Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
I cluster Big Data di Microsoft SQL Server 2019 sono stati ritirati. Il supporto per i cluster Big Data di SQL Server 2019 è terminato a partire dal 28 febbraio 2025. Per altre informazioni, vedere il post di blog sull'annuncio e le opzioni per Big Data nella piattaforma Microsoft SQL Server.
SQL Server offre un'estensione per Azure Data Studio che include taccuini di distribuzione. Un notebook di distribuzione include documentazione e codice che è possibile usare in Azure Data Studio per creare un cluster Big Data di SQL Server.
Implementati inizialmente come progetto open source, i notebook sono stati implementati in Azure Data Studio. È possibile usare markdown per il testo nelle celle di testo e uno dei kernel disponibili per scrivere codice nelle celle di codice.
È possibile usare i notebook per distribuire cluster Big Data di SQL Server.
Prerequisites
Per avviare il notebook sono necessari anche i prerequisiti seguenti:
- Versione più recente della build Insider di Azure Data Studio installata
Oltre a quanto sopra riportato, la distribuzione di un cluster Big Data richiede anche:
Avviare il notebook
Avviare Azure Data Studio.
Nella scheda Connessioni selezionare i puntini di sospensione (...), quindi selezionare Distribuisci SQL Server....
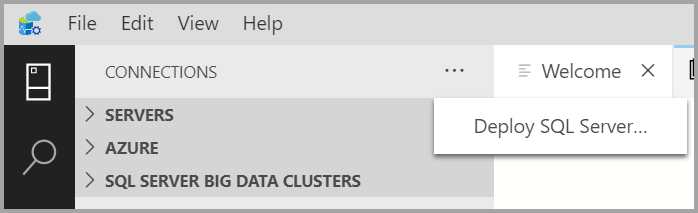
Nelle opzioni di distribuzione selezionare Cluster Big Data di SQL Server.
Nella destinazione di distribuzione, in Opzioni, selezionare Nuovo cluster Azure Kubernetes o Cluster del servizio Azure Kubernetes esistente.
Accettare le condizioni di privacy e licenza.
Questa finestra di dialogo controlla anche se gli strumenti necessari per il tipo di distribuzione SQL scelto esistono nell'host. Il pulsante Seleziona non è abilitato fino a quando il controllo degli strumenti non ha successo.
Fare clic sul pulsante Seleziona. Questa azione avvia l'esperienza di distribuzione.
Impostare il modello di configurazione della distribuzione
È possibile personalizzare le impostazioni del profilo di distribuzione seguendo le istruzioni riportate di seguito.
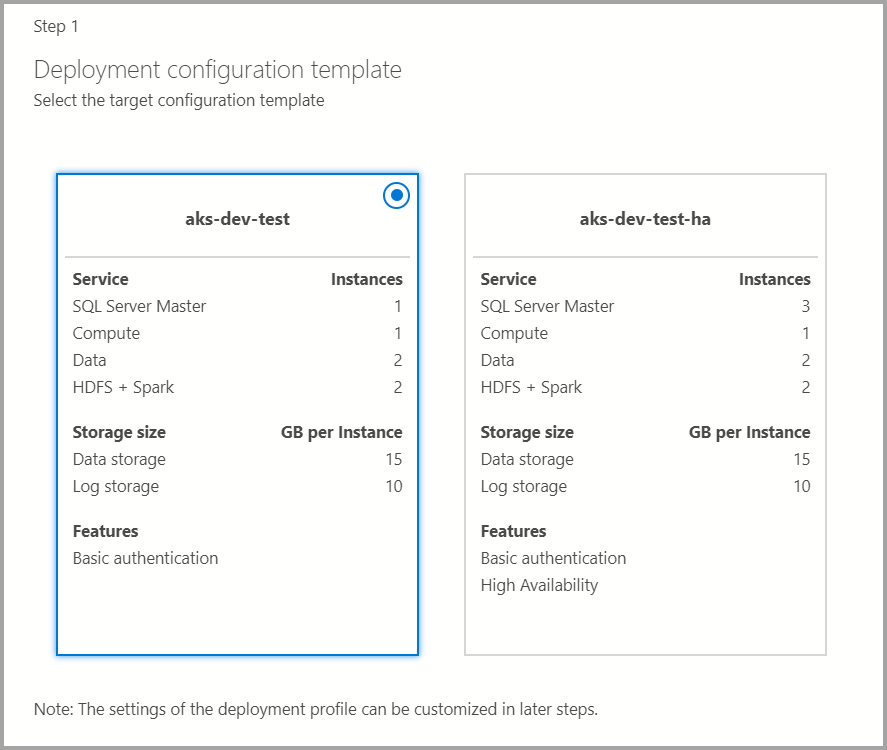
Modello di configurazione di obiettivo
Selezionare il modello di configurazione di destinazione dai modelli disponibili. I profili disponibili vengono filtrati a seconda del tipo di destinazione di distribuzione scelto nella finestra di dialogo precedente.
Azure settings
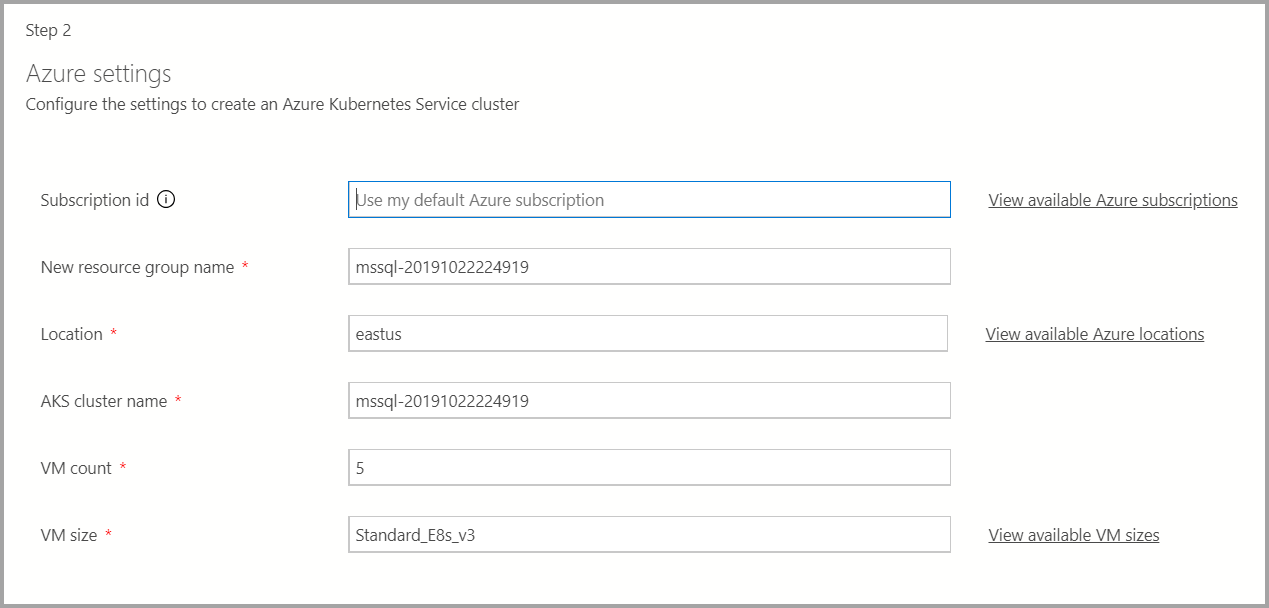
Se la destinazione di distribuzione è un nuovo servizio Azure Kubernetes, sono necessarie informazioni aggiuntive, ad esempio ID sottoscrizione di Azure, gruppo di risorse, nome del cluster del servizio Azure Kubernetes, numero di macchine virtuali, dimensioni e altre informazioni aggiuntive per creare il cluster del servizio Azure Kubernetes.
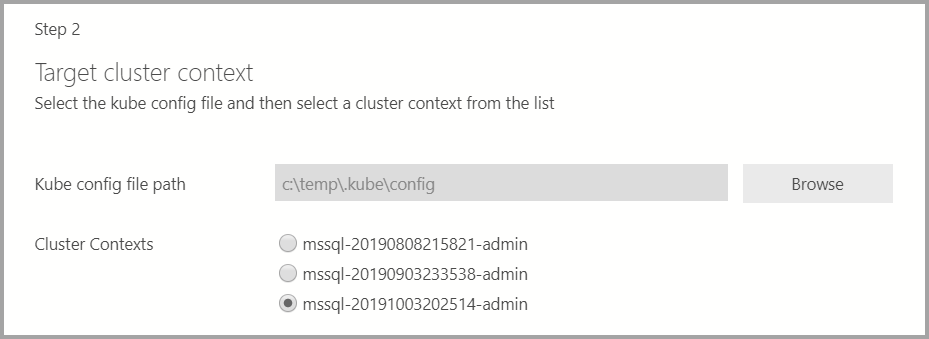
Se la destinazione di distribuzione è un cluster Kubernetes esistente, la procedura guidata richiede il percorso del file di configurazione kube per importare le impostazioni del cluster Kubernetes. Assicurarsi che sia selezionato il contesto del cluster appropriato in cui è possibile distribuire il cluster Big Data di SQL Server 2019.
Impostazioni del cluster, docker e di Active Directory
Immettere il nome del cluster per il cluster Big Data, un nome utente amministratore e una password. Questo stesso account viene usato per il controller e SQL Server.
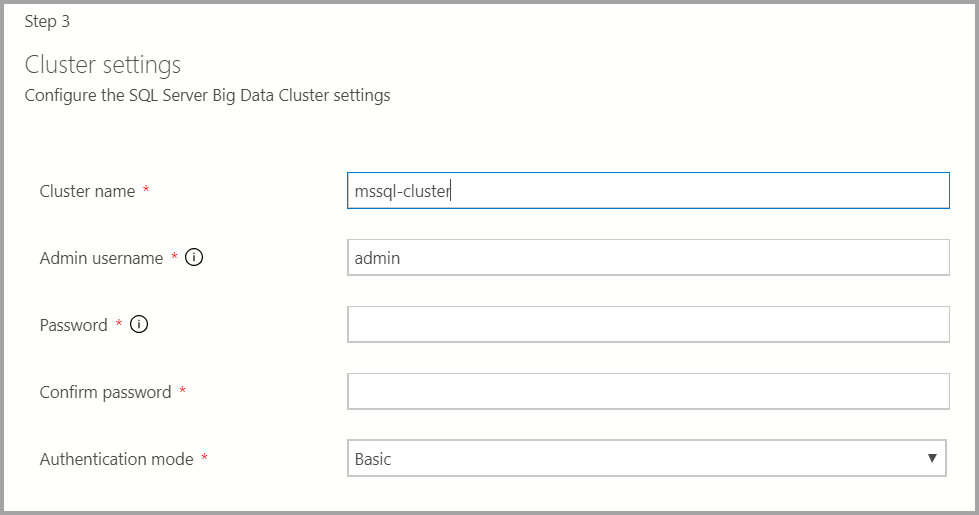
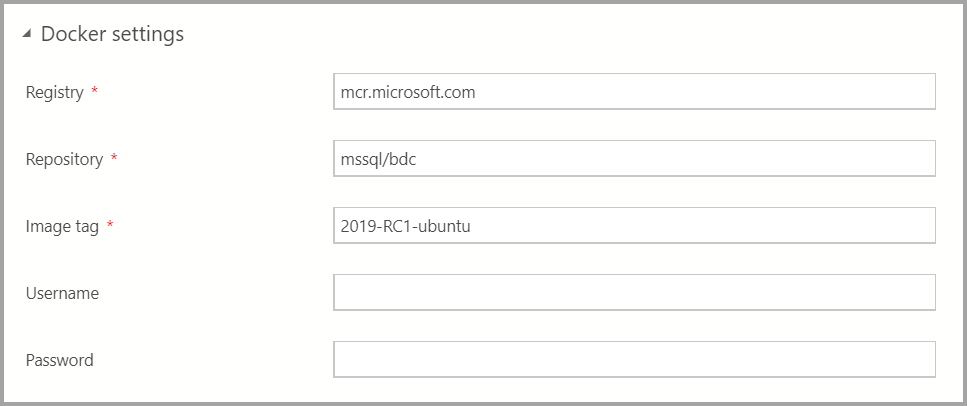
Immettere le impostazioni di Docker in base alle esigenze.
Important
Assicurarsi che il campo tag immagine sia più recente: 2019-CU13-ubuntu-20.04
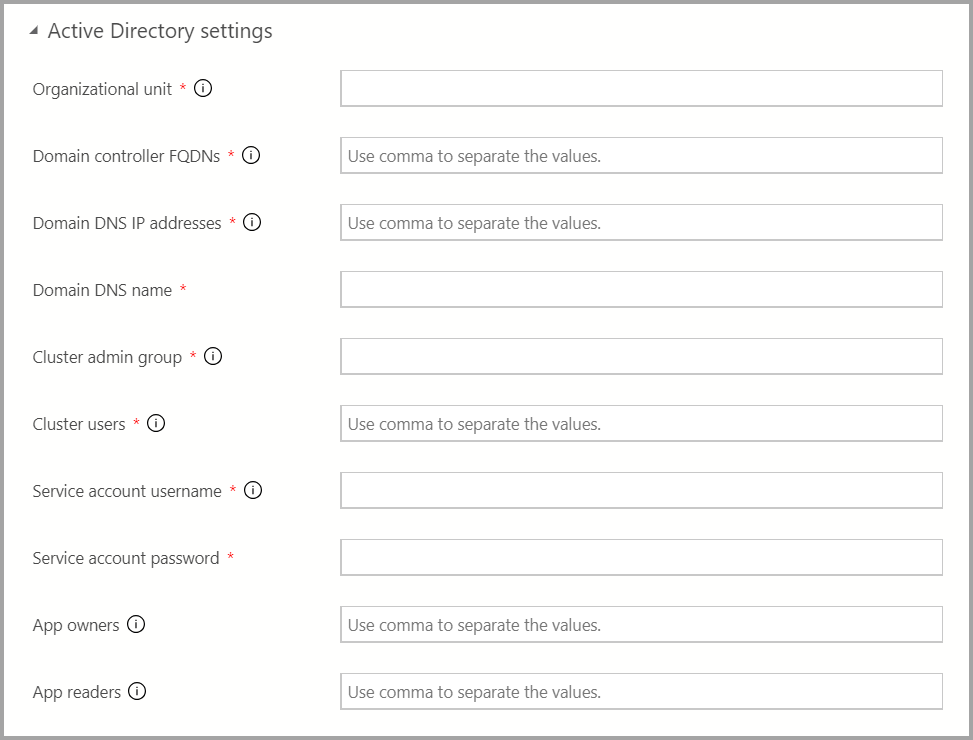
Se l'autenticazione di Active Directory è disponibile, immettere le impostazioni di Active Directory.
Service settings
Questa schermata include input per varie impostazioni, ad esempio Scalabilità, Endpoint, Archiviazione e altre impostazioni di archiviazione avanzate. Immettere i valori appropriati e selezionare Avanti.
Scale settings
Immettere il numero di istanze di ognuno dei componenti nel cluster Big Data.
Un'istanza di Spark può essere inclusa insieme a HDFS. È incluso nel pool di archiviazione o in modo autonomo nel pool di Spark.
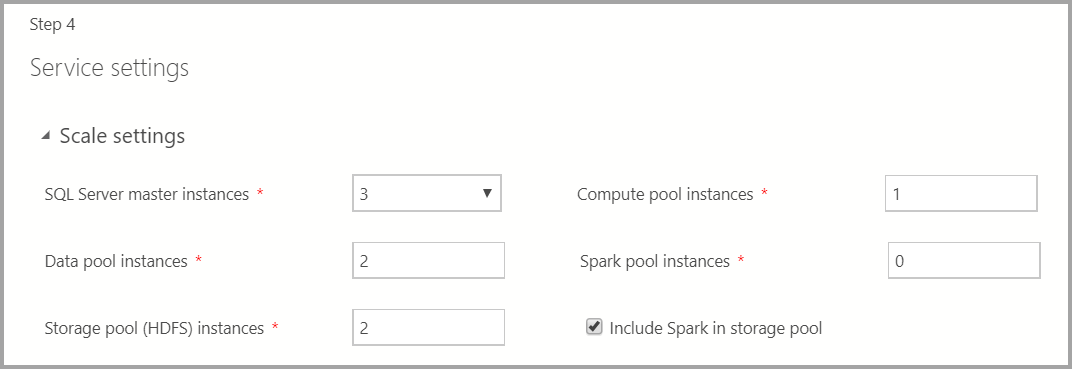
Per altre informazioni su ognuno di questi componenti, è possibile fare riferimento a istanza master, pool di dati, pool di archiviazione o pool di calcolo.
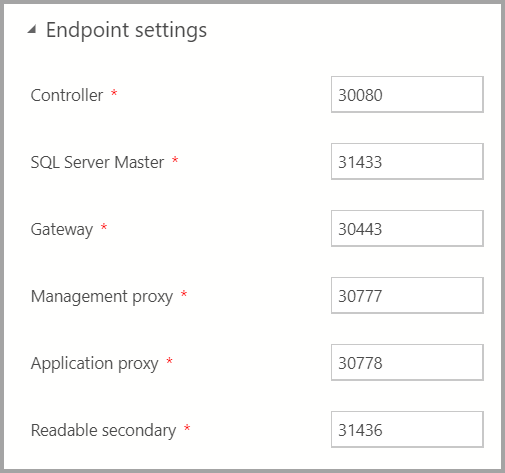
Endpoint settings
Gli endpoint predefiniti sono stati precompilati. Tuttavia, possono essere modificati in base alle esigenze.
Storage settings
Le impostazioni di archiviazione includono la classe di archiviazione e la dimensione della richiesta per i dati e i registri. Le impostazioni possono essere applicate tra archiviazione, dati e pool master di SQL Server.

Impostazioni di archiviazione avanzate
È possibile aggiungere impostazioni di archiviazione aggiuntive in Impostazioni di archiviazione avanzate
Pool di archiviazione (HDFS)
Data pool
Master di SQL Server

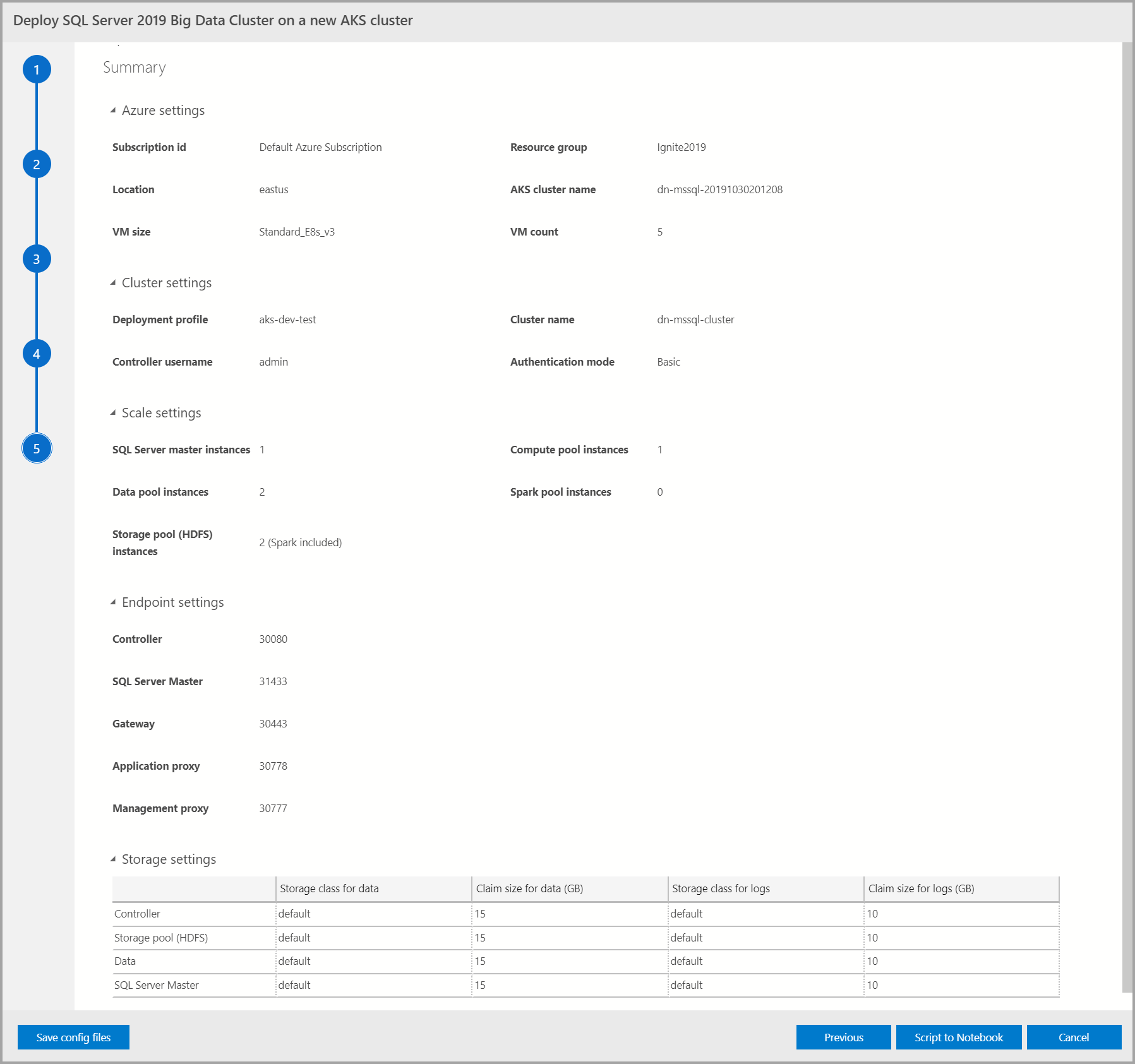
Summary
Questa schermata riepiloga tutti gli input forniti per distribuire il cluster Big Data. I file di configurazione possono essere scaricati tramite il pulsante Salva file di configurazione . Selezionare Script to Notebook (Script to Notebook ) per creare uno script dell'intera configurazione di distribuzione in un notebook. Quando il notebook è aperto, selezionare Esegui celle per avviare la distribuzione del cluster Big Data nella destinazione selezionata.
Next steps
Per altre informazioni sulla distribuzione, vedere Linee guida per la distribuzione per i cluster Big Data di SQL Server.