Inviare processi Spark nel cluster Big Data di SQL Server in Visual Studio Code
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Informazioni su come usare Spark & Hive Tools per Visual Studio Code per creare e inviare script PySpark per Apache Spark. Verrà prima di tutto descritto come installare gli strumenti Spark e Hive in Visual Studio Code e quindi verrà illustrato come inviare i processi a Spark.
È possibile installare Spark & Hive Tools nelle piattaforme supportate da Visual Studio Code, tra cui Windows, Linux e macOS. Di seguito sono illustrati i prerequisiti per le diverse piattaforme.
Prerequisiti
Per completare i passaggi in questo articolo, è necessario quanto segue:
- Un cluster Big Data di SQL Server. Vedere Cluster Big Data di SQL Server.
- Visual Studio Code.
- Python e l'estensione Python in Visual Studio Code.
- Mono. Mono è necessario solo per Linux e macOS.
- Configurare l'ambiente interattivo PySpark per Visual Studio Code.
- Una directory locale denominata SQLBDCexample. Questo articolo usa C:\SQLBDC\SQLBDCexample.
Installare Spark & Hive Tools
Dopo aver completato i prerequisiti, è possibile installare Spark & Hive Tools per Visual Studio Code. Per installare Spark & Hive Tools, eseguire questa procedura:
Aprire Visual Studio Code.
Dalla barra dei menu passare a Visualizza>Estensioni.
Nella casella di ricerca immettere Spark & Hive.
Selezionare Spark & Hive Tools, pubblicato da Microsoft, dai risultati della ricerca e quindi selezionare Installa.
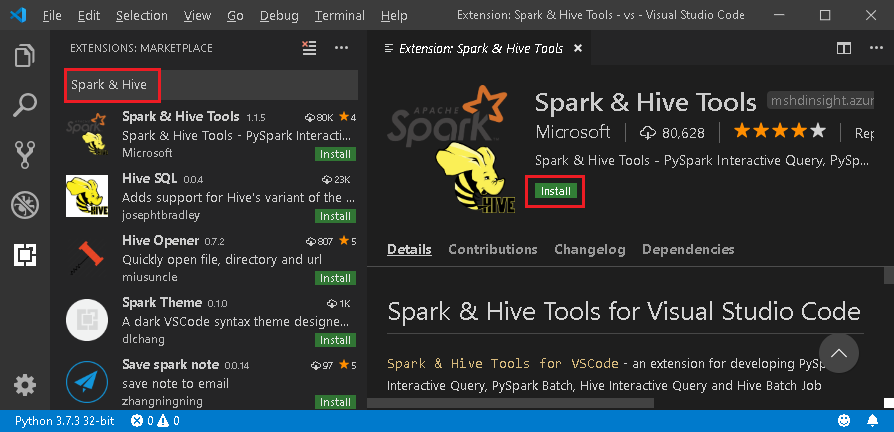
Ricaricare quando necessario.
Aprire la cartella di lavoro
Completare la procedura seguente per aprire una cartella di lavoro e creare un file in Visual Studio Code:
Dalla barra dei menu passare a File>Apri cartella>C:\SQLBDC\SQLBDCexample e quindi fare clic sul pulsante Seleziona cartella. La cartella verrà visualizzata nella visualizzazione Explorer a sinistra.
Dalla visualizzazione Explorer selezionare la cartella, SQLBDCexample e quindi l'icona Nuovo file accanto alla cartella di lavoro.
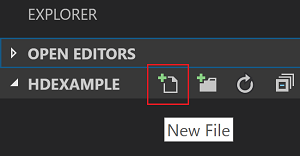
Assegnare al nuovo file l'estensione
.py(script Spark). Questo esempio usa HelloWorld.py.Copiare e incollare il codice seguente nel file di script:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Collegare un cluster Big Data di SQL Server
Prima di poter inviare script ai cluster da Visual Studio Code, è necessario collegare un cluster Big Data di SQL Server.
Dalla barra dei menu passare a Visualizza>Riquadro comandi e immettere Spark/Hive: Link a Cluster (Spark/Hive: Collega un cluster).

Selezionare il tipo di cluster collegato SQL Server Big Data (Big Data di SQL Server).
Immettere l'endpoint dei Big Data di SQL Server.
Immettere il nome utente del cluster Big Data di SQL Server.
Immettere la password per l'amministratore utenti.
Impostare il nome visualizzato del cluster Big Data (facoltativo).
Elencare i cluster ed esaminare la visualizzazione OUTPUT per verificare.
Elencare i cluster
Dalla barra dei menu passare a Visualizza>Riquadro comandi e immettere Spark/Hive: List Cluster (Spark/Hive: Elenca cluster).
Esaminare la visualizzazione OUTPUT. La visualizzazione mostrerà i cluster collegati.

Impostare il cluster predefinito
Aprire di nuovo la cartella SQLBDCexample creata in precedenza, se è stata chiusa.
Selezionare il file HelloWorld.py creato in precedenza. Il file verrà aperto nell'editor di script.
Collegare un cluster, se non è ancora stato fatto.
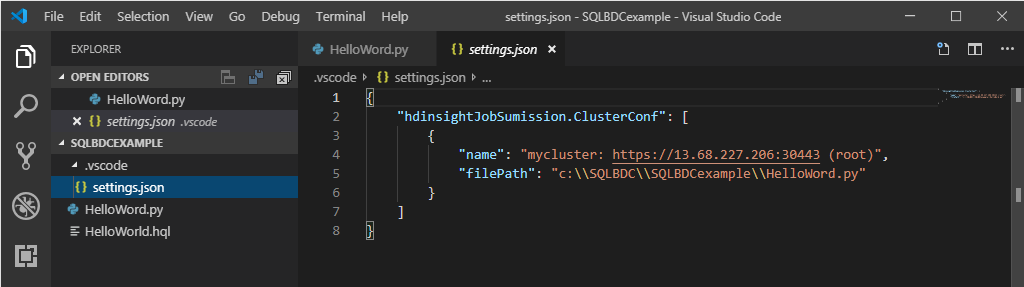
Fare clic con il pulsante destro del mouse sull'editor di script e selezionare Spark/Hive: Set Default Cluster (Spark/Hive: Impostare il cluster predefinito).
Selezionare un cluster come predefinito per il file di script corrente. Gli strumenti aggiornano automaticamente il file di configurazione .VSCode\settings.json.
Inviare query PySpark interattive
È possibile inviare query PySpark interattive seguendo questa procedura:
Aprire di nuovo la cartella SQLBDCexample creata in precedenza, se è stata chiusa.
Selezionare il file HelloWorld.py creato in precedenza. Il file verrà aperto nell'editor di script.
Collegare un cluster, se non è ancora stato fatto.
Scegliere tutto il codice e fare clic con il pulsante destro del mouse sull'editor di script, scegliere Spark: PySpark Interactive per inviare la query oppure usare il tasto di scelta rapida CTRL+ALT+I.
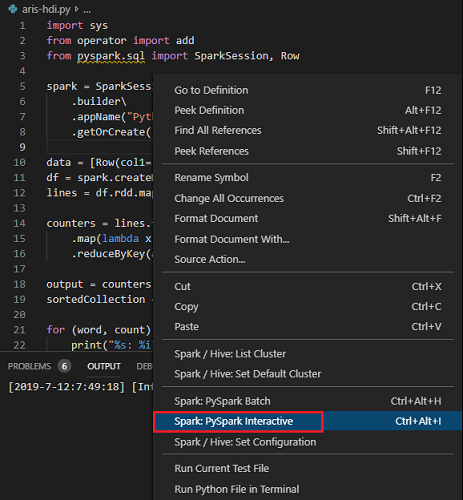
Selezionare il cluster se non è stato specificato un cluster predefinito. Dopo alcuni istanti, i risultati di Python Interactive vengono visualizzati in una nuova scheda. Gli strumenti consentono anche di inviare un blocco di codice anziché l'intero file di script usando il menu di scelta rapida.
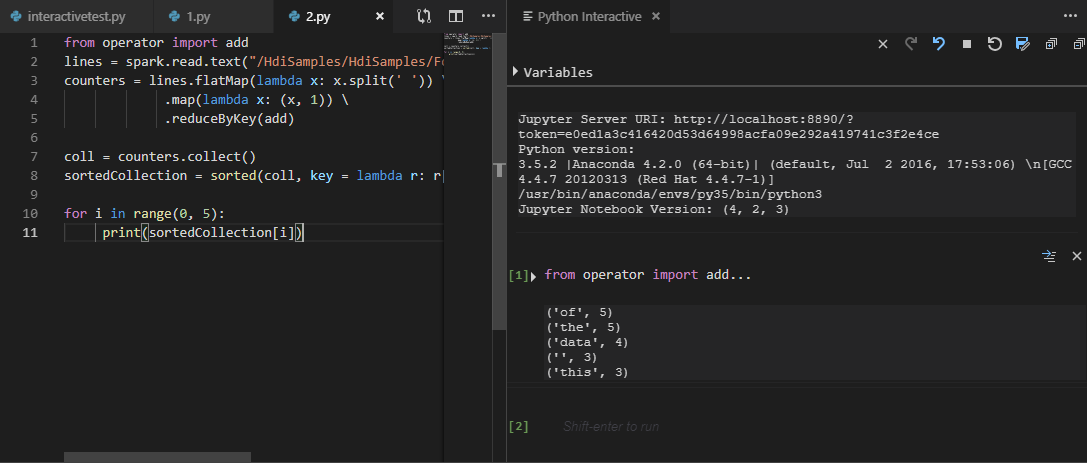
Immettere "%%info" e quindi premere MAIUSC+INVIO per visualizzare le informazioni sul processo. (Valore facoltativo)
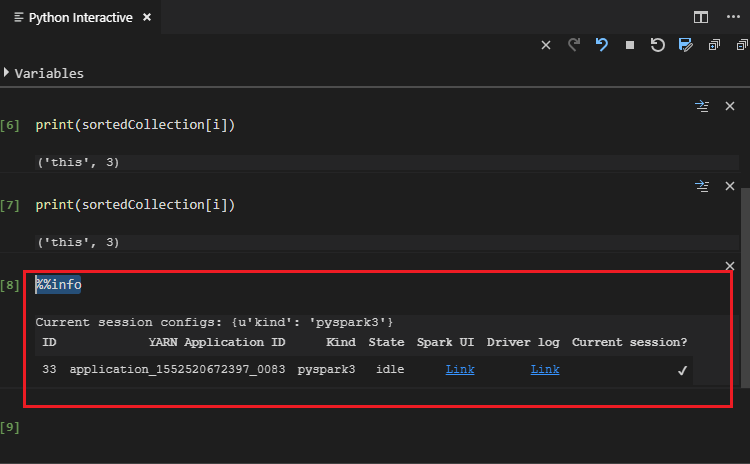
Nota
Quando l'opzione Python Extension Enabled (Estensione Python abilitata) è deselezionata nelle impostazioni (per impostazione predefinita è selezionata), i risultati dell'interazione PySpark inviata useranno la finestra precedente.
Inviare il processo batch PySpark
Aprire di nuovo la cartella SQLBDCexample creata in precedenza, se è stata chiusa.
Selezionare il file HelloWorld.py creato in precedenza. Il file verrà aperto nell'editor di script.
Collegare un cluster, se non è ancora stato fatto.
Fare clic con il pulsante destro del mouse sull'editor di script e quindi selezionare Spark: PySpark Batch o usare i tasti di scelta rapida CTRL + ALT + H.
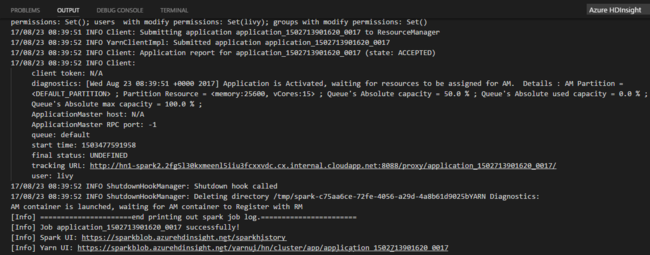
Selezionare il cluster se non è stato specificato un cluster predefinito. Dopo aver inviato un processo Python, i log di invio vengono visualizzati nella finestra OUTPUT in Visual Studio Code. Vengono visualizzati anche i valori di Spark UI URL (URL UI Spark) e Yarn UI URL (URL UI Yarn). È possibile aprire l'URL in un Web browser per tenere traccia dello stato del processo.
Configurazione di Apache Livy
La configurazione di Apache Livy è supportata e può essere impostata in .VSCode\settings.json nella cartella dell'area di lavoro. Attualmente, la configurazione di Livy supporta solo script Python. Per altre informazioni, vedere il file README di Livy.
Come attivare la configurazione di Livy
Metodo 1
- Dalla barra dei menu passare a File>Preferenze>Impostazioni.
- Nella casella di testo Impostazioni di ricerca immettere HDInsight Job Submission: Livy Conf.
- Selezionare Edit in settings.json (Modifica in settings.json) per il risultato della ricerca pertinente.
Metodo 2
Inviare un file e osservare che la cartella .vscode viene aggiunta automaticamente alla cartella di lavoro. Per trovare la configurazione Livy, selezionare settings.json in .vscode.
Impostazioni del progetto:
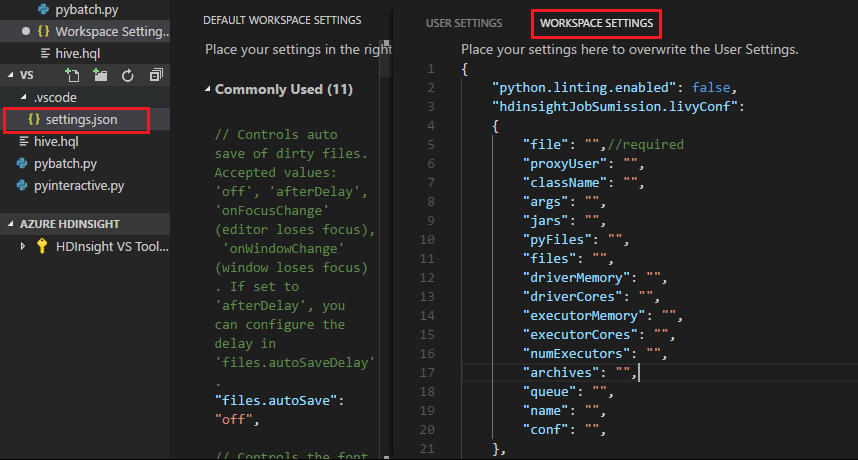
Nota
Per le impostazioni driverMemory ed executorMemory, impostare il valore con l'unità, ad esempio 1 GB o 1024 MB.
Configurazioni di Livy supportate
POST/batch
Testo della richiesta
| name | description | type |
|---|---|---|
| file | File contenente l'applicazione da eseguire | Percorso (obbligatorio) |
| proxyUser | Utente da rappresentare quando si esegue il processo | string |
| className | Classe principale Java/Spark dell'applicazione | string |
| args | Argomenti della riga di comando per l'applicazione | Elenco di stringhe |
| jars | File jar da usare in questa sessione | Elenco di stringhe |
| pyFiles | File Python da usare in questa sessione | Elenco di stringhe |
| files | File da usare in questa sessione | Elenco di stringhe |
| driverMemory | Quantità di memoria da usare per il processo del driver | string |
| driverCores | Numero di core da usare per il processo del driver | int |
| executorMemory | Quantità di memoria da usare per un processo executor | string |
| executorCores | Numero di core da usare per ogni executor | int |
| numExecutors | Numero di executor da avviare per questa sessione | int |
| archives | Archivi da usare in questa sessione | Elenco di stringhe |
| queue | Nome della coda YARN dove è stato eseguito l'invio | string |
| name | Nome della sessione | string |
| conf | Proprietà di configurazione Spark | Mappa di chiave=valore |
| :- | :- | :- |
Testo della risposta
Oggetto batch creato.
| name | description | type |
|---|---|---|
| id | ID della sessione | int |
| appId | ID applicazione della sessione | String |
| appInfo | Informazioni dettagliate sull'applicazione | Mappa di chiave=valore |
| log | Righe di log | Elenco di stringhe |
| state | Stato del batch | string |
| :- | :- | :- |
Nota
La configurazione di Livy assegnata verrà visualizzata nel riquadro di output quando si invia lo script.
Funzionalità aggiuntive
Spark & Hive Tools per Visual Studio Code supporta le funzionalità seguenti:
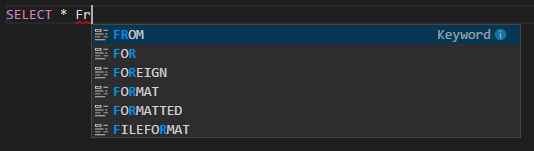
Completamento automatico di IntelliSense. Popup con suggerimenti per parole chiave, metodi, variabili e altro ancora. Le diverse icone rappresentano tipi diversi di oggetti.
Marcatori di errore di IntelliSense. Il servizio di linguaggio sottolinea gli errori nello script Hive.
Evidenziazioni della sintassi. Il servizio di linguaggio usa colori diversi per distinguere variabili, parole chiave, tipi di dati, funzioni e altro ancora.
Scollegare il cluster
Dalla barra dei menu passare a Visualizza>Riquadro comandi e immettere Spark/Hive: Unlink a Cluster (Spark/Hive: Scollega cluster).
Selezionare il cluster da scollegare.
Esaminare la visualizzazione OUTPUT per verificare.
Passaggi successivi
Per altre informazioni sui cluster Big Data di SQL Server e sugli scenari correlati, vedere Cluster Big Data di SQL Server.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per