Introduzione ai pool di calcolo in cluster Big Data di SQL Server
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Questo articolo descrive il ruolo dei pool di calcolo di SQL Server in un cluster Big Data di SQL Server. I pool di calcolo forniscono risorse di calcolo con scalabilità orizzontale per un cluster Big Data di SQL Server. Vengono usati per l'offload del lavoro di calcolo, o dei set di risultati intermedi, dall'istanza master di SQL Server. Le sezioni seguenti descrivono l'architettura, le funzionalità e gli scenari di utilizzo di un pool di calcolo.
È anche possibile guardare questo video di 5 minuti per un'introduzione ai pool di calcolo:
Architettura dei pool di calcolo
Un pool di calcolo è costituito da uno o più pod di calcolo in esecuzione in Kubernetes. Le operazioni automatiche di creazione e gestione di questi pod sono coordinate dall'istanza master di SQL Server. Ogni pod contiene un set di servizi di base e un'istanza del motore di database di SQL Server.
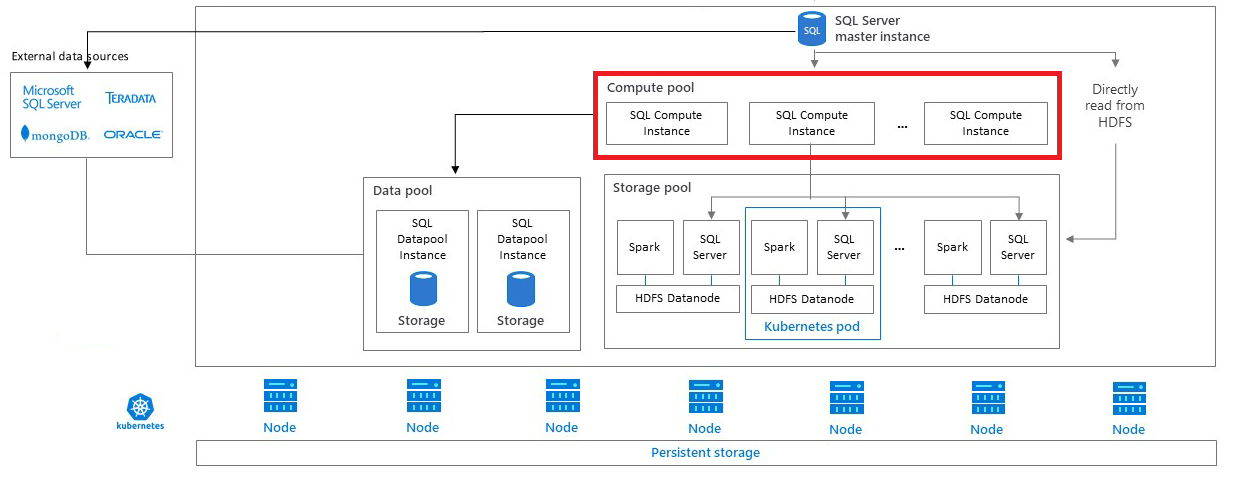
Gruppi con scalabilità orizzontale
Un pool di calcolo può svolgere la funzione di un gruppo con scalabilità orizzontale PolyBase per query distribuite tra origini dati esterne diverse, ad esempio SQL Server, Oracle, MongoDB, Teradata e HDFS. Usando pod di calcolo in Kubernetes, un cluster Big Data di SQL Server può automatizzare la creazione e la configurazione di pod di calcolo per gruppi PolyBase con scalabilità orizzontale.
Scenari di pool di calcolo
Il pool di calcolo viene usato nei seguenti scenari:
Quando le query inviate all'istanza master usano una o più tabelle presenti nel pool di archiviazione.
Quando le query inviate all'istanza master usano una o più tabelle con distribuzione round robin presenti nel pool di dati.
Quando le query inviate all'istanza master usano tabelle partizionate con origini dati esterne di SQL Server, Oracle, MongoDB e Teradata. Per questo scenario, è necessario abilitare l'opzione relativa all'hint per la query (FORCE SCALEOUTEXECUTION).
Quando le query inviate all'istanza master usano una o più tabelle presenti nella suddivisione in livelli HDFS.
Il pool di calcolo non viene usato nei seguenti scenari:
Quando le query inviate all'istanza master usano una o più tabelle presenti in un cluster Hadoop HDFS esterno.
Quando le query inviate all'istanza master usano una o più tabelle presenti in Archiviazione BLOB di Azure.
Quando le query inviate all'istanza master usano tabelle non partizionate con origini dati esterne di SQL Server, Oracle, MongoDB e Teradata.
Quando l'opzione relativa all'hint per la query (DISABLE SCALEOUTEXECUTION) è abilitata.
Quando le query inviate all'istanza master si applicano ai database presenti nell'istanza master.
Passaggi successivi
Per altre informazioni sui cluster Big Data di SQL Server, vedere le risorse seguenti:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per