Connettersi a un cluster Big Data di SQL Server con Azure Data Studio
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Questo articolo descrive come eseguire la connessione a un cluster Big Data di SQL Server 2019 da Azure Data Studio.
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Prerequisiti
- Un cluster Big Data di SQL Server 2019 distribuito.
- Strumenti per Big Data di SQL Server 2019:
- Azure Data Studio
- Estensione di SQL Server 2019
- kubectl
- azdata
Stabilire la connessione al cluster
Per connettersi a un cluster Big Data con Azure Data Studio, stabilire una nuova connessione all'istanza master di SQL Server nel cluster. Ecco come.
Individuare l'istanza master di SQL Server:
azdata bdc endpoint list -e sql-server-masterSuggerimento
Per altre informazioni su come recuperare gli endpoint, vedere Recuperare gli endpoint.
In Azure Data Studio premere F1>Nuova connessione.
In Tipo di connessione selezionare Microsoft SQL Server.
Digitare il nome dell'endpoint trovato per l'istanza master di SQL Server nella casella di testo Nome server, ad esempio: <IP_Address>,31433.
Scegliere il tipo di autenticazione. Per l'istanza master di SQL Server in esecuzione all'interno di cluster Big Data, sono supportati solo i tipi Autenticazione di Windows e Account di accesso SQL.
Se si usa l'account di accesso SQL, immettere l'account di accesso SQL: Nome utente e Password.
Suggerimento
Per impostazione predefinita, durante la distribuzione di cluster Big Data il nome utente SA è disabilitato. Durante la distribuzione viene eseguito il provisioning di un nuovo utente sysadmin con nome e password corrispondenti alle variabili di ambiente AZDATA_USERNAME e AZDATA_PASSWORD, impostate prima o durante a distribuzione.
Modificare il Nome database di destinazione in uno dei database relazionali.
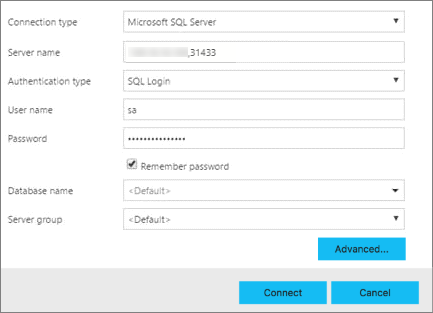
Premere Connetti. Verrà visualizzata la finestra Dashboard server.
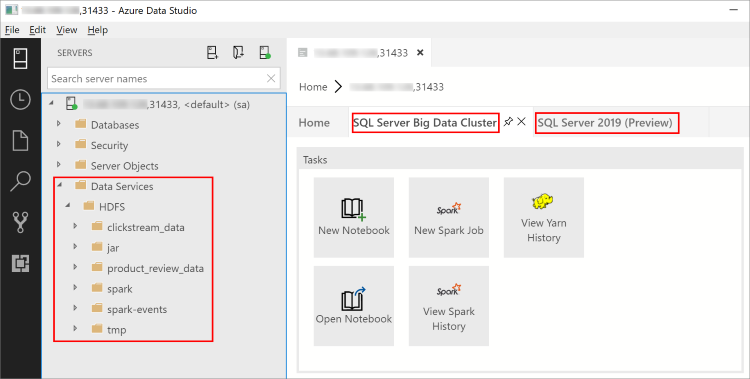
A partire dalla versione di febbraio 2019 di Azure Data Studio, la connessione all'istanza master di SQL Server Master consente anche di interagire con il gateway HDFS/Spark. Questo significa che non è necessario usare una connessione separata per HDFS e Spark secondo la procedura descritta nella sezione successiva.
Esplora oggetti contiene ora un nuovo nodo Servizi dati con supporto per le attività del cluster Big Data tramite il pulsante destro del mouse, come la creazione di nuovi notebook o l'invio di processi Spark.
Il nodo Servizi dati contiene anche una cartella HDFS che consente di esplorare il contenuto del sistema HDFS e di eseguire attività comuni che interessano HDFS, ad esempio la creazione di una tabella esterna o l'apertura di un notebook per l'analisi del contenuto di HDFS.
Nel Dashboard server per la connessione sono contenute anche schede per il cluster Big Data di SQL Server e SQL Server 2019 quando è installata l'estensione.
Passaggi successivi
Per altre informazioni sui cluster Big Data di SQL Server 2019, vedere Che cosa sono i cluster Big Data di SQL Server 2019?.