Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server![]() Database SQL di
Database SQL di![]() AzureIstanza gestita di SQL di
AzureIstanza gestita di SQL di![]() AzureDatabase SQL in Microsoft Fabric
AzureDatabase SQL in Microsoft Fabric
Pianificazione delle attività del sistema operativo
I thread sono le unità di elaborazione più piccole che sono eseguite da un sistema operativo e consentono la separazione della logica dell'applicazione in diversi percorsi di esecuzione simultanei. I thread sono utili quando in applicazioni complesse è necessario eseguire numerose attività simultaneamente.
Quando esegue un'istanza di un'applicazione, il sistema operativo crea un'unità denominata processo per gestire l'istanza. Il processo dispone di un thread di esecuzione. Si tratta di una serie di istruzioni di programmazione eseguite dal codice dell'applicazione. In un'applicazione semplice con un singolo set di istruzioni che è possibile eseguire in serie, ad esempio, tale set di istruzioni viene gestito come unica attività ed è disponibile solo un percorso di esecuzione, o thread, per tutta l'applicazione. Nelle applicazioni più complesse è possibile eseguire più attività simultaneamente anziché in serie. Un'applicazione può eseguire questa operazione avviando processi separati per ogni attività, operazione che richiede un uso intensivo delle risorse, o avviare thread distinti, caratterizzati da un uso relativamente minore delle risorse. Ogni thread, inoltre, può essere pianificato per l'esecuzione indipendentemente dagli altri thread associati al processo.
I thread consentono alle applicazioni complesse di ottimizzare l'utilizzo di un processore (CPU) anche nel caso di computer con una singola CPU Con una CPU, è possibile eseguire un solo thread alla volta. Se un thread esegue un'operazione che richiede tempi prolungati e non utilizza la CPU, ad esempio un'operazione di lettura o scrittura su disco, può essere eseguito un altro thread fino al completamento della prima operazione. La possibilità di eseguire thread mentre altri thread sono in attesa del completamento di un'operazione consente all'applicazione di ottimizzare l'utilizzo della CPU. Questo vale in particolare per le applicazioni multiutente che eseguono una grande quantità di I/O su disco, ad esempio i server di database. I computer con più CPU possono eseguire contemporaneamente un thread per ogni CPU. Se un computer dispone di otto CPU, ad esempio, può eseguire otto thread simultaneamente.
Pianificazione delle attività di SQL Server
Nell'ambito di SQL Server, una richiesta è la rappresentazione logica di una query o un batch. Una richiesta rappresenta anche le operazioni richieste dai thread di sistema, come ad esempio il checkpoint o lo scrittore di log. Le richieste esistono in vari stati durante il loro ciclo di vita e possono subire ritardi quando le risorse necessarie per eseguire la richiesta non sono disponibili, ad esempio blocchi o latch. Per altre informazioni sugli stati delle richieste, vedere sys.dm_exec_requests.
Attività
Un'attività rappresenta l'unità di lavoro che deve essere completata per soddisfare la richiesta. È possibile assegnare una o più attività a una singola richiesta.
- Le richieste parallele hanno diverse attività attive che vengono eseguite simultaneamente anziché in sequenza, con una attività padre (o attività di coordinamento) e più attività figlio. Un piano di esecuzione per una richiesta parallela può includere rami seriali, ovvero aree del piano con operatori che non vengono eseguiti in parallelo. L'attività padre è anche responsabile dell'esecuzione degli operatori seriali.
- Le richieste in serie hanno una sola attività attiva in un determinato momento durante l'esecuzione. Le attività esistono in vari stati per tutta la loro durata. Per altre informazioni sugli stati delle attività, vedere sys.dm_os_tasks. Le attività in stato SOSPESO sono in attesa delle risorse necessarie per eseguire l'attività e diventare disponibili. Per altre informazioni sulle attività in attesa, vedere sys.dm_os_waiting_tasks.
Lavoratori
Un thread di lavoro di SQL Server, noto anche come ruolo di lavoro o thread, è una rappresentazione logica di un thread del sistema operativo. Quando si eseguono richieste seriali, il Motore di database di SQL Server genera un ruolo di lavoro per eseguire l'attività attiva (1:1). Se si eseguono richieste parallele in modalità riga, il Motore di database di SQL Server assegna un ruolo di lavoro chiamato thread padre (o thread di coordinamento) che coordini i ruoli di lavoro figlio responsabili del completamento delle attività ad essi assegnate (1:1). Al thread padre è associato un compito padre. Il thread padre è il punto di ingresso della richiesta ed esiste anche prima che il motore analizzi una query. Le responsabilità principali del thread genitore sono:
- Coordinare un'analisi parallela.
- Avviare i ruoli di lavoro figlio paralleli.
- Raccogliere le righe dai thread paralleli e inviarle al client.
- Eseguire aggregazioni locali e globali.
Nota
Se un piano di query include rami seriali e paralleli, una delle attività parallele sarà responsabile dell'esecuzione del ramo seriale.
Il numero di thread di lavoro generati per ogni attività dipende da:
Se la richiesta era idonea per il parallelismo secondo quanto determinato da Query Optimizer.
Qual è grado di parallelismo (DOP) effettivamente disponibile nel sistema in base al carico corrente. Il valore può essere diverso dal DOP stimato, che si basa sulla configurazione del server per il massimo grado di parallelismo (MAXDOP). Ad esempio, la configurazione del server per MAXDOP può essere 8 ma il DOP disponibile al momento dell'esecuzione può essere solo 2 e questo influisce negativamente sulle prestazioni delle query. L’utilizzo elevato di memoria e la mancanza di lavoratori sono due condizioni che riducono il DOP disponibile in runtime.
Nota
Il limite MAXDOP (max degree of parallelism) viene impostato per attività, non per richiesta. Ciò significa che durante l'esecuzione di una query parallela, una singola richiesta può generare più task fino al limite MAXDOP e ogni task utilizzerà un solo lavoratore. Per ulteriori informazioni su MAXDOP, consultare Configura l'opzione di configurazione del server relativa al grado massimo di parallelismo.
Pianificatori
Un'utilità di pianificazione, nota anche come utilità di pianificazione SOS, gestisce i thread di lavoro che richiedono tempo di elaborazione per svolgere il lavoro per conto delle attività. Ogni scheduler viene mappato a un singolo processore (CPU). Il tempo in cui un lavoratore può rimanere attivo in un schedulatore si chiama quantum del sistema operativo, con un massimo di 4 ms. Scaduto il tempo del quantum, un thread cede il proprio tempo ad altri thread che devono accedere alle risorse della CPU e modifica il proprio stato. Questa cooperazione tra lavoratori per ottimizzare l'accesso alle risorse della CPU è denominata pianificazione cooperativa, nota anche come pianificazione non preventiva. A sua volta, la modifica dello stato del lavoratore viene propagata all'attività associata a tale lavoratore e alla richiesta associata all'attività. Per ulteriori informazioni sugli stati dei lavoratori, vedere sys.dm_os_workers. Per ulteriori informazioni sugli scheduler, vedere sys.dm_os_schedulers.
In breve, una richiesta può generare una o più attività per eseguire unità di lavoro. Ogni attività viene assegnata a un thread di lavoro responsabile del completamento dell'attività. Ogni thread di lavoro deve essere pianificato (inserito in un pianificatore) per l'esecuzione attiva dell'attività.
Prendi in considerazione lo scenario seguente:
- Lavoratore 1 è un'attività a esecuzione prolungata, ad esempio una query di lettura che utilizza il read-ahead su tabelle basate su disco. Lavoratore 1 scopre che le pagine di dati richieste sono già nel pool di buffer, quindi non deve cedere il proprio tempo per attendere le operazioni di I/O e può utilizzare tutto il quantum prima di passare il controllo.
- Lavoratore 2 sta eseguendo compiti più brevi inferiori al millisecondo e pertanto deve cedere il controllo del processore prima che il suo intero quantum sia esaurito.
In questo scenario e fino a SQL Server 2014 (12.x), Worker 1 può fondamentalmente monopolizzare il pianificatore avendo più tempo totale del quantum.
A partire da SQL Server 2016 (13.x), la pianificazione cooperativa include la pianificazione LDF (Large Deficit First). Con la pianificazione LDF, i modelli di utilizzo del quantum sono monitorati e un singolo thread di lavoro non monopolizza un pianificatore. Nello stesso scenario, Lavoratore 2 può utilizzare quantum ripetuti prima che a Lavoratore 1 vengano concessi ulteriori quantum, impedendo quindi a Lavoratore 1 di monopolizzare il pianificatore con uno schema non amichevole.
Pianificare attività in parallelo
Immaginiamo un SQL Server configurato con MaxDOP 8 e l'affinità di CPU configurata per 24 CPU (scheduler) tra i nodi NUMA 0 e 1. Gli scheduler da 0 a 11 appartengono al nodo NUMA 0, gli scheduler da 12 a 23 appartengono al nodo NUMA 1. Un'applicazione invia la query seguente (richiesta) al motore di database:
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
Suggerimento
La query di esempio può essere eseguita usando il database di esempio AdventureWorks2016_EXT. Le tabelle Sales.SalesOrderHeader e Sales.SalesOrderDetail sono state ingrandite 50 volte e rinominate Sales.SalesOrderHeaderBulk e Sales.SalesOrderDetailBulk.
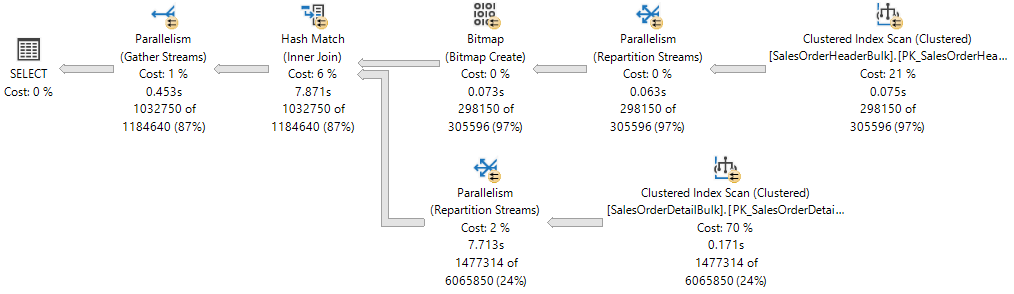
Il piano di esecuzione mostra un hash join tra due tabelle e ognuno degli operatori eseguiti in parallelo, come indicato dal cerchio giallo con due frecce. Ogni operatore di parallelismo è un ramo diverso del piano. Di conseguenza, nel piano di esecuzione riportato di seguito sono presenti tre rami.
Nota
Se si pensa a un piano di esecuzione come a un albero, un ramo è un'area del piano che raggruppa uno o più operatori tra gli operatori Parallelism, chiamati anche iteratori di Exchange. Per ulteriori informazioni sugli operatori del piano di esecuzione, vedere Guida di riferimento agli Operatori Logici e Fisici di Showplan.
Sebbene esistano tre rami nel piano di esecuzione, in qualsiasi momento durante l'esecuzione è possibile eseguire contemporaneamente solo due rami nel piano di esecuzione:
- Il ramo in cui un operatore Clustered Index Scan viene usato su
Sales.SalesOrderHeaderBulk(input di costruzione del join) viene eseguito separatamente. - Quindi, il ramo in cui viene utilizzato un Clustered Index Scan sull'
Sales.SalesOrderDetailBulk(ingresso di sonda del join) viene eseguito contemporaneamente al ramo in cui è stato creato il Bitmap e in cui è attualmente in esecuzione l'Hash Match.
Showplan XML mostra che 16 thread di lavoro sono stati prenotati e usati nel nodo NUMA 0:
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
La prenotazione dei thread garantisce che il motore di database disponga di un numero sufficiente di thread di lavoro per eseguire tutte le attività necessarie per la richiesta. I thread possono essere prenotati in diversi nodi NUMA oppure in un solo nodo NUMA. La prenotazione del thread viene eseguita al momento del runtime prima che inizi l'esecuzione e dipende dal carico del pianificatore. Il numero di thread di lavoro prenotati viene calcolato in maniera generica dalla formula concurrent branches * runtime DOP ed esclude il thread di lavoro padre. Ogni ramo è limitato a un numero di thread di lavoro uguale a MaxDOP. In questo esempio sono presenti due rami simultanei e MaxDOP è impostato su 8, ovvero 2 * 8 = 16.
Per riferimento, osservare il piano di esecuzione in tempo reale in Statistiche query dinamiche dove un ramo è stato completato e due rami sono in esecuzione simultaneamente.
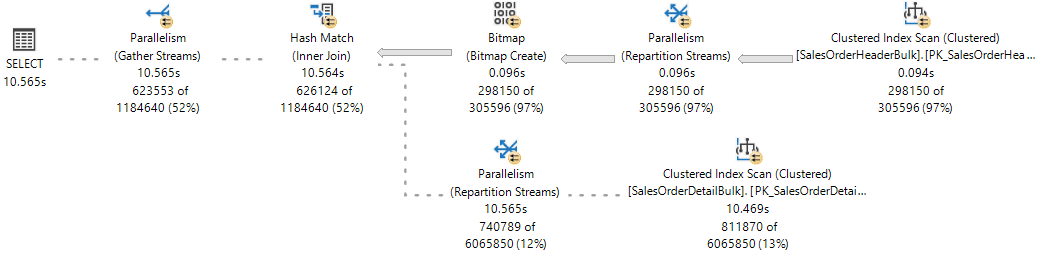
Il motore di database SQL Server assegnerà un thread di lavoro per eseguire un'attività attiva (1:1) che può essere osservata durante l'esecuzione di query eseguendo una query nella DMV sys.dm_os_tasks, come illustrato nell'esempio seguente:
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
Suggerimento
La colonna parent_task_address è sempre NULL per l'attività padre.
Suggerimento
In un motore di database SQL Server occupato è possibile osservare un numero di attività attive che supera il limite impostato dai thread prenotati. Queste attività possono appartenere a un ramo che non viene più usato e si trovano in uno stato temporaneo in attesa della pulizia.
Il set di risultati è il seguente. Si noti che sono presenti 17 attività attive per i rami attualmente in esecuzione: 16 attività figlie corrispondenti ai thread riservati, oltre all'attività principale o al coordinamento dell'attività.
| indirizzo_compito_genitore | indirizzo_task | stato_attività | scheduler_id | indirizzo del lavoratore |
|---|---|---|---|---|
| NULLO | 0x000001EF4758ACA8 |
SOSPESO | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | SOSPESO | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | SOSPESO | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | SOSPESO | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | SOSPESO | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | SOSPESO | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | SOSPESO | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | SOSPESO | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | SOSPESO | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | SOSPESO | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | SOSPESO | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | SOSPESO | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | SOSPESO | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | SOSPESO | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | SOSPESO | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | SOSPESO | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | SOSPESO | 11 | 0x000001EF6BD72160 |
Osservare che a ognuna delle 16 attività figlio è stato assegnato un thread di lavoro diverso (visibile nella colonna worker_address), ma tutti i thread sono assegnati allo stesso pool di otto scheduler (0, 5, 6, 7, 8, 9, 10, 11) e che all'attività padre è assegnato uno scheduler al di fuori di questo pool (3).
Importante
Dopo aver pianificato il primo set di attività parallele in un determinato ramo, il motore di database userà lo stesso pool di utilità di pianificazione per eventuali attività aggiuntive in altri rami. Ciò significa che lo stesso set di scheduler verrà utilizzato per tutte le attività parallele nell'intero piano di esecuzione, limitato solo da MaxDOP.
Il motore di database SQL Server tenterà sempre di assegnare gli scheduler dal medesimo nodo NUMA per l'esecuzione delle attività e di assegnarli in sequenza (in modalità round robin) se disponibili. Tuttavia, il thread di lavoro assegnato al compito principale può trovarsi in un nodo NUMA diverso rispetto agli altri compiti.
Un thread di lavoro può rimanere attivo nello schedulatore solo per la durata del quantum (4 ms) e deve cedere lo schedulatore dopo che il quantum è trascorso, in modo che un thread di lavoro assegnato a un'altra attività possa diventare attivo. Quando il quantum di un lavoratore scade e non è più operativo, l'attività corrispondente viene inserita in una coda FIFO con stato RUNNABLE fino a quando non ritorna allo stato RUNNING, a condizione che non richieda l'accesso a risorse non disponibili, come un fermaglio o un blocco. In tal caso, l'attività verrebbe messa in stato SUSPENDED anziché RUNNABLE fino a quando le risorse non diventano disponibili.
Suggerimento
Per l'output della DMV visto sopra, tutte le attività attive sono nello stato SUSPENDED. Per informazioni dettagliate sulle attività in attesa, è possibile eseguire una query nella DMV sys.dm_os_waiting_tasks.
In breve, una richiesta parallela genera più attività. Ogni attività deve essere assegnata a un unico thread di lavoro. Ogni thread di lavoro deve essere assegnato a un'unica pianificatore. Il numero di scheduler in uso non può quindi superare il numero di attività parallele per branca, impostato dalla configurazione MaxDOP o dall'hint della query. Il thread di coordinamento non contribuisce al limite MaxDOP.
Allocazione dei thread alle CPU
Per impostazione predefinita, ogni istanza di SQL Server avvia un singolo thread e il sistema operativo distribuisce i thread delle istanze di SQL Server tra i processori (CPU) di un computer in base al carico. Se è stata abilitata l'affinità del processo a livello di sistema operativo, il sistema operativo assegna ogni thread a una CPU specifica. Al contrario, il Motore di database di SQL Server assegna i thread di lavoro di SQL Server a pianificatori che distribuiscono i thread in modo uniforme tra le CPU, in modalità round robin.
Per eseguire il multitasking, ad esempio quando più applicazioni accedono allo stesso gruppo di CPU, in certi casi il sistema operativo distribuisce i thread di lavoro tra CPU diverse. Anche se in questo modo viene garantita una maggiore efficienza del sistema operativo, questa attività può comportare una riduzione delle prestazioni di SQL Server nel caso di carichi di lavoro elevati, poiché la cache di ogni processore viene ricaricata più volte con dati. L'assegnazione di CPU a thread specifici consente di migliorare le prestazioni, poiché le operazioni di ricaricamento dei processori vengono eliminate e si riduce la migrazione dei thread tra CPU, limitando lo scambio di contesto. Questo tipo di associazione tra un thread e un processore è definito "affinità processori". Se è stata abilitata l'affinità, il sistema operativo assegna ogni thread a una CPU specifica.
L'opzione affinity mask viene impostata tramite ALTER SERVER CONFIGURATION. Quando la maschera di affinità non è impostata, l'istanza di SQL Server alloca uniformemente i thread di lavoro fra gli scheduler che non sono stati esclusi.
Attenzione
Non configurare l'affinità della CPU nel sistema operativo né l'opzione affinity mask in SQL Server. Le due impostazioni mirano a ottenere lo stesso risultato e, se le configurazioni sono incoerenti, potrebbero causare risultati imprevisti. Per altre informazioni, vedere opzione affinity mask.
La creazione di un pool di thread consente di ottimizzare le prestazioni quando al server è connesso un numero elevato di client. In genere viene creato un thread del sistema operativo distinto per ogni richiesta di query. In presenza, tuttavia, di centinaia di connessioni al server, l'utilizzo di un thread per ogni richiesta di query può occupare quantità elevate di risorse di sistema. L'opzione max worker threads consente di migliorare le prestazioni di SQL Server grazie alla creazione di un pool di thread di lavoro per soddisfare una maggiore quantità di richieste di query.
Uso dell'opzione di lightweight pooling
Importante
A partire da SQL Server 2025 (17.x), la funzionalità in modalità fiber abilitata dall'opzione lightweight pooling è deprecata ed è pianificata per la rimozione in una versione futura di SQL Server. A causa di problemi noti di stabilità e compatibilità, Microsoft consiglia di evitare di usare questa funzionalità in qualsiasi versione di SQL Server.
Lo scambio del contesto dei thread non produce in genere un overhead molto elevato. Per la maggior parte delle istanze di SQL Server non si verificheranno differenze di prestazione tra l'impostazione dell'opzione lightweight pooling su 0 o 1. Le uniche istanze di SQL Server che possono trarre beneficio dall'opzione lightweight pooling sono quelle in esecuzione in un computer con le caratteristiche seguenti:
- Server di grandi dimensioni con più CPU
- Tutte le CPU stanno funzionando vicino alla capacità massima
- Viene eseguita un'intensa attività di cambio di contesto
Le prestazioni di questi sistemi potrebbero migliorare impostando il valore dell'opzione lightweight pooling su 1.
Importante
Non utilizzare la programmazione in modalità fiber per operazioni di routine. Questo può causare una diminuzione delle prestazioni, limitando i vantaggi normali del cambio di contesto, per il fatto che alcuni componenti di SQL Server non funzionano correttamente in modalità fiber. Per altre informazioni, vedere lightweight pooling.
Thread ed esecuzione in modalità fiber
Microsoft Windows utilizza un sistema a priorità numerica che utilizza intervalli compresi tra 1 e 31 per la pianificazione dei thread per l'esecuzione. Lo zero è riservato all'utilizzo da parte del sistema operativo. Quando più thread sono in attesa di esecuzione, Windows esegue il dispatch del thread con la priorità più alta.
Per impostazione predefinita, ogni istanza di SQL Server ha priorità 7, che è considerata la priorità normale. In questo modo ai thread di SQL Server viene assegnata una priorità sufficientemente alta per ottenere le risorse della CPU necessarie senza produrre effetti negativi sulle altre applicazioni.
Importante
Questa funzionalità verrà rimossa nelle versioni future di SQL Server. Evitare di usare questa funzionalità in un nuovo progetto di sviluppo e prevedere interventi di modifica nelle applicazioni in cui è attualmente implementata.
È possibile usare l'opzione di configurazione priority boost per aumentare fino a 13 il livello di priorità dei thread di un'istanza di SQL Server. (alta priorità). Questa impostazione consente di assegnare ai thread di SQL Server una priorità maggiore di quella della maggior parte delle altre applicazioni. Pertanto, il dispatch dei thread di SQL Server viene eseguito non appena è possibile eseguire i thread, che non vengono quindi preceduti dai thread di altre applicazioni. Le prestazioni vengono migliorate se nel server sono in esecuzione solo istanze di SQL Server e non altre applicazioni. Tuttavia, se in SQL Server viene eseguita un'operazione che impegna notevolmente la memoria, è probabile che la priorità delle altre applicazioni non sia maggiore di quella del thread di SQL Server.
Se vengono eseguite più istanze di SQL Server nello stesso computer e solo per alcune è impostata l'opzione priority boost, le prestazioni delle istanze in esecuzione con priorità normale potrebbero risentirne. Le prestazioni delle altre applicazioni e degli altri componenti sul server possono ridursi se priority boost è abilitato. Pertanto, è consigliabile utilizzarlo solo in condizioni assolutamente controllate.
Aggiunta di CPU a caldo
Importante
A partire da SQL Server 2025 (17.x), la funzionalità di aggiunta a caldo della CPU è deprecata e ne è prevista la rimozione in una versione futura di SQL Server. A causa di problemi di stabilità noti, Microsoft consiglia di evitare di usare questa funzionalità nell'amministrazione di SQL Server in qualsiasi versione di SQL Server.
Per aggiunta di CPU a caldo si intende la possibilità di aggiungere CPU a un sistema in esecuzione in modo dinamico. L'aggiunta di CPU può verificarsi fisicamente tramite l'aggiunta di nuovi componenti hardware, in modo logico tramite il partizionamento hardware online o virtualmente tramite un livello di virtualizzazione.
Requisiti per l'aggiunta di CPU a caldo:
- È necessario disporre di hardware che supporta l'aggiunta di CPU a caldo.
- Richiede una versione supportata di Windows Server Datacenter o edizione Enterprise. A partire da Windows Server 2012, il "hot add" è supportato nell'edizione Standard.
- Richiede SQL Server edizione Enterprise.
- SQL Server non può essere configurato per utilizzare soft NUMA. Per altre informazioni su Soft-NUMA, vedere Soft-NUMA (SQL Server).
SQL Server non usa automaticamente CPU una volta aggiunte. In tal modo si evita che SQL Server faccia uso di CPU che potrebbero essere state aggiunte per altri scopi. Dopo aver aggiunto CPU, eseguire l'istruzione RECONFIGURE , in modo che SQL Server riconosca le nuove CPU come risorse disponibili.
Se è configurata l'opzione affinity64 mask , sarà necessario modificarla per consentire l'uso delle nuove CPU.
Procedure consigliate per l'esecuzione di SQL Server in computer che hanno più di 64 CPU
Assegnazione dei thread hardware ai processori
Non usare le opzioni di configurazione del server affinity mask e affinity64 mask per associare processori a thread specifici. Queste opzioni sono limitate a 64 CPU. Usare invece l'opzione SET PROCESS AFFINITY di ALTER SERVER CONFIGURATION.
Gestione della dimensione del file di registro delle transazioni
Non utilizzare l'aumento automatico per aumentare le dimensioni del file registro transazioni. L'aumento del log delle transazioni deve essere eseguito tramite un processo seriale. L'estensione del log può impedire il proseguimento delle operazioni di scrittura delle transazioni fino al completamento dell'estensione del log. Preallocare invece lo spazio per i file di log impostando le dimensioni dei file su un valore sufficientemente elevato per supportare il tipico carico di lavoro nell'ambiente.
Imposta il grado massimo di parallelismo per le operazioni sugli indici
Le prestazioni delle operazioni sugli indici, come la creazione o la ricompilazione degli indici, possono essere ottimizzate nei computer dotati di molte CPU impostando temporaneamente il modello di recupero del database sul modello con registrazione bulk o sul modello di recupero semplice. Queste operazioni sugli indici possono generare attività del log significative e le contese relative al log possono influire sulla scelta del grado di parallelismo (DOP) effettuata da SQL Server.
Oltre a modificare l'opzione di configurazione del server max degree of parallelism (MAXDOP), valutare la possibilità di adeguare il parallelismo per le operazioni sugli indici usando l'opzione MAXDOP. Per altre informazioni, vedere Configurazione di operazioni parallele sugli indici. Per altre informazioni e istruzioni relative alla modifica dell'opzione di configurazione del server max degree of parallelism, vedere Configurare l'opzione di configurazione del server max degree of parallelism.
Opzione numero massimo di thread di lavoratore
SQL Server configura in modo dinamico l'opzione di configurazione del server max worker threads all'avvio. SQL Server usa il numero di CPU disponibili e l'architettura di sistema per determinare questa configurazione del server nella fase di avvio, usando una formula documentata.
Questa opzione è un'opzione avanzata e deve essere modificata solo da un professionista esperto del database.
Se si sospetta la presenza di un problema di prestazioni, è poco probabile che sia un problema di disponibilità dei thread di lavoro. È più probabile che la causa sia legata a operazioni di input/output che determinano l'attesa dei thread di lavoro. È consigliabile individuare la causa radice di un problema di prestazioni prima di modificare l'impostazione max worker threads. Tuttavia, se è necessario impostare manualmente il numero massimo di thread di lavoro, questo valore di configurazione deve essere sempre impostato su un valore che sia almeno sette volte il numero di CPU presenti nel sistema. Per altre informazioni, vedere Configura i thread massimi di lavoro.
Evitare l'uso di SQL Trace e SQL Server Profiler
L'uso di Traccia SQL e SQL Server Profiler in un ambiente di produzione è sconsigliato. L'overhead per l'esecuzione di questi strumenti, inoltre, aumenta in funzione del numero di CPU. Se è necessario utilizzare Traccia SQL in un ambiente di produzione, ridurre al minimo il numero di eventi di traccia. Profilare e testare accuratamente ogni evento di traccia soggetto a carico ed evitare di utilizzare combinazioni di eventi che influiscono notevolmente sulle prestazioni.
Importante
SQL Trace e SQL Server Profiler sono obsoleti. Anche lo spazio dei nomi Microsoft.SqlServer.Management.Trace che contiene gli oggetti Trace di SQL Server e Replay è deprecato.
Questa funzionalità verrà rimossa nelle versioni future di SQL Server. Evitare di usare questa funzionalità in un nuovo progetto di sviluppo e prevedere interventi di modifica nelle applicazioni in cui è attualmente implementata.
In alternativa, usare Eventi estesi. Per altre informazioni sugli eventi estesi, vedere Avvio rapido: Eventi estesi in SQL Server e Profiler XEvent di SSMS.
Nota
SQL Server Profiler per i carichi di lavoro di Analysis Services NON è deprecato e continuerà a essere supportato.
Impostare il numero di file di dati tempdb.
Il numero di file dipende dal numero di processori (logici) del computer. In generale, se il numero di processori logici è minore o uguale a otto, usare un numero di file di dati pari al numero dei processori logici. Se il numero di processori logici è maggiore di otto, usare otto file di dati e, se la contesa persiste, aumentare il numero di file di dati per multipli di 4 fino a quando la contesa si riduce a livelli accettabili o modificare il carico di lavoro o il codice. Tenere anche presenti altri consigli per tempdb, disponibili in Ottimizzazione delle prestazioni di tempdb in SQL Server.
Tuttavia, è possibile ridurre il carico di gestione del database considerando attentamente le esigenze di concorrenza di tempdb. Ad esempio, se un sistema dispone di 64 CPU e solo 32 query utilizzano in genere file tempdb, aumentando il numero di file tempdb a 64 le prestazioni non miglioreranno.
Componenti di SQL Server che possono usare più di 64 CPU
Nella tabella seguente sono elencati i componenti di SQL Server e viene indicato se possano o meno usare più di 64 CPU.
| Nome del processo | Programma eseguibile | Utilizza più di 64 CPU |
|---|---|---|
| Motore di database di SQL Server | Sqlserver.exe | Sì |
| Servizi di Reporting | Rs.exe | NO |
| Servizi di analisi | As.exe | NO |
| Servizi di Integrazione | Is.exe | NO |
| Servizio Broker | Sb.exe | NO |
| Ricerca a tutto testo | Fts.exe | NO |
| Agente di SQL Server | Sqlagent.exe | NO |
| SQL Server Management Studio | Ssms.exe | NO |
| Installazione di SQL Server | Setup.exe | NO |