Configurare un cluster dell'istanza del cluster di failover RHEL per SQL Server
Si applica a: ![]() SQL Server - Linux
SQL Server - Linux
Questa guida contiene istruzioni per la creazione di un cluster di failover di dischi condivisi a due nodi per SQL Server in Red Hat Enterprise Linux. Il livello di clustering si basa sul componente aggiuntivo a disponibilità elevata di Red Hat Enterprise Linux (RHEL), basato a sua volta su Pacemaker. L'istanza di SQL Server è attiva in un nodo o nell'altro.
Nota
Per accedere al componente aggiuntivo a disponibilità elevata e alla documentazione di Red Hat, è richiesta una sottoscrizione.
Come illustrato nel diagramma seguente, la risorsa di archiviazione viene presentata a due server. I componenti di clustering, Corosync e Pacemaker, coordinano le comunicazioni e la gestione delle risorse. Uno dei server ha la connessione attiva alle risorse di archiviazione e a SQL Server. Quando Pacemaker rileva un errore, i componenti di clustering sono responsabili del trasferimento delle risorse nell'altro nodo.
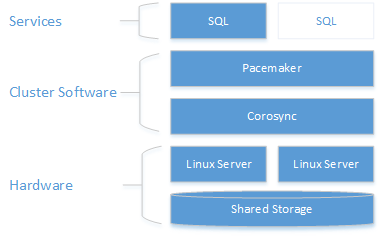
Per altre informazioni sulla configurazione del cluster, sulle opzioni degli agenti delle risorse e sulla gestione, vedere la documentazione di riferimento di RHEL.
Nota
A questo punto, l'integrazione di SQL Server con Pacemaker non è associata come con il cluster WSFC in Windows. SQL Server non è a conoscenza della presenza del cluster. Tutta l'orchestrazione viene eseguita all'esterno e il servizio viene controllato come istanza autonoma da Pacemaker. Inoltre, ad esempio, sys.dm_os_cluster_nodes dmvs del cluster e sys.dm_os_cluster_properties non eseguiranno alcun record.
Per usare una stringa di connessione che punta a un nome del server in formato stringa e non usare l'indirizzo IP, dovranno registrare nel server DNS l'IP usato per creare la risorsa IP virtuale (come illustrato nelle sezioni seguenti) con il nome del server scelto.
Le sezioni seguenti illustrano i passaggi per configurare una soluzione cluster di failover.
Prerequisiti
Per completare lo scenario end-to-end seguente, sono necessari due computer per distribuire il cluster a due nodi e un altro server per configurare il server NFS. I passaggi seguenti illustrano come saranno configurati questi server.
Installare e configurare il sistema operativo in ogni nodo del cluster
Il primo passaggio consiste nel configurare il sistema operativo nei nodi del cluster. Per questa procedura dettagliata, usare RHEL con una sottoscrizione valida per il componente aggiuntivo a disponibilità elevata.
Installare e configurare SQL Server in ogni nodo del cluster
Installare e configurare SQL Server in entrambi i nodi. Per istruzioni dettagliate, vedere Installare SQL Server in Linux.
Designare un nodo come primario e l'altro come secondario, ai fini della configurazione. Usare questi termini per la parte seguente di questa guida.
Nel nodo secondario arrestare e disabilitare SQL Server.
L'esempio seguente arresta e disabilita SQL Server:
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Nota
In fase di configurazione, viene generata una chiave master del server per l'istanza di SQL Server e viene inserita in /var/opt/mssql/secrets/machine-key. In Linux, SQL Server viene sempre eseguito come account locale denominato mssql. Poiché si tratta di un account locale, l'identità non è condivisa tra i nodi. È quindi necessario copiare la chiave di crittografia dal nodo primario a ogni nodo secondario, in modo che ogni account mssql locale possa accedervi per decrittografare la chiave master del server.
Nel nodo primario creare un account di accesso di SQL Server per Pacemaker e concedere l'autorizzazione di accesso per eseguire
sp_server_diagnostics. Pacemaker usa questo account per verificare quale nodo sta eseguendo SQL Server.sudo systemctl start mssql-serverConnettersi al database
masterdi SQL Server con l'account sa ed eseguire i comandi seguenti:USE [master] GO CREATE LOGIN [<loginName>] with PASSWORD= N'<loginPassword>' ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>]In alternativa, è possibile impostare le autorizzazioni a un livello più granulare. L'account di accesso di Pacemaker richiede
VIEW SERVER STATEper effettuare una query sullo stato di integrità consp_server_diagnostics,setupadmineALTER ANY LINKED SERVERper aggiornare il nome dell'istanza del cluster di failover con il nome della risorsa eseguendosp_dropserveresp_addserver.Nel nodo primario arrestare e disabilitare SQL Server.
Configurare il file hosts per ogni nodo del cluster. Il file hosts deve includere l'indirizzo IP e il nome di ogni nodo del cluster.
Controllare l'indirizzo IP per ogni nodo. Lo script seguente mostra l'indirizzo IP del nodo corrente.
sudo ip addr showImpostare il nome computer in ogni nodo. Assegnare a ogni nodo un nome univoco di 15 caratteri o meno. Per impostare il nome computer, aggiungerlo a
/etc/hosts. Lo script seguente consente di modificare/etc/hostsconvi.sudo vi /etc/hostsL'esempio seguente mostra
/etc/hostscon l'aggiunta di due nodi denominatisqlfcivm1esqlfcivm2.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
Nella sezione successiva si configurerà la risorsa di archiviazione condivisa, in cui verranno spostati i file di database.
Configurare la risorsa di archiviazione condivisa e spostare i file di database
Sono disponibili varie soluzioni per fornire spazio di archiviazione condiviso. Questa procedura dettagliata illustra la configurazione dello spazio di archiviazione condiviso con NFS. È opportuno seguire le procedure consigliate e usare Kerberos per proteggere NFS. Per un esempio, vedere https://www.certdepot.net/rhel7-use-kerberos-control-access-nfs-network-shares/.
Avviso
Se non si protegge NFS, chiunque possa accedere alla rete ed effettuare lo spoofing dell'indirizzo IP di un nodo SQL, riuscirà ad accedere ai file di dati. Come sempre, assicurarsi di creare un modello di rischio per il sistema prima di usarlo nell'ambiente di produzione. Un'altra opzione di archiviazione consiste nell'usare la condivisione file SMB.
Configurare la risorsa di archiviazione condivisa con NFS
Importante
L'hosting dei file di database in un server NFS con versione precedente alla <4 non è supportato in questa versione. Questo include l'uso di NFS per il clustering di failover su disco condiviso, nonché per i database in istanze non cluster. Le altre versioni del server NFS saranno abilitate nelle prossime versioni.
Eseguire i passaggi seguenti sul server NFS.
Installare
nfs-utilssudo yum -y install nfs-utilsAbilitare e avviare
rpcbindsudo systemctl enable rpcbind && sudo systemctl start rpcbindAbilitare e avviare
nfs-serversudo systemctl enable nfs-server && sudo systemctl start nfs-serverModificare
/etc/exportsper esportare la directory che si vuole condividere. Per ogni condivisione desiderata è necessaria una riga. Ad esempio:/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)Esportare le condivisioni
sudo exportfs -ravVerificare che i percorsi siano condivisi/esportati ed eseguiti dal server NFS
sudo showmount -eAggiungere l'eccezione in SELinux
sudo setsebool -P nfs_export_all_rw 1Aprire il firewall del server.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
Configurare tutti i nodi del cluster per la connessione alla risorsa di archiviazione condivisa NFS
Eseguire questa procedura in tutti i nodi del cluster.
Installare
nfs-utilssudo yum -y install nfs-utilsAprire il firewall nei client e nel server NFS
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadVerificare che sia possibile visualizzare le condivisioni NFS nei computer client
sudo showmount -e <IP OF NFS SERVER>Ripetere questi passaggi in tutti i nodi del cluster.
Per altre informazioni sull'uso di NFS, vedere le risorse seguenti:
- NFS servers and firewalld | Stack Exchange (Firewall e server NFS | Stack Exchange)
- Mounting an NFS Volume | Linux Network Administrators Guide (Montaggio di un volume NFS | Guida per gli amministratori di rete Linux)
- NFS server configuration | Red Hat Customer Portal (Configurazione del server NFS | Red Hat Customer Portal)
Montare la directory dei file di database in modo che punti alla risorsa di archiviazione condivisa
Solo nel nodo primario salvare i file di database in una posizione temporanea. Lo script seguente crea una nuova directory temporanea, copia i file di database nella nuova directory e rimuove i file di database obsoleti. Poiché SQL Server viene eseguito come utente locale
mssql, è necessario assicurarsi che dopo il trasferimento dei dati alla condivisione montata, l'utente locale abbia accesso in lettura/scrittura alla condivisione.sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitIn tutti i nodi del cluster modificare il file
/etc/fstabin modo che includa il comando di montaggio.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrNello script seguente viene illustrato un esempio della modifica.
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Nota
Se si usa una risorsa file system (FS) come consigliato, non è necessario mantenere il comando di montaggio in/etc/fstab. Pacemaker eseguirà il montaggio della cartella quando avvierà la risorsa cluster FS. Grazie all'isolamento, il file system non verrà mai montato due volte.
Eseguire il comando
mount -aper fare in modo che il sistema aggiorni i percorsi montati.Copiare i file di log e di database salvati in
/var/opt/mssql/tmpnella nuova condivisione montata/var/opt/mssql/data. È necessario eseguire questo passaggio solo nel nodo primario. Assicurarsi di concedere le autorizzazioni di lettura e scrittura all'utente localemssql.sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitVerificare che SQL Server venga avviato correttamente con il nuovo percorso del file. Eseguire questa operazione in ogni nodo. A questo punto, un solo nodo alla volta eseguirà SQL Server. Non possono essere eseguiti contemporaneamente perché entrambi proveranno ad accedere ai file di dati simultaneamente. Per evitare l'avvio accidentale di SQL Server in entrambi i nodi, usare una risorsa cluster del file system per assicurarsi che la condivisione non venga montata due volte da nodi diversi. I comandi seguenti avviano SQL Server, controllano lo stato e quindi arrestano SQL Server.
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
A questo punto, entrambe le istanze di SQL Server sono configurate per l'esecuzione con i file di database nello spazio di archiviazione condiviso. Il passaggio successivo consiste nel configurare SQL Server per Pacemaker.
Installare e configurare Pacemaker in ogni nodo del cluster
In entrambi i nodi del cluster creare un file per archiviare nome utente e password di SQL Server per l'accesso a Pacemaker. Il comando seguente crea e popola questo file:
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<loginPassword>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwdIn entrambi i nodi del cluster aprire le porte del firewall di Pacemaker. Per aprire queste porte con
firewalld, eseguire il comando seguente:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSe si sta usando un altro firewall che non ha una configurazione a disponibilità elevata predefinita, è necessario aprire le porte seguenti per consentire a Pacemaker di comunicare con altri nodi del cluster
- TCP: porte 2224, 3121, 21064
- UDP: porta 5405
Installare i pacchetti Pacemaker in ogni nodo.
sudo yum install pacemaker pcs fence-agents-all resource-agentsImpostare la password per l'utente predefinito creato durante l'installazione dei pacchetti Pacemaker e Corosync. Usare la stessa password in entrambi i nodi.
sudo passwd haclusterAbilitare e avviare il servizio
pcsde Pacemaker. In questo modo, i nodi potranno unirsi nuovamente in join con il cluster dopo il riavvio. Eseguire il comando seguente in entrambi i nodi.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstallare l'agente delle risorse FCI per SQL Server. Eseguire i comandi seguenti in entrambi i nodi.
sudo yum install mssql-server-ha
Configurare l'agente di isolamento
Un dispositivo STONITH fornisce un agente di isolamento. La configurazione di Pacemaker in Red Hat Enterprise Linux in Azure offre un esempio di come creare un dispositivo STONITH per questo cluster in Azure. Modificare le istruzioni per l'ambiente.
Creare il cluster
In uno dei nodi creare il cluster.
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allConfigurare le risorse del cluster per SQL Server, il file system e le risorse IP virtuale ed effettuare il push della configurazione nel cluster. Sono necessarie le informazioni seguenti:
- Nome risorsa SQL Server: nome della risorsa SQL Server cluster.
- Nome risorsa IP mobile: nome della risorsa indirizzo IP virtuale.
- Indirizzo IP: indirizzo IP che i client usano per connettersi all'istanza in cluster di SQL Server.
- Nome risorsa file system: nome della risorsa file system.
- dispositivo: percorso condivisione NFS
- dispositivo: percorso locale montato nella condivisione
- fstype: tipo di condivisione file (ad esempio,
nfs)
Aggiornare i valori dello script seguente per il proprio ambiente. Eseguire su un nodo per configurare e avviare il servizio in cluster.
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgLo script seguente, ad esempio, crea una risorsa in cluster di SQL Server denominata
mssqlhae una risorsa a indirizzo IP mobile con l'indirizzo IP10.0.0.99. Crea anche una risorsa Filesystem e aggiunge vincoli in modo che tutte le risorse si trovino nello stesso nodo della risorsa SQL.sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfgDopo il push della configurazione, SQL Server verrà avviato in un nodo.
Verificare che SQL Server sia avviato.
sudo pcs statusL’esempio seguente illustra i risultati quando Pacemaker ha avviato correttamente un 'istanza in cluster di SQL Server.
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled