Monitorare le prestazioni dei gruppi di disponibilità Always On
Si applica a:![]() SQL Server
SQL Server
Le prestazioni di Gruppi di disponibilità Always On sono un aspetto importante per garantire il contratto di servizio per i database cruciali. Conoscere come i gruppi di disponibilità inviano i log alle repliche secondarie può aiutare a stimare l'obiettivo del tempo di ripristino (RTO, recovery time objective) e l'obiettivo del punto di ripristino (RPO, recovery point objective) dell'implementazione della disponibilità e identificare i colli di bottiglia in gruppi o repliche di disponibilità le cui prestazioni risultano scarse. In questo articolo viene descritto il processo di sincronizzazione, viene illustrato come calcolare alcune delle metriche chiave e vengono specificati i collegamenti ad alcuni scenari comuni per la risoluzione dei problemi relativi alle prestazioni.
Processo di sincronizzazione dei dati
Per stimare il tempo di sincronizzazione completa e identificare il collo di bottiglia, è necessario conoscere il processo di sincronizzazione. Un collo di bottiglia delle prestazioni può verificarsi in punto qualsiasi del processo. Se si individua il punto del collo di bottiglia è possibile analizzare in modo approfondito i problemi sottostanti. La figura e la tabella seguenti illustrano il processo di sincronizzazione dei dati:

| Sequence | Descrizione passaggio | Commenti | Metrica utile |
|---|---|---|---|
| 1 | Generazione log | I dati del log vengono scaricati su disco. Il log deve essere replicato nelle repliche secondarie. I record del log immettono la coda di invii. | SQL Server:Database > Byte di log scaricati\sec |
| 2 | Capture | I log di ogni database vengono acquisiti e inviati alla coda del partner corrispondente (uno per ogni coppia di replica/database). Il processo di acquisizione viene eseguito in modo continuo purché la replica di disponibilità sia connessa e lo spostamento dei dati non sia per qualche motivo sospeso. La coppia replica/database avrò lo stato Sincronizzazione in corso o Sincronizzato. Se il processo di acquisizione non esegue l'analisi e accoda i messaggi a una velocità sufficiente, si crea la coda di invii del log. | SQL Server: Replica di disponibilità > Byte inviati alla replica/sec, vale a dire un'aggregazione della somma di tutti i messaggi di database accodati per tale replica di disponibilità. log_send_queue_size (KB) e log_bytes_send_rate (KB/sec) nella replica primaria. |
| 3 | Send | I messaggi di ogni coda della replica/database vengono rimossi dalla coda e inviati in rete alla rispettiva replica secondaria. | SQL Server:Replica di disponibilità > Byte inviati al trasporto/sec |
| 4 | Ricezione e memorizzazione nella cache | Ogni replica secondaria riceve il messaggio e lo memorizza nella cache. | Contatore delle prestazioni SQL Server:Replica di disponibilità > Byte log ricevuti/sec |
| 5 | Finalizzazione | Il log viene scaricato nella replica secondaria per la finalizzazione. Dopo aver scaricato il log, alla replica primaria viene inviato un acknowledgement. Finalizzando il log, si evita la perdita dei dati. |
Contatore delle prestazioni SQL Server:Database > Byte di log scaricati/sec Tipo di attesa HADR_LOGCAPTURE_SYNC |
| 6 | Ripeti | Ripristinare le pagine scaricate nella replica secondaria. Le pagine vengono mantenute nella coda di rollforward in attesa del rollforward. | SQL Server:Replica di database > Byte di cui è stato eseguito il rollforward/sec redo_queue_size (KB) e redo_rate. Tipo di attesa REDO_SYNC |
Controlli di flusso
I gruppi di disponibilità sono progettati con controlli di flusso nella replica primaria che consentono di evitare un consumo eccessivo delle risorse, ad esempio delle risorse di rete e di memoria, in tutte le repliche di disponibilità. Questi controlli non condizionano lo stato di integrità della sincronizzazione delle repliche di disponibilità, ma possono influenzare le prestazioni complessive dei database di disponibilità, incluso l'obiettivo RPO.
Dopo essere stati acquisiti nella replica primaria, i log vengono sottoposti a due livelli di controllo di flusso. Dopo che uno dei controlli ha raggiunto la soglia dei messaggi, i messaggi di log non vengono più inviati a una replica specifica o per un database specifico. È possibile inviare i messaggi quando vengono ricevuti i messaggi di acknowledgement per i messaggi inviati in modo che il numero di messaggi inviati sia al di sotto della soglia.
Oltre ai controlli di flusso, esiste un altro fattore che può impedire l'invio di messaggi del log. La sincronizzazione di repliche assicura che i messaggi siano inviati e applicati nell'ordine dei numeri di sequenza del file di log (LSN). Prima che venga inviato un messaggio di log, il numero LSN controlla il numero LSN più basso riconosciuto per assicurarsi che sia minore di uno dei valori soglia (a seconda del tipo di messaggio). Se il divario tra i due numeri LSN è maggiore della soglia, i messaggi non vengono inviati. Se invece è al di sotto della soglia, i messaggi vengono inviati.
SQL Server 2022 aumenta i limiti del numero di messaggi consentiti da ogni gate. Usando il flag di traccia 12310, è disponibile anche il limite aumentato per le versioni seguenti di SQL Server, a partire da: SQL Server 2019 CU9, SQL Server 2017 CU18 e SQL Server 2016 SP1 CU16.
La tabella seguente confronta i limiti dei messaggi:
SQL Server 2022 e le versioni supportate di SQL Server (a partire da SQL Server 2019 CU9, SQL Server 2017 CU18 e SQL Server 2016 SP1 CU16) che abilitano il flag di traccia 12310 vedono i limiti seguenti:
| Livello | Numero di controlli | Numero di messaggi | Metrica utile |
|---|---|---|---|
| Trasporto | 1 per replica di disponibilità | 16384 | Evento esteso database_transport_flow_control_action |
| Database | 1 per database di disponibilità | 7168 | DBMIRROR_SEND Evento esteso hadron_database_flow_control_action |
Due utili contatori delle prestazioni, SQL Server:Replica di disponibilità > Controllo di flusso/sec e SQL Server:Replica di disponibilità > Ora controllo di flusso (ms/sec), indicano, all'ultimo secondo, il numero di volte in cui il controllo di flusso è stato attivato e il tempo di attesa per il controllo di flusso. Maggiore è il tempo di attesa per il controllo di flusso, maggiore sarà l'obiettivo RPO. Per altre informazioni sui tipi di problemi che possono incrementare il tempo di attesa per il controllo di flusso, vedere Risoluzione dei problemi: Il gruppo di disponibilità ha superato la soglia RPO.
Stima del tempo di failover (RTO)
L'obiettivo RTO nel contratto di servizio dipende dal tempo di failover dell'implementazione Always On in qualsiasi momento. Può essere espresso con la formula seguente:

Importante
Se un gruppo di disponibilità contiene più di un database di disponibilità, il database di disponibilità con il più alto tempo di failover (Tfailover) diventa il valore di limitazione per la conformità dell'obiettivo RTO.
Il tempo di rilevamento di errori (Tdetection) è il tempo necessario al sistema per rilevare l'errore. Questo tempo dipende dalle impostazioni a livello di cluster e non dalle singole repliche di disponibilità. A seconda della condizione di failover automatico configurata, il failover può essere attivato come risposta immediata a un errore interno critico di SQL Server, ad esempio spinlock orfani. In questo caso, il rilevamento può essere veloce quanto la segnalazione di errore sp_server_diagnostics (Transact-SQL) inviata al cluster WSFC. L'intervallo predefinito è 1/3 del timeout del controllo integrità. È possibile attivare un failover anche in seguito a un timeout, ad esempio il timeout del controllo integrità del cluster è scaduto (30 secondi per impostazione predefinita) o il lease tra la DLL risorse e l'istanza di SQL Server è scaduto (20 secondi per impostazione predefinita). In questo caso, il tempo di rilevamento è lungo quanto l'intervallo di timeout. Per altre informazioni, vedere Criteri di failover flessibili per failover automatico di un gruppo di disponibilità (SQL Server).
Per poter eseguire il failover, la replica secondaria deve solo aggiornarsi alla fine del log per il rollforward. Il tempo di rollforward (Tredo) viene calcolato usando la formula seguente:

dove redo_queue è il valore in redo_queue_size e redo_rate è il valore in redo_rate.
Il tempo di overhead del failover (Toverhead) include il tempo necessario per eseguire il failover del cluster WSFC e portare i database online. Si tratta solitamente di un tempo breve e costante.
Stima della possibile perdita dei dati (RPO)
L'obiettivo RPO nel contratto di servizio varia in base alla possibile perdita dei dati dell'implementazione Always On in un qualsiasi momento specificato. La perdita dei dati può essere espressa con la formula seguente:

dove log_send_queue è il valore di log_send_queue_size e velocità di generazione dei log è il valore di SQL Server:Database > Byte/sec scaricamento log.
Avviso
Se un gruppo di disponibilità contiene più di un database di disponibilità, il database di disponibilità con la più alta perdita dei dati (Tdata_loss) diventa il valore di limitazione per la conformità dell'obiettivo RPO.
La coda di invii del log rappresenta tutti i dati persi in seguito a un errore irreversibile. A prima vista, sembrerebbe singolare usare la velocità di generazione del log anziché la velocità di invio log (vedere log_send_rate). Tenere comunque presente che con la velocità di invio log si ottiene solo il tempo di sincronizzazione, mentre l'obiettivo RPO consente di misurare la perdita dei dati in base alla velocità di generazione e non in base alla velocità di sincronizzazione.
Usare last_commit_time per stimare in modo semplice il valore Tdata_loss. La DMV nella replica primaria segnala questo valore per tutte le repliche. È possibile calcolare la differenza tra il valore della replica primaria e il valore della replica secondaria per stimare la velocità con cui il log della replica secondaria aggiorna la replica primaria. Come indicato in precedenza, questo calcolo non specifica la possibile perdita dei dati in base alla velocità con cui il log viene generato. Deve essere inteso come valore approssimativo.
Stimare i valori RTO e RPO con il dashboard di SSMS
Nei gruppi di disponibilità Always On, i valori RTO e RPO vengono calcolati e visualizzati per i database ospitati nelle repliche secondarie. Nel dashboard della replica primaria i valori RTO e RPO sono raggruppati in base alla replica secondaria.
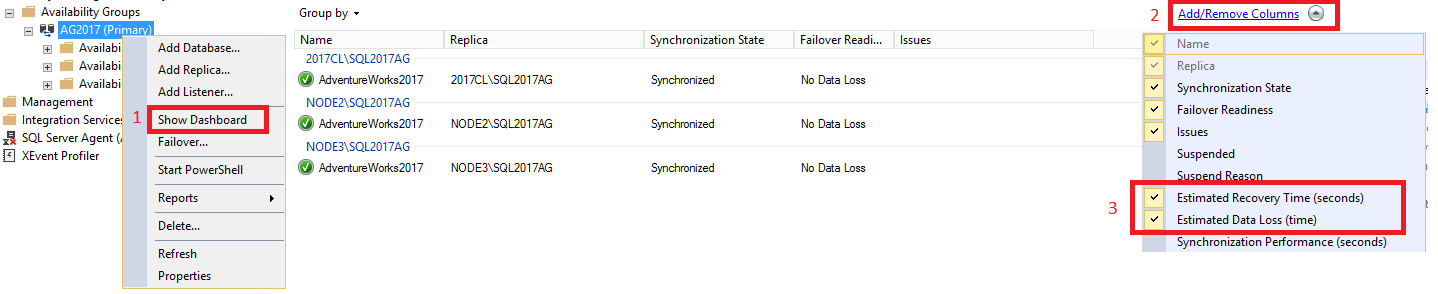
Per visualizzare i valori RTO e RPO all'interno del dashboard, eseguire le operazioni seguenti:
In SQL Server Management Studio espandere il nodo Disponibilità elevata Always On, fare clic con il pulsante destro del mouse sul nome del gruppo di disponibilità e scegliere Mostra dashboard.
Selezionare Aggiungi/Rimuovi colonne nella scheda Raggruppa per. Controllare il Tempo di recupero stimato (secondi) [RTO] e la Perdita di dati stimata (tempo) [RPO].
Calcolo del valore RTO del database secondario
Il calcolo del tempo di recupero determina il tempo necessario per recuperare il database secondario dopo che si verifica un failover. Il tempo di failover è solitamente breve e costante. Il tempo per il rilevamento dipende dalle impostazioni a livello di cluster e non dalle singole repliche di disponibilità.
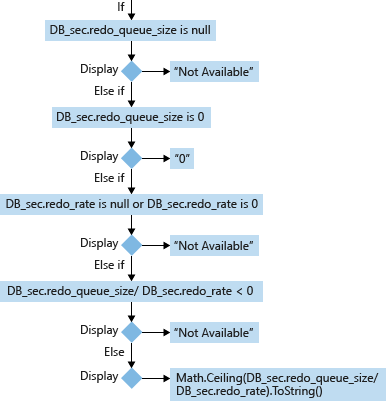
Per un database secondario (DB_sec), il calcolo e la visualizzazione del valore RTO prende in considerazione i valori di redo_queue_size e redo_rate:
Tranne nei casi limite, la formula per il calcolo del valore RTO di un database secondario è la seguente:
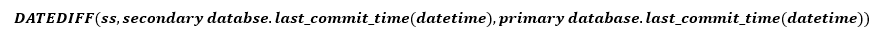
Calcolo del valore RPO del database secondario
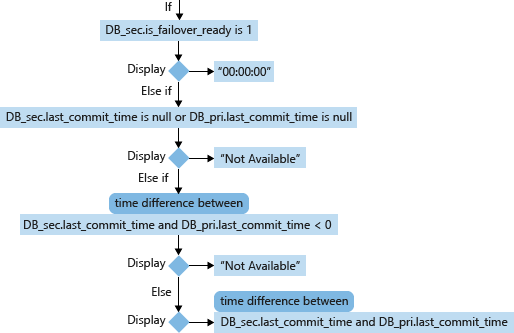
Per un database secondario (DB_sec), il calcolo e la visualizzazione del valore RPO prende in considerazione i valori di is_failover_ready, last_commit_time e last_commit_time del database primario correlato (DB_pri). Quando secondary database.is_failover_ready = 1, i dati sono sincronizzati e in caso di failover non si verificherà alcuna perdita di dati. Tuttavia, se questo valore è 0, c'è una differenza tra il valore last_commit_time del database primario e il last_commit_time del database secondario.
Per il database primario, last_commit_time corrisponde all'ora in cui è stato eseguito il commit della transazione più recente. Per il database secondario, last_commit_time corrisponde all'ora in cui è stato eseguito il commit della transazione più recente nel database primario che è stata finalizzata correttamente anche nel database secondario. Questo numero deve essere lo stesso per il database primario e secondario. Qualsiasi differenza tra questi due valori corrisponde al lasso di tempo a cui appartengono le transazioni in sospeso non ancora finalizzate nel database secondario e che andranno perse in caso di failover.
Contatori delle prestazioni utilizzati nelle formule RTO/RPO
- redo_queue_size (KB) [usato per l'RTO]: la dimensione della coda di rollforward è la dimensione dei log delle transazioni tra last_received_lsn e last_redone_lsn. last_received_lsn è l'ID del blocco di log che identifica il punto fino a cui tutti i blocchi di log sono stati ricevuti dalla replica secondaria che ospita questo database secondario. Last_redone_lsn è il numero di sequenza del file di log dell'ultimo record di log di cui è stato eseguito il rollforward nel database secondario. Sulla base di questi due valori, è possibile trovare gli ID del blocco di log iniziale (last_received_lsn) e del blocco di log finale (last_redone_lsn). Lo spazio tra questi due blocchi di log quindi può rappresentare il numero di blocchi di log delle transazioni di cui non è ancora stato eseguito il rollforward. Il valore viene misurato in kilobyte (KB).
- redo_rate (KB/sec) [usato per l'RTO]: valore cumulativo che rappresenta, dopo un dato periodo di tempo, la quantità, espressa in KB, del log della transazione che è stata sottoposta a rollforward nel database secondario in kilobyte (KB)/secondo.
- last_commit_time (Datetime) [usato per l'RPO]: per il database primario, last_commit_time corrisponde all'ora in cui è stato eseguito il commit della transazione più recente. Per il database secondario, last_commit_time corrisponde all'ora in cui è stato eseguito il commit della transazione più recente nel database primario che è stata finalizzata correttamente anche nel database secondario. Poiché questo valore del database secondario deve essere sincronizzato con lo stesso valore del database primario, eventuali differenze tra questi due valori rappresentano la stima della perdita dei dati (RPO).
Stimare i valori RTO e RPO mediante DMV
È possibile eseguire query di DM hadr_database_replica_states e DM hadr_database_replica_cluster_states nelle DMV per stimare i valori RPO e RTO di un database. Le query seguenti creano stored procedure che svolgono entrambe le operazioni.
Nota
Assicurarsi di creare ed eseguire la stored procedure per stimare prima il valore RTO, in quanto i valori generati sono necessari per eseguire la stored procedure per stimare il valore RPO.
Creare una stored procedure per stimare il valore RTO
- Nella replica secondaria di destinazione, creare la stored procedure proc_calculate_RTO. Se questa stored procedure esiste già, eliminarla e quindi ricrearla.
if object_id(N'proc_calculate_RTO', 'p') is not null
drop procedure proc_calculate_RTO
go
raiserror('creating procedure proc_calculate_RTO', 0,1) with nowait
go
--
-- name: proc_calculate_RTO
--
-- description: Calculate RTO of a secondary database.
--
-- parameters: @secondary_database_name nvarchar(max): name of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RTO
(
@secondary_database_name nvarchar(max)
)
as
begin
declare @db sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @redo_queue_size bigint
declare @redo_rate bigint
declare @replica_id uniqueidentifier
declare @group_database_id uniqueidentifier
declare @group_id uniqueidentifier
declare @RTO float
select
@is_primary_replica = dbr.is_primary_replica,
@is_failover_ready = dbcs.is_failover_ready,
@redo_queue_size = dbr.redo_queue_size,
@redo_rate = dbr.redo_rate,
@replica_id = dbr.replica_id,
@group_database_id = dbr.group_database_id,
@group_id = dbr.group_id
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbcs.database_name = @secondary_database_name
if @is_primary_replica is null or @is_failover_ready is null or @redo_queue_size is null or @replica_id is null or @group_database_id is null or @group_id is null
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else if @is_primary_replica = 1
begin
print 'You are visiting wrong replica';
return
end
if @redo_queue_size = 0
set @RTO = 0
else if @redo_rate is null or @redo_rate = 0
begin
print 'RTO of Database '+ @secondary_database_name +' is not available'
return
end
else
set @RTO = CAST(@redo_queue_size AS float) / @redo_rate
print 'RTO of Database '+ @secondary_database_name +' is ' + convert(varchar, ceiling(@RTO))
print 'group_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_id)
print 'replica_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @replica_id)
print 'group_database_id of Database '+ @secondary_database_name +' is ' + convert(nvarchar(50), @group_database_id)
end
- Eseguire proc_calculate_RTO con il nome di database secondario di destinazione:
exec proc_calculate_RTO @secondary_database_name = N'DB_sec'
L'output visualizza il valore RTO del database di replica secondaria di destinazione. Salvare i valori group_id, replica_id e group_database_id da usare con la stored procedure per la stima del valore RPO.
Output di esempio:
Il valore RTO di DB_sec del database è 0
Il valore group_id del database DB4 è F176DD65-C3EE-4240-BA23-EA615F965C9B
Il valore replica_id del database DB4 is 405554F6-3FDC-4593-A650-2067F5FABFFD
Il valore group_database_id del database DB4 is 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Creare una stored procedure per stimare il valore RPO
- Nella replica primaria, creare la stored procedure proc_calculate_RPO. Se esiste già, eliminarla e quindi ricrearla.
if object_id(N'proc_calculate_RPO', 'p') is not null
drop procedure proc_calculate_RPO
go
raiserror('creating procedure proc_calculate_RPO', 0,1) with nowait
go
--
-- name: proc_calculate_RPO
--
-- description: Calculate RPO of a secondary database.
--
-- parameters: @group_id uniqueidentifier: group_id of the secondary database.
-- @replica_id uniqueidentifier: replica_id of the secondary database.
-- @group_database_id uniqueidentifier: group_database_id of the secondary database.
--
-- security: this is a public interface object.
--
create procedure proc_calculate_RPO
(
@group_id uniqueidentifier,
@replica_id uniqueidentifier,
@group_database_id uniqueidentifier
)
as
begin
declare @db_name sysname
declare @is_primary_replica bit
declare @is_failover_ready bit
declare @is_local bit
declare @last_commit_time_sec datetime
declare @last_commit_time_pri datetime
declare @RPO nvarchar(max)
-- secondary database's last_commit_time
select
@db_name = dbcs.database_name,
@is_failover_ready = dbcs.is_failover_ready,
@last_commit_time_sec = dbr.last_commit_time
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.replica_id = @replica_id and dbr.group_database_id = @group_database_id
-- correlated primary database's last_commit_time
select
@last_commit_time_pri = dbr.last_commit_time,
@is_local = dbr.is_local
from sys.dm_hadr_database_replica_states dbr join sys.dm_hadr_database_replica_cluster_states dbcs on dbr.replica_id = dbcs.replica_id and
dbr.group_database_id = dbcs.group_database_id where dbr.group_id = @group_id and dbr.is_primary_replica = 1 and dbr.group_database_id = @group_database_id
if @is_local is null or @is_failover_ready is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
if @is_local = 0
begin
print 'You are visiting wrong replica'
return
end
if @is_failover_ready = 1
set @RPO = '00:00:00'
else if @last_commit_time_sec is null or @last_commit_time_pri is null
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
begin
if DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0
begin
print 'RPO of database '+ @db_name +' is not available'
return
end
else
set @RPO = CONVERT(varchar, DATEADD(ms, datediff(ss ,@last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114)
end
print 'RPO of database '+ @db_name +' is ' + @RPO
end
- Eseguire proc_calculate_RPO con i valori group_id, replica_id e group_database_id del database secondario di destinazione.
exec proc_calculate_RPO @group_id= 'F176DD65-C3EE-4240-BA23-EA615F965C9B',
@replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD',
@group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392'
- L'output visualizza il valore RPO del database di replica secondaria di destinazione.
Monitoraggio di RTO e RPO
In questa sezione viene illustrato come monitorare i gruppi di disponibilità per la metrica degli obiettivi RTO e RPO. Questa dimostrazione è simile all'esercitazione per la GUI descritta in The Always On health model, part 2: Extending the health model (Modello di integrità Always On, parte 2: Estensione del modello di integrità).
Gli elementi per il calcolo del tempo di failover e della possibile perdita dei dati in Stima del tempo di failover (RTO) e in Stima della potenziale perdita dei dati (RPO) vengono specificati come metrica delle prestazione nel facet della gestione basata su criteri Stato replica di database (vedere View the policy-based management facets on a SQL Server object) (Visualizzare i facet della gestione basata su criteri in un oggetto di SQL Server). È possibile monitorare queste due metriche in una pianificazione e ricevere un avviso quando la metrica supera rispettivamente gli obiettivi RTO e RPO.
Gli script della dimostrazione creano due criteri di sistema che vengono eseguiti nelle rispettive pianificazioni, con le caratteristiche seguenti:
Un criterio RTO che ha esito negativo quando il tempo di failover stimato supera i 10 minuti, valutato ogni 5 minuti
Un criterio RTO che ha esito negativo quando la perdita dei dati stimata supera 1 ora, valutato ogni 30 minuti
La configurazione dei due criteri è identica in tutte le repliche di disponibilità
I criteri vengono valutati in tutti i server, ma solo nei gruppi di disponibilità per cui la replica di disponibilità locale è la replica primaria. Se la replica di disponibilità locale non è la replica primaria, i criteri non vengono valutati.
Gli errori dei criteri vengono visualizzati nel dashboard Always On per praticità quando sono presenti nella replica primaria.
Per creare i criteri, seguire le istruzioni riportate di seguito in tutte le istanze del server che fanno parte del gruppo di disponibilità:
Avviare il servizio SQL Server Agent se non è già stato avviato.
Selezionare Opzioni dal menu Strumenti di SQL Server Management Studio.
Nella scheda SQL Server Always On selezionare Abilita criteri Always On definiti dall'utente e fare clic su OK.
Questa impostazione consente di visualizzare i criteri personalizzati configurati correttamente nel dashboard Always On.
Creare una condizione della gestione basata su criteri usando le specifiche seguenti:
Nome:
RTOFacet: Stato replica di database
Campo:
Add(@EstimatedRecoveryTime, 60)Operatore: <=
Valore:
600
Questa condizione ha esito negativo quando il tempo di failover potenziale supera i 10 minuti, incluso l'overhead di 60 secondi per il rilevamento degli errori e il failover.
Creare una seconda condizione della gestione basata su criteri usando le specifiche seguenti:
Nome:
RPOFacet: Stato replica di database
Campo:
@EstimatedDataLossOperatore: <=
Valore:
3600
Questa condizione ha esito negativo quando la possibile perdita dei dati supera 1 ora.
Creare una terza condizione della gestione basata su criteri usando le specifiche seguenti:
Nome:
IsPrimaryReplicaFacet: Gruppo di disponibilità
Campo:
@LocalReplicaRoleOperatore: =
Valore:
Primary
Questa condizione controlla se la replica di disponibilità locale per un determinato gruppo di disponibilità è la replica primaria.
Creare un criterio della gestione basata su criteri usando le specifiche seguenti:
PaginaGenerale:
Nome:
CustomSecondaryDatabaseRTOCondizioni di controllo:
RTOIn base alle destinazioni: Ogni DatabaseReplicaState in IsPrimaryReplica AvailabilityGroup
Questa impostazione controlla che i criteri vengano valutati solo nei gruppi di disponibilità per cui la replica di disponibilità locale è la replica primaria.
Modalità di valutazione: Su pianificazione
Pianificazione: CollectorSchedule_Every_5min
Abilitata: selezionato
Pagina Descrizione:
Categoria: avvisi del database di disponibilità
Questa impostazione abilita i risultati della valutazione dei criteri che devono essere visualizzati nel dashboard Always On.
Descrizione: la replica corrente è un obiettivo RTO che non supera i 10 minuti, presupponendo un overhead di 1 minuto per l'individuazione e il failover. È necessario analizzare immediatamente sui problemi di prestazioni dell’istanza sul rispettivo server.
Testo da visualizzare: RTO superato!
Creare un secondo criterio della gestione basata su criteri usando le specifiche seguenti:
PaginaGenerale:
Nome:
CustomAvailabilityDatabaseRPOCondizioni di controllo:
RPOIn base alle destinazioni: Ogni DatabaseReplicaState in IsPrimaryReplica AvailabilityGroup
Modalità di valutazione: Su pianificazione
Pianificazione: CollectorSchedule_Every_30min
Abilitata: selezionato
Pagina Descrizione:
Categoria: avvisi del database di disponibilità
Descrizione: il database di disponibilità ha superato il valore RPO di 1 ora. È consigliabile analizzare immediatamente i problemi di prestazioni nelle repliche di disponibilità.
Testo da visualizzare: RPO superato!
Al termine, vengono creati due nuovi processi di SQL Server Agent, uno per ogni pianificazione di valutazione dei criteri. I nomi di questi processi devono iniziare con syspolicy_check_schedule.
È possibile visualizzare la cronologia processo per controllare i risultati della valutazione. Anche gli errori di valutazione vengono registrati nel registro applicazioni di Windows (nel Visualizzatore eventi) con l'ID evento 34052. È anche possibile configurare SQL Server Agent per l'invio di avvisi in caso di errori dei criteri. Per altre informazioni, vedere Configure alerts to notify policy administrators of policy failures (Configurare avvisi per notificare agli amministratori eventuali errori dei criteri).
Scenari di risoluzione dei problemi relativi alle prestazioni
Nella tabella seguente sono elencati gli scenari comuni di risoluzione dei problemi relativi alle prestazioni.
| Scenario | Descrizione |
|---|---|
| Risoluzione dei problemi: Il gruppo di disponibilità ha superato la soglia RTO | Dopo un failover automatico o un failover manuale pianificato senza perdita di dati, il tempo di failover supera l'obiettivo RTO. Oppure, quando si stima il tempo di failover di una replica secondaria con commit asincrono (ad esempio un partner di failover automatico), si scopre che supera l'obiettivo RTO. |
| Risoluzione dei problemi: Il gruppo di disponibilità ha superato la soglia RPO | Dopo aver eseguito un failover manuale forzato, la perdita di dati è maggiore dell'obiettivo RPO. In alternativa, quando si calcola la potenziale perdita di dati di una replica secondaria con commit asincrono, si scopre che supera l'obiettivo RPO. |
| Risoluzione dei problemi: Le modifiche nella replica primaria non vengono riflesse nella replica secondaria | L'applicazione client completa con esito positivo un aggiornamento per la replica primaria, ma l'esecuzione di query sulla replica secondaria rivela che qui la modifica non è stata eseguita. |
Eventi estesi utili
Gli eventi estesi seguenti sono utili quando vengono risolti i problemi delle repliche che hanno lo stato Sincronizzazione in corso.
| Nome evento | Categoria | Canale | replica di disponibilità |
|---|---|---|---|
| redo_caught_up | transazioni | Debug | Secondario |
| redo_worker_entry | transazioni | Debug | Secondario |
| hadr_transport_dump_message | alwayson |
Debug | Primario |
| hadr_worker_pool_task | alwayson |
Debug | Primario |
| hadr_dump_primary_progress | alwayson |
Debug | Primario |
| hadr_dump_log_progress | alwayson |
Debug | Primario |
| hadr_undo_of_redo_log_scan | alwayson |
Analitiche | Secondario |
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per