Apprendimento automatico per la visione artificiale
La possibilità di utilizzare i filtri per applicare effetti alle immagini è utile nelle attività di elaborazione delle immagini, come quelle che si possono eseguire con i software di modifica delle immagini. Tuttavia, l'obiettivo della visione artificiale è quello di estrarre un significato, o perlomeno delle informazioni utili dalle immagini. Questo richiede la creazione di modelli di apprendimento automatico sottoposti a training per riconoscere le caratteristiche sulla base di grandi volumi di immagini esistenti.
Suggerimento
Questa unità presuppone che si conoscano i principi fondamentali dell'apprendimento automatico e che si abbia una certa conoscenza del Deep Learning con le reti neurali. Se non si ha familiarità con l'apprendimento automatico, è consigliabile completare il modulo Nozioni fondamentali dell’apprendimento automatico in Microsoft Learn.
Reti neurali convoluzionali (CNN)
Una delle architetture di modelli di Machine Learning più comuni per la visione artificiale è una rete neurale convoluzionale (CNN). Le CNN utilizzano filtri per estrarre mappe di caratteristiche numeriche dalle immagini, quindi inseriscono i valori delle caratteristiche in un modello di Deep Learning per generare una stima delle etichette. Ad esempio, in uno scenario di classificazione immagini, l'etichetta rappresenta il soggetto principale dell'immagine (in altre parole, di che immagine si tratta?). È possibile eseguire il training di un modello CNN con immagini di diversi tipi di frutta (ad esempio mela, banana e arancia) in modo che l'etichetta prevista sia il tipo di frutta presente in una determinata immagine.
Durante il processo di training di una CNN, i kernel del filtro vengono inizialmente definiti utilizzando valori di peso generati in modo casuale. Quindi, man mano che il processo di training avanza, le stime dei modelli vengono valutate rispetto ai valori noti delle etichette e i pesi del filtro vengono regolati per migliorare l'accuratezza. Infine, il modello di classificazione delle immagini della frutta sottoposto a training utilizza i pesi dei filtri che estraggono più facilmente le caratteristiche per identificare i diversi tipi di frutta.
Il diagramma seguente illustra il funzionamento di una rete CNN per un modello di classificazione delle immagini:
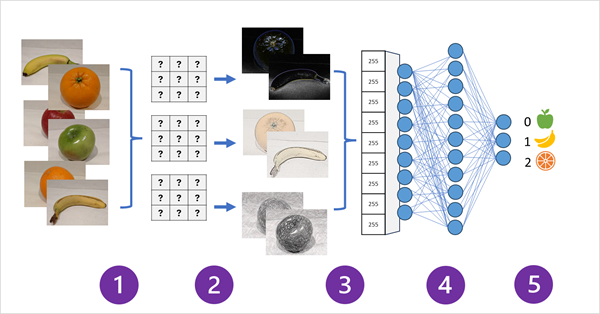
- Le immagini con etichette note (ad esempio, 0: mela, 1: banana o 2: arancia) vengono inserite nella rete per eseguire il training del modello.
- Uno o più livelli di filtri vengono utilizzati per estrarre le caratteristiche da ogni immagine che viene alimentata dalla rete. I kernel di filtro iniziano con pesi assegnati in modo casuale e generano matrici di valori numerici denominati mappe delle caratteristiche.
- Le mappe delle caratteristiche vengono ridotte in una matrice unidimensionale di valori delle caratteristiche.
- I valori delle caratteristiche vengono inseriti in una rete neurale completamente connessa.
- Il livello di output della rete neurale usa una funzione softmax o simile per produrre un risultato che contiene un valore di probabilità per ogni classe possibile, ad esempio [0,2, 0,5, 0,3].
Durante il training, le probabilità di output vengono confrontate con l'etichetta di classe effettiva, ad esempio un'immagine di una banana (classe 1) deve avere il valore [0,0, 1,0, 0,0]. La differenza tra i punteggi di classe stimati e effettivi viene usata per calcolare la perdita nel modello e i pesi nella rete neurale completamente connessa e i kernel di filtro nei livelli di estrazione delle caratteristiche vengono modificati per ridurre la perdita.
Il processo di training si ripete in più periodi fino a quando non viene appreso un set ottimale di pesi. Quindi, i pesi vengono salvati e il modello può essere utilizzato per prevedere le etichette di nuove immagini di cui non si conosce l'etichetta.
Nota
Le architetture CNN di solito includono più livelli di filtri convoluzionali e livelli aggiuntivi per ridurre le dimensioni delle mappe di caratteristiche, vincolare i valori estratti e manipolare i valori delle caratteristiche. Questi livelli sono stati omessi in questo esempio semplificato per concentrarsi sul concetto chiave: i filtri vengono utilizzati per estrarre caratteristiche numeriche dalle immagini, che vengono poi utilizzate in una rete neurale per prevedere le etichette delle immagini.
Trasformatori e modelli multi modali
Le CNN sono alla base delle soluzioni di visione artificiale da molti anni. Anche se vengono comunemente usate per risolvere i problemi di classificazione immagini, come descritto in precedenza, sono anche la base per i modelli di visione artificiale più complessi. Ad esempio, i modelli di rilevamento oggetti combinano i livelli di estrazione delle funzionalità CNN con l'identificazione delle aree di interesse nelle immagini per individuare più classi di oggetti nella stessa immagine.
Convertitori
La maggior parte dei progressi nella visione artificiale nel corso dei decenni è stata guidata dai miglioramenti nei modelli basati su CNN. Tuttavia, in un'altra disciplina di intelligenza artificiale, l’elaborazione del linguaggio naturale (NLP), un altro tipo di architettura di rete neurale, chiamato trasformatore ha abilitato lo sviluppo di modelli sofisticati per il linguaggio. I trasformatori funzionano elaborando enormi volumi di dati e codificando i token linguistici (che rappresentano singole parole o frasi) come embedding basati su vettori (matrici di valori numerici). Possiamo considerare un embedding come un insieme di dimensioni che rappresentano ciascuna un attributo semantico del token. Gli embedding sono creati in modo tale che i token comunemente usati nello stesso contesto siano più vicini dimensionalmente rispetto alle parole non correlate.
A titolo di semplice esempio, il diagramma seguente mostra alcune parole codificate come vettori tridimensionali e tracciate in uno spazio 3D:
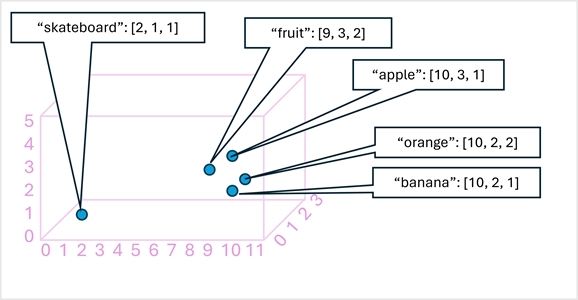
I token semanticamente simili vengono codificati in posizioni simili, creando un modello linguistico semantico che consente di sviluppare soluzioni di elaborazione del linguaggio naturale sofisticate per l'analisi del testo, la traduzione, la generazione del linguaggio e altre attività.
Nota
Abbiamo utilizzato solo tre dimensioni, perché in questo modo la visualizzazione risulta più semplice. In realtà, i codificatori nelle reti di trasformatori creano vettori con molte più dimensioni, definendo complesse relazioni semantiche tra i token basate su calcoli algebrici lineari. La matematica è complessa, così come l'architettura di un modello di trasformatore. Il nostro obiettivo è solo quello di fornire una panoramica concettuale su come la codifica crea un modello che incapsula le relazioni tra le entità.
Modelli multi modali
Il successo dei trasformatori come metodo per sviluppare modelli linguistici ha portato i ricercatori di intelligenza artificiale a valutare se lo stesso approccio possa essere efficace per i dati delle immagini. Il risultato è lo sviluppo di modelli multi modali, in cui il training del modello viene eseguito usando un volume elevato di immagini con didascalia, senza etichette fisse. Un codificatore di immagini estrae le caratteristiche dalle immagini in base ai valori dei pixel e le combina con gli embedding di testo creati da un codificatore linguistico. Il modello complessivo incapsula le relazioni tra gli embedding dei token del linguaggio naturale e le caratteristiche delle immagini, come mostrato di seguito:
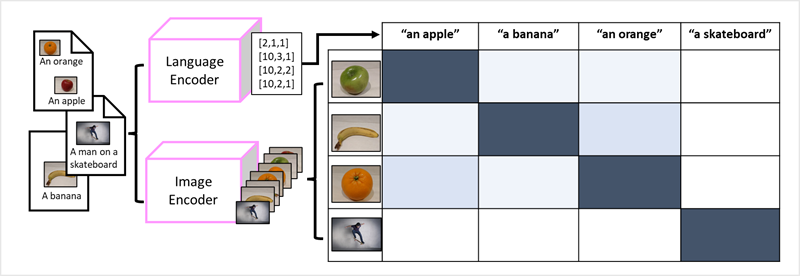
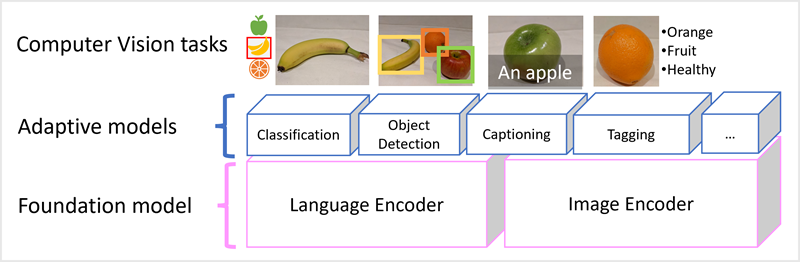
Il modello Microsoft Florence è un modello di questo tipo. Sottoposto a training con enormi volumi di immagini con didascalia da Internet, include sia un codificatore linguistico che un codificatore di immagini. Florence è un esempio di modello di fondazione. In altre parole, un modello generale con training preliminare su cui è possibile creare più modelli adattivi per attività specializzate. Ad esempio, è possibile usare Florence come modello di base per i modelli adattivi che eseguono:
- Classificazione immagini: Identificazione della categoria a cui appartiene un'immagine.
- Rilevamento oggetti: Individuazione di singoli oggetti all'interno di un'immagine.
- Didascalia: Generazione di descrizioni appropriate delle immagini.
- Assegnazione di tag: Compilazione di un elenco di tag di testo pertinenti per un'immagine.
I modelli multimodali come Florence sono all'avanguardia nel campo della visione artificiale e dell'intelligenza artificiale in generale, e si prevede che guideranno i progressi nelle soluzioni che l'intelligenza artificiale renderà possibili.