Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'identificazione e la classificazione accurate dei dati sono alla base di una sicurezza dei dati affidabile. Consente alle aziende di distribuire con sicurezza i criteri di protezione dei dati nel digital estate. Microsoft Purview supporta questo passaggio critico con tipi di informazioni sensibili (SIT) e tecnologie di classificazione avanzate come Exact Data Match (EDM),classificatori sottoponibili a training e impronta digitale dei documenti.
Tuttavia, per controllare il volume dei falsi positivi, è necessario configurare e applicare questi strumenti nei contesti e negli scenari corretti. Un falso positivo significa che il sistema contrassegna erroneamente qualcosa come corrispondenza anche se non lo è. Falsi positivi:
- Aumento dell'affaticamento degli avvisi : sovraccarica i team di sicurezza e conformità, aumentando la probabilità di rischi reali che scorrono.
- Svuotamento di tempo e risorse : la verifica dei falsi positivi comporta un'escalation dei costi operativi, in particolare per le aziende che gestiscono volumi di dati elevati.
- Ostacoli non necessari nelle attività quotidiane : la restrizione di accesso applicata in modo non corretto al contenuto che non è sensibile causa attriti nei flussi di lavoro e nella produttività.
- Riduzione della fiducia degli utenti nella soluzione : riduce l'adozione complessiva del prodotto.
È quindi importante avere una chiara comprensione dell'utilità e della rilevanza dei SIT e dei classificatori avanzati per la diversità degli scenari aziendali in un'azienda. Questo progetto spiega quando, perché e come usare le varie tecnologie di classificazione dei dati di Microsoft Purview, riducendo al minimo i falsi positivi per migliorare l'accuratezza e l'attendibilità.
Approfondimento del progetto
Questo articolo illustra come ridurre i falsi positivi usando le funzionalità di classificazione seguenti fornite da Microsoft Purview:
- Classificazione del sistema: rilevamento dei dati sensibili basato su pattern
- Exact Data Match (EDM): corrispondenza precisa con dati con hash
- Classificatore sottoponibile a training : classificazione del contenuto personalizzata basata su intelligenza artificiale
-
Rilevamento delle impronte digitali dei documenti - Rilevamento di documenti basato su modello
| Tecnologia di classificazione | Tipico caso d'uso | Perché? |
|---|---|---|
| Si siede | Identificazione di tipi di dati sensibili comuni che sono ampiamente riconosciuti e seguono modelli standardizzati. Ad esempio, numeri di carta di credito, SSN | Distribuibile rapidamente con una configurazione minima, insieme al supporto predefinito |
| Corrispondenze di dati esatte | Scenari che richiedono una corrispondenza precisa dei dati da un'origine dati nota. Ad esempio, il rilevamento di numeri di conto cliente specifici, ID dipendente o ID paziente all'interno di un'organizzazione | Riduce al minimo i falsi positivi contrassegnando solo i dati che corrispondono esattamente alle voci nella tabella dati di riferimento caricata |
| Classificatore sottoponibile a training | Identificazione di dati complessi e contestuali, documenti con struttura varia e formato imprevedibile in cui i modelli tradizionali non si applicano. Ad esempio, documenti legali con clausole e formati diversi | Fornisce un approccio personalizzabile e intelligente ai tipi di dati complessi |
| Impronta digitale dei documenti | Casi d'uso in cui il modello di documento e la formattazione sono coerenti nell'intera organizzazione. Ad esempio, contratti e fatture aziendali, richieste RFP o moduli standard contenenti dati sensibili | Fornisce protezione mirata per documenti critici e strutturati |
Panoramica del progetto
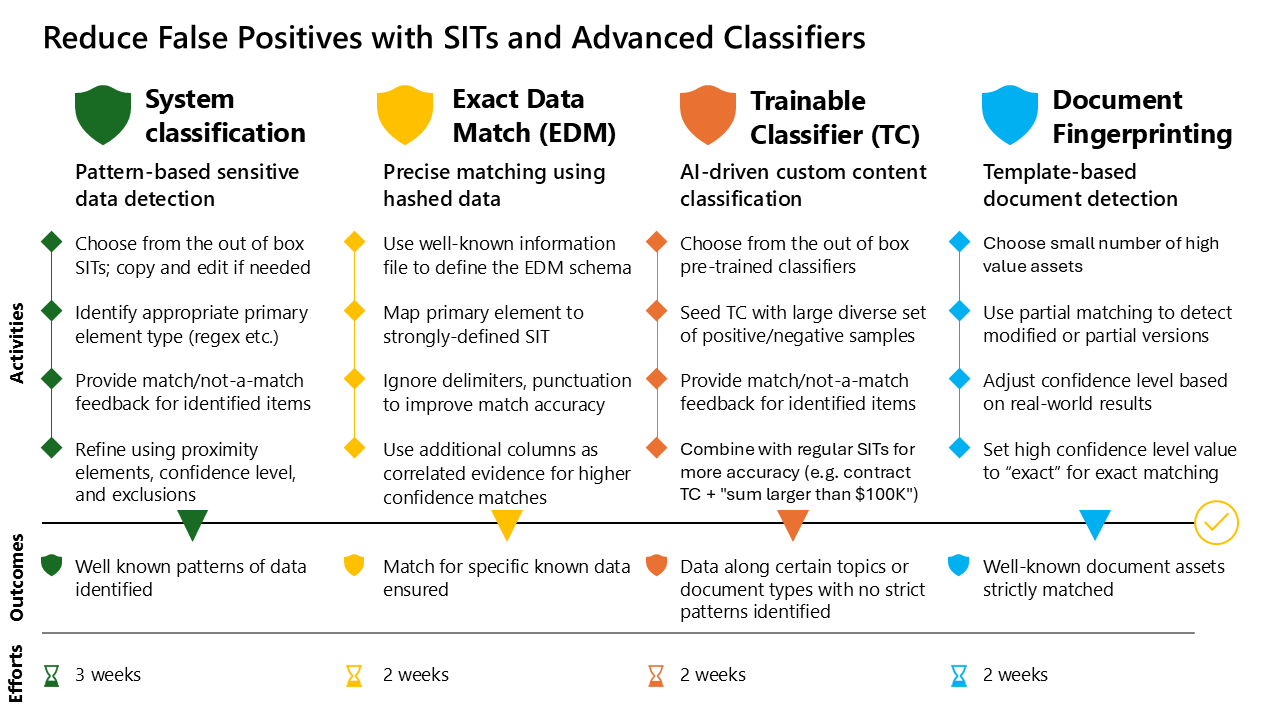
Classificazione del sistema: rilevamento dei dati sensibili basato su pattern
Per usare i SIT per la sicurezza dei dati nell'azienda digitale, è importante avere una visione completa del patrimonio dati. Eseguire quindi il mapping dei dati sensibili prima di tutto per identificare i tipi di dati sensibili presenti nell'azienda e dove si trovano.
Scegliere tra i SIT predefiniti; copiare e modificare, se necessario
Iniziare con i SIT predefiniti forniti da Microsoft. Per altre informazioni sui SIT, vedere Informazioni sui tipi di informazioni riservate | Microsoft Learn. Se non soddisfano le tue esigenze così come sono, clonarle e modificarle per renderle esattamente rilevanti per il contesto aziendale. Per altre informazioni sulla personalizzazione di un sit predefinito, vedere Personalizzare un tipo di informazioni riservate predefinito | Microsoft Learn.
Creare SIT personalizzati da zero per soddisfare completamente le esigenze di classificazione dei dati univoche dell'organizzazione. Per altre informazioni sulla creazione di un sit personalizzato, vedere Creare tipi di informazioni sensibili personalizzati | Microsoft Learn. Usare più modelli in una singola definizione SIT per garantire l'identificazione completa del tipo di dati sensibili di destinazione. Ad esempio, un SIT creato per identificare la data di nascita deve tenere conto di formati diversi (DD/MM/AAAA, MM/GG/AAAA e così via). Questo approccio garantisce una copertura inclusiva di tutti gli scenari e i casi d'uso.
Usare la funzionalità di classificazione su richiesta in Purview per testare i SIT personalizzati su esempi di dati di destinazione. Questa funzionalità consente l'iterazione rapida osservando il comportamento di rilevamento reale in un ambito controllato. Anche se la clonazione di SIT predefiniti e la creazione di SIT personalizzati offrono flessibilità, in particolare per i repository di dati legacy o ad accesso sporadico, è necessario crearli con attenzione per evitare risultati controproduttivi come falsi positivi e affaticamento degli avvisi.
Usare più SIT in una regola dei criteri DLP per creare una strategia di rilevamento più completa e precisa. Ad esempio, quando si è interessati al rilevamento delle informazioni personali, la scelta di una combinazione di SIT che coprono SSN, numero di patente di guida, numero di passaporto e così via, con una condizione OR è un approccio più ragionevole anziché dipendere esclusivamente da SSN. Inoltre, la configurazione di più SIT in un criterio DLP è essenziale quando i dati sensibili sono accompagnati da informazioni contestuali. Ad esempio, mentre un SSN da solo richiede protezione da perdite o uso improprio, il rischio aumenta in modo significativo quando viene visualizzato insieme ai dati correlati, ad esempio un nome o una data di nascita. In questi casi, una protezione più forte e garantita diventa imperativa per prevenire potenziali violazioni.
Identificare il tipo di elemento primario appropriato (regex e così via) nella configurazione SIT
Quando si definisce l'elemento primario, scegliere tra quattro opzioni: Espressione regolare (regex), Elenco parole chiave, Dizionario parole chiave o Funzione. Seguire queste indicazioni per ogni tipo:
| Tipo di elemento primario | Consigli principali |
|---|---|
| Espressione regolare | - Usare le asserzioni lookaround nel modello regex ovunque applicabile per garantire il contesto e ridurre corrispondenze irrilevanti. Le asserzioni lookaround in regex consentono di verificare se esiste un determinato modello prima (lookbehind) o dopo (lookahead) di un altro modello senza includerlo nella corrispondenza. - Convalidare i modelli regex rispetto a set di dati diversi per ottimizzare l'accuratezza e ridurre i falsi positivi. - Se è necessario rilevare stringhe isolate (ad esempio, non fanno parte di una stringa più lunga), usare \b all'inizio e alla fine dell'espressione regolare o selezionare l'opzione per usare "corrispondenza parola" anziché "corrispondenza stringa". - La sintassi delle espressioni regolari supportata varia in base a ogni singola implementazione. Tenere presente limiti e limitazioni specifici nella libreria di espressioni regolare usata da Purview. - È possibile migliorare il rilevamento usando altri validator predefiniti con una logica che non è possibile usando solo il linguaggio delle espressioni regolari. Ad esempio, è possibile controllare i valori corrispondenti per le cifre del checksum o altri algoritmi simili per ridurre i falsi positivi. |
| Elenco di parole chiave | - Usare la funzionalità di maiuscole e minuscole durante la definizione dell'elenco in base alla necessità o meno di maiuscole e minuscole esatte per rilevare le corrispondenze. - Nelle lingue delimitate da spazi (ad esempio, le lingue occidentali), usare "word match" anziché "string match" per una maggiore precisione. Ad esempio, la parola chiave "flu" corrisponderebbe a parole come influence e fluent se si sceglie string-match, ma non se si sceglie word-match.For instance, keyword "flu" would match with words like influence and fluent if string-match is chosen, but not if you choose word-match. Word corrispondenza è ideale per rilevare parole chiave autonome con delimitatori su entrambi i lati. Tuttavia, spesso mancano i rilevamenti quando le parole chiave vengono visualizzate all'interno di altre parole, soprattutto in lingue non delimitate da spazio come cinese, giapponese, tailandese e coreano. In questi casi, la corrispondenza di stringhe è rilevante perché migliora l'accuratezza della classificazione rilevando le parole chiave anche quando sono incorporate all'interno di parole o frasi più grandi. |
| Dizionario parole chiave | - Usare questo tipo sopra l'elenco di parole chiave quando è necessaria una gestione più semplice delle parole chiave su larga scala. Tenere presente il limite di 1 MB di testo compresso in tutti i dizionari nel tenant. - I dizionari di parole chiave non fanno sempre distinzione tra maiuscole e minuscole e supportano sia il rilevamento basato su "corrispondenza di parole" che "corrispondenza stringa". |
| Funzione | - Identificare la funzione appropriata da un elenco di funzioni predefinite. Queste funzioni si comportano in modo simile alle espressioni regolari, ma con funzionalità più programmatiche. |
Perfezionare usando elementi di prossimità, livello di confidenza ed esclusioni
Fornire elementi di supporto come prova corroborativa insieme all'elemento primario per aumentare la attendibilità rispetto all'accuratezza delle corrispondenze rilevate. Nell'esempio di data di nascita fornito in precedenza, la semplice corrispondenza di un formato di data per la data di nascita può portare a falsi positivi enormi da intestazioni di posta elettronica, timestamp e date non correlate. Di conseguenza, l'aggiunta di elementi di supporto come parole chiave (DOB, DateOfBirth e così via) diventa fondamentale per rilevare solo corrispondenze con attendibilità elevata.
Impostare il limite di prossimità su 300 caratteri per qualsiasi nuovo sit personalizzato. Mentre 300 è l'intervallo predefinito che offre un buon equilibrio tra prestazioni e copertura, è possibile scegliere un intervallo inferiore a seconda del caso d'uso, evitando di elevarlo a un limite eccessivamente elevato. La configurazione di SIT personalizzati con prossimità illimitata ("ovunque nel documento") non è pratica, in quanto genera troppi falsi positivi e può anche influire sulle prestazioni, in particolare durante l'elaborazione di set di dati tabulari di grandi dimensioni. Per migliorare il rilevamento in particolare nei dati tabulari di grandi dimensioni, usare l'opzione
RelaxProximityche è possibile configurare usando PowerShell. Consente una corrispondenza più rilassata nei casi in cui gli elementi primari e di supporto sono molto distanti.Specificare un livello di confidenza più elevato per i modelli con più elementi di supporto o espressioni regolari più restrittive. Se il sit definito ha pochi o nessun elemento di supporto in prossimità dell'elemento primario, impostare il livello di confidenza su basso.
Per migliorare ulteriormente l'accuratezza della corrispondenza, usare controlli aggiuntivi che includono o escludono testo e modelli, prefissi o suffissi specifici. È possibile escludere dati specifici che non sono sensibili o potrebbero essere erroneamente identificati da SIT come sensibili. Questo approccio riduce il numero di falsi positivi.
Ottimizzare l'efficacia della configurazione SIT usando la funzionalità di test (Testare un tipo di informazioni riservate | Microsoft Learn) per convalidare l'accuratezza di SIT. Inoltre, usare Esplora contenuto per esaminare le corrispondenze rilevate rispetto al sit definito. Questi approcci garantiscono che il sit sia ottimizzato convalidando gli elementi di supporto, l'intervallo di prossimità, il livello di attendibilità e altri parametri di rilevamento critici, potenziando la strategia di protezione dei dati.
Fornire feedback di corrispondenza e non corrispondenza per gli elementi identificati
Inviare regolarmente il feedback per tutti gli elementi corrispondenti per consentire a Microsoft di ottimizzare i propri SIT. Per ogni elemento di questo tipo in SharePoint e OneDrive, Microsoft Purview consente di fornire commenti e suggerimenti in termini di corrispondenza (vero positivo) o meno (falso positivo). Inoltre, è possibile scegliere di inviare a Microsoft una versione redacted dell'elemento. L'invio di una copia redatta insieme ai commenti e suggerimenti consente di migliorare l'accuratezza dei SIT pubblicati da Microsoft. Se non si vuole inviare una copia redacted, Microsoft si basa solo sui risultati della classificazione e sui metadati associati per migliorare l'accuratezza.
Exact Data Match (EDM): corrispondenza precisa con dati con hash
Microsoft Purview consente di identificare dati sensibili noti specifici nel data estate usando EDM. Per altre informazioni su EDM e sul suo funzionamento, vedere Informazioni sui tipi di informazioni sensibili basati sulla corrispondenza dei dati esatti | Microsoft Learn.
Usare informazioni note per definire lo schema EDM
Caricare un file di esempio e usare l'automazione fornita da Microsoft Purview per definire lo schema. Per altre informazioni, vedere Introduzione ai tipi di informazioni sensibili basati sulla corrispondenza esatta dei dati | Microsoft Learn.
Eseguire il mapping dell'elemento primario a un'istanza di SIT fortemente definita
Selezionare come colonne di elementi primari che contengono dati fortemente strutturati, ad esempio SSN o numeri di carta di credito, e usare un SIT fortemente definito come SIT di base per gli elementi primari. Quando si esegue il mapping del campo primario nello schema a un sit definito in modo flessibile che copre un'ampia gamma di valori, le prestazioni del classificatore EDM ne risentiranno. Questa riduzione delle prestazioni comporta scenari di limitazione o timeout che causano rilevamenti mancanti. Gli esempi seguenti di SIT "loose" devono essere in genere evitati:
Numeri semplici di meno di cinque cifre (troppo comuni).
Qualsiasi parola regexes (interfaccia utente EDM impedisce l'uso della maggior parte di tali SIT, ma alcuni potrebbero eseguire il rilevamento di escape).
Email indirizzo SIT che non esclude il dominio dell'azienda (poiché corrisponde a ogni messaggio di posta elettronica).
Data di nascita SIT che non esclude date recenti o future (è improbabile che tali date siano la data di nascita di un utente diversa da quella dell'assistenza sanitaria).
Tutti i nomi completi SIT producono troppe corrispondenze e spesso acquisiscono anche superstringhe che non corrispondono a quanto contenuto nella tabella EDM. Ad esempio, "Dr. John Smith" viene acquisito completamente e non corrisponde a un documento che include solo "John Smith".
Un regex per rilevare i GUID (poiché corrisponde alle intestazioni di ogni messaggio di posta elettronica).
Un regex per rilevare numeri lunghi (poiché corrisponde ai timestamp nelle intestazioni di posta elettronica).
Regex che non isola una singola parola o sequenza di corrispondenze di parole in sottostringhe di stringhe più lunghe. Ad esempio, la regex "\d{6}" corrisponde a un numero a sei cifre, ma anche a numeri con più di sei cifre. Una regex migliore sarebbe "\b\d{6}\b" che corrisponde esclusivamente a un numero a sei cifre.
Un regex per trovare qualsiasi stringa alfanumerica produce troppi falsi positivi perché corrisponde ai GUID a meno che non sia limitato alla lunghezza fissa e correttamente associato (ad esempio, aggiungendo "\b" a ogni estremità della regex per rilevare solo stringhe isolate).
L'indirizzo sit rileva troppe variazioni nella scrittura e tende a includere la maggior parte dell'indirizzo presente nel documento, che potrebbe non corrispondere a quanto contenuto nella tabella EDM.
Ignorare i delimitatori e la punteggiatura per migliorare l'accuratezza della corrispondenza
Selezionare l'opzione per ignorare i delimitatori e la punteggiatura nei dati, se applicabile, durante la definizione delle colonne dello schema. È possibile scegliere i delimitatori e i segni di punteggiatura da un elenco predefinito o specificare un elenco delimitato da virgole. Ad esempio, un numero di telefono degli Stati Uniti può essere scritto come +11234567890 o (+1) 123 456 7890 o +1 123-456-7890 e così via. Scegliendo di ignorare i delimitatori e la punteggiatura nel processo di rilevamento, è possibile assicurarsi che ogni formato del numero di telefono sia identificato come una corrispondenza valida. Per altre informazioni, vedere Creare uno schema SIT EDM e un pacchetto di regole (nuova esperienza) | Microsoft Learn.
Usare colonne aggiuntive come evidenza correlata per corrispondenze con maggiore attendibilità
Selezionare la modalità di corrispondenza appropriata per ogni colonna tra le tre opzioni disponibili: token singolo, multi-token o SIT. In generale, se è possibile eseguire il mapping accurato di uno dei campi di prova di supporto a un sit predefinito o personalizzato, eseguire questa operazione per garantire una maggiore accuratezza e una latenza migliorata. In altri casi, usare la corrispondenza basata su token. Evitare di usare la corrispondenza multi-token per un campo che contiene in modo coerente solo dati a token singolo. Per altre informazioni sulle modalità di corrispondenza con token singolo e multi token, vedere Creare uno schema SIT EDM e un pacchetto di regole (nuova esperienza) | Microsoft Learn.
Per le corrispondenze con attendibilità elevata, includere un numero maggiore di elementi di supporto nell'intervallo di prossimità dei caratteri definito. Facoltativamente, è anche possibile creare un modello di confidenza bassa con solo un numero inferiore di elementi di supporto o nessuno se l'elemento primario è sufficientemente accurato da solo.
Selezionare modalità wide o modalità stretta come modalità di rilevamento prossimità in base al modo in cui si desidera controllare gli elementi di supporto entro il limite di prossimità dell'elemento primario.
Classificatore sottoponibile a training: classificazione dei contenuti personalizzati basata su intelligenza artificiale
Usare classificatori sottoponibili a training quando è necessario identificare contenuti proprietari o specifici dell'organizzazione che i SIT predefiniti o i classificatori con training preliminare di Microsoft non possono rilevare in modo affidabile.
Scegliere tra i classificatori con training preliminare predefiniti
Usare i classificatori sottoponibili a training pronti all'uso forniti da Microsoft. Identificare il classificatore sottoponibile a training più adatto al caso d'uso, testarlo con i dati di esempio per verificare che soddisfi i requisiti e iniziare a usarlo nei criteri senza alcun ulteriore sforzo di configurazione manuale e ottimizzazione. Per altre informazioni, vedere Informazioni sui classificatori sottoponibili a training | Microsoft Learn.
Se i classificatori sottoponibili a training predefiniti non soddisfano le proprie esigenze, creare classificatori personalizzati in base ai documenti pertinenti dell'organizzazione.
Seed TC con un ampio set diversificato di campioni positivi e negativi
Eseguire il training del classificatore personalizzato con un numero adeguato di esempi del tipo di contenuto che si vuole rilevare. Creare classificatori sottoponibili a training personalizzati in base ai dati rilevati dai classificatori predefiniti. Se alcuni classificatori sottoponibili a training forniti da Microsoft in Purview sono rilevanti per le proprie esigenze, ma non forniscono l'accuratezza necessaria nell'ambiente, usarli per rilevare un set di documenti di grandi dimensioni nell'ambiente che sono corrispondenze corrette. Raccoglierli in un'unica posizione (rimuovendo quelli che sono falsi positivi e possibilmente aggiungendo alcuni documenti rilevanti identificati manualmente). Come esempi negativi usare documenti e documenti non correlati che non sono stati confrontati correttamente con il classificatore originale. Questo approccio garantisce che il set di training account per il gergo specifico, i nomi e altri aspetti rilevanti delle informazioni.
Per altre informazioni sul processo di creazione di un classificatore sottoponibile a training personalizzato, vedere Introduzione ai classificatori sottoponibili a training | Microsoft Learn.
Fornire feedback di corrispondenza e non corrispondenza per gli elementi identificati
Come nel caso dei SIT, fornire un feedback regolare per ogni elemento corrispondente a un classificatore sottoponibile a training per migliorare l'accuratezza del classificatore. Se il classificatore rileva molti falsi positivi, rimuovere il classificatore personalizzato e crearlo di nuovo con un set di dati di esempio più grande e preciso.
Combinare con i SIT regolari per una maggiore precisione (ad esempio, contratto TC + "somma maggiore di $100K")
Usare l'approccio ibrido di blending machine learning (con classificatore sottoponibile a training) e criteri di ricerca basati su regole (con SIT) per ottenere una maggiore precisione. Ad esempio, per identificare i contratti aziendali sensibili che superano il valore di $ 100.000, associare il classificatore sottoponibile Business Context a training con un sit personalizzato che rileva somme di contratto superiori a $ 100k.
Rilevamento delle impronte digitali dei documenti - Rilevamento di documenti basato su modelli
Usare la tecnica di rilevamento delle impronte digitali dei documenti per rilevare modelli di documento specifici o documenti in formato fisso con una struttura coerente. Per altre informazioni, vedere Informazioni sull'impronta digitale dei documenti | Microsoft Learn.
Scegliere un numero ridotto di asset di valore elevato
Per scegliere l'impronta digitale, identificare i documenti di valore elevato o altamente sensibili noti all'interno dell'organizzazione. Impronta digitale di questi documenti a tassi di "corrispondenza completa" o "corrispondenza elevata" in modo da poter rilevare copie identiche di questi documenti o variazioni strettamente corrispondenti mentre si spostano all'interno o all'esterno dell'organizzazione.
Usare la corrispondenza parziale per rilevare versioni modificate o parziali
Ottimizzare l'impronta digitale SIT per rilevare il contenuto che ha una corrispondenza parziale con l'impronta digitale. Questa ottimizzazione riguarda i casi in cui sono presenti lievi modifiche al modello standard su cui è definita l'impronta digitale. Ad esempio, se vuoi che Purview contrassegni gli elementi che corrispondono almeno al 50% all'impronta digitale, definisci i livelli di confidenza come: Basso (50 & sopra), Medio (70 & sopra), Alto (90 & sopra).
Regolare il livello di confidenza in base ai risultati reali
Se vengono visualizzati molti falsi positivi, aumentare la soglia minima di corrispondenza e modificare i livelli di attendibilità. Se vengono visualizzati molti falsi negativi, abbassare la soglia di corrispondenza. Effettuare regolarmente questa regolazione analizzando attentamente gli elementi corrispondenti.
Impostare un valore di livello di attendibilità elevato su esatto per la corrispondenza esatta
Scegli una corrispondenza esatta nell'impronta digitale dei documenti quando hai a che fare con documenti altamente strutturati e critici che richiedono un'identificazione precisa senza spazio per la variazione. In caso contrario, definire una frequenza elevata anziché usare la frequenza completa, poiché alcune forme di conversione del documento (ad esempio la trascrizione come PDF, l'aggiunta di un'intestazione o un piè di pagina o l'aggiornamento a un formato di file più recente) possono introdurre modifiche minori al file che impediscono la corrispondenza al 100%.
Seguendo questo progetto, è possibile applicare in modo strategico le tecnologie di classificazione di Microsoft Purview, ovvero i tipi di informazioni sensibili (SIT), l'esatta corrispondenza dei dati (EDM), i classificatori sottoponibili a training e l'impronta digitale dei documenti, in diversi scenari per ottimizzare l'accuratezza del rilevamento, riducendo al tempo stesso l'attrito.
Inoltre, le sezioni seguenti forniscono indicazioni su quando usare i diversi classificatori e su come ottimizzare la configurazione dei criteri DLP.
Strategie di classificazione dei dati basate su scenari
La tabella seguente fornisce indicazioni sulla distribuzione con esempi delle tecniche di classificazione dei dati consigliate per scenari diversi.
| Scenario | Metodo preferito | Metodi alternativi (meno precisi) | Tecniche per ridurre i falsi positivi |
|---|---|---|---|
| Rilevare informazioni personali/PHI per individui noti (clienti o pazienti) | EDM per i dati dall'estrazione dell'app LoB | SIT personalizzati, inclusi ID dipendente + SIT PII comuni (ad esempio, SSN) | Se si usano i SIT normali, è consigliabile richiedere la presenza di Tutti i nomi completi e limitare le regole ai documenti con un numero di corrispondenze superiore a un determinato minimo. |
| Rilevare pii/PHI per dipendenti o appaltatori | EDM per i dati dall'estrazione del sistema HR | SIT personalizzati, inclusi ID dipendente + entità denominate (ad esempio, tutti i nomi completi) + SIT PII comuni (ad esempio , SSN) | Se si usano i SIT normali, è consigliabile richiedere la presenza di Tutti i nomi completi e limitare le regole ai documenti con un numero di corrispondenze superiore a un determinato minimo. |
| Rilevare moduli con dati personali (ad esempio moduli di iscrizione, moduli fiscali, moduli di gestione account) | Impronta digitale dei moduli + SIT standard o impronta digitale + SIT personalizzati | SIT personalizzati + OCR (per i moduli analizzati) | Se non si usa l'impronta digitale, usare EDM anziché SIT personalizzati. |
| Contratti, documenti legali o altri moduli aziendali | Classificatori sottoponibili a training personalizzati (+ OCR) | Classificatori sottoponibili a training OOB + OCR | Identificare i documenti nell'organizzazione che il TC OOB identifica correttamente, copiarli in un repository e usarli per eseguire il training di un TC personalizzato. Questo approccio produce un classificatore ottimizzato che si allinea meglio ai termini tipici dell'organizzazione, che includono nomi aziendali, gergo e boilerplate. |
| Contratti importanti o altri documenti | Classificatore sottoponibile a training + etichetta di riservatezza (applicata manualmente o automaticamente) | Classificatore sottoponibile a training + SIT personalizzato (ad esempio, regex per rilevare importi monetari superiori a $ 100.000 o dizionario o EDM con nomi di clienti importanti) | Identificare i documenti nell'organizzazione che il TC OOB identifica correttamente e i documenti contrassegnati/etichettati manualmente come tali. Copiarli in un repository e usarli per eseguire il training di un TC personalizzato. Questo approccio produce un classificatore ottimizzato che si allinea meglio ai termini tipici dell'organizzazione, che includono nomi aziendali, gergo e boilerplate. È anche possibile combinare più controller di dominio in una singola regola, ad esempio "Contratti" e "Documenti sul progetto X" per trovare documenti rilevanti per entrambi gli argomenti. |
| Informazioni personali generali o PHI di individui sconosciuti (ad esempio, non clienti o potenziali clienti) | SIT OOB, se disponibili per le informazioni personali o i SIT personalizzati desiderati | Etichettatura manuale | Copiare e modificare un sit esistente per ottimizzare i requisiti delle parole chiave. Espandere i requisiti di limite di prossimità per la corrispondenza del contenuto nei moduli compilati in formato PDF, poiché il contenuto nei moduli non viene archiviato all'interno della struttura del modulo. Aggiungere i requisiti per le entità denominate, ad esempio Tutti i nomi completi. Assicurarsi che le espressioni regolari personalizzate siano definite come "corrispondenza di parole" o come inizio e fine con \b. |
| Conversazioni sensibili di natura nota | Training personalizzato del classificatore sottoponibile a training basato su esempi confermati | - | Identificare nei documenti di Esplora contenuto con etichette rilevanti per tali soggetti, estrarli e usarli per eseguire il training di un TC personalizzato. |
| Conversazioni sensibili di natura non specifica | Etichettatura manuale | Usare dizionari di "parole non significative" o altre parole chiave rilevanti che potrebbero suggerire argomenti sensibili. | Consentire all'utente di decidere di applicare l'etichetta di riservatezza pertinente, usando il proprio giudizio o in base all'etichetta consigliata dall'etichettatura automatica sul lato client. |
| Carte d'identità analizzate (o simili) | OOB o SIT personalizzati + OCR | SIT personalizzato con elenchi di parole chiave presenti in tali documenti + OCR | Aggiungere i requisiti per le entità denominate (nomi o indirizzi) se previsto in una riga del documento. |
| Project data | Etichettatura basata sulla posizione (ad esempio, etichetta predefinita per la libreria) | Etichettatura manuale o classificatori sottoponibili a training personalizzati | Una volta che l'etichettatura basata sulla posizione o l'etichettatura manuale identifica un numero sufficiente di documenti rilevanti, usarli per eseguire il training di un TC personalizzato. |
Ottimizzazione della configurazione dei criteri DLP
Quando si usano i classificatori nei criteri DLP, modificare il numero di istanze per ridurre i falsi positivi. Mantenere la soglia minima per il conteggio delle istanze a un valore superiore quando le occorrenze piccole o banali di dati sensibili non disturbano l'utente(ad esempio, un'istanza di un numero di carta di credito). Tuttavia, quando il contesto aziendale richiede una maggiore sicurezza dei dati, usare un numero di istanze inferiore per bloccare anche una singola occorrenza di dati sensibili. Personalizzare il conteggio delle istanze in base al livello di riservatezza dei dati.
Tenere presente anche che Esplora contenuto è l'hub centrale per l'individuazione di contenuti sensibili nell'area dati, usando i classificatori disponibili. Offre visibilità completa sui tipi e le posizioni dei dati sensibili all'interno dell'ambiente digitale. Tuttavia, non tutte le corrispondenze visualizzate qui sono rilevanti per lo scenario aziendale specifico. Si tratta di uno strumento potente per esplorare e valutare ciò che è veramente importante, ma la chiave per ridurre il rumore e ridurre i falsi positivi risiede nella configurazione efficace dei criteri DLP. Ottimizzando le soglie dell'istanza e impostando i livelli di attendibilità appropriati per il rilevamento, è possibile assicurarsi che gli avvisi vengano attivati solo quando il contesto è allineato al comportamento di rischio dell'organizzazione. Ad esempio, mentre Esplora contenuto potrebbe rivelare centinaia di corrispondenze di numeri di carta di credito, i criteri possono concentrarsi esclusivamente sui rilevamenti ad alta attendibilità. Le altre corrispondenze non sono necessariamente falsi positivi, ma non sono rilevanti per il caso d'uso definito.