Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La qualità dei dati misura l'integrità dei dati in un'organizzazione. È possibile valutare la qualità dei dati usando i punteggi di qualità dei dati. Microsoft Purview Unified Catalog genera punteggi in base alla valutazione dei dati rispetto alle regole definite dall'utente.
Le regole di qualità dei dati sono linee guida essenziali che le organizzazioni stabiliscono per garantire l'accuratezza, la coerenza e la completezza dei dati. Queste regole consentono di mantenere l'integrità e l'affidabilità dei dati.
Ecco alcuni aspetti chiave delle regole di qualità dei dati:
Accuratezza: i dati devono rappresentare in modo accurato le entità reali. Il contesto è importante. Ad esempio, se si archiviano gli indirizzi dei clienti, assicurarsi che corrispondano alle posizioni effettive.
Completezza: questa regola identifica i dati vuoti, Null o mancanti. Convalida che tutti i valori siano presenti, anche se non necessariamente corretti.
Conformità: questa regola garantisce che i dati seguano gli standard di formattazione dei dati, ad esempio la rappresentazione di date, indirizzi e valori consentiti.
Coerenza: questa regola verifica che valori diversi dello stesso record siano conformi a una determinata regola e che non vi siano contraddizioni. La coerenza dei dati garantisce che le stesse informazioni siano rappresentate in modo uniforme tra record diversi. Ad esempio, se si dispone di un catalogo prodotti, i nomi e le descrizioni dei prodotti coerenti sono fondamentali.
Sequenze temporali: questa regola mira a garantire che i dati siano accessibili nel minor tempo possibile. Garantisce che i dati siano aggiornati.
Univocità: questa regola verifica che i valori non siano duplicati. Ad esempio, se si suppone che sia presente un solo record per cliente, non sono presenti più record per lo stesso cliente. Ogni cliente, prodotto o transazione deve avere un identificatore univoco.
Ciclo di vita della qualità dei dati
La creazione di regole di qualità dei dati è il sesto passaggio del ciclo di vita della qualità dei dati. I passaggi precedenti sono:
- Assegnare agli utenti le autorizzazioni di amministratore della qualità dei dati in Unified Catalog per usare tutte le funzionalità di qualità dei dati.
- Registrare ed analizzare un'origine dati in Microsoft Purview Data Map.
- Aggiungere l'asset di dati a un prodotto dati.
- Configurare una connessione all'origine dati per preparare l'origine per la valutazione della qualità dei dati.
- Configurare ed eseguire la profilatura dei dati per un asset nell'origine dati.
Ruoli obbligatori
- Per creare e gestire le regole di qualità dei dati, gli utenti hanno bisogno del ruolo di amministratore della qualità dei dati.
- Per visualizzare le regole di qualità esistenti, gli utenti hanno bisogno del ruolo lettore di qualità dei dati.
Visualizzare le regole di qualità dei dati esistenti
In Unified Catalog selezionare Gestione integrità e quindi Qualità dati.
Selezionare un dominio di governance e quindi selezionare un prodotto dati.
Selezionare un asset di dati dall'elenco Asset di dati.
Selezionare la scheda Regole per visualizzare le regole esistenti applicate all'asset.
Selezionare una regola per esplorare la cronologia delle prestazioni della regola applicata all'asset di dati selezionato.
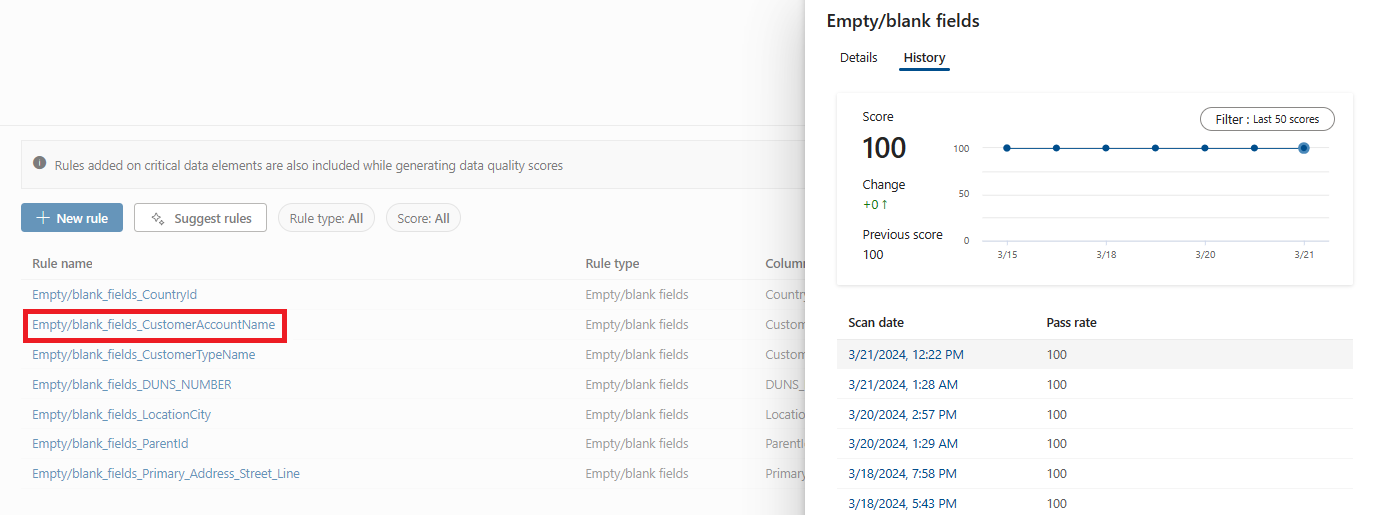

Regole di qualità dei dati disponibili
Qualità dei dati di Microsoft Purview abilita la configurazione delle regole seguenti. Queste regole sono disponibili all'inizio e offrono un modo di misurare la qualità dei dati con codice basso e senza codice.
| Regola | Definizione |
|---|---|
| Freschezza | Conferma che tutti i valori sono aggiornati. |
| Valori univoci. | Conferma che i valori in una colonna sono univoci. |
| Corrispondenza del formato stringa | Conferma che i valori di una colonna corrispondono a un formato specifico o ad altri criteri. |
| Corrispondenza del tipo di dati | Conferma che i valori in una colonna corrispondono ai requisiti relativi al tipo di dati. |
| Righe duplicate | Verifica la presenza di righe duplicate con gli stessi valori in due o più colonne. |
| Campi vuoti/vuoti | Cerca campi vuoti e vuoti in una colonna in cui devono essere presenti valori. |
| Ricerca tabella | Conferma che è possibile trovare un valore in una tabella nella colonna specifica di un'altra tabella. |
| Personalizzato | Creare una regola personalizzata con il generatore di espressioni visive. |
Freschezza
La regola di aggiornamento controlla se l'asset viene aggiornato entro il tempo previsto. La freschezza è determinata dalla selezione delle date dell'ultima modifica.
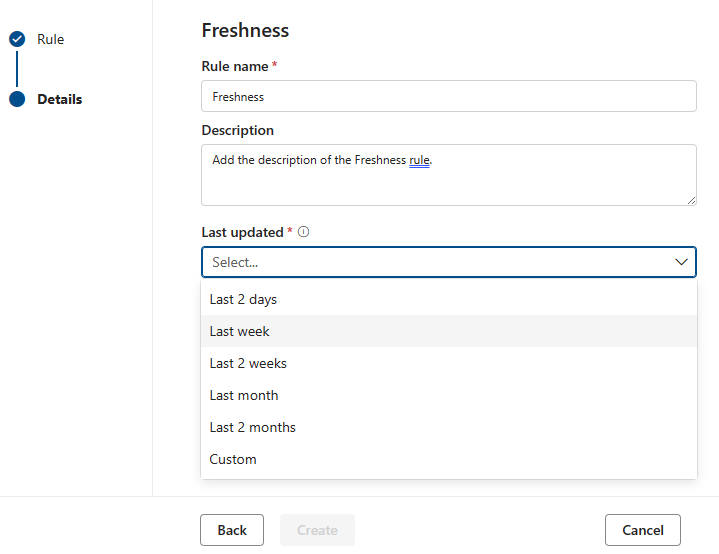
Nota
Il punteggio della regola di aggiornamento è 100 (passaggio) o 0 (esito negativo). La regola di aggiornamento non è supportata per Snowflake, Azure Databricks Unity Catalog, Google BigQuery, Synapse e Microsoft Azure SQL.
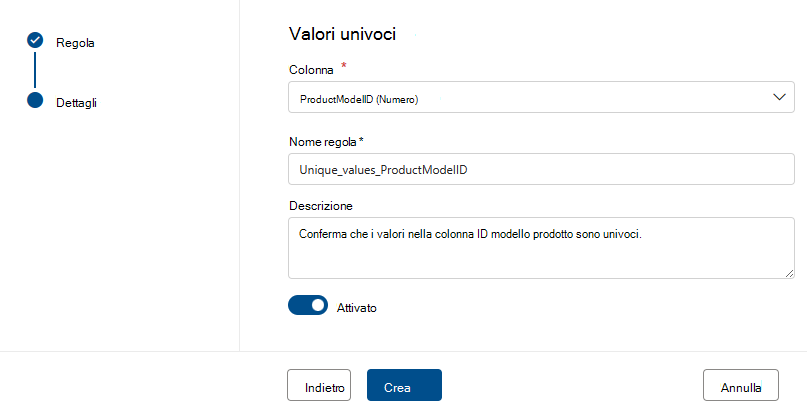
Valori univoci.
La regola Valori univoci indica che tutti i valori nella colonna specificata devono essere univoci. Tutti i valori univoci vengono considerati come pass e i valori non univoci vengono considerati come non riusciti. Se la regola Campi vuoti/vuoti non è definita nella colonna, i valori Null o vuoti vengono ignorati ai fini di questa regola.
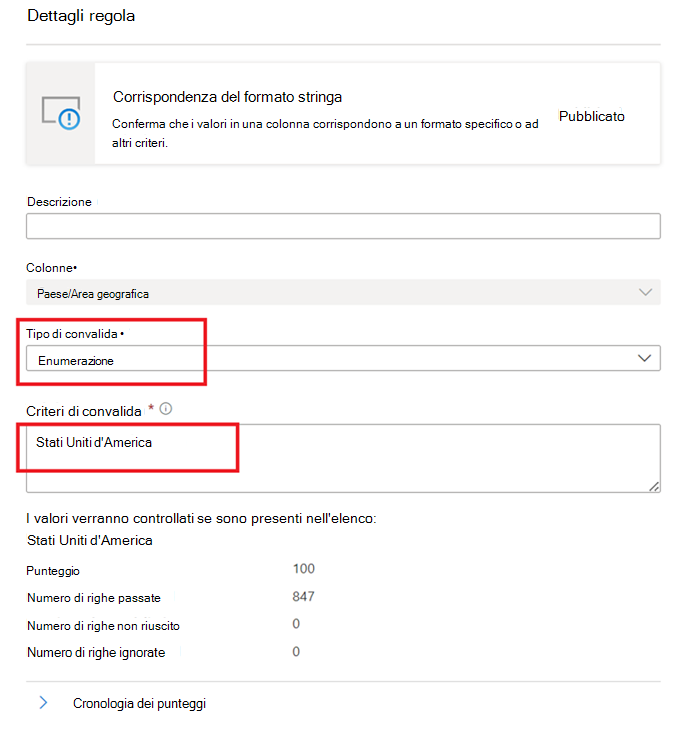
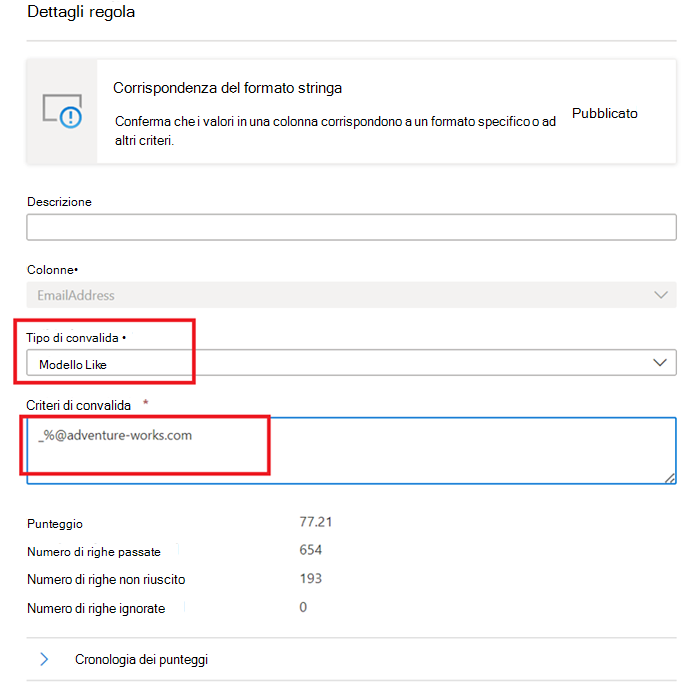
Corrispondenza del formato stringa
La regola Di corrispondenza formato controlla se tutti i valori nella colonna sono validi. Se non si definisce la regola Campi vuoti/vuoti in una colonna, la regola ignora i valori Null o vuoti.
Questa regola può convalidare ogni valore nella colonna usando tre approcci diversi:
-
Enumerazione: questo approccio usa un elenco di valori delimitato da virgole. Se il valore valutato non corrisponde a uno dei valori elencati, il controllo non riesce. È possibile eseguire l'escape di virgole e barre rovesciate usando una barra rovesciata (
\).a \, b, cContiene quindi due valori: il primo èa , be il secondo èc.
Come modello:
like(<i><string></i> : string, <i><pattern match></i> : string) => booleanil modello è una stringa che corrisponde letteralmente alla regola. Le eccezioni sono i simboli speciali seguenti: _ corrisponde a qualsiasi carattere nell'input (simile a nelleposixespressioni regolari) % corrisponde a.zero o più caratteri nell'input (simili alle.posixespressioni regolari). Il carattere di escape è.Se un carattere di escape precede un simbolo speciale o un altro carattere di escape, il carattere seguente corrisponde letteralmente. Non è valido eseguire l'escape di qualsiasi altro carattere.like('icecream', 'ice%') -> true
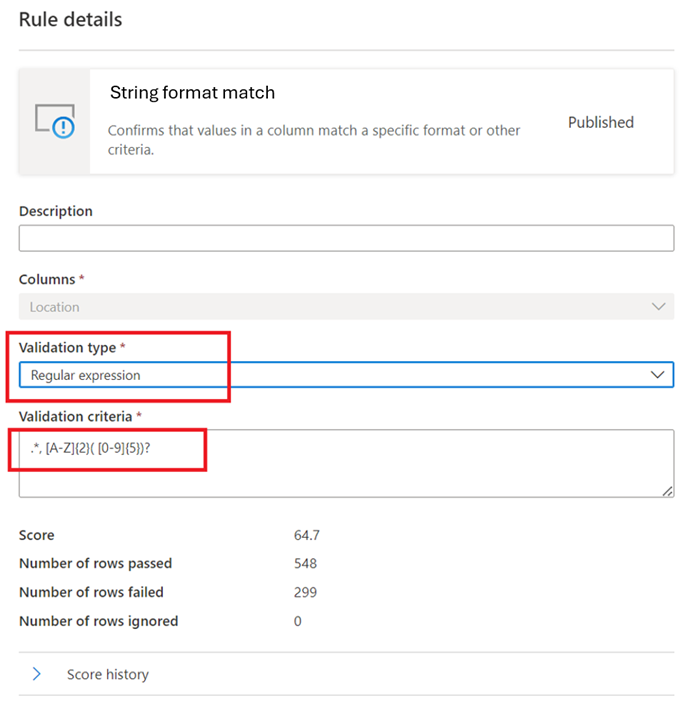
Espressione regolare:
regexMatch(<i><string></i> : string, <i><regex to match></i> : string) => booleanControlla se la stringa corrisponde al modello regex specificato. Usare
<regex>(virgolette indietro) per trovare la corrispondenza con una stringa senza escape.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
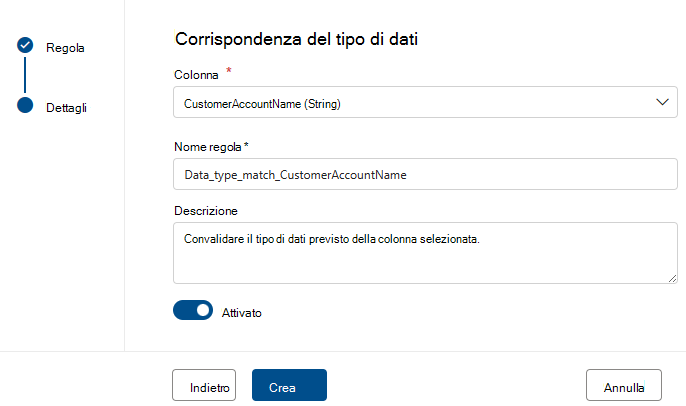
Corrispondenza del tipo di dati
La regola di corrispondenza Tipo di dati specifica il tipo di dati previsto per la colonna associata. Poiché il motore delle regole viene eseguito in molte origini dati diverse, non può usare tipi nativi come BIGINT o VARCHAR. Al contrario, usa il proprio sistema di tipi e converte i tipi nativi in questo sistema. Questa regola indica al motore di analisi della qualità quali dei relativi tipi predefiniti usare per il tipo nativo. Il sistema dei tipi di dati proviene dal sistema di tipi microsoft Azure Flusso di dati usato in Azure Data Factory.
Durante un'analisi della qualità, il motore testa tutti i tipi nativi in base al tipo di corrispondenza del tipo di dati. Se non riesce a convertire il tipo nativo nel tipo di corrispondenza del tipo di dati, considera tale riga come un errore.
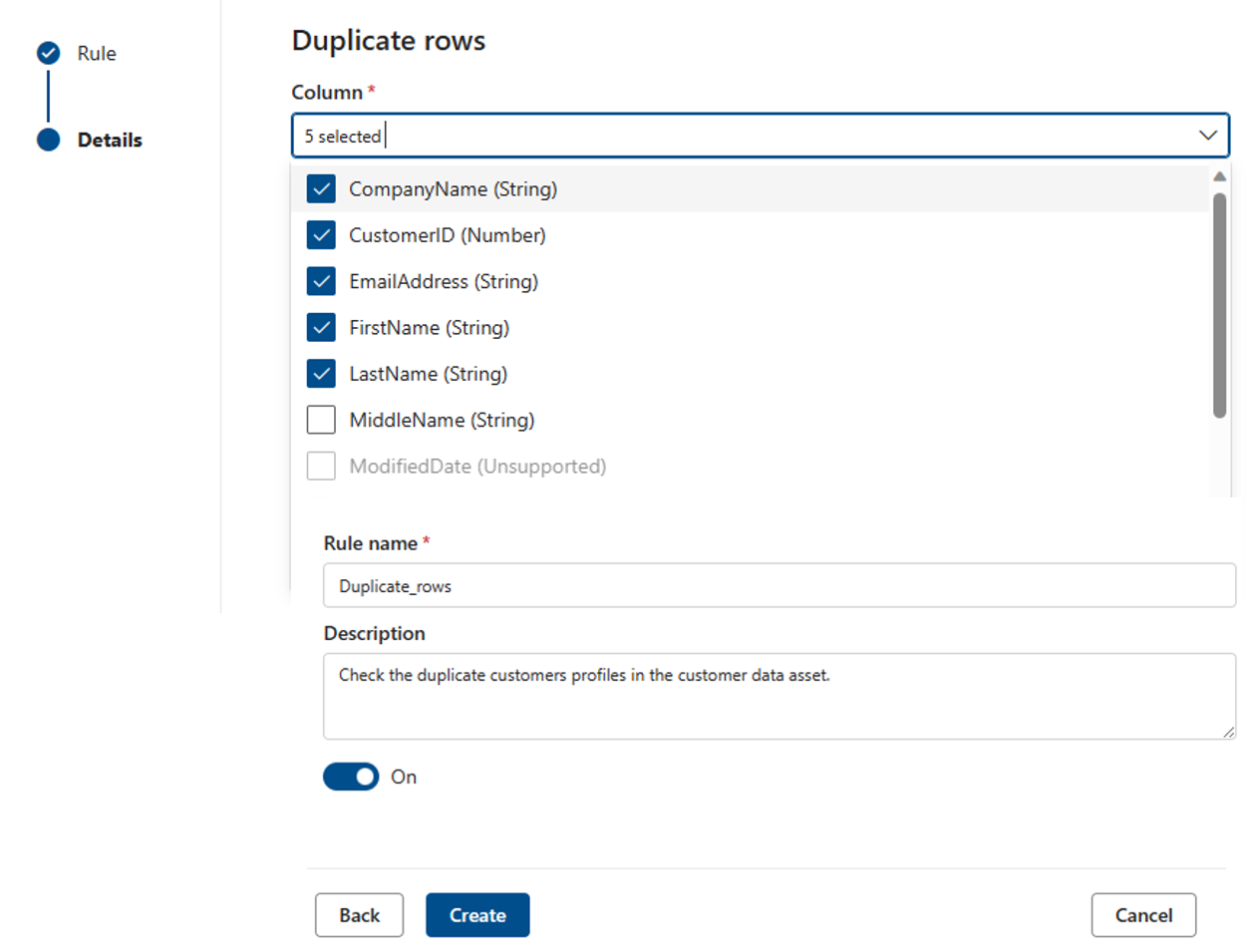
Righe duplicate
La regola Righe duplicate controlla se la combinazione dei valori nella colonna è univoca per ogni riga della tabella.
Nell'esempio seguente si prevede che la concatenazione di CompanyName, CustomerID, EmailAddress, FirstName e LastName produca un valore univoco per tutte le righe della tabella.
Ogni asset può avere zero o un'istanza di questa regola.
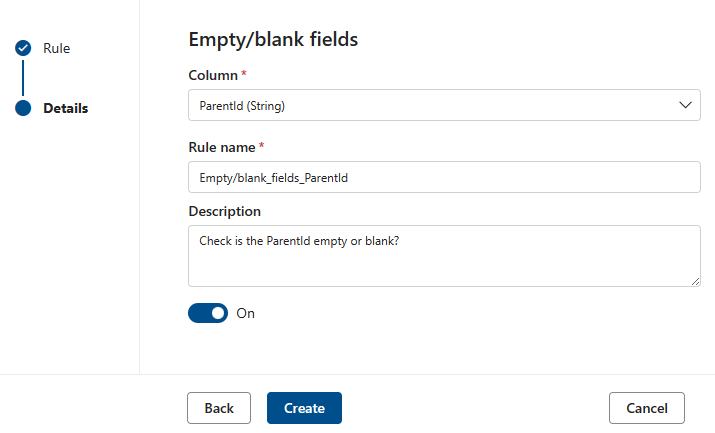
Campi vuoti/vuoti
La regola Campi vuoti/vuoti afferma che le colonne identificate non devono contenere valori Null. Per le stringhe, la regola non consente inoltre valori vuoti o solo spazi vuoti. Durante un'analisi della qualità dei dati, il motore considera qualsiasi valore in questa colonna non null come corretto. Questa regola influisce su altre regole, ad esempio i valori univoci o le regole di corrispondenza formato . Se non si definisce questa regola in una colonna, tali regole ignorano automaticamente tutti i valori Null quando vengono eseguiti su tale colonna. Se si definisce questa regola in una colonna, tali regole esaminano i valori Null o vuoti in tale colonna e li considerano a scopo di punteggio.
Ricerca tabella
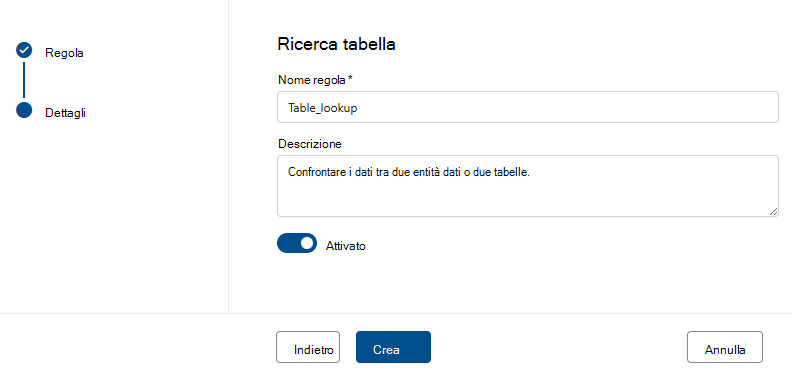
La regola di ricerca tabella esamina ogni valore nella colonna in cui si definisce la regola e la confronta con una tabella di riferimento. Ad esempio, una tabella primaria ha una colonna denominata "location" che contiene città, stati e codici postali nel formato "city, state zip". Una tabella di riferimento denominata "citystate" contiene tutte le combinazioni legali di città, stati e codici postali supportati nella Stati Uniti. L'obiettivo è confrontare tutte le posizioni nella colonna corrente con l'elenco di riferimento per assicurarsi che vengano usate solo combinazioni legali.
Per configurare questa regola, immettere il nome "citystatezip" nella finestra di dialogo degli asset di ricerca. Selezionare quindi l'asset desiderato e la colonna da confrontare.
Nota
La tabella di riferimento o l'asset di dati deve appartenere allo stesso dominio di governance. Non è possibile confrontare un asset di dati tra domini di governance diversi.
Regole personalizzate
La regola personalizzata consente di specificare regole che convalidano le righe in base a uno o più valori in tale riga. È possibile usare il linguaggio delle espressioni regolari, Azure Data Factory espressione e il linguaggio delle espressioni SQL per creare regole personalizzate.
Una regola personalizzata è composta da tre parti:
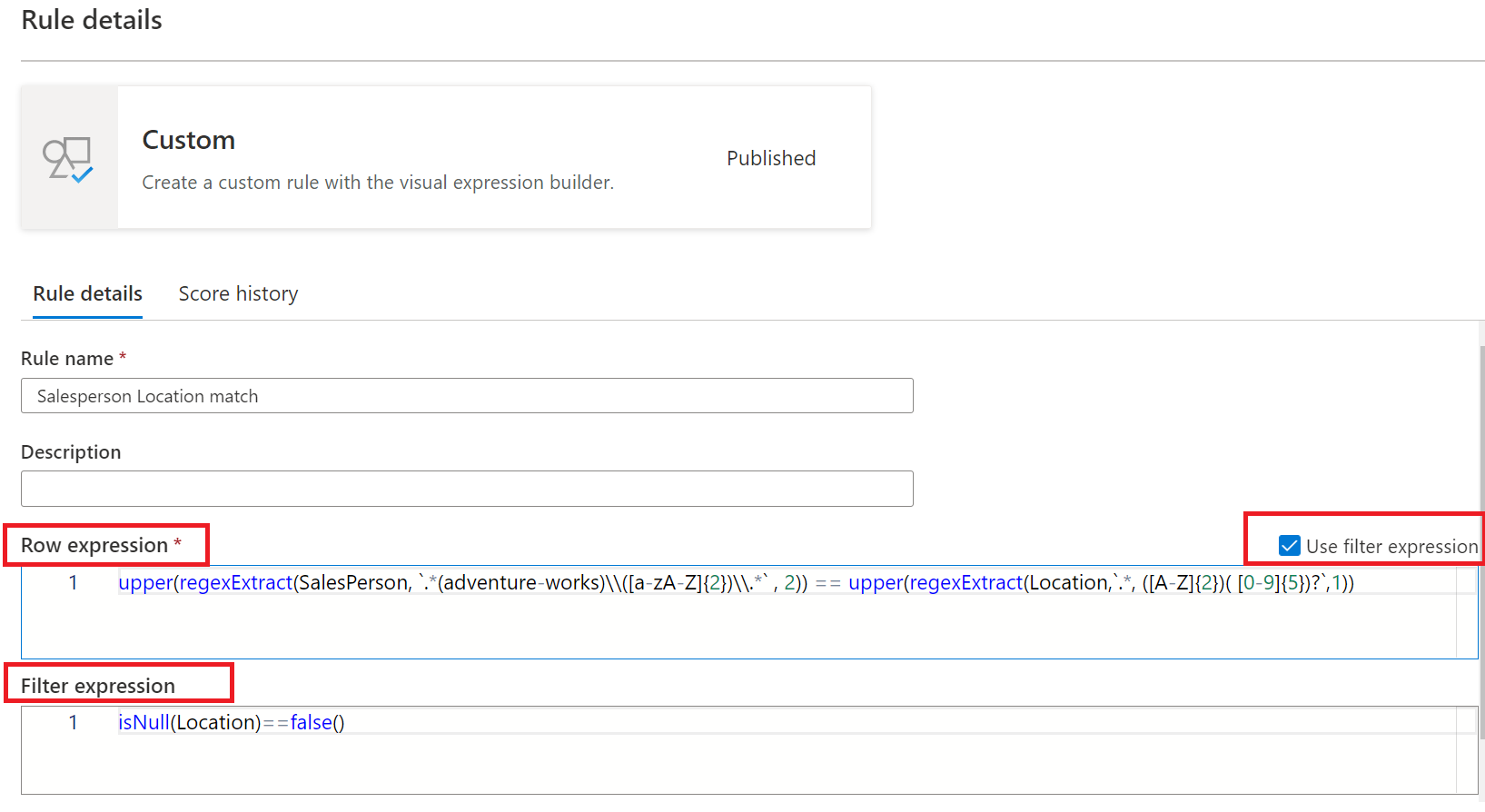
Espressione di riga: questa espressione booleana si applica a ogni riga approvata dall'espressione di filtro. Se questa espressione restituisce true, la riga passa. Se restituisce false, la riga ha esito negativo.
Espressione di filtro: questa condizione facoltativa limita il set di dati in cui viene valutata la condizione di riga. Per attivarla, selezionare la casella di controllo Usa espressione filtro . Questa espressione restituisce un valore booleano. L'espressione di filtro si applica a una riga e se restituisce true, tale riga viene considerata per la regola. Se l'espressione di filtro restituisce false per tale riga, significa che la riga viene ignorata ai fini di questa regola. Il comportamento predefinito dell'espressione di filtro consiste nel passare tutte le righe, quindi se non si specifica un'espressione di filtro, vengono considerate tutte le righe.
Espressione Null: controlla la modalità di gestione dei valori NULL. Questa espressione restituisce un valore booleano che gestisce i casi in cui mancano dati. Se l'espressione restituisce true, l'espressione di riga non viene applicata.
Ogni parte della regola funziona in modo analogo alle condizioni di Qualità dei dati di Microsoft Purview esistenti. Una regola passa solo se l'espressione di riga restituisce TRUE per il set di dati corrispondente all'espressione di filtro e gestisce i valori mancanti come specificato nell'espressione Null.
Esempio: una regola per garantire che "fareAmount" sia positiva e "tripDistance" sia valida:
- Espressione di riga: tripDistance > 0 AND fareAmount > 0
- Espressione di filtro: paymentType = 'CRD'
- Espressione Null: tripDistance IS NULL
Creare una regola personalizzata
- In Unified Catalog passare a Qualitàdei dati di gestione> dell'integrità.
- Selezionare un dominio di governance, selezionare un prodotto dati e quindi un asset di dati.
- Nella scheda Regole selezionare Nuova regola.
Creare una regola personalizzata usando l'espressione Azure Data Factory (ADF)
Per creare la regola usando un'espressione regolare o un'espressione ADF, selezionare Personalizzato dall'elenco di opzioni delle regole e quindi selezionare Avanti.
Aggiungere Nome regola e Descrizione, quindi selezionare Crea.
Esempi di regole personalizzate
| Scenario | Espressioni |
|---|---|
| Verificare se state_id è uguale alla California e aba_Routing_Number corrisponde a un determinato modello regex e la data di nascita rientra in un determinato intervallo | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Verificare se VendorID è uguale a 124 | {VendorID}=='124' |
| Controllare se fare_amount è uguale o maggiore di 100 | {fare_amount} >= "100" |
| Verificare se fare_amount è maggiore di 100 e tolls_amount non è uguale a 100 | {fare_amount} >= "100"||{tolls_amount} != "400" |
| Controllare se Rating è minore di 5 | Rating < 5 |
| Verificare se il numero di cifre nell'anno è 4 | length(toString(year)) == 4 |
| Confrontare due colonne bbToLoanRatio e bankBalance per verificare se i valori sono uguali | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Controllare se il numero di caratteri tagliati e concatenati in firstName, lastName, LoanID, uuid è maggiore di 20 | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Verificare se aba_Routing_Number corrisponde a un determinato modello regex e la data di transazione iniziale è maggiore di 2022-11-12 e Disallow-Listed è false e bankBalance media è maggiore di 50000 e state_id è uguale a 'Massachusetts', 'Tennessee', 'North Dakota' o 'Alabama' | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachusetts' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Alabama') |
| Verificare se aba_Routing_Number corrisponde a un determinato modello regex e dateOfBirth è compreso tra il 1968-12-13 e il 2020-12-13 | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Controllare se il numero di valori univoci in aba_Routing_Number è uguale a 1.000.000 e il numero di valori univoci in EMAIL_ADDR è uguale a 1.000.000 | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
Sia l'espressione di filtro che l'espressione di riga vengono definite usando il linguaggio dell'espressione Azure Data Factory, con il linguaggio definito qui. Tuttavia, non sono disponibili tutte le funzioni definite per il linguaggio di espressione ADF generico. L'elenco completo delle funzioni disponibili è disponibile nell'elenco Funzioni disponibile nella finestra di dialogo dell'espressione. Le funzioni seguenti definite in qui non sono supportate: isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, ricerca memorizzata nella cache e funzioni Window.
Nota
<regex> (virgolette indietro) può essere usato nelle espressioni regolari incluse nelle regole personalizzate per trovare la corrispondenza con la stringa senza eseguire l'escape di caratteri speciali. Il linguaggio delle espressioni regolari è basato su Java. Informazioni sulle espressioni regolari e Su Java e comprendere i caratteri che devono essere preceduti da caratteri di escape.
Creare una regola personalizzata usando un'espressione SQL
Le regole SQL personalizzate in Qualità dei dati di Microsoft Purview offrono un modo flessibile per definire i controlli di qualità dei dati usando predicati SQL Spark. Questa funzionalità consente agli utenti di creare regole direttamente in Spark SQL per scenari di convalida avanzati. È necessaria solo un'espressione di riga; le espressioni filter e Null sono facoltative per un'ulteriore personalizzazione. Usare regole SQL personalizzate per soddisfare requisiti aziendali complessi e migliorare la qualità dei dati, sfruttando tutte le funzionalità di Spark SQL. Le regole SQL personalizzate consentono una convalida dei dati complessa che potrebbe non essere possibile solo con le espressioni ADF. Scrivendo predicati Spark SQL, è possibile soddisfare esigenze aziendali specifiche e mantenere standard elevati di qualità dei dati.
Per creare la regola usando il linguaggio di espressione SQL, selezionare Personalizzato (SQL) dall'elenco di opzioni delle regole e quindi selezionare Avanti.
Aggiungere Nome regola e Descrizione, quindi selezionare Crea.
Scenario Espressioni Convalida i modelli di stringa corretti(ad esempio, rateCodeId a partire da '1' e numerico) e filtra in base ai tipi di pagamento validi. Row: rateCodeId RLIKE '^1[0-9]+$'Filter: paymentType IN ('CRD', 'CSH')Null: rateCodeId IS NULLGarantisce il corretto confronto delle colonne tra puLocationId e doLocationId e la tariffa rispetto alla distanza del viaggio. Row: puLocationId > doLocationId AND fareAmount > tripDistance * 10'Filter: paymentType <> 'CSH''Null: tripDistance IS NULLControlla se paymentType si trova in un determinato elenco (Carta, Contanti), filtrando le righe in base agli importi delle tariffe. Row: paymentType IN ('CRD', 'CSH')'Filter: fareAmount >= 50Null: paymentType IS NULLGarantisce che la distanza sia compresa in un intervallo inclusivo (5-10 miglia) durante la gestione di NULL e il filtro per i tipi di pagamento validi. Row: tripDistance BETWEEN 5 AND 10Filter: paymentType <> 'CRD'Null: tripDistance IS NULLGarantisce che il set di dati non superi un valore NULL del 20% per fareAmount. Row: (SELECT avg(CASE WHEN fareAmount IS NULL THEN 1 ELSE 0 END) FROM nycyellowtaxidelta1BillionPartitioned) < 0.20'Filter: vendorID IN ('VTS', 'CMT')Verifica che nel set di dati siano presenti almeno 2 valori paymentType distinti. Row: (SELECT count(DISTINCT paymentType) FROM nycyellowtaxidelta1BillionPartitioned) >= 2Filter: vendorID IN ('1', '2')Garantisce che l'importo medio della tariffa del set di dati rientri in un intervallo specificato (80 <= media <= 140). Row: (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) BETWEEN 80 AND 140 'Filter: paymentType IN ('CRD', 'CSH')Garantisce che il valore massimo tripDistance nel set di dati sia <= 10 miglia. Row: (SELECT max(tripDistance) FROM nycyellowtaxidelta1BillionPartitioned) <= 10.0Filter: vendorID IN ('VTS', 'CMT')Garantisce che la deviazione standard dell'importo tariffario sia inferiore a una determinata soglia (< 30). Row: (SELECT stddev_samp(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) < 30.0Filter: vendorID IN ('VTS', 'CMT')Garantisce che l'importo della tariffa mediano del set di dati sia compreso nella soglia specificata (<= 15). Row: (SELECT percentile_approx(fareAmount, 0.5) FROM nycyellowtaxidelta1BillionPartitioned) <= 15.0Filter: vendorID IN ('VTS', 'CMT')Garantisce che vendorId sia univoco nel set di dati all'interno di paymentType specifico. Row: COUNT(1) OVER (PARTITION BY vendorID) = 1Filter: paymentType IN ('CRD', 'CSH','1', '2')Null: vendorID IS NULLGarantisce che la combinazione di puLocationId e doLocationId sia univoca all'interno del set di dati. Row: COUNT(1) OVER (PARTITION BY puLocationId, doLocationId) = 1Filter: paymentType IN ('CRD', 'CSH')Null: puLocationId IS NULL OR doLocationId IS NULLGarantisce che vendorId sia univoco per ogni tipo di pagamento. Row: COUNT(1) OVER (PARTITION BY paymentType, vendorID) = 1 ,Filter: rateCodeId < 25, Null: vendorID IS NULLGarantisce che tpepPickupDateTime della riga sia maggiore di un timestamp di cutoff specificato. Row: tpepPickupDateTime >= TIMESTAMP '2014-01-03 00:00:00'Filter: paymentType IN ('CRD', 'CSG', '1', '2')Null: tpepPickupDateTime IS NULLOgni viaggio deve essere completato entro 1 ora Row: (unix_timestamp(tpepDropoffDateTime) - unix_timestamp(tpepPickupDateTime)) <= 3600Filter: paymentType IN ('CRD', 'CSH', '1', '2')Null: tpepPickupDateTime IS NULL OR tpepDropoffDateTime IS NULLMantiene solo il viaggio tariffario più alto per località di ritiro. Row: row_number() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1, Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0, Null: fareAmount IS NULL OR puLocationId IS NULLTutte le tariffe più alte legate per ogni passaggio di ritiro (non solo prima di row_number). Row: rank() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0Null: fareAmount IS NULL OR puLocationId IS NULLLa tariffa non deve diminuire nel tempo per ogni tipo di pagamento. Row: fareAmount >= lag(fareAmount) OVER (PARTITION BY paymentType ORDER BY tpepPickupDateTime)Null: tpepPickupDateTime IS NULL OR fareAmount IS NULLTariffa di ogni riga entro 10 della media del gruppo per tipo di pagamento. Row: abs(fareAmount - avg(fareAmount) OVER (PARTITION BY paymentType)) <= 10Filter: paymentType IN ('CRD', 'CSH','1','2')Null: fareAmount IS NULLIl totale delle distanze di viaggio non deve superare le 20 miglia. Row: sum(tripDistance) OVER (ORDER BY tpepPickupDateTime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) <= 20Filter: paymentType = '1'Null: tripDistance IS NULLControlla se la tariffa di ogni viaggio è superiore alla media globale per i fornitori idonei. Row: fareAmount > (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned)Filter: vendorID IN ('VTS', 'CMT')Null: fareAmount IS NULLControlla se tripDistance di ogni riga è maggiore del valore minimo per il relativo tipo di pagamento (carta/contanti). Row: tripDistance > (SELECT min(u.tripDistance) FROM (SELECT tripDistance, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD', 'CSH')Null: tripDistance IS NULLPer ogni corsa, verifica se la tariffa è superiore alla media per il tipo di pagamento Row: fareAmount > (SELECT avg(u.fareAmount) FROM (SELECT fareAmount, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD','CSH','1','2') AND vendorID IN ('VTS','CMT')Null: fareAmount IS NULLVerifica se la colonna fareAmount (numerica) può essere rappresentata correttamente come stringa corrispondente al modello numerico (numeri positivi con decimale facoltativo). Viene usato il cast come fareAmount è una colonna numerica. Row: CAST(fareAmount AS STRING) RLIKE '^[0-9]+(\.[0-9]+)?$'Filter: paymentType IN ('CRD', 'CSH')Null: fareAmount IS NULLGarantisce che tpepPickupDateTime sia un timestamp valido in formato yyyy-MM-dd HH:mm:ss. Questa colonna è già in formato DATETIME Row: to_timestamp(tpepPickupDateTime, 'yyyy-MM-dd HH:mm:ss') IS NOT NULLFilter: paymentType IN ('CRD','CSH')Null: tpepPickupDateTime IS NULLAssicura che i valori paymentType siano normalizzati in lettere minuscole e non abbiano spazi iniziali o finali. Row: lower(trim(paymentType)) IN ('card','cash') AND length(trim(paymentType)) > 0Null: paymentType IS NULL OR trim(paymentType) = ''Calcola in modo sicuro il rapporto tra tariffaAmount e tripDistance, assicurando che la divisione per zero non si verifichi controllando prima se tripDistance > 0. Row: CASE WHEN tripDistance > 0 THEN fareAmount / tripDistance ELSE NULL END >= 10Filter: tripDistance > 0 AND vendorID IN ('VTS', 'CMT')Viene illustrato come l'unione può sostituire i valori Null con valori predefiniti (ad esempio, 0,0) e garantisce che vengano restituite solo righe valide. Row: coalesce(fareAmount, 0.0) >= 5Filter: paymentType IN ('CRD','CSH')
Procedure consigliate per la scrittura di regole SQL personalizzate
- Mantenere le espressioni semplici. L'obiettivo è scrivere espressioni chiare e semplici da mantenere.
- Usare le funzioni SQL Spark predefinite. Usare la libreria completa di funzioni di Spark SQL per la manipolazione delle stringhe, la gestione delle date e le operazioni numeriche per ridurre al minimo gli errori e migliorare le prestazioni.
- Eseguire prima il test con un set di dati di piccole dimensioni. Convalidare le regole in un set di dati di piccole dimensioni prima di applicarle su larga scala per identificare i potenziali problemi in anticipo.
Limitazioni note e considerazioni per le regole delle espressioni SQL
Riferimenti di colonna ambigui e ombreggiatura delle colonne
Problema: quando una colonna viene visualizzata sia nella query esterna che nella sottoquery (o in parti diverse della query) con lo stesso nome, Spark SQL potrebbe non essere in grado di risolvere la colonna da usare. Questo problema causa errori logici o un'esecuzione di query non corretta. Questo problema può verificarsi in query annidate, sottoquery o join, causando ambiguità o ombreggiatura.
Ambiguità: si verifica quando un nome di colonna è presente sia nella query esterna che nella sottoquery senza una qualificazione chiara, causando un'incertezza su quale colonna fare riferimento a Spark SQL.
Ombreggiatura: fa riferimento a quando una colonna nella query esterna viene "sottoposta a override" o "ombreggiata" dalla stessa colonna nella sottoquery, causando l'ignorare il riferimento esterno.
Espressione di esempio:
distance_km > ( SELECT min(distance_km) FROM Tripdata t WHERE t.payment_type = payment_type -- ambiguous outer reference )Problema: il payment_type non qualificato viene risolto nell'ambito più vicino con una colonna con tale nome, ovvero il t.payment_type interno, non l'payment_type della riga esterna. In questo modo il predicato viene trasformato in t.payment_type = t.payment_type (sempre TRUE), quindi la sottoquery diventa un min globale anziché un min di gruppo.
Soluzione: per risolvere questa ambiguità ed evitare l'ombreggiatura della colonna, rinominare la colonna interna nella sottoquery, assicurando che l'payment_type della query esterna rimanga non ambigua.
Espressione corretta:
distance_km >
(
SELECT min(u.distance_km)
FROM (
SELECT distance_km, payment_type AS pt
FROM Tripdata
) u
WHERE u.pt = payment_type -- this `payment_type` now binds to OUTER row
)
- Nella sottoquery la colonna payment_type viene aliasata come pt (ovvero payment_type AS pt) e you.pt viene usata nella condizione .
- Nella query esterna è ora possibile fare riferimento chiaramente al payment_type originale e Spark SQL lo risolve correttamente come payment_type esterno.
Operazioni finestra (considerazioni sulle prestazioni)
- Le operazioni della finestra, ad esempio ROW_NUMBER() e RANK() possono essere costose, soprattutto per set di dati di grandi dimensioni. Usarli con giudizio e testare le prestazioni su set di dati più piccoli prima di applicarli su larga scala. Prendere in considerazione l'uso di PARTITION BY per ridurre l'ambito dei dati.
Escape dei nomi di colonna in Spark SQL
- Se i nomi di colonna contengono caratteri speciali, ad esempio spazi, trattini o altri caratteri non alfanumerici, è necessario eseguirne l'escape tramite backticks.
- Esempio se il nome della colonna è order-id e la regola deve essere maggiore di 10.
- Espressione non corretta: order-id > 10
- Espressione corretta:
`order-id`> 10
Nome dell'asset di dati che fa riferimento nelle espressioni
Quando si fa riferimento all'asset di dati nelle espressioni SQL, è necessario seguire regole di sanificazione specifiche. Non è necessario aggiornare il nome dell'asset di dati originale, ma il nome dell'asset di dati a cui si fa riferimento nelle espressioni SQL deve essere purificato per soddisfare i criteri seguenti:
| Regola | Descrizione | Esempio- Nome originale | Esempio- Nome purificato |
|---|---|---|---|
| Caratteri consentiti | Sono consentite solo lettere (A-Z, a-z), numeri (0-9) e caratteri di sottolineatura (_). I caratteri speciali (spazi, trattini, punti e così via) devono essere rimossi. | my-dataset_v1+2023 | mydataset_v12023 |
| Taglia caratteri di sottolineatura | I caratteri di sottolineatura all'inizio o alla fine del nome devono essere rimossi. | my_dataset_ | my_dataset |
| Limite di caratteri | Il nome finale purificato non deve superare i 64 caratteri. | [Nome lungo che supera i 64 caratteri] | [I primi 64 caratteri del nome purificato] |
Se il nome dell'asset di dati segue già queste linee guida, ovvero non contiene caratteri speciali, caratteri di sottolineatura iniziali/finali ed è compreso nel limite di 64 caratteri, può essere usato così come è nelle espressioni SQL senza alcuna modifica.
Come purificare il nome di un set di dati
Seguire questa procedura per assicurarsi che il nome del set di dati sia valido per le espressioni SQL:
- Rimuovi caratteri speciali: rimuove tutti i caratteri tranne lettere, numeri e caratteri di sottolineatura.
- Taglia caratteri di sottolineatura: rimuovere i caratteri di sottolineatura iniziali o finali.
- Troncamento: se il nome risultante supera i 64 caratteri, troncarlo in modo che rientri nel limite di 64 caratteri.
Esempio: Nome asset di dati f07d724d-82c9-4c75-97c4-c5baf2cd12a4.parquet
- Rimuovi caratteri speciali: f07d724d82c94c7597c4c5baf2cd12a4parquet
- Taglia i caratteri di sottolineatura: (N/D in questo caso, in quanto non sono presenti caratteri di sottolineatura iniziali o finali).
- Troncamento: il nome risultante è lungo 54 caratteri, che è inferiore al limite di 64 caratteri.
Nome di riferimento SQL finale: f07d724d82c94c7597c4c5baf2cd12a4parquet
Nota
Il nome dell'asset di dati originale rimane invariato. Solo il nome dell'asset di dati usato nelle espressioni SQL deve seguire queste regole. Per i nomi di colonna che contengono caratteri speciali, ad esempio spazi o trattini, è possibile eseguirne l'escape usando virgolette in espressioni SQL.
I join non sono supportati
Le regole SQL personalizzate in Qualità dei dati di Microsoft Purview non supportano i join. Le regole devono funzionare su un singolo set di dati. Non è possibile unire più tabelle o set di dati durante la scrittura di queste regole personalizzate.
Operazioni SQL non supportate (DML, DCL e SQL dannoso)
Le regole SQL personalizzate non supportano le operazioni DML (Data Manipulation Language) o DCL (Data Control Language), ad esempio INSERT, UPDATE, DELETE, GRANT e altre operazioni SQL dannose, ad esempio TRUNCATE, DROP e ALTER. Queste operazioni non sono supportate perché modificano i dati o lo stato del database.
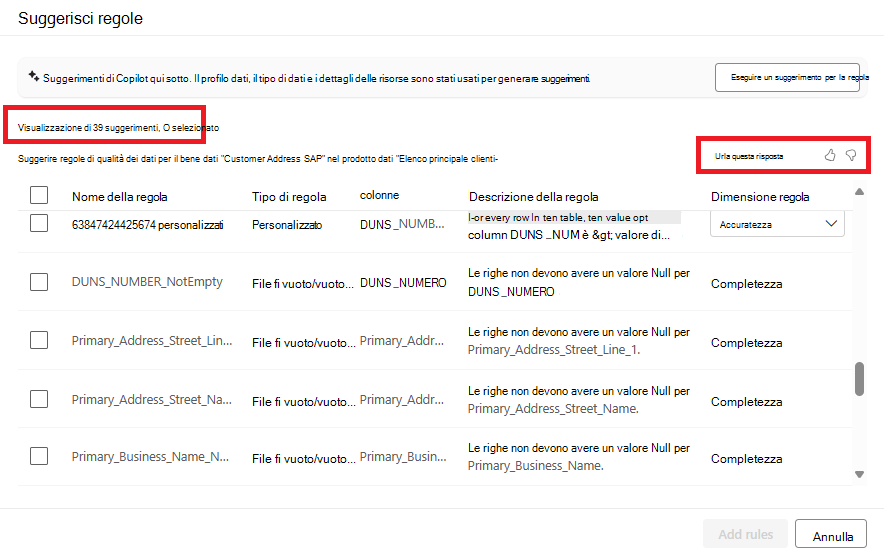
Regole generate automaticamente con intelligenza artificiale
La generazione automatizzata di regole assistita dall'intelligenza artificiale per la misurazione della qualità dei dati usa tecniche di intelligenza artificiale (IA) per creare automaticamente regole per valutare e migliorare la qualità dei dati. Le regole generate automaticamente sono specifiche del contenuto. La maggior parte delle regole comuni viene generata automaticamente in modo che non sia necessario dedicare molto impegno alla creazione di regole personalizzate.
Per esplorare e applicare regole generate automaticamente:
Nella scheda Regole di un asset di dati selezionare Suggerisci regole.
Esplorare l'elenco delle regole suggerite.
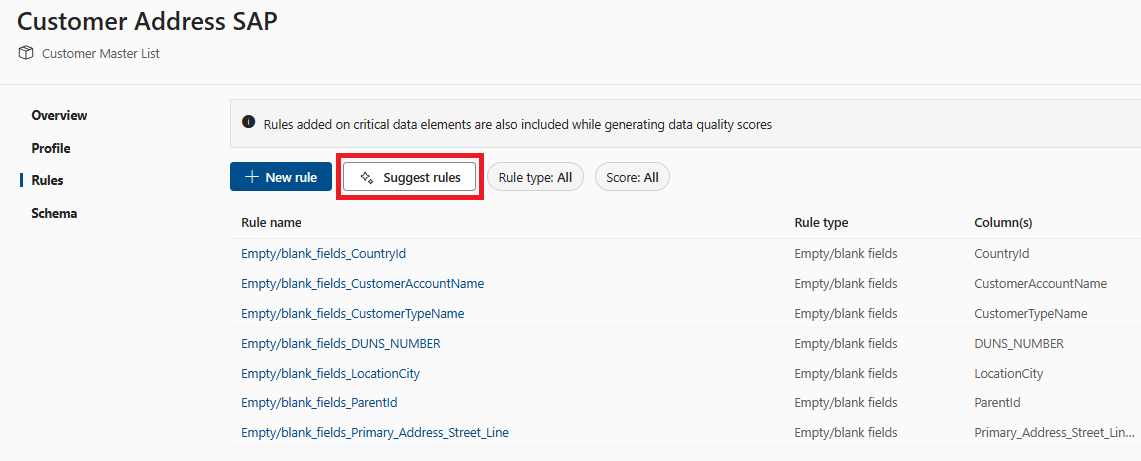
Selezionare le regole dall'elenco di regole suggerite da applicare all'asset di dati.


Passaggi successivi
- Configurare ed eseguire un'analisi della qualità dei dati in un prodotto dati per valutare la qualità di tutti gli asset supportati nel prodotto dati.
- Esaminare i risultati dell'analisi per valutare la qualità dei dati corrente del prodotto dati.