Case study: Hadoop distributed file system (HDFS)
Il modello di programmazione MapReduce consente di strutturare i processi di calcolo secondo due funzioni: mapping e riduzione. L'input viene immesso in MapReduce come coppie chiave-valore, in cui viene quindi elaborato tramite una funzione di mapping e inserito in una funzione di riduzione. L'operazione di riduzione produce quindi un risultato, anch'esso sotto forma di coppie chiave-valore. MapReduce è progettato per eseguire molte istanze di operazioni di mapping e riduzione in parallelo su un cluster di calcolo di grandi dimensioni. Il modello di programmazione MapReduce viene descritto in dettaglio in un modulo successivo.
Il modello di programmazione MapReduce presuppone la disponibilità di un sistema di archiviazione distribuito disponibile in tutti i nodi del cluster, con un singolo spazio dei nomi, in cui viene coinvolto un file system distribuito (DFS). Un file system DFS si trova nella stessa posizione dei nodi del cluster MapReduce. Il file system DFS è progettato per operare in tandem con MapReduce e gestisce un singolo spazio dei nomi per l'intero cluster MapReduce.
Una versione open source di MapReduce, denominata Apache Hadoop2, è molto diffusa negli ambienti con Big Data. HDFS è un file system DFS open source. HDFS è progettato come file system distribuito, scalabile e a tolleranza di errore che soddisfa principalmente le esigenze del modello di programmazione MapReduce. Il video 4.12 presenta HDFS.
È importante notare che HDFS non è conforme a POSIX e non è di per sé un file system montabile. L'accesso ad HDFS viene in genere eseguito tramite client HDFS o usando chiamate API (Application Programming Interface) dalle librerie Hadoop. Tuttavia, lo sviluppo di un driver FUSE (File system in User SpacE) per HDFS consente di montarlo come dispositivo virtuale in sistemi operativi simili a UNIX.
Architettura di HDFS
Come descritto in precedenza, HDFS è un file system DFS progettato per essere eseguito in un cluster di nodi con gli obiettivi seguenti:
- Un singolo spazio dei nomi comune a livello di cluster
- Possibilità di archiviare file di grandi dimensioni, ad esempio di diversi terabyte o petabyte
- Supporto per il modello di programmazione MapReduce
- Accesso ai dati di flusso per i modelli di accesso ai dati WORM
- Disponibilità elevata con prodotti hardware
La figura seguente mostra un cluster HDFS:
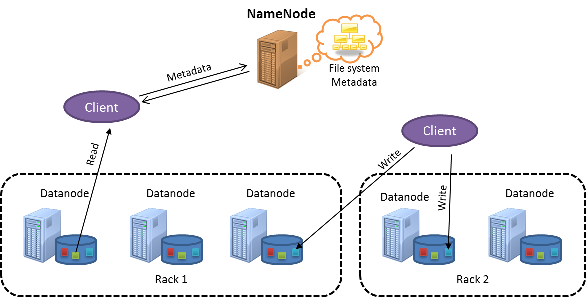
Figura 1: Architettura HDFS
HDFS segue una progettazione master-subordinato. Il nodo master viene chiamato NameNode. Il nodo NameNode si occupa della gestione dei metadati per l'intero cluster e mantiene un singolo spazio dei nomi per tutti i file archiviati in HDFS. I nodi subordinati sono noti come DataNode. I nodi DataNode archiviano all'interno di ogni nodo gli effettivi blocchi di dati presenti nel file system locale.
I file in HDFS sono suddivisi in blocchi con una dimensione predefinita di 128 MB ciascuno. Al contrario, i file system locali hanno in genere blocchi di file di dimensioni di circa 4 KB. HDFS usa blocchi di grandi dimensioni perché è progettato per archiviare file molto grandi in modo efficiente per l'elaborazione con processi MapReduce.
Per impostazione predefinita, una singola attività di mapping è configurata in MapReduce per operare indipendentemente in un singolo blocco HDFS e di conseguenza più attività di mapping possono elaborare più blocchi HDFS in parallelo. Se le dimensioni del blocco sono troppo piccole, sarà necessario distribuire un numero elevato di attività di mapping tra i nodi del cluster e l'overhead prodotto influirà negativamente sulle prestazioni. D'altro canto, se il blocco è troppo grande, il numero di attività di mapping che possono elaborare il file in parallelo è ridotto e questo influisce sul parallelismo. HDFS consente di specificare le dimensioni dei blocchi per ogni singolo file, in modo da ottimizzarle per ottenere il livello di parallelismo desiderato. L'interazione di MapReduce con HDFS viene descritta in dettaglio in un modulo successivo.
Inoltre, poiché HDFS è progettato per tollerare errori di singoli nodi, i blocchi di dati vengono replicati tra nodi per fornire ridondanza dei dati. Questo processo viene approfondito nelle sezioni seguenti.
Topologia dei cluster in HDFS
I cluster Hadoop vengono in genere distribuiti in un data center costituito da più rack di server connessi con una topologia ad albero FAT, come descritto in un modulo precedente. A questo scopo, HDFS è stato progettato con riconoscimento della topologia del cluster, che semplifica le decisioni relative alla posizione dei blocchi per influire sulle prestazioni e sulla tolleranza di errore. I cluster Hadoop comuni includono circa da 30 a 40 server per rack, con un commutatore gigabit dedicato al rack e un collegamento a un commutatore o un router centrale, la cui larghezza di banda viene condivisa tra molti rack nel data center, come mostrato nella figura seguente:
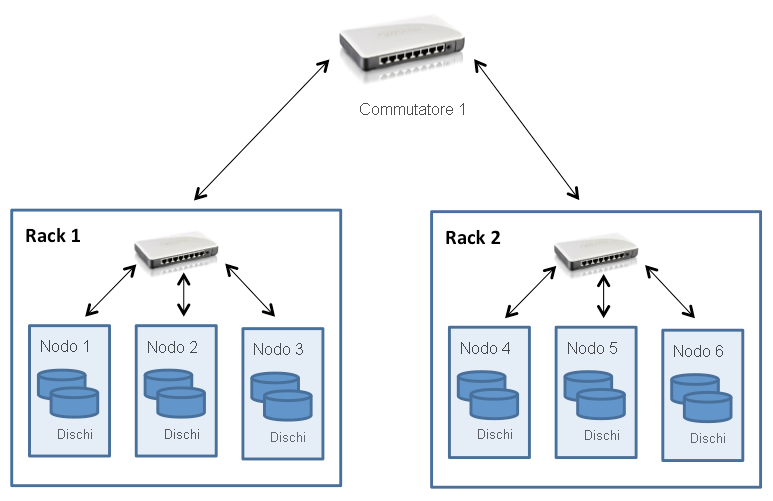
Figura 2: Topologia del cluster HDFS
Il punto saliente da notare è che Hadoop presuppone che la larghezza di banda aggregata all'interno dei nodi in un rack sia superiore alla larghezza di banda aggregata tra nodi su rack diversi. Questa supposizione è integrata nella progettazione di Hadoop per quanto riguarda l'accesso ai dati e il posizionamento delle repliche (descritto nelle sezioni seguenti).
Quando HDFS viene distribuito in un cluster, gli amministratori di sistema possono configurarlo con una descrizione della topologia che esegue il mapping di ogni nodo a un determinato rack del cluster. La distanza di rete viene misurata in hop, dove un hop corrisponde a un collegamento nella topologia. Hadoop presuppone una topologia di tipo albero e la distanza tra due nodi è la somma delle loro distanze dal predecessore comune più vicino.
Nell'esempio della figura 2 la distanza tra il nodo 1 e se stesso è pari a zero hop (caso in cui due processi comunicano nello stesso nodo). La distanza tra il nodo 1 e il nodo 2 è due hop, mentre la distanza tra il nodo 3 e il nodo 4 è quattro hop.
Il video seguente descrive le operazioni di lettura e scrittura di file in HDFS.
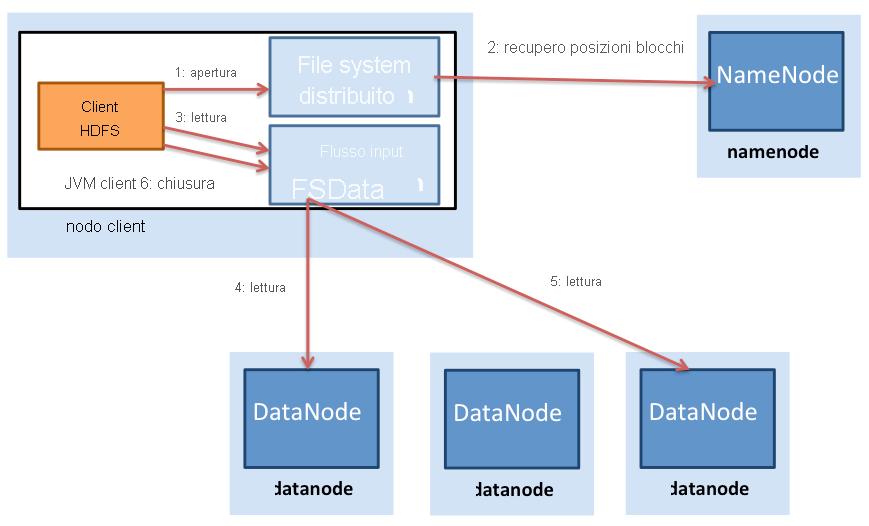
Figura 3: Letture di file in HDFS
La figura 3 mostra il processo di lettura di file in HDFS. Un client HDFS (l'entità che deve accedere a un file) contatta prima di tutto il nodo NameNode quando viene aperto un file per la lettura. Il nodo NameNode fornisce quindi al client un elenco di posizioni dei blocchi del file. Hadoop presuppone inoltre che i blocchi vengano replicati tra i nodi e di conseguenza il nodo NameNode trova effettivamente il blocco più vicino al client quando fornisce la posizione di un determinato blocco. La località viene determinata in questo ordine (località decrescente): blocchi all'interno dello stesso nodo del client, blocchi nello stesso rack del client e blocchi in un rack diverso rispetto al client.
Dopo aver determinato i percorsi dei blocchi, il client apre una connessione diretta a ogni DataNode e trasmette i dati da DataNode al processo client, operazione eseguita quando il client HDFS richiama l'operazione di lettura nel blocco di dati. Di conseguenza, il blocco non deve essere trasferito integralmente prima che il client possa iniziare il calcolo, frapponendo le operazioni di calcolo e di comunicazione. Quando il client termina la lettura del primo blocco, ripete il processo con i blocchi rimanenti, fino a completare la lettura di tutti i blocchi e quindi procedere alla chiusura del file.
È importante notare che i client contattano direttamente il nodo DataNode per recuperare i dati. Questo contatto consente ad HDFS di ridimensionarsi in base a un numero elevato di client contemporaneamente, per letture simultanee e parallele dei dati.
Le attività di scrittura di file e di lettura di file sono diverse in HDFS (Figura 4). Un client che deve scrivere dati in HDFS contatta prima di tutto il nodo NameNode e quindi comunica la creazione di un file. Il nodo NameNode controlla se il file esiste già e se il client ha l'autorizzazione necessaria per la creazione di un file. Se il controllo ha esito positivo, il nodo NameNode crea quindi un record di un nuovo file.
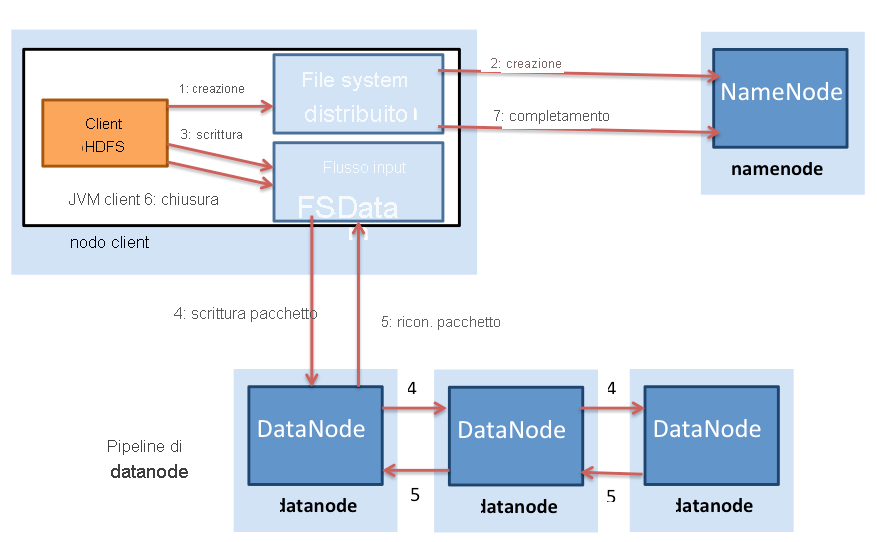
Figura 4: Scritture di file in HDFS
Il client passa quindi a scrivere il file in una coda di dati interna e richiede al nodo NameNode le posizioni dei blocchi nei nodi DataNode del cluster. I blocchi nella coda interna vengono quindi trasferiti a singoli nodi DataNode in modalità pipeline. Il blocco viene scritto nel primo nodo DataNode, che quindi trasferisce in modalità pipeline il blocco ad altri nodi DataNode per scrivere repliche del blocco. In questo modo, i blocchi vengono replicati durante la scrittura stessa del file. È importante tenere presente che HDFS non conferma una scrittura al client (passaggio 5 nella figura 4.28) finché tutte le repliche del file non sono state scritte dai nodi DataNode.
Hadoop usa anche la nozione di località del rack durante il posizionamento delle repliche. Per impostazione predefinita, i blocchi di dati vengono replicati tre volte in HDFS. HDFS tenta di posizionare la prima replica nello stesso nodo del client che scrive il blocco. Nel caso in cui un processo client non sia in esecuzione nel cluster HDFS, viene scelto un nodo in modo casuale. La seconda replica viene scritta in un nodo che si trova in un rack diverso dal primo (fuori dal rack). La terza replica del blocco viene quindi scritta in un altro nodo casuale nello stesso rack del secondo. Altre repliche vengono scritte in nodi casuali nel cluster, ma il sistema tenta di non posizionare troppe repliche nello stesso rack. La figura 5 mostra il posizionamento della replica per un blocco con replica tripla in HDFS. L'idea alla base del posizionamento delle repliche di HDFS è la possibilità di tollerare errori di nodi e rack. Ad esempio, quando un intero rack passa alla modalità offline a causa di problemi di alimentazione o di rete, il blocco richiesto può ancora trovarsi in un rack diverso.
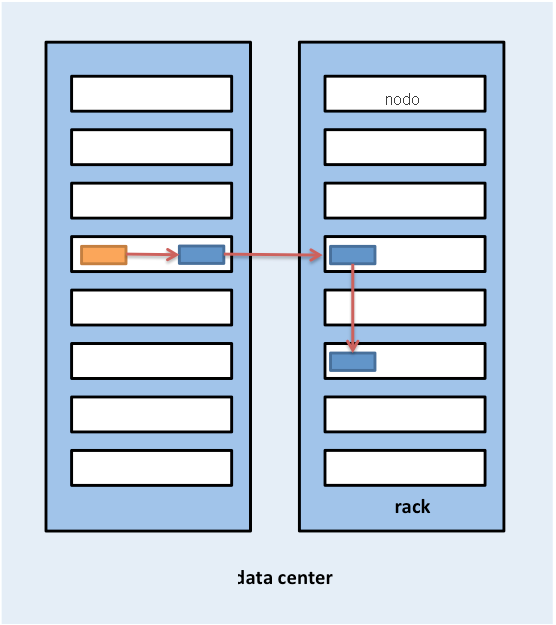
Figura 5: Posizionamento della replica per un blocco con replica triplo in HDFS
Sincronizzazione: semantica
La semantica di HDFS è cambiata leggermente. Le prime versioni di HDFS seguono una rigorosa semantica non modificabile. Una volta scritto un file nelle versioni precedenti di HDFS, il file non può essere più riaperto per la scrittura. I file possono comunque essere eliminati. Tuttavia, le attuali versioni di HDFS supportano l'accodamento in modo limitato. Questo significa che una volta scritti in HDFS, i dati binari esistenti non possono più essere modificati sul posto.
Questa scelta di progettazione in HDFS è stata adottata perché alcuni dei carichi di lavoro MapReduce più comuni seguono il modello di accesso ai dati a scrittura singola e a più letture WORM (Write Once, Read Many). MapReduce è un modello di calcolo limitato con fasi predefinite e gli output dei reducer in MapReduce scrivono file indipendenti in HDFS come output. HDFS è incentrato su accessi in lettura simultanei e veloci per più client per volta.
Modello di coerenza
HDFS è un file system con coerenza assoluta. Ogni blocco di dati viene replicato in più nodi, ma una scrittura viene dichiarata riuscita solo al termine della scrittura di tutte le repliche. Di conseguenza, tutti i client visualizzano il file non appena viene scritto e la visualizzazione del file è identica in tutti i client. La semantica non modificabile di HDFS semplifica relativamente questa implementazione, perché un file può essere aperto per la scrittura solo una volta durante la sua esistenza.
Tolleranza di errore in HDFS
Il meccanismo di tolleranza di errore principale in HDFS è la replica. Come indicato in precedenza, per impostazione predefinita ogni blocco scritto in HDFS viene replicato tre volte, ma può essere modificato dagli utenti in base ai singoli file, se necessario.
Il nodo NameNode tiene traccia dei nodi DataNode tramite un meccanismo di heartbeat. Ogni nodo DataNode invia messaggi heartbeat periodici (a intervalli di pochi secondi) al nodo NameNode. Se un nodo DataNode diventa inattivo, gli heartbeat al nodo NameNode vengono arrestati. Il nodo NameNode rileva che un nodo DataNode è inattivo se il numero di messaggi heartbeat mancanti raggiunge una determinata soglia. Il nodo NameNode contrassegna quindi il nodo DataNode come inattivo e non inoltra più richieste di I/O a tale nodo. Per i blocchi archiviati in questo nodo DataNode devono essere disponibili altre repliche in altri nodi DataNode. Inoltre, il nodo NameNode effettua un controllo dello stato sul file system per individuare blocchi sottoreplicati ed esegue un processo di ribilanciamento del cluster per avviare la replica per i blocchi per cui è disponibile un numero di repliche minore di quello desiderato.
Il nodo NameNode è un singolo punto di guasto (SPOF) in HDFS, perché un errore del nodo NameNode comporta l'arresto dell'intero file system. Internamente, il nodo NameNode gestisce due strutture di dati su disco che archiviano lo stato del file system: un file di immagine e un log delle modifiche. Il file di immagine è un checkpoint dei metadati del file system in un determinato momento, mentre il log delle modifiche è un log di tutte le transazioni dei metadati del file system dall'ultima creazione del file di immagine. Tutte le modifiche in ingresso ai metadati del file system vengono scritte nel log delle modifiche. A intervalli periodici, i log di modifica e il file di immagine vengono uniti per creare un nuovo snapshot del file di immagine e il log di modifica viene cancellato. In caso di errore di NameNode, tuttavia, i metadati non sarebbero disponibili e un errore del disco in NameNode sarebbe irreversibile perché i metadati del file andrebbero persi.
Per eseguire il backup dei metadati nel nodo NameNode, HDFS consente la creazione di un nodo NameNode secondario, che copia periodicamente i file di immagine dal nodo NameNode. Queste copie permettono di recuperare il file system in caso di perdita di dati nel nodo NameNode, ma le ultime modifiche apportate contenute nel log delle modifiche del nodo NameNode andranno perdute. Il lavoro in corso svolto nelle versioni più recenti di Hadoop ha come obiettivo la creazione di un nodo NameNode secondario vero e proprio, che intervenga automaticamente in caso di errore del nodo NameNode.
HDFS in pratica
Sebbene HDFS sia stato progettato principalmente per supportare processi MapReduce di Hadoop fornendo un file system DFS per operazioni di mapping e riduzione, HDFS ha trovato una miriade di usi con strumenti per Big Data.
HDFS viene usato in diversi progetti Apache basati sul framework Hadoop, tra cui Pig, hive, HBase e Giraph. Il supporto per HDFS è incluso anche in altri progetti, ad esempio GraphLab.
I vantaggi principali di HDFS sono i seguenti:
- Larghezza di banda elevata per carichi di lavoro MapReduce: i cluster Hadoop di grandi dimensioni (migliaia di computer) sono noti per scrivere continuamente fino a 1 terabyte al secondo con HDFS.
- Affidabilità elevata: la tolleranza di errore è un obiettivo principale della progettazione in HDFS. La replica in HDFS offre affidabilità e disponibilità elevate, in particolare nei cluster di grandi dimensioni, in cui la probabilità di errori del disco e del server aumenta significativamente.
- Costi bassi per byte: rispetto a una soluzione disco condivisa dedicata, ad esempio una SAN, HDFS costa meno per gigabyte perché l'archiviazione viene collocato con i server di calcolo. Con una SAN è necessario pagare costi aggiuntivi per l'infrastruttura gestita, ad esempio l'enclosure di array di dischi e i dischi aziendali di livello superiore, per gestire gli errori nell'hardware. HDFS è progettato per essere eseguito con prodotti hardware e la ridondanza viene gestita tramite software per la tolleranza di errore.
- Scalabilità: HDFS consente l'aggiunta di DataNodes a un cluster in esecuzione e offre strumenti per ribilanciare manualmente i blocchi di dati quando vengono aggiunti nodi del cluster, operazione che può essere eseguita senza arrestare il file system.
Gli svantaggi principali di HDFS includono i seguenti:
- Inefficienze di file di piccole dimensioni: HDFS è progettato per essere usato con dimensioni di blocchi di grandi dimensioni (64 MB e superiori). Ha lo scopo di eseguire file di grandi dimensioni (centinaia di megabyte, gigabyte o terabyte) e suddividerli in blocchi, che possono quindi essere inseriti in processi MapReduce per l'elaborazione parallela. HDFS è poco efficiente con file di dimensioni effettive ridotte (nell'ordine di kilobyte). La presenza di un numero elevato di file di piccole dimensioni pone un sovraccarico aggiuntivo per il nodo NameNode, che deve gestire i metadati per tutti i file nel file system. In genere, gli utenti di HDFS combinano molti file di piccole dimensioni in file più grandi tramite tecniche come i file di sequenza.
- POSIX non conforme: HDFS non è stato progettato per essere un file system compatibile con POSIX e montabile. Le applicazioni dovranno essere scritte da zero o modificate per l'uso di un client HDFS. Esistono soluzioni alternative che consentono di montare HDFS usando un driver FUSE, ma la semantica del file system non consente attività di scrittura nei file dopo che questi vengono chiusi.
- Modello write-once: il modello write-once è un potenziale svantaggio per le applicazioni che richiedono accessi in scrittura simultanei allo stesso file. Tuttavia, la versione più recente di HDFS supporta ora accodamenti di file.
In breve, HDFS è un'opzione utile come back-end di archiviazione per le applicazioni distribuite che seguono il modello MapReduce o che sono state scritte specificamente per l'uso di HDFS. HDFS può essere usato in modo efficiente con un numero ridotto di file di grandi dimensioni anziché con un numero elevato di file di piccole dimensioni.
Riferimenti
- Sanjay Ghemawat, Howard Gobioff e Shun-Tak Leung (2003). The Google File Systems Diciannovesimo simposio ACM sui principi dei sistemi operativi
- White, Tom (2012). Hadoop: The Definitive Guide O'Reilly Media, Yahoo Press