti neurali per la modellazione dei dati delle scienze biologiche.
Per calcolare, selezionare Logistica e impostare le opzioni seguenti:
Scalabilità
Immettere un valore da usare per il ridimensionamento della distribuzione.Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.
Il valore predefinito è 1,0. I valori devono essere numeri positivi.
Media
Immettere un numero (double) che indica il valore medio stimato della distribuzione. Il valore predefinito è 0,0.
Lognormale
La distribuzione lognormale è una distribuzione univariata continua.
Per calcolare, selezionare Lognormal e impostare le opzioni seguenti:
Media
Digitare un numero (double) che indica il valore medio stimato della distribuzione. Il valore predefinito è 0,0.Deviazione standard
Immettere un numero positivo (double) che indica la deviazione standard stimata della distribuzione. Il valore predefinito è 1.0.
Binomiale negativa
La distribuzione binomiale negativa è una distribuzione sui numeri naturali con due parametri (r, p). Nel caso speciale che r è un numero intero, è possibile interpretare la distribuzione come numero di code prima delr th head quando la probabilità della testa è p.
Per calcolare, selezionare NegativeBinomial e impostare le opzioni seguenti:
Probability of success
Digitare un numero (float) compreso tra 0,0 e 1,0 che indica la probabilità di successo. Il valore predefinito è .5.Number of success
Immettere un valore Integer che specifica il valore per l'esito positivo. Il valore predefinito è 24.
Normale
La distribuzione normale è nota anche come distribuzione gaussiana.
Per calcolare, selezionare Normale e impostare le opzioni seguenti:
Media
Digitare un numero (double) che indica il valore medio stimato della distribuzione. Il valore predefinito è 0,0.Deviazione standard
Immettere un numero positivo (double) che indica la deviazione standard stimata della distribuzione. Il valore predefinito è 1.0.
Pareto
La distribuzione di Pareto è una distribuzione di probabilità delle leggi di potenza che coincide con fenomeni sociali, scientifici, geofisici, assicuratici e molti altri tipi di fenomeni osservabili.
Per calcolare, selezionare Pareto e impostare le opzioni seguenti:
Forma
Digitare un valore (facoltativo) per modificare la forma della distribuzione.Un parametro Shape è un parametro di una distribuzione di probabilità che non definisce la posizione o la scala. Quando si immette un valore per la forma, il parametro cambia quindi la forma della distribuzione, invece di spostarla, allungarla o ridurla.
Il valore deve essere un numero (
double). Il valore predefinito è 1.0.Scalabilità
Digitare un valore (facoltativo) per modificare la scala della distribuzione. Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.Il valore deve essere un numero (
double). Il valore predefinito è 1.0.
Poisson
In questa implementazione viene usato il metodo di Knuth per generare variabili casuali distribuite di Poisson. Per altre informazioni sulla distribuzione di Poisson, vedere Poisson Regression.
Per calcolare, selezionare Poisson e impostare le opzioni seguenti:
- Media
Digitare un numero (double) che indica il valore medio stimato della distribuzione. Il valore predefinito è 0,0.
Rayleigh
La distribuzione di Rayleigh è una distribuzione di probabilità continua. Ad esempio, la velocità del vento ha una distribuzione di Rayleigh se i componenti del vettore bidimensionale della velocità del vento non sono correlati e sono distribuiti normalmente con uguale varianza.
Per calcolare, selezionare Rayleigh e impostare le opzioni seguenti:
- Limite inferiore
Immettere un numero (double) che rappresenta il limite inferiore della distribuzione. Il valore predefinito è 0,0.
Normale standard
Questa opzione fornisce la distribuzione normale standard, senza altri parametri.
Per calcolare, selezionare StandardNormal e selezionare le colonne.
T di Student
Questa opzione implementa la distribuzione t di Student univariate.
Per calcolare, selezionare TStudent e impostare le opzioni seguenti:
- Number of degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà. Il valore predefinito è 1.0.
T di Student con coda a destra
Implementa la distribuzione T di Student usando una coda a destra.
Per calcolare, selezionare TStudentRightTailed e impostare le opzioni seguenti:
- Number of degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà. Il valore predefinito è 1.0.
T di Student con due code
Implementa una distribuzione T di Student con due code.
Per calcolare, selezionare TStudentTwoTailed e impostare le opzioni seguenti:
- Number of degrees of freedom
Immettere un numero (double) per specificare i gradi di libertà. Il valore predefinito è 1.0.
Uniforme
La distribuzione uniforme è nota anche come distribuzione rettangolare.
Per calcolare, selezionare Uniform e impostare le opzioni seguenti:
Limite inferiore
Immettere un numero (double) che rappresenta il limite inferiore della distribuzione. Il valore predefinito è 0,0.Limite superiore
Immettere un numero (double) che rappresenta il limite superiore della distribuzione. Il valore predefinito è 1.0.
Weibull
La distribuzione di Weibull è ampiamente usata nell'ingegneria dell'affidabilità. È possibile usare il parametro Shape per modellare molte altre distribuzioni.
Per calcolare, selezionare Weibull e impostare le opzioni seguenti:
Forma
Digitare un valore (facoltativo) per modificare la forma della distribuzione.Un parametro Shape è un parametro di una distribuzione di probabilità che non definisce la posizione o la scala. Quando si immette un valore per la forma, il parametro cambia quindi la forma della distribuzione, invece di spostarla, allungarla o ridurla.
Il valore deve essere un numero (
double). Il valore predefinito è 1.0.Scalabilità
Digitare un valore (facoltativo) per modificare la scala della distribuzione. Applicando un valore di scala alla distribuzione, è possibile ridurla o allungarla.Il valore deve essere un numero (
double). Il valore predefinito è 1.0.
Note tecniche
Questa sezione contiene informazioni dettagliate sull'implementazione, suggerimenti e risposte alle domande frequenti.
Dettagli dell'implementazione
Questo modulo supporta tutte le distribuzioni fornite nella libreria open source MATH.NET Numerics. Per altre informazioni, vedere la documentazione relativa alla libreria Math.Net.Numerics.Distribution .
Le distribuzioni a coda destra e a due code vengono visualizzate come distribuzioni separate, non come versioni con parametri delle distribuzioni di base. Il comportamento attuale mantiene la compatibilità con Excel.
Definizioni
Questo modulo supporta il calcolo di uno di questi valori per la distribuzione specificata:
cdf o la funzione di distribuzione cumulativa
Restituisce la probabilità per un evento composto, definito come somma di ricorsi quando la variabile casuale accetta un valore inferiore a un valore x specifico.
In altre parole, risponde alla domanda: "In che modo i campioni comuni sono minori o uguali a questo valore?"
Questa funzione può essere usata con variabili numeriche continue e discrete.
InverseCdf o la funzione di distribuzione cumulativa inversa
Restituisce il valore associato a un valore di probabilità cumulativo specifico (cdf).
In altre parole, risponde alla domanda: "Qual è il valore di x in cui la funzione cdf restituisce la probabilità cumulativa y?"
pdf o la funzione di densità di probabilità
Descrive la probabilità relativa per una variabile casuale di essere un valore specifico.
In altre parole, risponde alla domanda: "Come sono comuni esempi esattamente in questo valore?"
Input previsti
| Nome | Tipo | Descrizione |
|---|---|---|
| Set di dati | Tabella dati | Set di dati di input |
Parametri del modulo
| Nome | Intervallo | Type | Predefinito | Descrizione |
|---|---|---|---|---|
| Distribuzione | Qualsiasi | ProbabilityDistribution | Normale standard | Selezionare il tipo di distribuzione di probabilità per generare. |
| Metodo | Qualsiasi | ProbabilityDistributionMethod | Cdf | Selezionare il metodo da usare per calcolare la distribuzione della probabilità selezionata. Le opzioni disponibili sono la funzione di distribuzione cumulativa (cdf), la funzione di distribuzione cumulativa inversa (InverseCdf) e la funzione di densità di probabilità o funzione di massa (pdf). |
| Metodo di distribuzione binomiale negativa | Qualsiasi | ProbabilityDistributionMethodForNegativeBinomial | Cdf | Se si seleziona la distribuzione binomiale negativa, specificare il metodo usato per valutare la distribuzione. |
| Probability of success | [0,0;1,0] | Float | 0,5 | Digitare un valore da usare come probabilità di successo. |
| Forma | Qualsiasi | Float | 1.0 | Immettere un valore che modifica la forma della distribuzione. |
| Scalabilità | >=0.0 | Float | 1.0 | Immettere un valore che cambia la scala della distribuzione per espanderla o ridurla. |
| Number of trials | >=1 | Integer | 3 | Specificare il numero di versioni di valutazione. |
| Limite inferiore | Qualsiasi | Float | 0,0 | Immettere un numero da usare come limite inferiore della distribuzione. |
| Upper bound | Qualsiasi | Float | 1.0 | Immettere un numero da usare come limite superiore della distribuzione. |
| Location | Qualsiasi | Float | 0.0 | Digitare la posizione dell'elemento zero nella distribuzione. |
| Number of degrees of freedom | Qualsiasi | Float | 1.0 | Specificare il numero di gradi di libertà. |
| Numerator degrees of freedom | Qualsiasi | Float | 3.0 | Specificare il numero di gradi di libertà nel numeratore. |
| Denominator degrees of freedom | Qualsiasi | Float | 6,0 | Specificare il numero di gradi di libertà nel denominatore. |
| Lambda | >=0.0 | Float | 1.0 | Specificare un valore per il parametro Lambda. |
| Numero di campioni | Qualsiasi | Integer | 9 | Specificare il numero di campioni. |
| Number of success | Qualsiasi | Integer | 24 | Immettere un valore da usare come numero di esiti positivi. |
| Population size | Qualsiasi | Integer | 52 | Specificare la dimensione della popolazione. |
| Media | Qualsiasi | Float | 0,0 | Immettere il valore medio stimato. |
| Deviazione standard | >=0.0 | Float | 1.0 | Immettere la deviazione standard stimata. |
| Column set | Qualsiasi | ColumnSelection | Scegliere le colonne per cui calcolare la distribuzione di probabilità. | |
| Result mode | Qualsiasi | OutputTo | ResultOnly | Specificare come devono essere salvati i risultati nel set di dati di output. Le opzioni disponibili sono l'aggiunta di nuove colonne, la sostituzione di colonne esistenti o la restituzione dei soli risultati. |
Output
| Nome | Tipo | Descrizione |
|---|---|---|
| Set di dati di risultati | Tabella dati | Set di dati di output |
Eccezione
Per un elenco completo dei messaggi di errore, vedere Codici di errore del modulo.
| Eccezione | Descrizione |
|---|---|
| Errore 0017 | Si verifica un'eccezione se il tipo di una o più colonne specificate non è supportato dal modulo attuale. |
Per un elenco di errori specifici dei moduli di Studio (versione classica), vedere Machine Learning Codici di errore.
Per un elenco di eccezioni API, vedere Machine Learning codici di errore dell'API REST.