Case study: file system CEPH
Ceph è un sistema di archiviazione che può essere distribuito in cluster di server di grandi dimensioni con dischi collegati. Il video seguente presenta i concetti di base relativi a Ceph.
Gli obiettivi di progettazione per Ceph2 includono i seguenti:
- Cluster di archiviazione per utilizzo generico, abbastanza flessibile da supportare un'ampia gamma di applicazioni.
- Architettura in grado di ridimensionarsi facilmente fino a centinaia di migliaia di nodi e petabyte di archiviazione.
- Sistema altamente affidabile senza singolo punto di guasto, ovvero con gestione automatica e sicuro.
- Il sistema deve essere eseguito su hardware facilmente disponibile. Ceph è progettato per essere accessibile tramite tre astrazioni diverse, come mostrato nella figura seguente.
Il cluster di archiviazione Ceph è un archivio di oggetti distribuito. A un livello superiore del cluster di archiviazione vi sono i diversi servizi di archiviazione lato client. Il servizio Ceph Object Gateway consente ai client di accedere a un cluster di archiviazione Ceph tramite un'interfaccia HTTP basata su REST attualmente compatibile con i protocolli S3 di Amazon e Swift di OpenStack. Il servizio basato sui dispositivi a blocchi Ceph consente ai client di accedere al cluster di archiviazione come dispositivi a blocchi, che possono essere formattati con un file system locale e montati in un sistema operativo oppure usati come disco virtuale per l'esecuzione di macchine virtuali in Xen, KVM, VMWare o QEMU. Infine, Ceph File System (CephFS) fornisce l'astrazione di file e directory nell'intero cluster di archiviazione come file system conforme a POSIX.
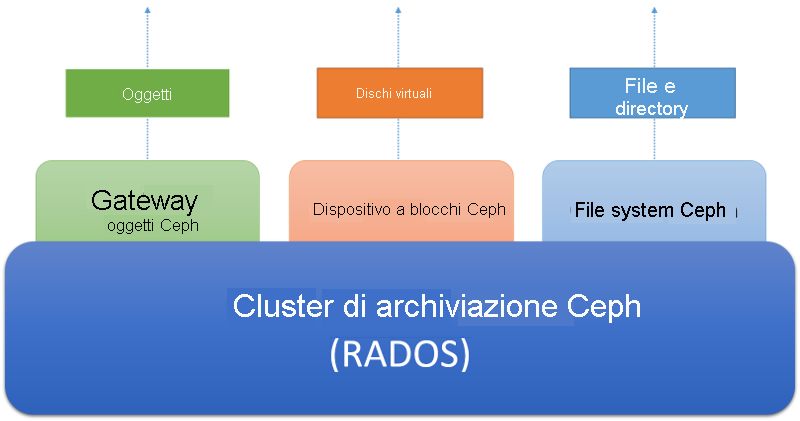
Figura 6: Ecosistema Ceph
Di seguito viene mostrata l'architettura di Ceph in modo più approfondito:

Figura 7: Architettura Ceph
Alla base di Ceph vi è un sistema di archiviazione di oggetti distribuito denominato RADOS. I client possono interagire direttamente con RADOS usando un'API di basso livello denominata librados, che è basata su socket e supporta diversi linguaggi di programmazione. In alternativa, i client possono interagire con le 3 API di livello superiore che forniscono tre astrazioni separate in RADOS.
RADOS Gateway o radosgw consente ai client di accedere a RADOS tramite un gateway basato su REST tramite HTTP. Questo emula il servizio di archiviazione di oggetti Amazon S3 ed è compatibile con le applicazioni che usano l'API Amazon S3 o l'API OpenStack SWIFT.
RADOS Block Device o RBD espone l'archivio di oggetti RADOS come dispositivo a blocchi distribuito per utilizzo generico, molto simile a una SAN. Tramite RBD, i dispositivi a blocchi vengono recuperati da RADOS e montati su sistemi Linux tramite un driver del kernel. RBD può essere usato anche come immagini di disco virtuale per i sistemi di virtualizzazione più diffusi, tra cui Xen, VMWare, KVM e QEMU.
CephFS è un file system distribuito conforme a POSIX di livello superiore rispetto a RADOS, che può essere montato direttamente nei file system dei client Linux. Il file system Ceph verrà descritto in dettaglio più avanti in questa pagina.
Architettura del cluster di archiviazione Ceph (RADOS)
Alla base di Ceph vi è RADOS (Reliable, Autonomous, Distributed Object Store). In RADOS i dati vengono archiviati come oggetti distribuiti in un cluster di computer. I client interagiscono con un cluster RADOS archiviando e recuperando oggetti. Un oggetto è costituito da un nome di oggetto (chiave utilizzata per identificare un oggetto) e dal contenuto binario dell'oggetto (valore associato a una determinata chiave dell'oggetto). Il ruolo di RADOS consiste nell'archiviare oggetti in modo distribuito in un cluster con scalabilità, affidabilità e tolleranza di errore.
Sono disponibili due tipi di nodi in un cluster RADOS: nodi OSD (Object Storage Daemon) e nodi di monitoraggio (figura 8). Un nodo OSD archivia gli oggetti e risponde alle richieste di oggetti. I nodi OSD archiviano questi oggetti in nodi usando il file system locale in ogni nodo e mantengono una cache del buffer per migliorare le prestazioni. I nodi di monitoraggio controllano lo stato del cluster per tenere traccia dei nodi OSD che entrano ed escono dal server.
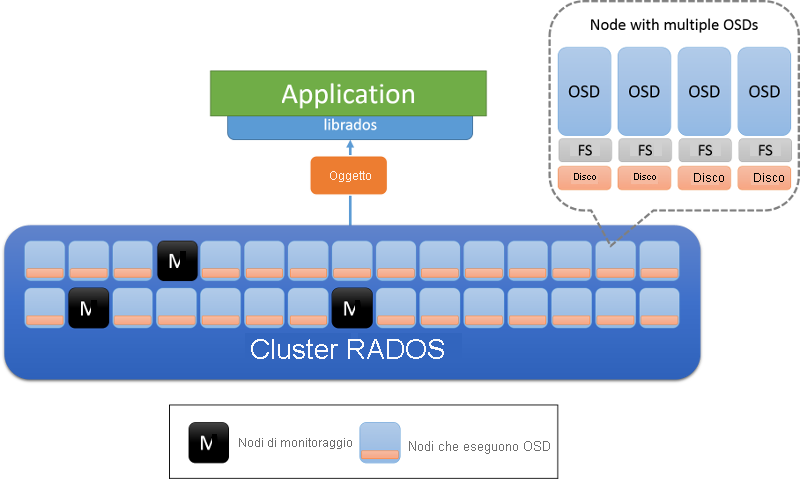
Figura 8: Architettura RADOS. I nodi OSD sono responsabili dei dati in un nodo: in genere viene distribuito un nodo OSD per ogni disco fisico. I nodi contrassegnati con M sono i nodi di monitoraggio.
Stato del cluster e nodi di monitoraggio in RADOS
Lo stato di un cluster RADOS viene incapsulato in un oggetto noto come mappa del cluster, condivisa da tutti i nodi di un cluster. La mappa del cluster contiene informazioni sullo stato di un cluster in qualsiasi momento, incluso il numero di nodi OSD attualmente presenti, una rappresentazione compatta di come vengono distribuiti i dati tra nodi OSD (operazione che verrà descritta più in dettaglio nella sezione seguente) e un timestamp logico che indica il momento in cui è stata creata la mappa del cluster. Gli aggiornamenti alla mappa del cluster vengono eseguiti in modo incrementale peer-to-peer dai nodi di monitoraggio. Di conseguenza, solo le modifiche nella mappa del cluster da un timestamp all'altro vengono comunicate tra i nodi in un cluster, in modo da mantenere minima la quantità di dati trasferiti tra nodi.
I nodi di monitoraggio in RADOS sono collettivamente responsabili della gestione del sistema di archiviazione attraverso l'archiviazione della copia master della mappa del cluster e l'invio di aggiornamenti periodici in caso di modifica dello stato dei nodi OSD. I nodi di monitoraggio sono organizzati in base all'algoritmo Paxos ed è necessario che la maggior parte di essi legga o aggiorni la mappa del cluster. Questi nodi di monitoraggio assicurano che gli aggiornamenti della mappa siano serializzati e coerenti. Un cluster RADOS è progettato per includere un numero ridotto di nodi di monitor (>3), in genere un numero dispari per evitare la presenza di collegamenti da interrompere quando singoli monitor devono raggiungere il consenso.
Posizionamento dei dati in RADOS
Per il corretto funzionamento di un archivio di oggetti distribuito, un client deve essere in grado di contattare il nodo OSD corretto per interagire con un oggetto. Innanzitutto, un client contatta un nodo di monitoraggio per recuperare la mappa del cluster per il cluster di archiviazione specificato. Le informazioni contenute nella mappa del cluster possono essere usate per determinare il nodo OSD specifico responsabile di un determinato oggetto nel cluster.
Il primo passaggio consiste nel determinare il gruppo di posizionamento di un oggetto specifico (figura 9). Un gruppo di posizionamento può essere considerato un bucket in cui si trova un oggetto. A questo scopo, viene usata una funzione hash (la funzione hash più recente da usare viene sempre ottenuta dalla mappa del cluster). Una volta determinato un gruppo di posizionamento per l'oggetto specifico, il client deve trovare il nodo OSD responsabile del gruppo di posizionamento.
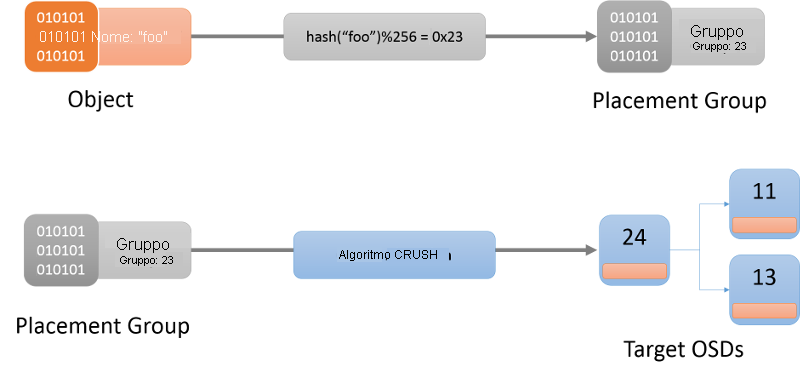
Figura 9: Individuazione di un oggetto in un gruppo di posizionamento e infine in un OSD usando l'algoritmo CRUSH.
L'algoritmo usato per assegnare gruppi di posizionamento a nodi OSD è noto come algoritmo CRUSH (Controlled Replication Under Scalable Hashing)1 (figura 9). CRUSH assegna i gruppi di posizionamento in un cluster in modo pseudo casuale, ma deterministico. CRUSH è più stabile di una funzione hash, nel senso che quando i nodi OSD entrano o escono dal cluster CRUSH fa sì che la maggior parte dei gruppi di posizionamento resti dove si trova e sposta solo una piccola quantità di dati per mantenere una distribuzione bilanciata. Una funzione hash semplice, d'altro canto, richiederebbe la ridistribuzione della maggior parte delle chiavi quando vengono aggiunti o rimossi bucket. La descrizione completa dell'algoritmo CRUSH esula dall'ambito di questa discussione. I lettori interessati devono fare riferimento a CRUSH: posizionamento controllato, scalabile e decentralizzato dei dati replicati.
Quando viene eseguito l'hashing di un nome di oggetto in un gruppo di posizionamento, CRUSH produce un elenco esatto dei nodi OSD che sono responsabili del gruppo di posizionamento. Qui r è il numero di repliche per un oggetto specifico. In base alle informazioni nella mappa del cluster, vengono identificati i nodi OSD attivi inclusi in questo mapping, quindi è possibile contattare il nodo OSD per interagire (operazioni come creazione, lettura, aggiornamento o eliminazione) con l'oggetto specificato.
Replica in RADOS
In RADOS un oggetto viene replicato tra più nodi OSD associati al gruppo di posizionamento dell'oggetto. In questo modo, si garantisce la presenza di più copie di un determinato oggetto in caso di errore di uno dei nodi OSD. RADOS include molti schemi disponibili in cui viene effettivamente eseguita la replica. Questi sono gli schemi di replica della copia primaria, a catenaed estesa (figura 10).
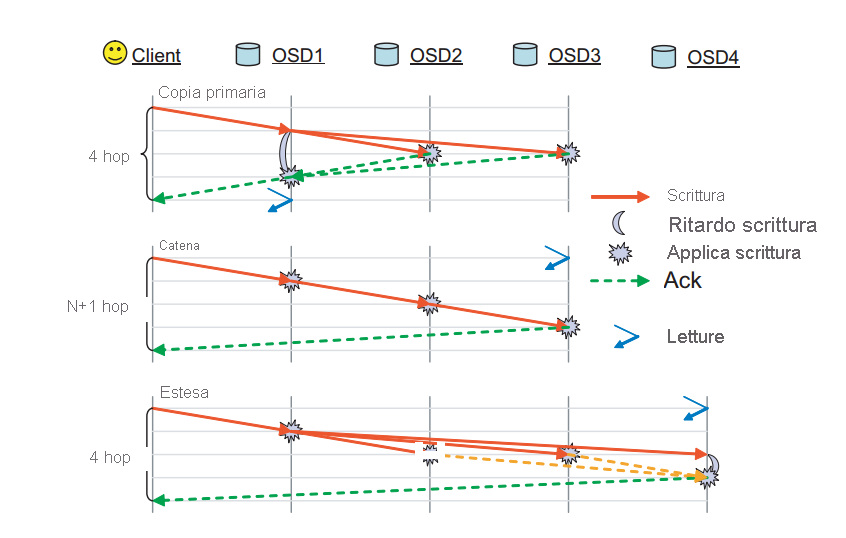
Figura 10: Modalità di replica supportate in RADOS. (fonte 2).
Replica di copia primaria: nello schema di replica di copia primaria, un client interagisce con il primo OSD disponibile (OSD della replica primaria) per interagire con un oggetto. Il nodo OSD della replica primaria elabora la richiesta e risponde al client. Nel caso di una scrittura, il nodo OSD di replica primaria inoltra la richiesta di scrittura a repliche r-1 che aggiornano quindi le proprie copie locali dell'oggetto e rispondono al nodo master. L'operazione di scrittura nel nodo master viene posticipata fino a quando gli altri nodi OSD non eseguono il commit di tutte le scritture per l'oggetto. Il nodo master conferma la scrittura al client. La scrittura non è completa finché tutte le repliche non rispondono al nodo OSD della copia primaria. Lo stesso processo si applica alle letture: la copia primaria risponde a una lettura solo dopo che tutte le repliche vengono contattate e il valore dell'oggetto è lo stesso tra tutte le repliche.
Replica della catena: le richieste di un oggetto vengono inoltrate nella catena fino a quando non viene trovata la replica r (finale). Se l'operazione è una scrittura, ne viene eseguito il commit in ognuna delle repliche lungo la catena verso l'ultima replica. Il nodo OSD finale contenente la replica finale conferma infine la scrittura al client. Tutte le operazioni di lettura vengono indirizzate direttamente alla coda, per ridurre il numero di hop necessari per la lettura dei dati da un cluster.
Replica Splay: la replica Splay combina gli elementi della replica di copia primaria e della replica a catena. Le richieste di lettura vengono indirizzate all'ultimo nodo OSD nella catena di replica, mentre le scritture vengono inviate prima al nodo head. A differenza della replica a catena, gli aggiornamenti ai nodi OSD intermedi vengono eseguiti in parallelo, analogamente allo schema di replica di copia primaria.
Oltre a questi schemi di replica, il salvataggio permanente in RADOS viene gestito utilizzando due messaggi di conferma distinti (figura 11). Ogni nodo OSD dispone di una cache del buffer dei dati resi disponibili. Gli aggiornamenti vengono scritti nella cache del buffer e riconfermati immediatamente tramite un messaggio ack. Questa cache del buffer viene scaricata periodicamente sul disco e quando l'ultima replica ha eseguito il commit dei dati su disco, viene inviato un messaggio commit al client, che indica che i dati sono stati salvati in modo permanente.
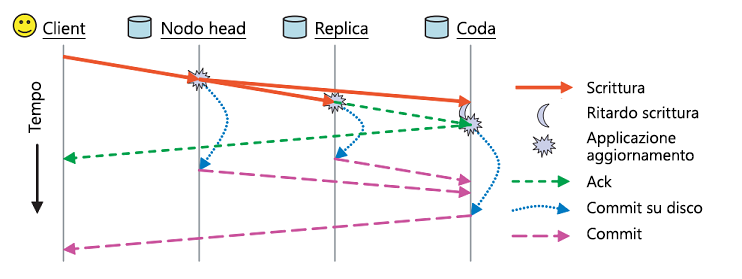
Figura 11: Messaggi Ack e commit in RADOS (origine 2)
Modello di coerenza in RADOS
Tutti i messaggi in RADOS (sia i messaggi dal client sia quelli peer-to-peer tra i nodi) vengono contrassegnati con il timestamp per garantire che vengano ordinati e applicati in modo coerente. Se i nodi OSD rilevano un messaggio errato a causa di una mappa del cluster non aggiornata dal richiedente del messaggio, vengono inviati aggiornamenti incrementali della mappa per aggiornare il richiedente del messaggio.
Esistono casi limite in cui le garanzie di assoluta coerenza offerte da RADOS devono essere gestite con attenzione. Se i mapping dei gruppi di posizionamento per un determinato nodo OSD cambiano (in caso di modifica della mappa del cluster), il sistema deve garantire che l'handoff dei gruppi di posizionamento tra i nodi OSD precedenti e quelli nuovi venga eseguito in modo uniforme e coerente. Durante la modifica di un gruppo di posizionamento, sono necessari nuovi nodi OSD per contattare quelli precedenti per il passaggio dello stato, durante il quale i nodi OSD precedenti vengono a conoscenza della modifica e arrestano le query corrispondenti per i gruppi di posizionamento specifici.
Un altro caso in cui le rigorose garanzie di coerenza possono essere difficili da realizzare è se si verifica un errore di rete che causa una partizione di rete. In questo caso, alcuni client che hanno una mappa del cluster meno recente possono continuare a eseguire operazioni di lettura su tale nodo OSD, mentre una mappa aggiornata può modificare il nodo OSD responsabile del gruppo di posizionamento. Si tratta di uno scenario di errore evidenziato in precedenza nella trattazione del teorema CAP. Questa finestra di incoerenza è sempre presente in questo caso. RADOS cerca di ridurre l'effetto di questo scenario richiedendo a tutti i nodi OSD di scambiare messaggi heartbeat con le altre repliche, a un intervallo predefinito di 2 secondi. Se un particolare nodo OSD non riesce a raggiungere gli altri gruppi di replica entro una certa soglia, le letture vengono bloccate. Inoltre, i nodi OSD assegnati come nuovi nodi primari per un gruppo di posizionamento specifico devono ricevere una conferma del passaggio dal nodo primario del gruppo di posizionamento precedente o attendere l'intervallo di heartbeat prima di presupporre che il nodo primario del gruppo di posizionamento precedente sia inattivo. In questo modo, viene ridotta la possibile finestra di incoerenza in un cluster RADOS in presenza di partizioni di rete.
Rilevamento degli errori e tolleranza di errore in RADOS
Gli errori dei nodi in RADOS vengono rilevati durante un errore di comunicazione tra i nodi OSD assegnati a un gruppo di posizionamento o tra i nodi OSD e i nodi di monitoraggio. Se un nodo non risponde entro un numero limitato di tentativi di riconnessione, viene dichiarato inattivo. I nodi OSD che fanno parte di un gruppo di posizionamento scambiano messaggi heartbeat per garantire il rilevamento degli errori. Questo fa sì che i nodi di monitoraggio prendano il controllo sull'aggiornamento della mappa del cluster e sulla relativa notifica a tutti i nodi tramite un messaggio di aggiornamento incrementale della mappa. Dopo un aggiornamento della mappa del cluster, i nodi OSD scambiano oggetti tra loro per garantire il mantenimento del numero desiderato di repliche per ogni gruppo di posizionamento. Se un nodo OSD rileva tramite un messaggio di essere stato dichiarato inattivo, sincronizza semplicemente il proprio buffer sul disco e termina se stesso per garantire un comportamento coerente.
File system Ceph
Come mostrato nella figura precedente, il file system Ceph è un livello di astrazione sul sistema di archiviazione RADOS. RADOS non include alcun concetto di metadati per un oggetto, a parte il nome dell'oggetto. Il file system Ceph consente il posizionamento dei metadati dei file a un livello superiore rispetto ai singoli oggetti file archiviati in RADOS. Il video seguente presenta il concetto di CephFS.
Oltre ai ruoli dei nodi OSD e di monitoraggio del cluster, il file system Ceph introduce i server di metadati (figura 12). Questi server archiviano i metadati del file system (l'albero di directory, nonché gli elenchi di controllo di accesso e le autorizzazioni, la modalità, le informazioni di titolarità e i timestamp per ogni file).
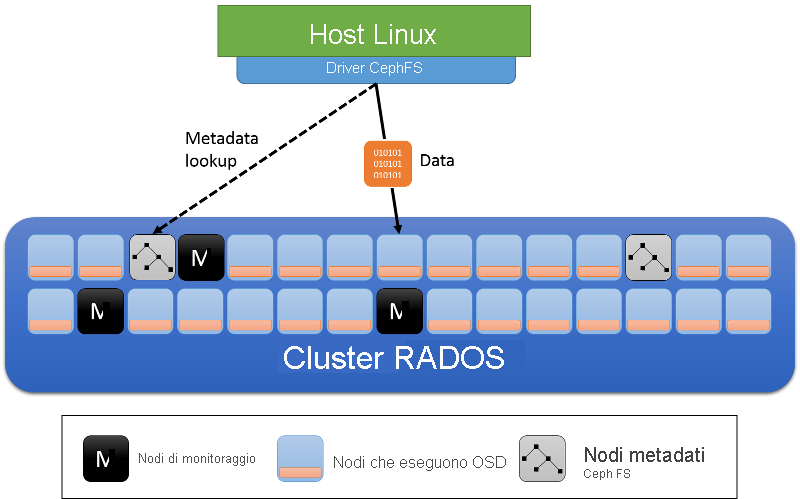
Figura 12: Server di metadati nel file system Ceph
I metadati usati dal file system Ceph sono diversi da quelli usati dai file system locali per molti aspetti. In un file system locale un file viene descritto da un inode, che contiene un elenco di puntatori che puntano ai blocchi di dati di un file. Le directory in un file system locale sono semplicemente file speciali che contengono collegamenti ad altri inode, che possono essere altri file o directory. Nel file system Ceph un oggetto directory nel server di metadati contiene tutti gli inode incorporati al suo interno.
Partizionamento dinamico di sottoalberi
Inizialmente, un singolo server di metadati è responsabile di tutti i metadati per il cluster. Poiché i server di metadati vengono aggiunti al cluster, l'albero di directory del file system viene partizionato e assegnato al gruppo di server di metadati risultante (figura 13). Ogni server di metadati misura la popolarità dei metadati all'interno della gerarchia di directory tramite contatori. Viene usato uno schema ponderato3 non solo per aggiornare il contatore di un nodo foglia specifico nella directory, ma anche per i predecessori dell'elemento di directory fino alla radice. Di conseguenza, ogni server di metadati può mantenere un elenco di hotspot nei metadati che possono essere spostati in un nuovo server di metadati aggiunto al cluster.
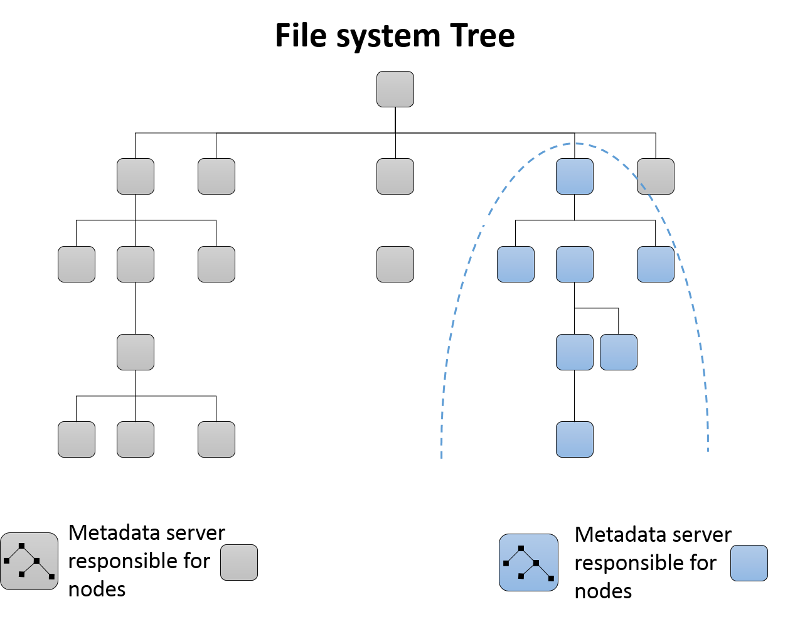
Figura 13: Partizionamento di sottoalbero dinamico nel file system Ceph
Memorizzazione nella cache e tolleranza di errore nei server di metadati
I server di metadati nel file system Ceph in genere memorizzano nella cache le informazioni sui metadati e gestiscono la maggior parte delle richieste non in memoria. Inoltre, i server di metadati usano una forma di inserimento nel journal, in cui gli aggiornamenti vengono inviati a valle a RADOS come oggetti journal, che vengono scritti per ogni server di metadati. In caso di errore di un server di metadati, è possibile riprodurre il journal per ricreare la parte del server di metadati con errore dell'albero in un nuovo server di metadati o in uno esistente.
Riferimenti
- Weil, S. A., Brandt, S. A., Miller, E. L., & Maltzahn, C. (2006). CRUSH: Controlled, scalable, decentralized placement of replicated data negli atti della conferenza ACM/IEEE 2006 sul supercomputing 122
- Weil, S. A., Brandt, S. A., Miller, E. L., & Maltzahn, C. (2006). Ceph: A scalable, high-performance distributed file system Documentazione del settimo simposio sulla progettazione e sull'implementazione dei sistemi operativi, 307-320
- Weil, S. A., Pollack, K. T., Brandt, S. A., & Miller, E. L. (2004). Dynamic metadata management for petabyte-scale file systems negli atti della conferenza ACM/IEEE 2004 sul supercomputing 4