Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
I cluster Big Data di Microsoft SQL Server 2019 sono stati ritirati. Il supporto per i cluster Big Data di SQL Server 2019 è terminato a partire dal 28 febbraio 2025. Per altre informazioni, vedere il post di blog sull'annuncio e le opzioni per Big Data nella piattaforma Microsoft SQL Server.
Questa esercitazione illustra come caricare ed eseguire un notebook in Azure Data Studio in un cluster Big Data di SQL Server 2019. In questo modo i data scientist e i data engineer possono eseguire codice Python, R o Scala nel cluster.
Tip
Se si preferisce, è possibile scaricare ed eseguire uno script per i comandi di questa esercitazione. Per istruzioni, vedere gli esempi di Spark in GitHub.
Prerequisites
-
Strumenti per Big Data
- kubectl
- Azure Data Studio
- Estensione SQL Server 2019
- Caricare dati di esempio nel cluster Big Data
Scaricare il file del notebook di esempio
Usare le istruzioni seguenti per caricare il file del notebook di esempio spark-sql.ipynb in Azure Data Studio.
Aprire un prompt dei comandi bash (Linux) o Windows PowerShell.
Accedere a una cartella dove si vuole scaricare il file del notebook di esempio.
Eseguire il comando curl seguente per scaricare il file del notebook da GitHub:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Aprire il notebook
La procedura seguente illustra come aprire il file del notebook in Azure Data Studio:
In Azure Data Studio, collegatevi all'istanza master del cluster di big data. Per altre informazioni, vedere Connettersi a un cluster Big Data.
Fare doppio clic sulla connessione gateway HDFS/Spark nella finestra Server . Selezionare quindi Apri notebook.
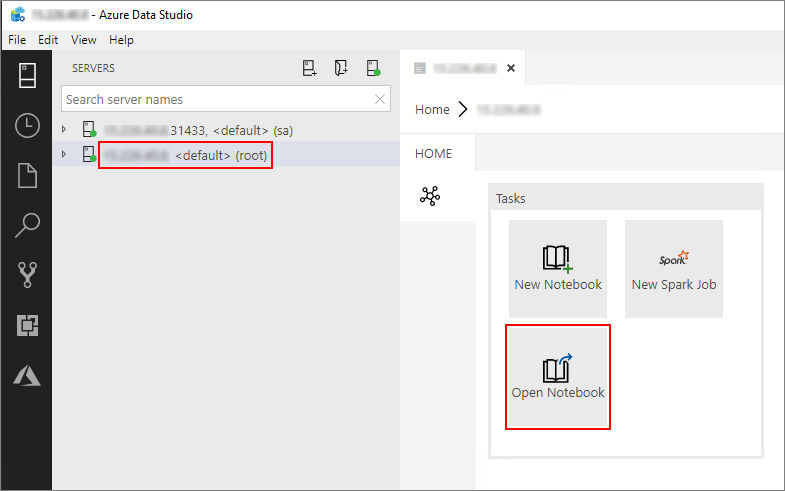
Attendere che il kernel e il contesto di destinazione (Aggancia a) siano popolati. Impostare Kernel su PySpark3 e impostare Connetti a sull'indirizzo IP dell'endpoint del cluster Big Data.
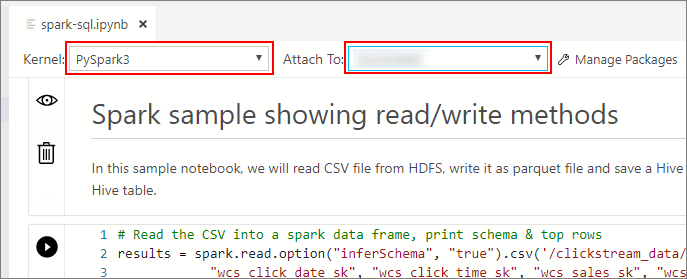
Important
In Azure Data Studio tutti i tipi di notebook Spark (Scala Spark, PySpark e SparkR) definiscono convenzionalmente alcune importanti variabili correlate alla sessione Spark al primo esecuzione della cella. Queste variabili sono: spark, sce sqlContext. Quando si copia la logica dai notebook per l'invio in batch (ad esempio, in un file Python da eseguire con azdata bdc spark batch create ), assicurarsi di definire le variabili di conseguenza.
Esegui le celle del notebook
È possibile eseguire ogni cella del notebook premendo il pulsante play a sinistra della cella. I risultati verranno visualizzati nel notebook dopo che la cella ha terminato l'esecuzione.

Eseguire ognuna delle celle del notebook di esempio in successione. Per altre informazioni sull'uso di notebook con cluster Big Data di SQL Server, vedere le risorse seguenti:
Next steps
Altre informazioni sui notebook: