Creare, esportare e classificare i modelli di Machine Learning di Spark in cluster Big Data di SQL Server
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Nell'esempio seguente viene illustrato come creare un modello con Machine Learning Spark, esportare il modello in MLeap e quindi assegnare punteggi al modello in SQL Server con l'estensione del linguaggio Java. Questa operazione viene eseguita nel contesto di un cluster Big Data di SQL Server.
Nella figura seguente vengono illustrate le operazioni eseguite in questo esempio:
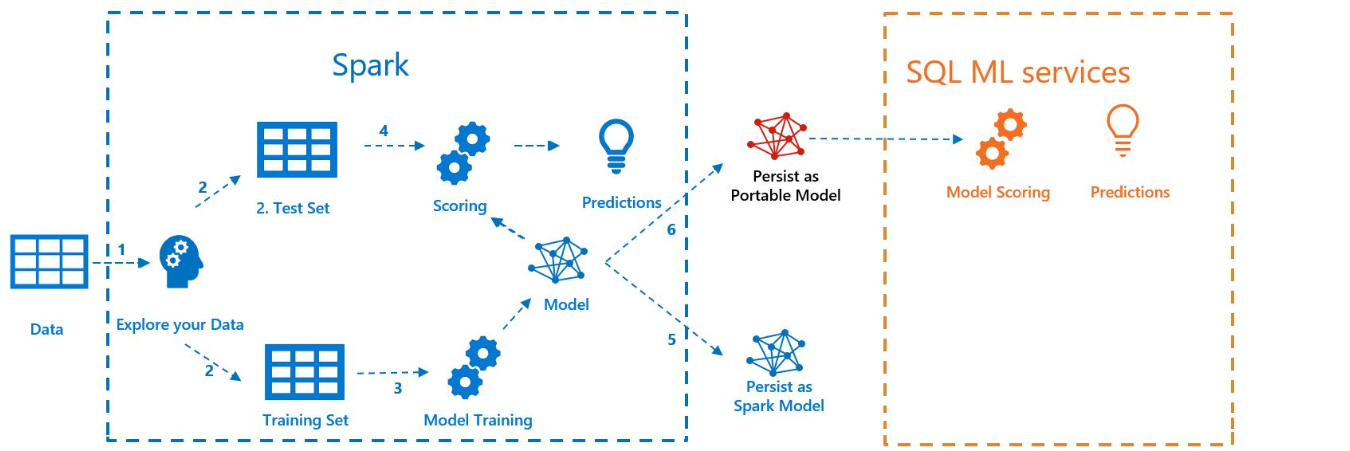
Prerequisiti
Tutti i file necessari per questo esempio si trovano in https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Per poter eseguire l'esempio, è necessario anche soddisfare i prerequisiti seguenti:
-
- kubectl
- curl
- Azure Data Studio
Training del modello con Machine Learning Spark
In questo esempio, per creare un modello di pipeline per Machine Learning Spark vengono usati dati di Census (AdultCensusIncome.csv).
Usare il file mleap_sql_test/setup.sh per scaricare il set di dati da Internet e inserirlo nel sistema HDFS all'interno del cluster Big Data di SQL Server, in modo che sia accessibile da Spark.
Scaricare quindi il notebook di esempio train_score_export_ml_models_with_spark.ipynb. Da una riga di comando di PowerShell o della shell Bash, eseguire il comando seguente per scaricare il notebook:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Il notebook contiene le celle con i comandi necessari per questa sezione dell'esempio.
Aprire il notebook in Azure Data Studio ed eseguire ogni blocco di codice. Per altre informazioni sull'uso dei notebook, vedere Come usare i notebook in SQL Server.
Per prima cosa, i dati vengono letti in Spark e suddivisi in set di dati di training e di testing. Il codice esegue quindi il training di un modello di pipeline con i dati di training ed esporta infine il modello in un bundle MLeap.
Suggerimento
È possibile rivedere o eseguire il codice Python associato a questi passaggi anche all'esterno del notebook, nel file mleap_sql_test/mleap_pyspark. py.
Assegnazione di punteggi al modello con SQL Server
Ora che il modello di pipeline per Machine Learning Spark si trova nel formato di serializzazione comune bundle MLeap, è possibile assegnare punteggi al modello in Java anche senza la presenza di Spark.
Questo esempio usa l'estensione del linguaggio Java in SQL Server. Per poter assegnare i punteggi al modello in SQL Server, è prima necessario sviluppare un'applicazione Java in grado di caricare il modello in Java e assegnargli i punteggi. È possibile trovare il codice di esempio per questa applicazione Java nella cartella mssql-mleap-app.
Dopo aver creato l'esempio, è possibile usare Transact-SQL per chiamare l'applicazione Java e assegnare i punteggi al modello con una tabella di database, disponibile nel file di origine mleap_sql_test/mleap_sql_tests.py.
Passaggi successivi
Per altre informazioni sui cluster Big Data, vedere Come distribuire cluster Big Data di SQL Server in Kubernetes