Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come creare un file di pacchetto di regole XML che definisce tipi di informazioni sensibili personalizzati. Questo articolo descrive un tipo di informazioni sensibili personalizzato che identifica un ID dipendente. È possibile usare il codice XML di esempio in questo articolo come punto di partenza per il proprio file XML.
Per altre informazioni sui tipi di informazioni riservate, vedere Informazioni sui tipi di informazioni riservate.
Dopo aver creato un file XML ben formato, è possibile caricarlo in Microsoft 365 usando PowerShell. È quindi possibile usare il tipo di informazioni sensibili personalizzate nei criteri. È possibile testarne l'efficacia nel rilevare le informazioni sensibili come previsto.
Nota
Se non è necessario il controllo con granularità fine fornito da PowerShell, è possibile creare tipi di informazioni sensibili personalizzati nel portale di Microsoft Purview. Per altre informazioni, vedere Creare un tipo di informazione sensibile personalizzato.
Dichiarazione di non responsabilità importante
supporto tecnico Microsoft non consente di creare definizioni di corrispondenza del contenuto.
Per lo sviluppo, il test e il debug personalizzati per la corrispondenza dei contenuti, è necessario usare le proprie risorse IT interne o usare servizi di consulenza, ad esempio Microsoft Consulting Services (MCS). supporto tecnico Microsoft tecnici possono fornire un supporto limitato per questa funzionalità, ma non possono garantire che i suggerimenti personalizzati per la corrispondenza dei contenuti soddisfino pienamente le proprie esigenze.
MCS può fornire espressioni regolari a scopo di test. Possono anche fornire assistenza nella risoluzione dei problemi di un modello RegEx esistente che non funziona come previsto con un singolo esempio di contenuto specifico.
Vedere Potenziali problemi di convalida di cui tenere conto in questo articolo.
Per ulteriori informazioni sul motore Boost.RegEx (in precedenza noto come RegEx++) utilizzato per l'elaborazione del testo, vedere Boost.Regex 5.1.3.
Nota
Se si usa un carattere e commerciale (&) come parte di una parola chiave nel tipo di informazioni sensibili personalizzato, è necessario aggiungere un termine aggiuntivo con spazi intorno al carattere. Ad esempio, usare L & PnoL&P.
Esempio di XML di un pacchetto di regole
Ecco il codice XML di esempio del pacchetto di regole creato in questo articolo. Gli elementi e gli attributi sono illustrati nelle sezioni seguenti.
<?xml version="1.0" encoding="UTF-16"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version build="0" major="1" minor="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>Contoso</PublisherName>
<Name>Employee ID Custom Rule Pack</Name>
<Description>
This rule package contains the custom Employee ID entity.
</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="65">
<IdMatch idRef="Regex_employee_id"/>
</Pattern>
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id"/>
<Match idRef="Func_us_date"/>
</Pattern>
<Pattern confidenceLevel="85">
<IdMatch idRef="Regex_employee_id"/>
<Match idRef="Func_us_date"/>
<Any minMatches="1">
<Match idRef="Keyword_badge" minCount="2"/>
<Match idRef="Keyword_employee"/>
</Any>
<Any minMatches="0" maxMatches="0">
<Match idRef="Keyword_false_positives_local"/>
<Match idRef="Keyword_false_positives_intl"/>
</Any>
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<Keyword id="Keyword_badge">
<Group matchStyle="string">
<Term>card</Term>
<Term>badge</Term>
<Term caseSensitive="true">ID</Term>
</Group>
</Keyword>
<Keyword id="Keyword_false_positives_local">
<Group matchStyle="word">
<Term>credit card</Term>
<Term>national ID</Term>
</Group>
</Keyword>
<Keyword id="Keyword_false_positives_intl">
<Group matchStyle="word">
<Term>identity card</Term>
<Term>national ID</Term>
<Term>EU debit card</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">Employee ID</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee IDs.
</Description>
<Description default="false" langcode="de-de">
Description for German locale.
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Quali sono i requisiti principali? [Rule, Entity, Pattern elements]
È importante comprendere la struttura di base dello schema XML per una regola. La comprensione della struttura consente al tipo di informazioni sensibili personalizzate di identificare il contenuto corretto.
Una regola definisce una o più entità (note anche come tipi di informazioni riservate). Ogni entità definisce uno o più modelli. Un modello è quello che cerca un criterio quando valuta il contenuto , ad esempio posta elettronica e documenti.
Nel markup XML le "regole" indicano i modelli che definiscono il tipo di informazioni riservate. Non associare riferimenti alle regole in questo articolo con "condizioni" o "azioni" comuni in altre funzionalità Microsoft.
Scenario più semplice: entità con un solo modello
Ecco uno scenario semplice: si vuole che i criteri identifichino il contenuto che contiene id dipendente a nove cifre usati nell'organizzazione. Un criterio fa riferimento all'espressione regolare nella regola che identifica i numeri a nove cifre. Qualsiasi contenuto che contiene un numero di nove cifre soddisfa il modello.

Tuttavia, questo modello potrebbe identificare qualsiasi numero di nove cifre, inclusi i numeri più lunghi o altri tipi di numeri a nove cifre che non sono ID dipendente. Questo tipo di corrispondenza indesiderata è noto come falso positivo.
Scenario più comune: entità con più modelli
A causa del potenziale di falsi positivi, in genere si usa più di un modello per definire un'entità. Più modelli forniscono prove di supporto per l'entità di destinazione. Ad esempio, parole chiave aggiuntive, date o altro testo possono aiutare a identificare l'entità originale, ad esempio il numero di dipendente a nove cifre.
Ad esempio, per aumentare la probabilità di identificare il contenuto che contiene un ID dipendente, è possibile definire altri modelli da cercare:
- Modello che identifica una data di assunzione.
- Modello che identifica sia una data di assunzione che la parola chiave "ID dipendente".
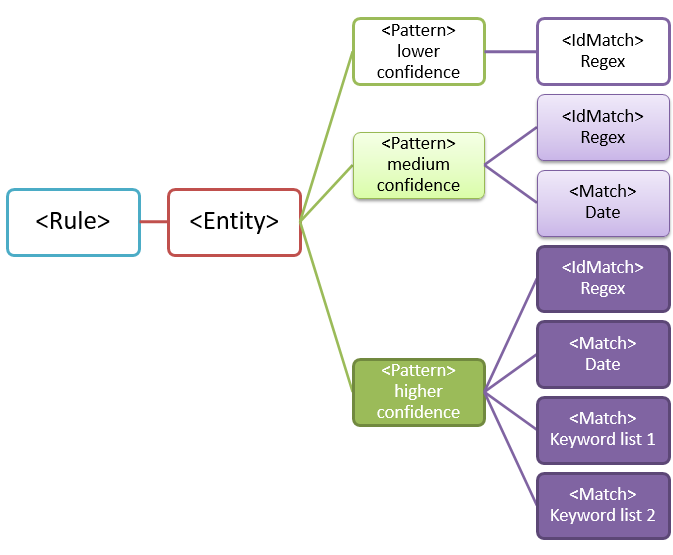
Esistono punti importanti da considerare per le corrispondenze con più modelli:
I criteri che richiedono altre prove hanno un livello di probabilità più alto. In base al livello di attendibilità, è possibile eseguire le azioni seguenti:
- Usare azioni più restrittive , ad esempio il contenuto del blocco, con corrispondenze con maggiore attendibilità.
- Usare azioni meno restrittive ,ad esempio inviare notifiche, con corrispondenze di minore attendibilità.
Gli elementi e
Matchdi supportoIdMatchfanno riferimento a RegEx e parole chiave che sono effettivamente elementi figlio dell'elementoRule, non aPattern. IPatternriferimenti agli elementi di supporto, ma sono inclusi inRule. Questo comportamento significa che a una singola definizione di un elemento di supporto, ad esempio un'espressione regolare o un elenco di parole chiave, può essere fatto riferimento da più entità e modelli.
Quale entità è necessario identificare? [Elemento entity, attributo ID]
Un'entità è un tipo di informazioni riservate, ad esempio un numero di carta di credito, con un modello ben definito. Ogni entità ha un GUID univoco come ID.
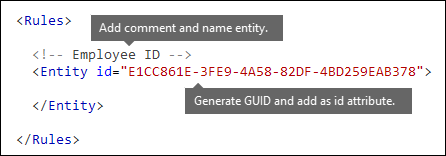
Assegnare un nome all'entità e creare il relativo GUID
- Nell'editor XML preferito aggiungere gli
Ruleselementi eEntity. - Aggiungere un commento che contiene il nome dell'entità personalizzata, ad esempio ID dipendente. Successivamente, si aggiungerà il nome dell'entità alla sezione stringhe localizzate e tale nome verrà visualizzato nell'interfaccia di amministrazione quando si creano criteri.
- Generare un GUID univoco per l'entità. Ad esempio, in Windows PowerShell è possibile eseguire il comando
[guid]::NewGuid(). Successivamente, si aggiungerà anche il GUID alla sezione delle stringhe localizzate dell'entità.
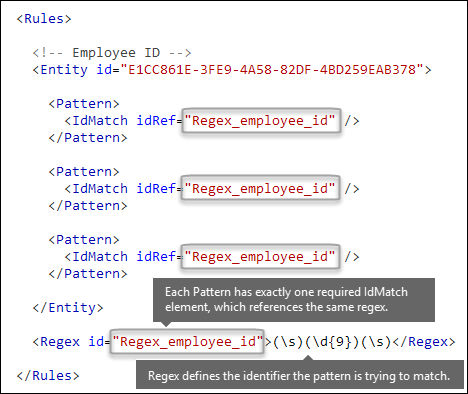
Quale modello si desidera associare? [Elemento pattern, elemento IdMatch, elemento Regex]
Il modello contiene l'elenco degli elementi cercati dal tipo di informazioni riservate. Il modello può includere regex, parole chiave e funzioni predefinite. Le funzioni eseguono attività come l'esecuzione di RegEx per trovare date o indirizzi. I tipi di informazioni sensibili possono avere più modelli con probabilità univoche.
Nel diagramma seguente tutti i modelli fanno riferimento alla stessa espressione regolare. Questo oggetto RegEx cerca un numero (\d{9}) di nove cifre racchiuso tra spazi vuoti (\s) ... (\s). L'elemento IdMatch fa riferimento a questa espressione regolare ed è il requisito comune per tutti i modelli che cercano l'entità ID dipendente.
IdMatch è l'identificatore che il modello sta cercando di trovare. Un Pattern elemento deve avere esattamente un IdMatch elemento.
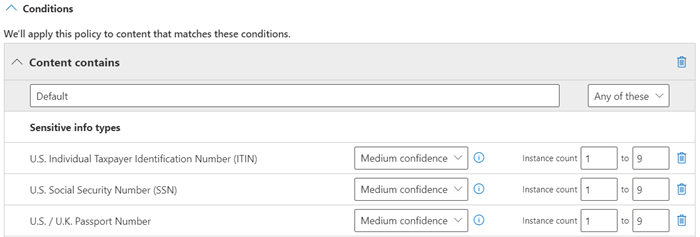
Una corrispondenza di modello soddisfatta restituisce un livello di conteggio e confidenza, che è possibile usare nelle condizioni dei criteri. Quando si aggiunge una condizione per il rilevamento di un tipo di informazioni riservate a un criterio, è possibile modificare il livello di conteggio e attendibilità, come illustrato nel diagramma seguente. Il livello di attendibilità (detto anche accuratezza delle corrispondenze) è illustrato più avanti in questo articolo.
Le espressioni regolari sono potenti, quindi ci sono problemi che è necessario conoscere. Ad esempio, un RegEx che identifica una quantità eccessiva di contenuto può influire sulle prestazioni. Per altre informazioni su questi problemi, vedere la sezione Potenziali problemi di convalida di cui tenere conto più avanti in questo articolo.
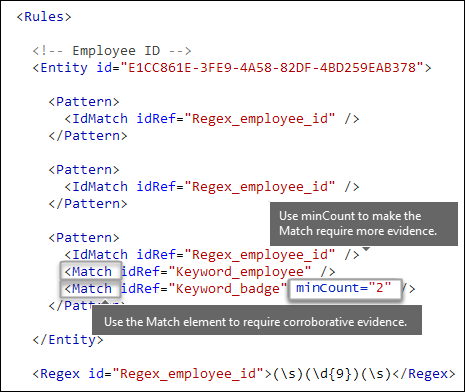
Vuoi richiedere prove aggiuntive? [Elemento Match, attributo minCount]
Oltre a IdMatch, un modello può usare l'elemento Match per richiedere ulteriori evidenze di supporto, ad esempio una parola chiave, RegEx, data o indirizzo.
Un Pattern oggetto può includere più Match elementi:
- Direttamente nell'elemento
Pattern. - Combinato usando l'elemento
Any.
Match gli elementi vengono uniti con un operatore AND implicito. In altre parole, tutti gli Match elementi devono essere soddisfatti per la corrispondenza del modello.
È possibile usare l'elemento Any per introdurre operatori AND o OR. L'elemento Any è descritto più avanti in questo articolo.
È possibile usare l'attributo facoltativo minCount per specificare il numero di istanze di una corrispondenza da trovare per ogni Match elemento. Ad esempio, è possibile specificare che un modello viene soddisfatto solo quando vengono trovate almeno due parole chiave da un elenco di parole chiave.
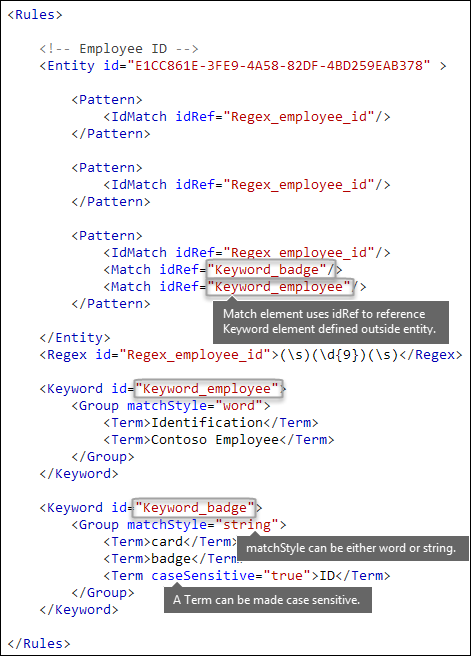
Parole chiave [elementi Keyword, Group e Term, attributi matchStyle e caseSensitive]
Come descritto in precedenza, l'identificazione di informazioni riservate richiede spesso parole chiave aggiuntive come prove corroborative. Ad esempio, oltre a corrispondere a un numero di nove cifre, è possibile cercare parole come "card", "badge" o "ID" usando l'elemento Keyword. L'elemento Keyword ha un ID attributo a cui possono fare riferimento più Match elementi in più modelli o entità.
Le parole chiave vengono incluse come elenco di Term elementi in un Group elemento. L'elemento Group ha un matchStyle attributo con due valori possibili:
matchStyle="word": una corrispondenza di parole identifica parole intere circondate da spazi vuoti o altri delimitatori. È consigliabile usare sempre word a meno che non sia necessario associare parti di parole o parole in lingue asiatiche.
matchStyle="string": una corrispondenza stringa identifica le stringhe indipendentemente da ciò che sono racchiuse. Ad esempio, "ID" corrisponde sia a "bid" che a "idea". Usare
stringsolo quando è necessario trovare la corrispondenza con parole asiatiche o se la parola chiave potrebbe essere inclusa in altre stringhe.
Infine, è possibile usare l'attributo caseSensitive dell'elemento Term per specificare che il contenuto deve corrispondere esattamente alla parola chiave, incluse le lettere minuscole e maiuscole.
Espressioni regolari [elemento Regex]
In questo esempio l'entità employee ID usa già l'elemento IdMatch per fare riferimento a un'espressione regolare per il modello: un numero di nove cifre racchiuso tra spazi vuoti. Inoltre, un modello può usare un Match elemento per fare riferimento a un elemento aggiuntivo Regex per identificare l'evidenza corroborativa, ad esempio un numero a cinque o nove cifre nel formato di un codice postale degli Stati Uniti.
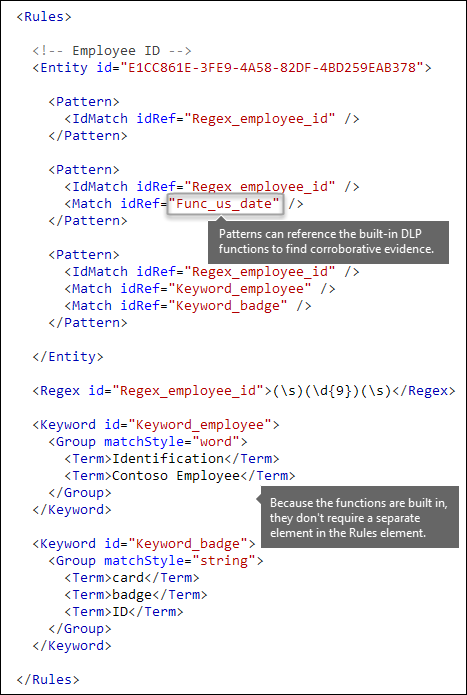
Altri criteri, ad esempio date o indirizzi [funzioni predefinite]
I tipi di informazioni sensibili possono anche usare funzioni predefinite per identificare le prove di conferma. Ad esempio, una data usa, una data UE, una data di scadenza o un indirizzo degli Stati Uniti. Microsoft 365 non supporta il caricamento di funzioni personalizzate. Tuttavia, quando si crea un tipo di informazioni sensibili personalizzato, l'entità può fare riferimento a funzioni predefinite.
Ad esempio, una notifica id dipendente ha una data di assunzione, quindi questa entità personalizzata può usare la funzione predefinita Func_us_date per identificare una data nel formato comunemente usato negli Stati Uniti.
Per altre informazioni, vedere Funzioni del tipo di informazioni riservate.
Diverse combinazioni di evidenze [qualsiasi elemento, minMatches e maxMatches attributi]
In un Pattern elemento tutti gli IdMatch elementi e Match vengono uniti con un operatore AND implicito. In altre parole, tutte le corrispondenze devono essere soddisfatte prima che il modello possa essere soddisfatto.
È possibile creare una logica di corrispondenza più flessibile usando l'elemento Any per raggruppare Match gli elementi. Ad esempio, è possibile usare l'elemento per trovare la Any corrispondenza con tutti, nessuno o un subset esatto dei relativi elementi figlio Match .
L'elemento Any ha attributi facoltativi minMatches e maxMatches che è possibile usare per definire il numero di elementi figlio Match che devono essere soddisfatti prima della corrispondenza del modello. Questi attributi definiscono il numero di Match elementi, non il numero di istanze di evidenza trovate per le corrispondenze. Per definire un numero minimo di istanze per una corrispondenza specifica, ad esempio due parole chiave da un elenco, usare l'attributo minCount per un Match elemento (vedere sopra).
Corrispondenza con almeno un elemento Match figlio
Per richiedere solo un numero minimo di Match elementi, è possibile usare l'attributo minMatches . In effetti, questi Match elementi vengono uniti con un operatore OR implicito. Questo Any elemento viene soddisfatto se viene trovata una data formattata negli Stati Uniti o una parola chiave da uno degli elenchi.
<Any minMatches="1" >
<Match idRef="Func_us_date" />
<Match idRef="Keyword_employee" />
<Match idRef="Keyword_badge" />
</Any>
Associa un sottoinsieme esatto di elementi Match figlio simili
Per richiedere un numero esatto di Match elementi, impostare minMatches e maxMatches sullo stesso valore. Questo Any elemento viene soddisfatto solo se viene trovata esattamente una data o una parola chiave. Se sono presenti altre corrispondenze, il modello non viene confrontato.
<Any minMatches="1" maxMatches="1" >
<Match idRef="Func_us_date" />
<Match idRef="Keyword_employee" />
<Match idRef="Keyword_badge" />
</Any>
Non corrisponde a nessuno degli elementi figlio "Match"
Se vuoi richiedere l'assenza di prove specifiche per soddisfare un modello, puoi impostare sia minMatches che maxMatches su 0. Questo può essere utile se si dispone di un elenco di parole chiave o di altre prove che probabilmente indicano un falso positivo.
Ad esempio, l'entità ID dipendente cerca la parola chiave "card" perché potrebbe fare riferimento a una "scheda ID". Tuttavia, se la carta viene visualizzata solo nella frase "carta di credito", "carta" in questo contenuto è improbabile che significhi "carta ID". È quindi possibile aggiungere "carta di credito" come parola chiave a un elenco di termini che si desidera escludere dal soddisfacimento del modello.
<Any minMatches="0" maxMatches="0" >
<Match idRef="Keyword_false_positives_local" />
<Match idRef="Keyword_false_positives_intl" />
</Any>
Corrisponde a diversi termini univoci
Se si desidera trovare una corrispondenza con diversi termini univoci, usare il parametro uniqueResults , impostato su true, come illustrato nell'esempio seguente:
<Pattern confidenceLevel="75">
<IdMatch idRef="Salary_Revision_terms" />
<Match idRef=" Salary_Revision_ID " minCount="3" uniqueResults="true" />
</Pattern>
In questo esempio viene definito un criterio per la revisione dello stipendio, con almeno tre corrispondenza univoche.
Quanto deve essere vicina all'entità l'altra evidenza? [patternsProximity attribute]
Il tipo di informazioni sensibili è alla ricerca di un modello che rappresenta un ID dipendente e, come parte di tale modello, cerca anche prove corroborative come una parola chiave come "ID". È opportuno che più questa evidenza sia unita, più è probabile che il modello sia un ID dipendente effettivo. È possibile determinare la vicinanza di altre evidenze nel modello all'entità usando l'attributo patternsProximity obbligatorio dell'elemento Entity.
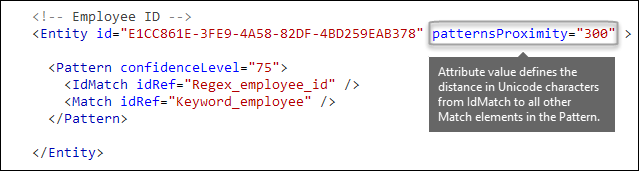
Per ogni criterio nell'entità, il valore dell'attributo patternsProximity definisce la distanza (in caratteri Unicode) dalla posizione IdMatch per tutte le altre corrispondenze specificate per tale criterio. La finestra di prossimità viene ancorata dalla posizione IdMatch con la finestra che si estende a sinistra e a destra di IdMatch.
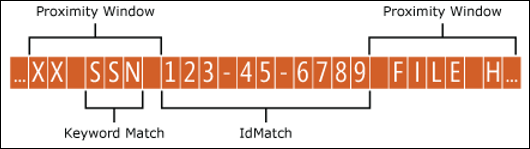
L'esempio seguente illustra in che modo la finestra di prossimità influisce sulla corrispondenza dei criteri in cui l'elemento IdMatch per l'entità personalizzata id dipendente richiede almeno una corrispondenza di conferma della parola chiave o della data. Solo ID1 corrisponde perché per ID2 e ID3, nella finestra di prossimità non viene trovata alcuna prova di conferma parziale o solo parziale.
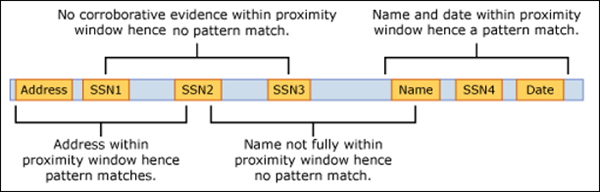
Per il messaggio di posta elettronica, il corpo del messaggio e ogni allegato vengono considerati come elementi separati. Ciò significa che la finestra di prossimità non si estende oltre la fine di ognuno di questi elementi. Per ogni elemento (allegato o corpo), sia l'idMatch che l'evidenza corroborativa devono risiedere in tale elemento.
Quali sono i livelli di confidenza corretti per modelli diversi? [attributo confidenceLevel, attributo recommendedConfidence]
Maggiore è l'evidenza necessaria per un modello, maggiore sarà la probabilità che un'entità effettiva (ad esempio l'ID dipendente) sia stata identificata quando il modello viene confrontato. Ad esempio, si ha maggiore fiducia in un modello che richiede un numero ID di nove cifre, una data di assunzione e una parola chiave in prossimità, rispetto a un modello che richiede solo un numero ID a nove cifre.
L'elemento Pattern ha un attributo confidenceLevel obbligatorio. È possibile considerare il valore di confidenceLevel (un valore compreso tra 65/75/85 che indica livelli di attendibilità bassa/media/alta) come un ID univoco per ogni modello in un'entità. Dopo aver caricato il tipo di informazioni riservate personalizzato e aver creato dei criteri, è possibile fare riferimento a questi livelli di probabilità nelle condizioni delle regole create dall'utente.
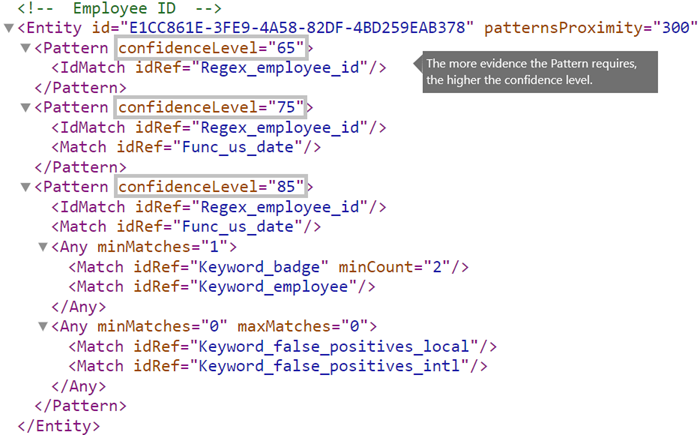
Oltre all'attributo confidenceLevel per ogni elemento Pattern, l'elemento Entity ha un attributo recommendedConfidence. L'attributo recommendedConfidence può essere considerato come il livello di confidenza predefinito per la regola. Quando si crea una regola in un criterio, se non si specifica un livello di confidenza per la regola da usare, tale regola corrisponde in base al livello di attendibilità consigliato per l'entità. L'attributo recommendedConfidence è obbligatorio per ogni ID entità nel pacchetto della regola, se mancante non sarà possibile salvare i criteri che usano il tipo di informazioni riservate.
Si vuole supportare altre lingue nell'interfaccia utente del portale Purview? Elemento LocalizedStrings
Se il team di conformità usa il portale di Microsoft Purview per creare criteri in impostazioni locali diverse e in lingue diverse, è possibile fornire versioni localizzate del nome e della descrizione del tipo di informazioni sensibili personalizzate. Quando il team di conformità usa Microsoft 365 in una lingua supportata, viene visualizzato il nome localizzato nell'interfaccia utente.
L'elemento Rules deve contenere un elemento LocalizedStrings, che contiene un elemento Resource che fa riferimento al GUID dell'entità personalizzata. A sua volta, ogni elemento Resource contiene uno o più elementi Name e Description che usano l'attributo langcode per fornire una stringa localizzata per una lingua specifica.
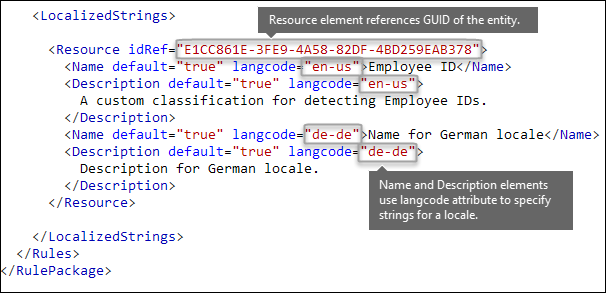
Le stringhe localizzate vengono usate solo per la visualizzazione del tipo di informazioni sensibili personalizzate nell'interfaccia utente del Centro conformità. Le stringhe localizzate vengono utilizzate solo per il modo in cui le informazioni riservate personalizzate vengono visualizzate nell'interfaccia utente del Centro di conformità e sicurezza. Non è possibile utilizzare le stringhe localizzate per fornire versioni localizzate diverse di un elenco di parole chiave o di un'espressione regolare.
Altri markup del pacchetto di regole [GUID RulePack]
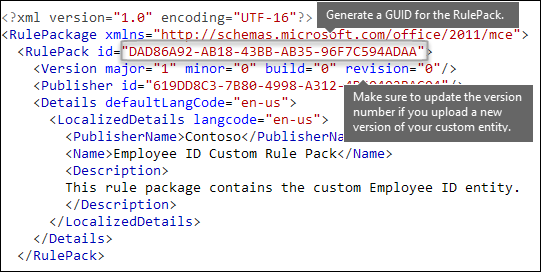
Infine, l'inizio di ogni RulePackage contiene alcune informazioni generali che è necessario compilare. È possibile usare il markup seguente come modello e sostituire ". . ." segnaposto con le proprie informazioni.
Soprattutto, è necessario generare un GUID per RulePack. In precedenza è stato generato un GUID per l'entità; si tratta di un secondo GUID per RulePack. Esistono diversi modi per generare i GUID, ma la soluzione più semplice consiste nell'usare PowerShell digitando [guid]::NewGuid().
Anche l'elemento Version è importante. Quando si carica il pacchetto della regola per la prima volta, Microsoft 365 annota il numero di versione. In seguito, se si aggiorna il pacchetto della regola e si carica una nuova versione, assicurarsi di aggiornare il numero di versione oppure Microsoft 365 non distribuirà il pacchetto della regola.
<?xml version="1.0" encoding="utf-16"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id=". . .">
<Version major="1" minor="0" build="0" revision="0" />
<Publisher id=". . ." />
<Details defaultLangCode=". . .">
<LocalizedDetails langcode=" . . . ">
<PublisherName>. . .</PublisherName>
<Name>. . .</Name>
<Description>. . .</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
. . .
</Rules>
</RulePackage>
Una volta completato, l'elemento RulePack dovrebbe avere l'aspetto seguente.
Validator
Microsoft 365 espone i processori di funzione per i SIT di uso comune come validator. Ecco un elenco di loro.
Elenco dei validator attualmente disponibili
Func_credit_cardFunc_ssnFunc_unformatted_ssnFunc_randomized_formatted_ssnFunc_randomized_unformatted_ssnFunc_aba_routingFunc_south_africa_identification_numberFunc_brazil_cpfFunc_ibanFunc_brazil_cnpjFunc_swedish_national_identifierFunc_india_aadhaarFunc_uk_nhs_numberFunc_Turkish_National_IdFunc_australian_tax_file_numberFunc_usa_uk_passportFunc_canadian_sinFunc_formatted_itinFunc_unformatted_itinFunc_dea_number_v2Func_dea_numberFunc_japanese_my_number_personalFunc_japanese_my_number_corporate
In questo modo è possibile definire il proprio RegEx e convalidarli. Per usare i validator, definire il proprio RegEx e usare la Validator proprietà per aggiungere il processore di funzioni di propria scelta. Una volta definito, è possibile usare questo RegEx in un SIT.
Nell'esempio seguente viene definita un'espressione regolare Regex_credit_card_AdditionalDelimiters per la carta di credito, che viene quindi convalidata usando la funzione checksum per la carta di credito usando Func_credit_card come validator.
<Regex id="Regex_credit_card_AdditionalDelimiters" validators="Func_credit_card"> (?:^|[\s,;\:\(\)\[\]"'])([0-9]{4}[ -_][0-9]{4}[ -_][0-9]{4}[ -_][0-9]{4})(?:$|[\s,;\:\(\)\[\]"'])</Regex>
<Entity id="675634eb7-edc8-4019-85dd-5a5c1f2bb085" patternsProximity="300" recommendedConfidence="85">
<Pattern confidenceLevel="85">
<IdMatch idRef="Regex_credit_card_AdditionalDelimiters" />
<Any minMatches="1">
<Match idRef="Keyword_cc_verification" />
<Match idRef="Keyword_cc_name" />
<Match idRef="Func_expiration_date" />
</Any>
</Pattern>
</Entity>
Microsoft 365 fornisce due validator generici
Checksum validator
In questo esempio viene definito un validator checksum per l'ID dipendente per convalidare RegEx per EmployeeID.
<Validators id="EmployeeIDChecksumValidator">
<Validator type="Checksum">
<Param name="Weights">2, 2, 2, 2, 2, 1</Param>
<Param name="Mod">28</Param>
<Param name="CheckDigit">2</Param> <!-- Check 2nd digit -->
<Param name="AllowAlphabets">1</Param> <!— 0 if no Alphabets -->
</Validator>
</Validators>
<Regex id="Regex_EmployeeID" validators="ChecksumValidator">(\d{5}[A-Z])</Regex>
<Entity id="675634eb7-edc8-4019-85dd-5a5c1f2bb085" patternsProximity="300" recommendedConfidence="85">
<Pattern confidenceLevel="85">
<IdMatch idRef="Regex_EmployeeID"/>
</Pattern>
</Entity>
Convalida data
In questo esempio viene definito un validator di data per una parte RegEx di cui è data.
<Validators id="date_validator_1"> <Validator type="DateSimple"> <Param name="Pattern">DDMMYYYY</Param> <!—supported patterns DDMMYYYY, MMDDYYYY, YYYYDDMM, YYYYMMDD, DDMMYYYY, DDMMYY, MMDDYY, YYDDMM, YYMMDD --> </Validator> </Validators>
<Regex id="date_regex_1" validators="date_validator_1">\d{8}</Regex>
Modifiche per Exchange Online
In passato, per importare tipi di informazioni riservate personalizzati per la prevenzione della perdita dei dati, è probabile che tu abbia usato PowerShell in Exchange Online. Ora i tipi di informazioni sensibili personalizzati possono essere usati sia nell'interfaccia di amministrazione di Exchange]"https://go.microsoft.com/fwlink/p/?linkid=2059104") che nel portale di Microsoft Purview. Come parte di questo miglioramento, è consigliabile usare Security & Compliance PowerShell per importare i tipi di informazioni sensibili personalizzati. Non è più possibile importarli da Exchange Online PowerShell. I tipi di informazioni riservate personalizzati continueranno a funzionare come prima, tuttavia per visualizzare nell'interfaccia di amministrazione di Exchange le modifiche apportate ai tipi di informazioni riservate personalizzati nel Centro conformità potrebbe volerci fino a un'ora.
Notare che, nel Centro conformità, bisogna usare il cmdlet New-DlpSensitiveInformationTypeRulePackage per caricare un pacchetto di regole. In precedenza, nell'interfaccia di amministrazione di Exchange è stato usato il cmdlet ClassificationRuleCollection.
Caricare il pacchetto di regole
Per caricare il pacchetto di regole, eseguire i passaggi seguenti:
Salvarlo come file XML con codifica Unicode.
Utilizzare la sintassi seguente:
New-DlpSensitiveInformationTypeRulePackage -FileData ([System.IO.File]::ReadAllBytes('PathToUnicodeXMLFile'))In questo esempio, viene caricato il file XML Unicode denominato MyNewRulePack.xml da C:\Documenti.
New-DlpSensitiveInformationTypeRulePackage -FileData ([System.IO.File]::ReadAllBytes('C:\My Documents\MyNewRulePack.xml'))Per informazioni dettagliate su sintassi e parametri, vedere New-DlpSensitiveInformationTypeRulePackage.
Nota
Il numero massimo di pacchetti di regole supportati è 10, ma ogni pacchetto può contenere la definizione di più tipi di informazioni riservate.
Per verificare che sia stato creato correttamente un nuovo tipo di informazioni riservate, eseguire uno dei passaggi seguenti:
Eseguire il cmdlet Get-DlpSensitiveInformationTypeRulePackage per verificare che sia elencato il nuovo pacchetto di regole:
Get-DlpSensitiveInformationTypeRulePackageEseguire il cmdlet Get-DlpSensitiveInformationType per verificare che sia elencato il tipo di informazioni riservate:
Get-DlpSensitiveInformationTypePer i tipi di informazioni riservate personalizzati, il valore proprietà Publisher sarà diverso da Microsoft Corporation.
Sostituire <Nome> con il valore nome del tipo di informazioni riservate (ad esempio, il numero ID del dipendente) ed eseguire il cmdlet Get-DlpSensitiveInformationType:
Get-DlpSensitiveInformationType -Identity "<Name>"
Possibili problemi di convalida da tenere presenti
Quando si carica il file XML del pacchetto di regole, il sistema convalida il codice XML e verifica la presenza di modelli non validi noti e problemi di prestazioni evidenti. Ecco alcuni problemi noti che la convalida verifica per un'espressione regolare:
Le asserzioni Lookbehind nell'espressione regolare devono essere di lunghezza fissa. Le asserzioni di lunghezza variabile comportano errori.
Ad esempio,
"(?<=^|\s|_)"non supererà la convalida. Il primo criterio (^) è di lunghezza zero, mentre i due modelli successivi (\se_) hanno una lunghezza pari a uno. Un modo alternativo per scrivere questa espressione regolare è"(?:^|(?<=\s|_))".Non è possibile iniziare o terminare con l'alternatore
|, che corrisponde a tutto perché è considerato una corrispondenza vuota.Ad esempio,
|aob|non supererà la convalida.Non può iniziare o terminare con un
.{0,m}modello, che non ha scopo funzionale e compromette solo le prestazioni.Ad esempio,
.{0,50}ASDFoASDF.{0,50}non supererà la convalida.Non può avere
.{0,m}o.{1,m}in gruppi e non può avere.\*o.+in gruppi.Ad esempio,
(.{0,50000})non supererà la convalida.Non è possibile avere caratteri con
{0,m}o{1,m}ripetitori in gruppi.Ad esempio,
(a\*)non supererà la convalida.Non è possibile iniziare o terminare con
.{1,m}; usare.invece .Ad esempio,
.{1,m}asdfnon supererà la convalida..asdfUsare invece .Non è possibile avere un ripetitore non associato (ad
*esempio o+) in un gruppo.Ad esempio,
(xx)\*e(xx)+non supererà la convalida.Le parole chiave hanno una lunghezza massima di 50 caratteri. Se in un gruppo è presente una parola chiave che supera questa lunghezza, è consigliabile creare il Gruppo di termini come Dizionario di parole chiave e fare riferimento al GUID del Dizionario di parole chiave nella struttura XML come parte dell’entità per Match o idMatch nel file.
Ogni tipo di informazioni sensibili personalizzate può avere un massimo di 2.048 parole chiave totali.
Le dimensioni massime dei dizionari di parole chiave in un singolo tenant sono compresse di 480 KB per rispettare i limiti dello schema di Active Directory. Quando si creano tipi di informazioni sensibili personalizzati, fare riferimento allo stesso dizionario tutte le volte necessarie. Iniziare creando elenchi di parole chiave personalizzati nel tipo di informazioni sensibili e usare dizionari di parole chiave se un elenco di parole chiave contiene più di 2048 parole chiave oppure se la lunghezza di una parola chiave supera i 50 caratteri.
In un tenant è consentito un massimo di 50 tipi di informazioni sensibili basati su dizionario di parole chiave.
Verificare che ogni elemento Entity contenga un attributo recommendedConfidence.
Quando si usa il cmdlet di PowerShell, le dimensioni massime restituite dei dati deserializzati sono di circa 1 megabyte. Ciò influisce sulle dimensioni del file XML del pacchetto di regole. Mantenere il file caricato entro un massimo di 770 kilobyte come limite suggerito per ottenere risultati coerenti senza errori durante l'elaborazione.
La struttura XML non richiede la formattazione di caratteri quali spazi, schede o voci di ritorno a capo/avanzamento riga. Tenere a mente questo fattore quando si ottimizza lo spazio per i caricamenti. Strumenti come Microsoft Visual Code forniscono funzionalità di unione righe per compattare il file XML.
Se un tipo di informazioni riservate personalizzato contiene un problema che può influire sulle prestazioni, non verrà caricato e potrebbe essere visualizzato uno di questi messaggi di errore:
Generic quantifiers which match more content than expected (e.g., '+', '*')Lookaround assertionsComplex grouping in conjunction with general quantifiers
Effettuare una nuova ricerca per indicizzazione del contenuto per identificare le informazioni riservate
Microsoft 365 usa il crawler di ricerca per identificare e classificare le informazioni riservate contenute nel sito. Il contenuto in SharePoint Online e OneDrive for Business viene sottoposto di nuovo a ricerca per indicizzazione automaticamente ogni volta che viene aggiornato. Tuttavia, per identificare il nuovo tipo di informazioni riservate personalizzato in tutto il contenuto esistente, è necessario ripetere la ricerca per indicizzazione del contenuto.
Per rivalutare il contenuto in più posizioni contemporaneamente, è possibile creare un'analisi usando la classificazione su richiesta. Altre informazioni sulla classificazione su richiesta\
Riferimento: XML Schema Definition del pacchetto di regole
È possibile copiare questo markup, salvarlo come file XSD e usarlo per convalidare il file XML del pacchetto di regole.
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="https://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<!-- Use include if this schema has the same target namespace as the schema being referenced, otherwise use import -->
<xs:element name="RulePackage" type="mce:RulePackageType"/>
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity|mce:Version/mce:Entity|mce:Version/mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword|mce:Fingerprint"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity|mce:Version/mce:Entity|mce:Version/mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
<xs:element name="Version" type="mce:VersionedRuleType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
<xs:element name="Fingerprint" type="mce:FingerprintType"/>
<xs:element name="ExtendedKeyword" type="mce:ExtendedKeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
<xs:element name="Version" type="mce:VersionedPatternType" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
<xs:element name="Version" type="mce:VersionedEvidenceType" minOccurs="0" maxOccurs="unbounded" />
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
<xs:attribute name="minCount" type="xs:positiveInteger" use="optional"/>
<xs:attribute name="uniqueResults" type="xs:boolean" use="optional"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:union>
<xs:simpleType>
<xs:restriction base='xs:string'>
<xs:enumeration value="unlimited"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType>
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="EngineVersionType">
<xs:restriction base="xs:token">
<xs:pattern value="^\d{2}\.01?\.\d{3,4}\.\d{1,3}$"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="VersionedRuleType">
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:attribute name="minEngineVersion" type="mce:EngineVersionType" use="required" />
</xs:complexType>
<xs:complexType name="VersionedPatternType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="minEngineVersion" type="mce:EngineVersionType" use="required" />
</xs:complexType>
<xs:complexType name="VersionedEvidenceType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="minEngineVersion" type="mce:EngineVersionType" use="required" />
</xs:complexType>
<xs:simpleType name="FingerprintValueType">
<xs:restriction base="xs:string">
<xs:minLength value="2732"/>
<xs:maxLength value="2732"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="FingerprintType">
<xs:simpleContent>
<xs:extension base="mce:FingerprintValueType">
<xs:attribute name="id" type="xs:token" use="required"/>
<xs:attribute name="threshold" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="shingleCount" type="xs:positiveInteger" use="required"/>
<xs:attribute name="description" type="xs:string" use="optional"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="ExtendedKeywordType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>