Filegroup e file di database
Si applica a: ![]() SQL Server
SQL Server ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Ogni database di SQL Server contiene almeno due file del sistema operativo: un file di dati e un file di resoconto. I file di dati contengono dati e oggetti come tabelle, indici, stored procedure e viste. I file di log contengono le informazioni necessarie per il recupero di tutte le transazioni del database. I file di dati possono essere raggruppati in filegroup ai fini dell'allocazione e dell'amministrazione.
File di database
I database di SQL Server contengono tre tipi di file, come illustrato nella tabella seguente.
| File | Descrizione |
|---|---|
| Primari | Contiene le informazioni di avvio del database e punta agli altri file del database. In ogni database è disponibile un unico file di dati primario. L'estensione consigliata per i file di dati primari è .mdf. |
| Secondari | File di dati facoltativi definiti dall'utente. I dati possono essere distribuiti in più dischi, inserendo ogni file in un'unità disco distinta. L'estensione consigliata per i file di dati secondari è .ndf. |
| Log delle transazioni | Il log contiene le informazioni usate per recuperare il database. È necessario che sia disponibile almeno un file di log per ogni database. L'estensione consigliata per i file di log delle transazioni è .ldf. |
Ad esempio, un database semplice, denominato Sales, ha un file primario che include tutti i dati e gli oggetti e un file di log che contiene le informazioni del log delle transazioni. Si può creare un database più complesso, denominato Orders, con un file primario e cinque file secondari. I dati e gli oggetti all'interno del database vengono suddivisi nei sei file e i quattro file di log includono le informazioni del log delle transazioni.
Per impostazione predefinita, i dati e i log delle transazioni vengono archiviati nella stessa unità e nello stesso percorso per gestire i sistemi a disco singolo. Questa scelta può non essere la soluzione ottimale per gli ambienti di produzione. È consigliabile archiviare i dati e i file di log in dischi separati.
Nomi di file logici e fisici
I file SQL Server hanno due tipi di nome file:
logical_file_name:Illogical_file_nameè il nome del file fisico in tutte le istruzioni Transact-SQL. Il nome di file logico deve essere conforme alle regole per gli identificatori di SQL Server e deve essere univoco tra i nomi di file logici nel database.os_file_name:Ilos_file_nameè il nome del file fisico che include il percorso di directory. Tale nome deve essere conforme alle regole relative ai nomi di file del sistema operativo.
Per altre informazioni sull'argomento NAME e FILENAME, vedere Opzioni per file e filegroup ALTER DATABASE (Transact-SQL).
Suggerimento
I dati e i file di log di SQL Server possono essere memorizzati sia in file system FAT che NTFS. Nei sistemi Windows, Microsoft consiglia di utilizzare il file system NTFS per i vantaggi di sicurezza intrinseci di NTFS.
Avviso
I file di log e i filegroup di dati di lettura/scrittura non sono supportati in un file system compresso NTFS. Solo i database e i filegroup secondari di sola lettura possono essere memorizzati in un file system compresso NTFS. Per un risparmio di spazio, è consigliabile utilizzare la compressione dei dati anziché la compressione del file system.
Se nello stesso computer sono in esecuzione più istanze di SQL Server, a ogni istanza viene assegnata una directory predefinita diversa in cui verranno archiviati i file dei database creati nell'istanza. Per altre informazioni, vedere Percorsi dei file per le istanze predefinite e denominate di SQL Server.
Pagine di file di dati
Le pagine dei file di dati di SQL Server sono numerate modo sequenziale a partire dalla prima, che corrisponde al numero zero (0). A ogni file di un database è associato un numero di ID file univoco. Per identificare in modo univoco una pagina in un database, sono necessari sia ID file che numero di pagina. Nell'esempio seguente vengono illustrati i numeri di pagina di un database che include un file di dati primario di 4 MB e un file di dati secondario di 1 MB.
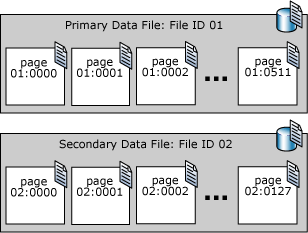
Una pagina di intestazione del file è la prima pagina che contiene informazioni sugli attributi del file. Anche molte altre pagine all'inizio del file contengono informazioni di sistema, ad esempio mappe delle allocazioni. Una delle pagine di sistema archiviate sia nel file di dati primario che nel primo file di log è una pagina di avvio del database contenente informazioni sugli attributi del database.
Dimensione file
Le dimensioni dei file di SQL Server possono aumentare automaticamente rispetto ai valori originari. Quando si definisce un file, è possibile specificare un incremento di crescita specifico. Quando lo spazio assegnato al file si esaurisce, le sue dimensioni aumentano in base all'incremento specificato. Se un filegroup include più file, le loro dimensioni non aumentano automaticamente finché lo spazio di tutti i file non si esaurisce.
Per altre informazioni su pagine e tipi di pagina, vedere Guida all'architettura di pagine ed extent.
È inoltre possibile specificare le dimensioni massime di ogni file. Se non vengono specificate le dimensioni massime, il file può continuare ad aumentare fino a occupare tutto lo spazio disponibile nel disco. Questa caratteristica è particolarmente utile quando SQL Server viene usato come database incorporato in un'applicazione per cui l'utente non può rivolgersi direttamente all'amministratore di sistema. L'utente può lasciare aumentare i file in base alle necessità per alleggerire il carico amministrativo derivante dal monitoraggio dello spazio libero nel database e dall'allocazione manuale di spazio aggiuntivo.
Per altre informazioni sulla gestione del file di log delle transazioni, vedere Gestione delle dimensioni del file di log delle transazioni.
File di snapshot di database
La forma del file utilizzato da uno snapshot del database per archiviare i propri dati copy-on-write cambia a seconda che lo snapshot venga creato da un utente o utilizzato internamente:
- Quando lo snapshot del database viene creato da un utente, i dati vengono archiviati in uno o più file sparse. La tecnologia file sparse è una caratteristica del file system NTFS. Inizialmente un file sparse non contiene alcun dato utente e lo spazio su disco per i dati utente non viene allocato per tale file. Per informazioni generali sull'uso di file sparse negli snapshot del database e sul modo in cui aumentano le dimensioni degli snapshot del database, vedere Visualizzare le dimensioni del file sparse di uno snapshot del database.
- Gli snapshot del database vengono utilizzati internamente da alcuni comandi DBCC, Questi comandi includono
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOCeDBCC CHECKFILEGROUP. Uno snapshot interno del database utilizza flussi di dati alternativi sparse dei file originali del database. Come i file sparse, anche i flussi di dati alternativi rappresentano una caratteristica del file system NTFS. L'utilizzo dei flussi di dati alternativi sparse consente l'associazione di più allocazioni di dati a un solo file o a una sola cartella senza incidere sulla dimensione del file o sulle statistiche del volume.
Filegroup
- Il filegroup primario contiene il file di dati primario e gli eventuali file secondari non inclusi in altri filegroup.
- È possibile creare filegroup definiti dall'utente per raggruppare i file di dati a fini amministrativi e di allocazione e posizione dei dati.
Ad esempio, è possibile creare Data1.ndf, Data2.ndf e Data3.ndf rispettivamente su tre unità disco e assegnarli al filegroup fgroup1. È quindi possibile creare una tabella specifica nel filegroup fgroup1. Le query sui dati della tabella verranno suddivise sui tre dischi con il conseguente miglioramento delle prestazioni. È possibile ottenere lo stesso risultato in termini di prestazioni utilizzando un singolo file creato su un set di striping RAID. File e filegroup, tuttavia, consentono di aggiungere nuovi file su nuovi dischi in modo semplice.
Tutti i file di dati vengono archiviati nei filegroup elencati nella tabella seguente.
| Filegroup | Descrizione |
|---|---|
| Primari | Il filegroup che contiene il file primario. Tutte le tabelle di sistema fanno parte del filegroup primario. |
| Dati ottimizzati per la memoria | Un filegroup ottimizzato per la memoria è basato sul filegroup FileStream |
| FileStream | |
| personalizzato | Qualsiasi filegroup creato dall'utente in fase di creazione o di successiva modifica del database. |
Filegroup predefinito (primario)
Gli oggetti di database creati senza specificare un filegroup di appartenenza vengono assegnati al filegroup predefinito. Viene designato sempre e solo un filegroup predefinito. I file nel filegroup predefinito devono essere di dimensioni sufficienti a contenere tutti i nuovi oggetti non allocati ad altri filegroup.
A meno che non venga modificato tramite l'istruzione ALTER DATABASE, PRIMARY è il filegroup predefinito. Gli oggetti e le tabelle di sistema, tuttavia, restano allocati all'interno del filegroup PRIMARY e non all'interno del nuovo filegroup predefinito.
Filegroup di dati ottimizzati per la memoria
Per altre informazioni sui filegroup ottimizzati per la memoria, vedere Filegroup ottimizzato per la memoria.
Filegroup FILESTREAM
Per altre informazioni sui filegroup FILESTREAM, vedere FILESTREAM e Creare un database abilitato per FILESTREAM.
Esempio di file e filegroup
Nell'esempio seguente viene illustrata la creazione di un database in un'istanza di SQL Server. Nel database sono presenti un file di dati primario, un filegroup definito dall'utente e un file di log. Il file di dati primario è incluso nel filegroup primario e il filegroup definito dall'utente include due file di dati secondari. Tramite l'istruzione ALTER DATABASE viene impostato come predefinito il filegroup definito dall'utente. e quindi viene creata una tabella che specifica tale filegroup. Questo esempio usa un percorso generico c:\Program Files\Microsoft SQL Server\MSSQL.1 per evitare di specificare una versione di SQL Server.
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
La figura seguente riepiloga i risultati dell'esempio precedente (esclusi i dati FileStream).

Strategia di riempimento dei file e dei filegroup
I filegroup utilizzano una strategia di riempimento proporzionale per tutti i file presenti in ogni filegroup. Quando i dati vengono scritti nel filegroup, il motore di database SQL Server scrive una quantità di dati proporzionale allo spazio disponibile in ogni file del filegroup anziché scrivere tutti i dati nel primo file fino all'esaurimento dello spazio e quindi passa al file successivo. Ad esempio, se nel file f1 sono disponibili 100 MB e nel file f2 sono disponibili 200 MB, un extent verrà assegnato dal file f1, due extent dal file f2 e così via. In questo modo, entrambi i file vengono riempiti quasi simultaneamente e si ottiene uno striping semplice.
Si supponga, ad esempio, che un filegroup includa tre file per i quali è stato impostato l'aumento di dimensioni automatico. Quando lo spazio viene esaurito in tutti i file del filegroup, viene espanso solo il primo file. Quando il primo file è pieno e non è possibile scrivere altri dati nel filegroup, viene espanso il secondo file. Quando il secondo file è pieno e non è possibile scrivere altri dati nel filegroup, viene espanso il terzo file. Quando il terzo file è pieno e non è possibile scrivere altri dati nel filegroup, viene espanso nuovamente il primo file e così via.
Regole per la progettazione di file e filegroup
Per i file e i filegroup sono valide le regole seguenti:
- Un file o un filegroup non può essere utilizzato da più database. Ad esempio, i file
sales.mdfesales.ndf, che includono dati e oggetti del database sales, non possono essere usati da altri database. - Un file può essere membro di un solo filegroup.
- I file di log delle transazioni non fanno mai parte di un filegroup.
Consigli
Suggerimenti per l'utilizzo di file e filegroup:
- La maggior parte dei database funziona in modo ottimale con un singolo file di dati e un unico file di log delle transazioni.
- Se si utilizzano più file di dati, creare un secondo filegroup per i file aggiuntivi e impostarlo come filegroup predefinito. In questo modo, il file primario conterrà unicamente le tabelle e gli oggetti di sistema.
- Per ottimizzare le prestazioni, creare i file o i filegroup sul numero maggiore possibile di dischi disponibili. Posizionare in filegroup diversi gli oggetti che creano conflitti di spazio.
- Utilizzare i filegroup per la posizione di oggetti su dischi fisici specifici.
- Posizionare in filegroup diversi le diverse tabelle utilizzate nelle stesse query di join. Questo passaggio consente di ottimizzare le prestazioni, grazie al fatto che i dati uniti in join vengono cercati con operazioni di I/O su disco in parallelo.
- Posizionare in filegroup diversi le tabelle utilizzate molto frequentemente e gli indici non cluster che appartengono a queste tabelle. L'uso di filegroup diversi consente di ottimizzare le prestazioni, grazie al fatto che vengono eseguite operazioni di I/O in parallelo se i file si trovano su dischi fisici diversi.
- Non posizionare il file o i file di log delle transazioni sullo stesso disco fisico in cui si trovano gli altri file o filegroup.
- Se è necessario estendere un volume o una partizione in cui risiedono i file di database usando strumenti come Diskpart, è necessario eseguire il backup di tutti i database di sistema e utente e arrestare prima i servizi SQL Server. Inoltre, dopo aver esteso correttamente i volumi del disco, è consigliabile eseguire il comando
DBCC CHECKDBper garantire l'integrità fisica di tutti i database che risiedono nel volume.
Per altre informazioni sulle raccomandazioni relative alla gestione del file di log delle transazioni, vedere Gestione delle dimensioni del file di log delle transazioni.
Contenuto correlato
- CREATE DATABASE (SQL Server Transact-SQL)
- Opzioni per file e filegroup ALTER DATABASE (Transact-SQL)
- Collegamento e scollegamento di un database (SQL Server)
- Architettura e gestione del log delle transazioni di SQL Server
- Guida sull'architettura di pagina ed extent
- Gestione delle dimensioni del file di log delle transazioni