Configurare un set di scalabilità di macchine virtuali
Quando si effettua un ridimensionamento, si aggiungono istanze al set di scalabilità di macchine virtuali. Nello scenario dell’azienda di spedizioni, il ridimensionamento è un buon modo per gestire il numero di richieste mutevoli nel tempo. Il ridimensionamento regola il numero di macchine virtuali che eseguono l'applicazione Web quando il numero di utenti cambia. In questo modo, il sistema è in grado di mantenere un tempo di risposta costante, indipendentemente dal carico corrente.
In questa unità si apprenderà come ridimensionare un set di scalabilità di macchine virtuali. È possibile eseguire il ridimensionamento manualmente impostando in modo esplicito il numero di istanze di macchine virtuali nel set di scalabilità oppure è possibile configurare la scalabilità automatica definendo regole di scalabilità che attivano l'allocazione e la deallocazione delle macchine virtuali. Queste regole determinano quando ridimensionare il sistema tramite il monitoraggio di varie metriche delle prestazioni.
Ridimensionare manualmente i set di scalabilità di macchine virtuali
È possibile ridimensionare manualmente un set di scalabilità di macchine virtuali aumentando o riducendo il numero di istanze. Questa attività può essere eseguita a livello di codice o nel portale di Azure.
Il codice seguente usa l'interfaccia della riga di comando di Azure per modificare il numero di istanze in un set di scalabilità di macchine virtuali:
az vmss scale \
--name MyVMScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
Ridimensionare automaticamente i set di scalabilità di macchine virtuali
In alcune circostanze, la scalabilità manuale è utile. In molte situazioni, tuttavia, la scalabilità automatica è preferibile. Consente al sistema di controllare il numero di istanze in un set di scalabilità.
È possibile basare la scalabilità automatica su:
- Pianificazione: usare questo approccio se si è certi di avere un carico di lavoro maggiore durante un determinato intervallo di date/ore.
- Metriche: regolare il ridimensionamento monitorando le metriche delle prestazioni associate al set di scalabilità. Quando le metriche superano una soglia specificata, il set di scalabilità può avviare automaticamente nuove istanze di macchine virtuali. Quando le metriche indicano che le risorse aggiuntive non sono più necessarie, il set di scalabilità può arrestare le eventuali istanze in eccesso.
Definire le condizioni, le regole e i limiti di scalabilità automatica
La scalabilità automatica si basa su un set di condizioni, regole e limiti di scalabilità. Una condizione di scalabilità combina un orario con un set di regole di scalabilità. Se l'ora corrente rientra nel periodo definito nella condizione di scalabilità, vengono valutate le regole di scalabilità della condizione. I risultati di questa valutazione determinano se aggiungere o rimuovere istanze nel set di scalabilità. La condizione di scalabilità definisce anche i limiti di scalabilità, per il numero massimo e minimo di istanze.
Nello scenario dell’azienda di spedizioni, è possibile aggiungere regole di scalabilità che monitorano l'utilizzo della CPU nel set di scalabilità. Se l'utilizzo della CPU supera la soglia del 75%, la regola di scalabilità può aumentare il numero di istanze di macchine virtuali. Una seconda regola di scalabilità può anche monitorare l'utilizzo della CPU ma ridurre il numero di istanze di macchine virtuali quando l'utilizzo scende al di sotto del 50%. Dato che l'applicazione è globale, queste regole dovrebbero rimanere sempre attive anziché limitarsi a orari specifici.
Un set di scalabilità di macchine virtuali può contenere molte condizioni di scalabilità. Viene applicata ogni condizione di scalabilità corrispondente. Un set di scalabilità può anche contenere una condizione di scalabilità predefinita che viene usata se nessun'altra condizione corrisponde alle metriche di prestazioni e orario correnti. La condizione di scalabilità predefinita è sempre attiva. Non contiene regole di scalabilità e agisce in modo efficace come una condizione di scalabilità null che esegue operazioni di riduzione o aumento. Tuttavia, è possibile modificare la condizione di scalabilità predefinita per impostare un numero di istanze predefinito oppure è possibile aggiungere di nuovo una coppia di regole di scalabilità che eseguono un aumento e poi una riduzione.
Usare la scalabilità automatica basata sulla pianificazione
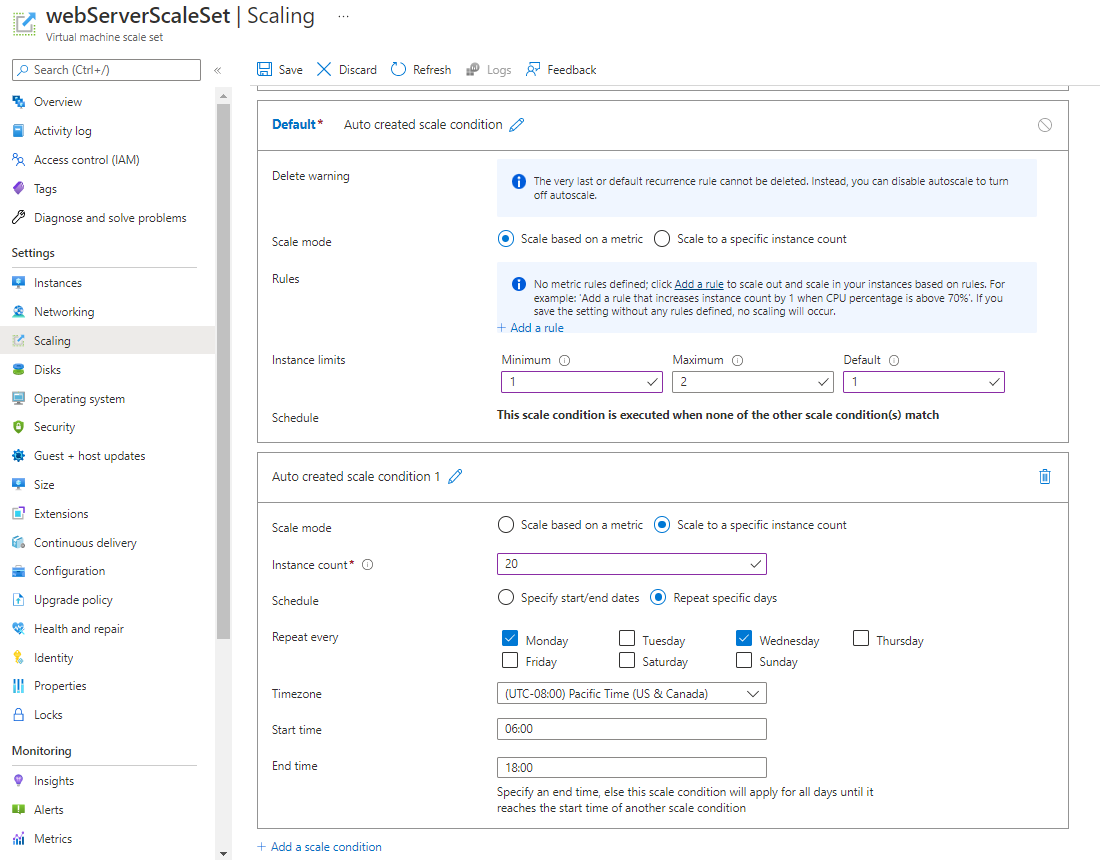
Il ridimensionamento basato su una pianificazione specifica un'ora di inizio e di fine e il numero di istanze da aggiungere al set di scalabilità. Lo screenshot seguente illustra un esempio nel portale di Azure. Il numero di istanze viene ridotto a 20 tra le 6.00 e le 18.00 di ogni lunedì e mercoledì. Al di fuori di questi orari, se non sono presenti altre condizioni di scalabilità, viene applicata quella predefinita.
In questo caso, la regola predefinita consente di riportare il sistema a due istanze. Questo valore è il massimo in questa condizione di scalabilità predefinita.
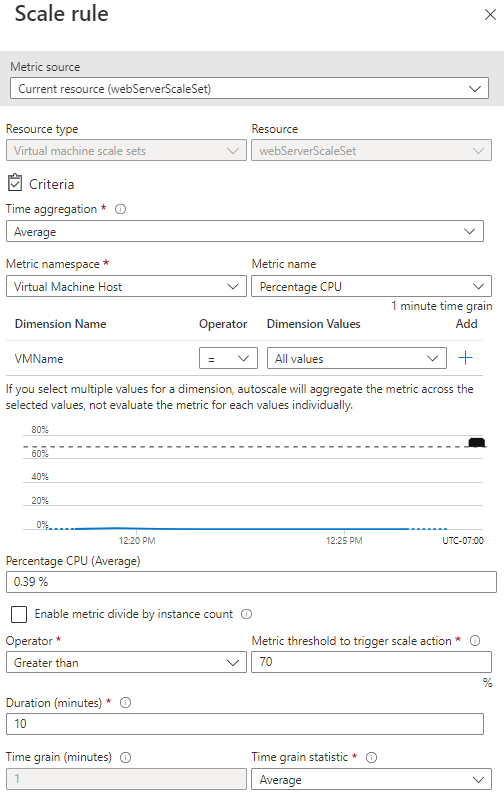
Usare la scalabilità automatica basata sulle metriche
Una regola di scalabilità basata sulle metriche specifica le risorse da monitorare, ad esempio l'utilizzo della CPU o il tempo di risposta. Questa regola di scalabilità aggiunge o rimuove le istanze del set di scalabilità in base ai valori di queste metriche. È possibile specificare limiti per il numero di istanze per impedire a un set di scalabilità di aumentare o ridurre eccessivamente il numero di istanze.
Nello scenario di esempio, si vuole aumentare di uno il numero di istanze quando l'utilizzo medio della CPU supera il 75%. Inoltre, si vuole limitare l'operazione di ampliamento a 50 istanze. Questo limite può essere utile per evitare ridimensionamenti fuori controllo costosi causati da un attacco. Analogamente, è opportuno ridurre il numero di istanze quando l'utilizzo medio della CPU scende al di sotto del 50%.
Queste metriche vengono comunemente usate per monitorare un set di scalabilità di macchine virtuali:
- Percentuale CPU: questa metrica indica l'utilizzo della CPU in tutte le istanze. Un valore elevato indica che le istanze dipendono sempre più dalla CPU, e questo può causare ritardi nell'elaborazione delle richieste client.
- Flussi in ingresso e flussi in uscita: queste metriche mostrano la velocità di flusso del traffico di rete in entrata e in uscita dalle macchine virtuali nel set di scalabilità.
- Operazioni di lettura disco/sec e operazioni di scrittura disco/sec: Queste metriche mostrano il volume di I/O su disco nel set di scalabilità.
- Profondità coda per un disco dati: questa metrica indica il numero di richieste di I/O solo per i dischi dati nelle macchine virtuali in attesa di essere servite.
Una regola di scalabilità aggrega i valori recuperati per una metrica per tutte le istanze. Aggrega i valori per un periodo noto come intervallo di tempo. Ogni metrica ha un intervallo di tempo intrinseco, ma in genere questo periodo è di un minuto. Il valore aggregato è noto come aggregazione temporale. Le opzioni di aggregazione temporale sono media, minimo, massimo, totale, ultimo e conteggio.
Un intervallo di un minuto è un periodo di tempo troppo breve per determinare se eventuali variazioni della metrica sono di durata sufficiente da rendere utile la scalabilità automatica. Una regola di scalabilità richiede un secondo passaggio, per l'ulteriore aggregazione del valore dell'aggregazione temporale per un periodo più lungo specificato dall'utente. Questo periodo è denominato durata. La durata minima è cinque minuti. Ad esempio, se la durata è impostata su 10 minuti, la regola di scalabilità aggrega i 10 valori calcolati per l'intervallo di tempo.
Il calcolo delle aggregazioni della durata può essere diverso dal calcolo delle aggregazioni dell'intervallo di tempo. Ad esempio, si supponga che l'aggregazione temporale sia media e che la statistica raccolta sia percentuale CPU per un intervallo di tempo di un minuto. Per ogni minuto, verrà calcolato l'utilizzo medio della percentuale di CPU in tutte le istanze durante tale minuto. Se la statistica per l'intervallo di tempo è impostata su massimo e la durata della regola è impostata su 10 minuti, il massimo dei 10 valori medi per la percentuale di utilizzo della CPU determina se è stata superata la soglia della regola.
Quando una regola di scalabilità rileva che una metrica ha superato una soglia, può eseguire un'azione di scalabilità. Questa azione può consistere in un aumento del numero di istanze o in una riduzione del numero di istanze. L'aumento del numero di istanze è noto anche come azione scale-out, mentre la riduzione del numero di istanze è nota anche come scale-in.
Un'azione di scalabilità usa un operatore (ad esempio, minore di, maggiore di o uguale a) per determinare come rispondere alla soglia. Le azioni di aumento del numero di istanze in genere usano l'operatore maggiore di per confrontare il valore della metrica con la soglia. Le azioni di riduzione del numero di istanze confrontano tendenzialmente il valore della metrica con la soglia usando l'operatore minore di. Un'azione di scalabilità imposta anche il numero di istanze su un livello specifico, anziché incrementare o ridurre il numero disponibile.
Un'azione di scalabilità ha un periodo di disattivazione, espresso in minuti. Durante questo periodo, la regola di scalabilità non viene nuovamente attivata. Il periodo di disattivazione consente al sistema di stabilizzarsi tra gli eventi di scalabilità. È necessario tempo per avviare o arrestare le istanze, pertanto le metriche raccolte potrebbero non mostrare variazioni significative per diversi minuti. Il periodo di disattivazione minimo è di cinque minuti.
Infine, è consigliabile pianificare una riduzione quando un carico di lavoro diminuisce. È possibile definire coppie di regole di scalabilità nella stessa condizione di scalabilità. Una regola di scalabilità deve indicare come aumentare la scalabilità del sistema quando una metrica supera una soglia superiore. L'altra regola deve definire come ridurre nuovamente il sistema quando la stessa metrica scende sotto una soglia inferiore. Non impostare entrambi i valori di soglia sullo stesso valore. In caso contrario, si potrebbero attivare una serie di eventi oscillanti che effettuano un aumento e una riduzione.
L'immagine seguente illustra una regola di scalabilità definita nel portale di Azure.