Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'algoritmo Microsoft Decision Trees è un algoritmo di classificazione e regressione fornito da Microsoft SQL Server Analysis Services per l'uso nella modellazione predittiva di attributi discreti e continui.
Per gli attributi discreti, l'algoritmo esegue stime in base alle relazioni tra colonne di input in un set di dati. Usa i valori, noti come stati, di tali colonne per stimare gli stati di una colonna designata come prevedibile. In particolare, l'algoritmo identifica le colonne di input correlate alla colonna stimabile. Ad esempio, in uno scenario per stimare quali clienti hanno probabilità di acquistare una bicicletta, se nove clienti più giovani acquistano una bicicletta, ma solo due su dieci clienti meno recenti lo fanno, l'algoritmo deduce che l'età è un buon stimatore dell'acquisto di biciclette. L'albero delle decisioni effettua stime in base a questa tendenza verso un determinato risultato.
Per gli attributi continui, l'algoritmo usa la regressione lineare per determinare la posizione di divisione di un albero delle decisioni.
Se più colonne sono impostate su prevedibile o se i dati di input contengono una tabella nidificata impostata su prevedibile, l'algoritmo costruisce un albero decisionale separato per ogni colonna prevedibile
Esempio
Il reparto marketing dell'azienda Adventure Works Cycles vuole identificare le caratteristiche dei clienti precedenti che potrebbero indicare se tali clienti potrebbero acquistare un prodotto in futuro. Il database AdventureWorks2012 archivia informazioni demografiche che descrivono i clienti precedenti. Usando l'algoritmo Microsoft Decision Trees per analizzare queste informazioni, il reparto marketing può creare un modello che stima se un determinato cliente acquisterà prodotti, in base agli stati delle colonne note relative al cliente, ad esempio dati demografici o modelli di acquisto precedenti.
Funzionamento dell'algoritmo
L'algoritmo Microsoft Decision Trees compila un modello di data mining creando una serie di divisioni nell'albero. Queste divisioni sono rappresentate come nodi. L'algoritmo aggiunge un nodo al modello ogni volta che viene rilevata una colonna di input in correlazione significativa con la colonna stimabile. Il modo in cui l'algoritmo determina una divisione è diverso a seconda che stia stimando una colonna continua o una colonna discreta.
L'algoritmo Microsoft Decision Trees usa la selezione delle funzionalità per guidare la selezione degli attributi più utili. La selezione delle funzionalità viene utilizzata da tutti gli algoritmi di data mining di Analysis Services per migliorare le prestazioni e la qualità dell'analisi. La selezione delle funzionalità è importante per evitare che gli attributi non importanti usino il tempo del processore. Se si usano troppi attributi di input o stimabili quando si progetta un modello di data mining, il modello può richiedere molto tempo per elaborare o persino esaurire la memoria. I metodi usati per determinare se suddividere l'albero includono metriche standard del settore per le reti entropia e Bayesian*.* Per altre informazioni sui metodi usati per selezionare attributi significativi e quindi assegnare punteggi e classificare gli attributi, vedere Selezione delle funzionalità (data mining).
Un problema comune nei modelli di data mining è che il modello diventa troppo sensibile alle piccole differenze nei dati di training, nel qual caso si dice che sia sovradimensionato o sottoposto a training eccessivo. Un modello con overfitted non può essere generalizzato in altri set di dati. Per evitare il sovradattamento su un determinato set di dati, l'algoritmo Microsoft di alberi decisionali utilizza tecniche per controllare la crescita dell'albero. Per una spiegazione più approfondita del funzionamento dell'algoritmo Microsoft Decision Trees, vedere Microsoft Decision Trees Algorithm Technical Reference (Informazioni di riferimento tecnico sull'algoritmo Microsoft Decision Trees).
Previsione delle colonne discrete
Il modo in cui l'algoritmo Microsoft Decision Trees crea un albero per una colonna stimabile discreta può essere dimostrato usando un istogramma. Il diagramma seguente mostra un istogramma che traccia una colonna prevedibile, Acquirenti di biciclette, rispetto a una colonna di input, Età. L'istogramma mostra che l'età di una persona aiuta a distinguere se quella persona acquisterà una bicicletta.

La correlazione illustrata nel diagramma causerebbe la creazione di un nuovo nodo nel modello da parte dell'algoritmo Microsoft Decision Trees.
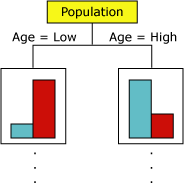
Quando l'algoritmo aggiunge nuovi nodi a un modello, viene creata una struttura ad albero. Il nodo principale dell'albero descrive la suddivisione della colonna prevedibile per la popolazione complessiva dei clienti. Man mano che il modello continua a crescere, l'algoritmo considera tutte le colonne.
Predizione delle colonne continue
Quando l'algoritmo Microsoft Decision Trees crea un albero basato su una colonna stimabile continua, ogni nodo contiene una formula di regressione. Una divisione si verifica a un punto di non linearità nella formula di regressione. Si consideri ad esempio il diagramma seguente.

Il diagramma contiene dati che possono essere modellati usando una singola riga o usando due linee connesse. Tuttavia, una singola riga eseguirà un lavoro insufficienti per rappresentare i dati. Se invece si usano due righe, il modello eseguirà un lavoro molto migliore per approssimare i dati. Il punto in cui le due linee vengono unite è il punto di non linearità e rappresenta il punto in cui un nodo in un modello di albero delle decisioni verrà suddiviso. Ad esempio, il nodo che corrisponde al punto di non linearità nel grafico precedente può essere rappresentato dal diagramma seguente. Le due equazioni rappresentano le equazioni di regressione per le due righe.

Dati necessari per i modelli di albero delle decisioni
Quando si preparano i dati per l'uso in un modello di albero delle decisioni, è necessario comprendere i requisiti per l'algoritmo specifico, inclusa la quantità di dati necessari e il modo in cui vengono usati i dati.
I requisiti per un modello di albero delle decisioni sono i seguenti:
Una singola colonna chiave Ogni modello deve contenere una colonna numerica o di testo che identifica in modo univoco ogni record. Le chiavi composte non sono consentite.
Colonna stimabile Richiede almeno una colonna stimabile. È possibile includere più attributi stimabili in un modello e gli attributi stimabili possono essere di tipi diversi, numerici o discreti. Tuttavia, l'aumento del numero di attributi stimabili può aumentare il tempo di elaborazione.
Colonne di input Richiede colonne di input, che possono essere discrete o continue. L'aumento del numero di attributi di input influisce sul tempo di elaborazione.
Per informazioni più dettagliate sui tipi di contenuto e sui tipi di dati supportati per i modelli di albero delle decisioni, vedere la sezione Requisiti di Riferimento tecnico sull'algoritmo Microsoft Decision Trees.
Visualizzazione di un modello di alberi decisionali
Per esplorare il modello, è possibile usare Microsoft Tree Viewer. Se il modello genera più alberi, è possibile selezionare un albero e il visualizzatore mostra una suddivisione di come i casi vengono classificati per ogni attributo prevedibile. È anche possibile visualizzare l'interazione degli alberi usando il visualizzatore di rete delle dipendenze. Per altre informazioni, vedere Browse a Model Using the Microsoft Tree Viewer.
Per altre informazioni dettagliate su qualsiasi ramo o nodo nell'albero, è anche possibile esplorare il modello usando Microsoft Generic Content Tree Viewer. Il contenuto archiviato per il modello include la distribuzione di tutti i valori in ogni nodo, probabilità a ogni livello dell'albero e formule di regressione per gli attributi continui. Per altre informazioni, vedere Contenuto del modello di data mining per i modelli di albero delle decisioni (Analysis Services - Data mining).
Creazione di stime
Dopo l'elaborazione del modello, i risultati vengono archiviati come set di modelli e statistiche, che è possibile usare per esplorare le relazioni o eseguire stime.
Per esempi di query da usare con un modello di albero delle decisioni, vedere Esempi di query sul modello decision trees.
Per informazioni generali su come creare query sui modelli di data mining, vedere Query di data mining.
Osservazioni:
Supporta l'uso di Predictive Model Markup Language (PMML) per creare modelli di data mining.
Supporta il drill-through.
Supporta l'uso di modelli di data mining OLAP e la creazione di dimensioni di data mining.
Vedere anche
Algoritmi di data mining (Analysis Services - Data mining)Riferimento Tecnico Algoritmo Microsoft Decision TreesEsempi di Query di Alberi DecisionaliContenuto del Modello di Mining per Modelli di Alberi Decisionali (Analysis Services - Data mining)